 AVM系統算法框架搭建的方法
AVM系統算法框架搭建的方法
AVM(Around View Monitor),中文:全景環視系統。AVM已經是一種較為成熟的技術,中高端車型均有部署,但詳細講述AVM系統算法的技術博文并不多。作者在工作中搭建了一套AVM算法框架,有一些效果還不錯的demo。本文主要是想將AVM算法框架中每個算子講述清楚,與大家共同進步。本博文的風格為理論與實踐結合,含有部分代碼,適合有一些計算機視覺基礎的同學。
作者仿真效果
01AVM系統概述
AVM汽車環視影像系統如圖所示,由安裝在前保險杠、后備箱、后視鏡上的四個外置魚眼相機構成。該系統包含的算子按照先后順序:去畸變、四路魚眼相機聯合標定、投影變換、鳥瞰圖微調、拼接融合、3D模型紋理映射等。四路魚眼捕捉到的圖像信息通過上述算子,生成一個2D、3D的全景圖。AVM算法又分為離線階段和在線階段兩部分,在線階段是對離線階段的簡化,更加適合于工程實現。下面我們來一一講述。
02離線階段算法pipeline
先來粗略瀏覽下AVM算法Pipeline包含哪些算子:
2DAVM
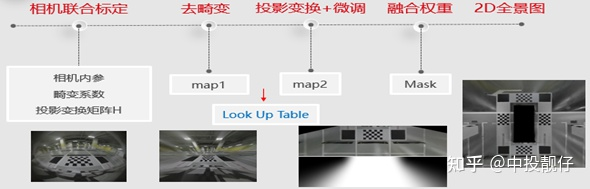
2D AVM Pipeline
3DAVM
2.1基于畸變表的魚眼相機去畸變
2.1.1 魚眼相機畸變模型
我們知道普通相機和廣角相機的投影方式一般為透視投影,即通過三角形相似原理,將相機坐標系下三維世界中的物體投影到平面上,這是基于理想的透視投影模型(無畸變)。但實際情況是我們得到的最終圖像與理想的透視投影模型有一些區別,即徑向畸變(桶形、枕型)、切向畸變。因此相機標定中都會對畸變做矯正。
魚眼相機的投影方式有很多種假設,例如等距投影、等立體角投影、正交投影、體視投影、線性投影。但是真實的魚眼相機鏡頭并不完全遵循上述的這些模型假設。因此Kannala-Brandt提出了一種一般形式的估計,適用于不同類型的魚眼相機:
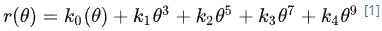
這個也是納入opencv中的魚眼相機畸變模型。對照下圖:
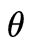 為光線入射角
為光線入射角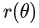 為出射光線在相機歸一化平面上或者在相機成像平面上與O之間的距離(在opencv中表示光線在相機歸一化平面上的成像位置)。
為出射光線在相機歸一化平面上或者在相機成像平面上與O之間的距離(在opencv中表示光線在相機歸一化平面上的成像位置)。
魚眼相機模型
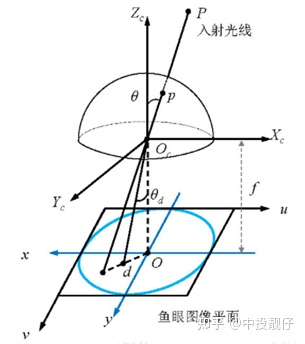
相機去畸變通常使用張正友老師的棋盤格標定方法,首先通過矩陣推導得到一個比較好的初始解,然后通過非線性優化得到最優解,包括相機的內參、外參、畸變系數,然后對魚眼圖像做去畸變處理。內參即:
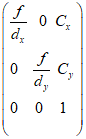
相機內參矩陣
然而,張正友標定法并不適用于我們的場景。
2.1.2 基于廠家畸變表的魚眼圖像去畸變
由于張正友老師的棋盤格標定法是在圖像的全局進行擬合得到一個全局的最優解,因此需要保證多次拍攝到的標定板的棋盤格可以覆蓋整個圖像區域。
而我們假設的場景為要求汽車整車上流水線進行標定,即相機已經安裝在車上。很顯然,由于車身遮擋的原因,很難保證上述條件。另外,棋盤格標定法并不適用于批量生產。因此,我們選擇了基于廠家提供的畸變表對魚眼相機圖像進行去畸變。相機廠家都有專業的光學工程師,大廠提供的畸變表通常情況下比較準確。當然,也有一些在畸變表的基礎上進行優化的方法,例如[2]中采用最小重投影的方法計算出最優的相機主點位置,然后使用畸變表進行去畸變處理。在其他場景中,還有些同學先標定出相機的內參,然后將內參與畸變表聯合使用。下面我們來講述基于畸變表的去畸變方法:
廠家提供的畸變表
上面的表格展示了相機畸變表的一部分,廠家給出了入射角從0°到90°的光線在焦距為f的相機真實成像平面上成像點距離成像平面中心的真實距離,單位為mm。如果想用opencv提供的API做去畸變處理,需要使用廠家提供的焦距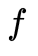 ,將換算到相機的歸一化平面上去(即除以)。然后通過多項式擬合的方法,計算出
,將換算到相機的歸一化平面上去(即除以)。然后通過多項式擬合的方法,計算出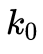 ,
,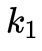 ,
,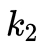 ,
,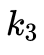 ,
,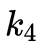 這幾個畸變參數,例如可以使用python的curve_fit庫進行多項式擬合。調用Opencv API,m_distortion_coeffs即為多項式擬合的畸變參數。
這幾個畸變參數,例如可以使用python的curve_fit庫進行多項式擬合。調用Opencv API,m_distortion_coeffs即為多項式擬合的畸變參數。
fisheye::initUndistortRectifyMap(m_intrinsic_matrix, m_distortion_coeffs, R, NewCoeff, image_size*2, CV_32FC1, mapx, mapy); cv::remap(disImg, undisImg, mapx, mapy, INTER_LINEAR);
通俗講:魚眼相機去畸變的過程實際上就是遍歷我們想要的無畸變圖上的坐標點,通過mapx,mapy兩個查找表,找到該坐標點在畸變圖上的像素位置。通常這個像素的位置為浮點型,需要做雙線性插值。否則在紋理邊緣上會有鋸齒狀的問題,這個結論是作者實現了opencv remap函數驗證過的,有興趣的同學可以自己實現一下mapping的過程(查找+插值)。來看圖:

