") 中國研究人員提出StructGPT,提高LLM對結構化數(shù)據(jù)的零樣本推理能力
中國研究人員提出StructGPT,提高LLM對結構化數(shù)據(jù)的零樣本推理能力
大型語言模型 (LLM) 最近在自然語言處理 (NLP) 方面取得了重大進展。現(xiàn)有研究表明,LLM) 具有很強的零樣本和少樣本能力,可以借助專門創(chuàng)建的提示完成各種任務,而無需針對特定任務進行微調。盡管它們很有效,但根據(jù)目前的研究,LLM 可能會產生與事實知識不符的不真實信息,并且無法掌握特定領域或實時的專業(yè)知識。這些問題可以通過在LLM中添加外部知識源來修復錯誤的生成來直接解決。