魚眼圖 去畸變
右圖為基于畸變表去畸變的結果,可以看出去畸變的效果大體上滿足要求,例如柱子邊、標定布邊、車道線為直線。但是仍有部分區域的去畸變效果不好,直線不夠直。這個問題會在鳥瞰圖中看起來更加突出,也是導致覆蓋區域拼接不齊的重要原因。原因可能有幾種:(1)相機光軸與成像平面的交點(主點)與圖像平面的中心不重合,即內參矩陣中的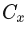 ,
,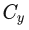 。(2)廠家給的焦距
。(2)廠家給的焦距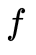 不準(3)廠家給的畸變表有誤差。
不準(3)廠家給的畸變表有誤差。
理論上講,相機的標定是一個計算全局最優解的過程,可以理解為:我的內參可以不那么準,我拿到的畸變表也可以不那么準,但是只要我的優化目標重投影誤差很小,或者畸變去的比較干凈,那么這個全局最優解就是可以接受的。因此引用【2】中使用了最小化重投影誤差的方法得到內參中,然后再使用畸變表;在有的場景中,還有些同學用棋盤格標定出相機的內參,然后配合畸變表進行使用。這些內容作者后面都會陸續做優化。
2.2四路魚眼聯合標定
魚眼相機聯合標定的目的是要得到四個魚眼相機之間的位姿關系,然后將拍攝到的圖像搞到同一個坐標系下得到一幅全景環視圖。
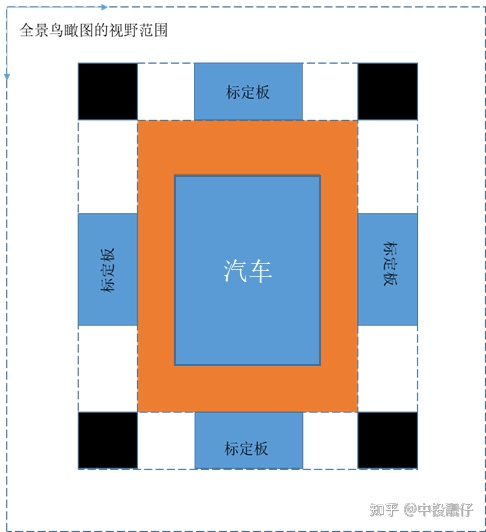
相機聯合標定示意圖
如圖所示,全景鳥瞰圖的視野范圍是人為給定的參數,可根據用戶喜好進行調節。標定布上的棋盤格大小、黑格子尺寸、汽車與標定布之間的間距這些都是已知的先驗信息。上述先驗信息在現實世界中與在全景圖上的尺度關系為1:1,即1個像素代表1cm(當然這個尺度也可以調節,你想讓一個像素代表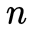 厘米也沒問題)。這樣做聯合標定的意義在于:我們可以知道前、后、左、右四個魚眼相機去畸變后圖像中棋盤格上角點,與前、后、左、右四個鳥瞰圖中棋盤格角點之間對應的坐標關系。這樣我們就可以根據投影變換,將整張圖像投影到對應的鳥瞰圖上去。又由于在聯合標定中,四個鳥瞰圖是剛好拼接到一塊的,因此利用上述方法將四張圖全部投影到鳥瞰圖上,在不考慮誤差的理想情況下,應該是剛好拼接在一起的。以上,就是聯合標定的思路。
厘米也沒問題)。這樣做聯合標定的意義在于:我們可以知道前、后、左、右四個魚眼相機去畸變后圖像中棋盤格上角點,與前、后、左、右四個鳥瞰圖中棋盤格角點之間對應的坐標關系。這樣我們就可以根據投影變換,將整張圖像投影到對應的鳥瞰圖上去。又由于在聯合標定中,四個鳥瞰圖是剛好拼接到一塊的,因此利用上述方法將四張圖全部投影到鳥瞰圖上,在不考慮誤差的理想情況下,應該是剛好拼接在一起的。以上,就是聯合標定的思路。
2.3投影變換
2.3.1 投影變換原理
投影變換的通俗理解就是:假設同一個相機分別在A、B兩個不同位置,以不同的位姿拍攝同一個平面(重點是拍攝平面,例如桌面、墻面、地平面),生成了兩張圖象,這兩張圖象之間的關系就叫做投影變換。張正友老師的相機標定法使用的就是從標定板平面到圖像平面之間的投影模型。
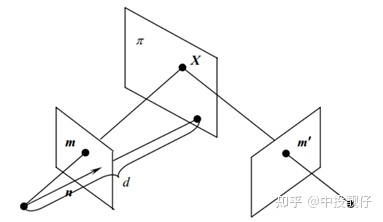
投影變換模型
圖中相機從兩個不同的角度拍攝同一個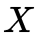 平面,兩個相機拍攝到的圖像之間的投影變換矩陣
平面,兩個相機拍攝到的圖像之間的投影變換矩陣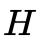 (單應矩陣)為:
(單應矩陣)為:
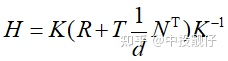
其中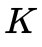 為相機內參矩陣,
為相機內參矩陣,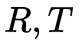 為兩個相機之間的外參。這個公式怎么推導的網上有很多,我們只需要知道,這個單應矩陣內部實際是包含了兩個相機之間的位姿關系即可。這也就解釋了:為什么有的AVM pipeline的方法是需要標定相機的外參,然后通過廠家提供的相機安裝參數將四路魚眼全部統一到車身坐標系下,而我們不需要這個過程,只需要用標定布來做聯合標定。其實兩種方法內部都是相通的,都繞不開計算相機外參這件事情。
為兩個相機之間的外參。這個公式怎么推導的網上有很多,我們只需要知道,這個單應矩陣內部實際是包含了兩個相機之間的位姿關系即可。這也就解釋了:為什么有的AVM pipeline的方法是需要標定相機的外參,然后通過廠家提供的相機安裝參數將四路魚眼全部統一到車身坐標系下,而我們不需要這個過程,只需要用標定布來做聯合標定。其實兩種方法內部都是相通的,都繞不開計算相機外參這件事情。
2.3.2 投影變換生成鳥瞰圖
生成鳥瞰圖的過程可以理解為:將魚眼相機拍攝到的圖像,投影到某個在汽車上方平行地面拍攝的相機的平面上去。這個單應矩陣具體是多少,由去畸變圖中檢測到的棋盤格角點坐標和聯合標定全景圖中棋盤格角點坐標來決定。如圖所示,以后置相機為例,聯合標定已知圖(2)中框出棋盤格的坐標,圖(1)中的棋盤格坐標可通過opencv的函數進行檢測,從而建立單應矩陣H的求解模型。

(1)去畸變圖中棋盤格位置 (2)聯合標定全景圖中棋盤格位置 (3)瞰圖
2.3.3 一些經驗之談
a. 盡量選擇更多的角點計算單應矩陣
單應矩陣的求解是一個擬合的過程,如果選用過少的點,容易陷入局部最優解。造成的結果是就是鳥瞰圖上只有你選擇的那些點可以正確的投影,其他像素的投影可能不正確。這一點有點類似于深度學習中訓練樣本太少,導致過擬合的問題。
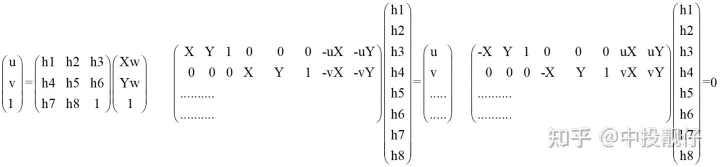
單應矩陣三種形式(1)(2)(3)
上面公式可以看出,一對匹配點可以提供兩組方程,理論上4對匹配點就可以求解出單應矩陣。Opencv求解單應矩陣提供了兩個函數,findHomography和getPerspectiveTransform。
getPerspectiveTransform的輸入是4對點,對(2)中矩陣求逆。理想情況下這種方法是可行的,但由于存在噪聲,我們在圖像上檢測到的角點的誤差、標定布棋盤格的誤差,這種方法極其不準確。
findHomography求單應矩陣的方法輸入點對很多,解一個超定方程(3)。經過一頓推導,單應矩陣為(3)中矩陣的奇異值分解中最小奇異值對應的特征向量。這種方法用于做擬合的樣本更多,最終的效果更好。而且Opencv還有很多優化算法,例如基于ransac思想的單應矩陣求解方法。當然,為了提高效果,可以對標定布進行DIY,某寶上很多這種DIY標定布,你想搞多少格子就搞多少。
如1.2所述,由于畸變去除的不徹底,導致有些直線仍然是彎曲的。這一現象在投影到鳥瞰圖上之后尤為明顯,通過大量的棋盤格點進行投影變換,可以從一定程度上強制矯正這個問題。至少可以讓車身附近的全景圖效果更佳,而我們的avm系統最在意的恰好就是車身周圍這部分,距離車身遠的部分也不會呈現出來。如圖所示為某廠DIY的標定布示意圖。

DIY標定布
b. 盡量讓棋盤格處于相機拍攝圖像的中心
魚眼相機在中心部分畸變小,邊緣位置畸變大。去畸變的結果通常也是中間的效果好,邊緣殘留的畸變多。因此,為了使單應矩陣計算的更佳準確,我們要保證標定布擺放的時候棋盤格位于魚眼相機中央。這也是為什么某寶上標定布使用的示意圖通常是圖(2)這種,而不是圖(1)。很顯然,圖(2)中棋盤格位于左側后視鏡附近(左魚眼相機就在左后視鏡上),即相機圖像的中間位置,而圖1中棋盤格則在相機圖像邊緣上。

左側魚眼相機鳥瞰圖(1)(2)
2.4拼接融合
經過3中的投影變換,我們得到4張包含重疊區域的鳥瞰圖如圖所示,需要將這些鳥瞰圖進行拼接融合。

鳥瞰圖
以左、前魚眼相機俯視圖為例,觀察下它們的重疊區域重疊區域:

白色為重疊區域、AB為前鳥瞰圖邊界、CD為右鳥瞰圖邊界
通常的做法是分別以AB、CD為邊界,計算白色區域像素點與AB、CD之間的距離,然后計算一個權重,距離CD越近的位置,前俯視圖權重越大;距離AB越近的位置,左俯視圖權重越大。但會出現邊界效應如圖所示:

前俯視圖權重圖
其原因也很容易理解:如圖所示,將AB、CD延長至O點,在EAOCE這個區域內,使用上述方法計算權重圖才是一個完整連續的模型,如果在EABFDCE這個區域內計算權重圖相當于把一個完整連續的域強行截斷,計算得到的權重圖必然是有截斷痕跡的
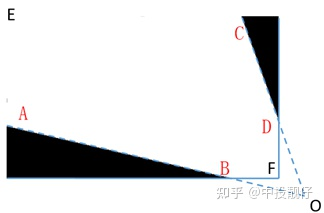
完整、連續模型示意圖
因此需要使用某種策略,讓我們在一個連續的作用域上計算權重,這里提供一個思路[3]:在EAFCE這個連續的作用域中計算權重,
連續模型和權重圖
2.5基于光流的鳥瞰圖微調
在整個AVM系統中,廠家提供的畸變表、焦距、相機主點位置,聯合標定使用的標定布都會引入誤差。這些誤差會導致生成的鳥瞰圖在重疊區域有一些偏移。第4小節中的拼接融合模塊是為了讓鳥瞰圖在覆蓋區域過渡平滑,盡量避免偽影現象。但是我們不能將這個壓力全部施加給拼接融合模塊。因此需要在拼接融合模塊之前,對鳥瞰圖進行微調,這個微調功能是供客戶或者4S店人員進行手動調節的。
在調研中發現,現在很多部署在車上的AVM系統都包含有微調功能。但大部分都存在一個問題:只能保證一邊是對齊的,另外一邊拼不齊。例如,前面對齊后面對不齊。
作者使用了[4],將前、后微調光流圖進行融合,得到一個平緩過渡的光流圖,兼顧了前后兩側的微調。以左俯視圖為例,算法流程如下:
固定住前、后兩個鳥瞰圖
手動微調左鳥瞰圖,使左鳥瞰圖與前鳥瞰圖之間的重疊區域貼合。記錄微調矩陣M1,并根據矩陣計算光流map1
手動微調左鳥瞰圖,使左鳥瞰圖與后鳥瞰圖之間的重疊區域貼合。記錄微調矩陣M2,并根據矩陣計算光流map2
根據像素距離計算map1與map2的權重圖w,即距離前鳥瞰圖越近,map1的權重越大,反之則越小
使用w對map1和map2進行加權融合
當微調矩陣M1和M2方向正好相反時,這個基于光流的思想可以很好地將兩者融合,因為矩陣變換是比較“硬”的一種數學方法,而光流卻像水一樣的“軟”。
左側為普通的融合效果 右側為基于光流思想微調后的效果
可以看出這個方法可以兼顧前、后的微調效果。可以理解為將拼接區域的誤差均攤給中間的區域,而中間這部分區域不存在拼接融合的問題,而且我們在泊車的過程中更注重的是車與周圍物體的相對位置而非周圍物體的精確位置,因此實際看上去也沒什么問題。
最終的2D AVM 效果展示:
2D AVM Demo
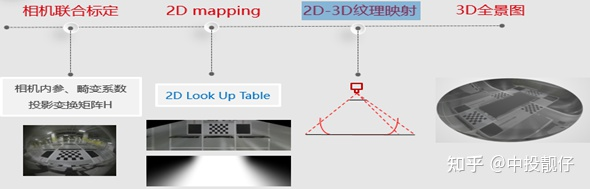
2.6三維模型紋理映射
2D的AVM算法是基于投影變換,將魚眼圖像投影到鳥瞰圖上。而單應變換有一個前提:就是平面假設。是把一個平面投影到另外一個平面。存在的問題是:圖像中所有的三維物體,例如汽車、柱子、墻,全部被當成平面來處理。這些內容在鳥瞰圖上會被拉的很長
安裝在車身周圍的魚眼相機是單目相機,單目相機不能獲取三維物體的深度。在圖形學中有一種真實感增強的方法:制作一個三維模型,把二維的紋理貼圖以某種方式映射到三維模型上,3D AVM正是使用了這個紋理映射技術,為駕駛員呈現出一個偽3D的效果。
2.6.1 AVM 3D模型構建
3D模型是由一個個小面片構成的,可以是三角面片、多邊形面片等等。面片又是由多個頂點構成的,例如三角面片對應的就是3個頂點。
3dsMax三維模型
放大看可以看到,3D模型是由很多個小的多邊形面片構成。3D模型的文件形式有很多種,但大體上都是包含:模型頂點、面片、紋理坐標、法向量這些三維信息。具體如何使用3dsMax來制作3D模型,就不敘述了,作者不是專業的美工,方法可能不太聰明,領會精即可。
AVM 3D模型是一個碗狀的三維模型。模擬駕駛員視角,即汽車周圍附近是路面,這部分直接映射到碗底平面上;而距離汽車較遠的位置可能是樓房、樹木、墻等三維物體,這部分內容將使用某種方式映射到三維點上。下面展示的就是我們的3d模型中的必要信息,包含頂點坐標、紋理坐標、法向量、三角面片索引。
//頂點坐標 v 166.2457 190.1529 575.8246 v 169.0261 192.6147 575.0482 v 163.5212 194.2559 576.8094 v 160.4214 177.1097 576.3941 v 160.5880 183.6252 577.0156 ...... //紋理坐標 vt 0.227618 0.463987 vt 0.254011 0.468448 vt 0.251903 0.470549 vt 0.248436 0.466586 vt 0.267204 0.509296 ...... //法向量信息 vn 0.3556 -0.4772 -0.8036 vn 0.3606 -0.4537 -0.8149 vn 0.3145 -0.3999 -0.8609 vn 0.3101 -0.3998 -0.8626 vn 0.3170 -0.3811 -0.8685 ...... //三角面片信息 f 5825/5825/4368 5826/5826/4369 5827/5827/4370 f 5828/5828/4371 5829/5829/4372 5830/5830/4373 f 5831/5831/4374 5832/5832/4375 5833/5833/4376 f 5834/5834/4377 5835/5835/4378 5836/5836/4379 f 5837/5837/4380 5838/5838/4381 5839/5839/4382
2.6.2 三維模型紋理映射
這一小節講述的是:
(1)紋理映射是從哪里映射到哪里
(2)采用哪種策略進行映射
我們的最終目標是:找到3d模型上每個頂點對應在魚眼2d圖像上的紋理坐標。
作者采用的是一種基于虛擬相機思想的3d紋理映射方法[5],如圖所示:
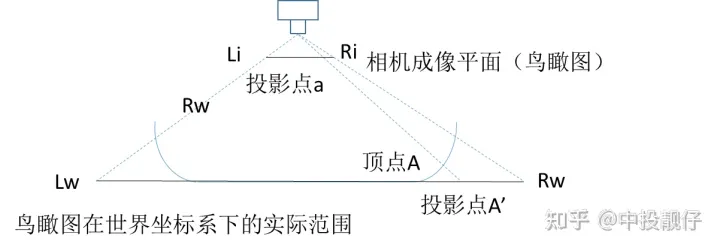
基于虛擬相機思想的3d紋理映射模型
假設2D AVM的全景鳥瞰圖是由汽車正上方某個虛擬相機拍攝到的圖,將其當作2D紋理,以透視投影的方法映射到3d模型上面。圖中Lw-Rw為全景俯視圖,虛擬相機與頂點A的直線在鳥瞰圖上的交點為A',從而得到A頂點對應的2D紋理映射坐標A'。然后通過逆投影變換H_inverse、畸變mapx、mapy查找到3d模型的頂點A在魚眼相機上的紋理坐標。遍歷3d模型上的每一個點,即可得到三維模型與魚眼相機紋理坐標之間的映射關系:
根據透視投影原理,計算頂點A對應的鳥瞰圖紋理A'
使用矩陣變換和單應變換逆推A'在去畸變圖上的坐標A1
通過去畸變的查找表map查找A1在魚眼相機畸變圖上的坐標
遍歷上述過程,即可得到3D模型上所有頂點對應魚眼圖上的紋理坐標
具體流程如圖所示:

3d模型紋理映射流程
看下效果:這個模型的法向量是反的,所以渲染的結果光線有問題,非常的暗。不過可以看到偽3D的真實感增強效果,領會精神即可。

右側模型映射
2.6.3 三維融合
實際上作者使用的是前、后、左、右4個曲面模型,這4個曲面模型與4路魚眼圖像一一對應,這樣做是為了增加OpenGl渲染的并行,避免在做拼接融合時用到if、else這些判斷語句。上圖中的3d模型就是左側魚眼相機對應的曲面模型。
我們先來回顧2D AVM的做法:生成鳥瞰圖,然后做融合。我們當時生成的鳥瞰圖大小為10801080,這個分辨率等同于現實世界中的1080cm1080cm,足以顯示車身周圍。但是,這個范圍最多只能映射到3d碗模型的底部附近區域,如下圖:忽略邊上的鋸齒,那是渲染時插值的bug,先不去管他。從這圖可以看出:如果鳥瞰圖選的很小,會導致只映射到碗的底部。

小鳥瞰圖映射到模型上
我們把鳥瞰圖的尺寸放大,可以看到:

大鳥瞰圖映射到模型上
圖1為左側魚眼相機去畸變后的圖像,圖2是由圖1做投影變換得到的鳥瞰圖,圖3為映射到左側模型后的結果
這里要注意:在算法實現上不可以像2D AVM那樣,去真正地生成一個鳥瞰圖。從鳥瞰圖我們不難看出,在遠離棋盤格的部分被嚴重拉長,而圖1中接近消失點、消失線的那些像素在鳥瞰圖上將會被拉到無窮遠。可以這樣理解,圖一中的消失點、消失線表示:在當前的相機位姿,某一個平面上(例如地面)的點全部在這條消失線以下。而鳥瞰圖相當于我們把相機平行于地面進行拍攝,那么地平面無窮遠處(即1中的消失點、消失線)成像在鳥瞰圖中必然會被拉長到無窮遠處,就像圖2一樣。有興趣的同學可以看看消失點的解釋。
消失點
如果想要將整個碗狀模型填滿紋理,需要生成一個特別大的鳥瞰圖。即需要計算一個特別大的map,這個計算量是巨大的。因此在算法實現上,要選用遍歷模型上的每個頂點,進行逆向紋理映射的方法計算紋理坐標(不再依賴于生成一個鳥瞰圖),頂點之間的空缺將由渲染引擎通過插值的方法進行填充,這個是種成熟的技術。
講了這么多終于說到三維的融合。2D的融合是對鳥瞰圖的覆蓋區域做形態學操作,得到下圖,然后計算權重。而3D的算法強調的是離散點的思維,不會再生成一個超級大的鳥瞰圖。換句話說,算法不會再計算一個像下圖一樣覆蓋區域的圖像。因此,要尋找其他的方式來解決3D融合的問題。
左上角重疊區域
如圖所示[6]:
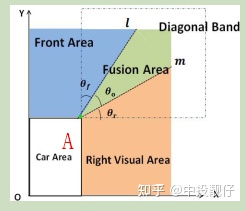
右上方重疊區域示意圖
大概思路就是計算3D頂點對應鳥瞰圖的紋理坐標B。通過AB與m、l的夾角與θ0計算權重。
當然,重疊區域不可能這么理想,這個論文中的示意圖l和m正好交于A點。實際情況是它上面那個圖的樣子。需要使用某種專門針對3D AVM融合的策略來實現之[7]。將3D模型頂點對應的權重圖映射到二維的示意圖:

放大看
總體來講,3D AVM算法就是先搞一個3維模型,然后通過紋理映射,將3維模型上的每一個頂點與二維的紋理圖進行綁定。OpenGl利用上述數據進行渲染。最終的3D效果后續會發上來。
03在線階段工程實現pipeline
前面介紹的是離線階段的算法流程,離線階段只有在流水線上或者4s店才會用到,是一個初始化的過程。初始化的內容包括:畸變表、投影變換矩陣、紋理映射關系、拼接融合權重圖等。最重要的是要將去畸變、投影變換、紋理映射這些過程寫入一個查找表,存入內存,在線處理的時候直接調用即可。附上部分代碼,對map做remap這塊可能會稍微難理解一些。
//4個label是鳥瞰圖在avm全景上的位置坐標
for (int i = label1; i < label2; i++)
{
float *map2_x = map2_xR.ptr(i);
float *map2_y = map2_yR.ptr(i);
for (int j = label3; j < label4; j++)
{
Mat vec = (Mat_(3, 1) << j, i, 1);//AVM全景圖的grid網格坐標
vec = matrix * (vec);//獲取鳥瞰圖坐標
Mat coor = Homo_inverse * vec;//從鳥瞰圖反向投影到去畸變圖
map2_x[j] = coor.at(0, 0);
map2_y[j] = coor.at(1, 0);
}
}
//map1(畸變) remap map2(投影+旋轉)
remap(map1_y, my, map2_xR, map2_yR, INTER_LINEAR);
remap(map1_x, mx, map2_xR, map2_yR, INTER_LINEAR);
//畸變+投影+旋轉+finetune
if (finetune)
{
remap(mx, mx, m_finetune_l_blendX, m_finetune_l_blendY, INTER_LINEAR, BORDER_REPLICATE);
remap(my, my, m_finetune_l_blendX, m_finetune_l_blendY, INTER_LINEAR, BORDER_REPLICATE);
}
9.1 2D AVM

2D AVM Pipeline
9.2 3D AVM

3D AVM Pipeline
04其他
另外還有一種做法:通過廠家提供的相機安裝參數計算魚眼相機與同意坐標系(汽車中心)之間的外參,通過外參將3d模型上的頂點坐標轉換到相機坐標系下,再通過相機內參轉換到圖像坐標系上。用此方法同樣可以得到2d圖像紋理與3d模型頂點之間的一一映射關系。這兩種方法的基本思想其實是相通的,殊途同歸。只不過這種方法相機安裝參數會有一些誤差,可能會導致最終的3d拼接效果不佳。
05總結
AVM2D、3D全景環視是一個需要算法理論和實踐強結合的自動駕駛系統,其中涉及到的領域為計算機視覺、圖像增強、三維等。后續作者還會對標定、去畸變等算子進行優化,并加入自標定、車輪視角、廣角、透明底盤等內容。
本文的每個章節都是首先講述基礎理論,再結合實驗demo來進行呈現,盡量避免繁瑣的公式推導,目的在于將AVM系統算法框架搭建的方法講述清楚。如果有不清楚或者哪里說的不夠嚴謹,歡迎大家一起交流進步。
-
代碼
+關注
關注
30文章
4825瀏覽量
69044 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46127 -
AVM
+關注
關注
0文章
12瀏覽量
10743
原文標題:深度解析自動泊車AVM算法框架
文章出處:【微信號:談思實驗室,微信公眾號:談思實驗室】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AVM全車監視系統 360度全景泊車系統
SoC驗證環境搭建方法的研究
國外AVM技術在批量評估中的應用
AVM Based Unified Verification
基于半監督學習框架的識別算法
TensorFlow的框架結構解析






 工商網監
工商網監
評論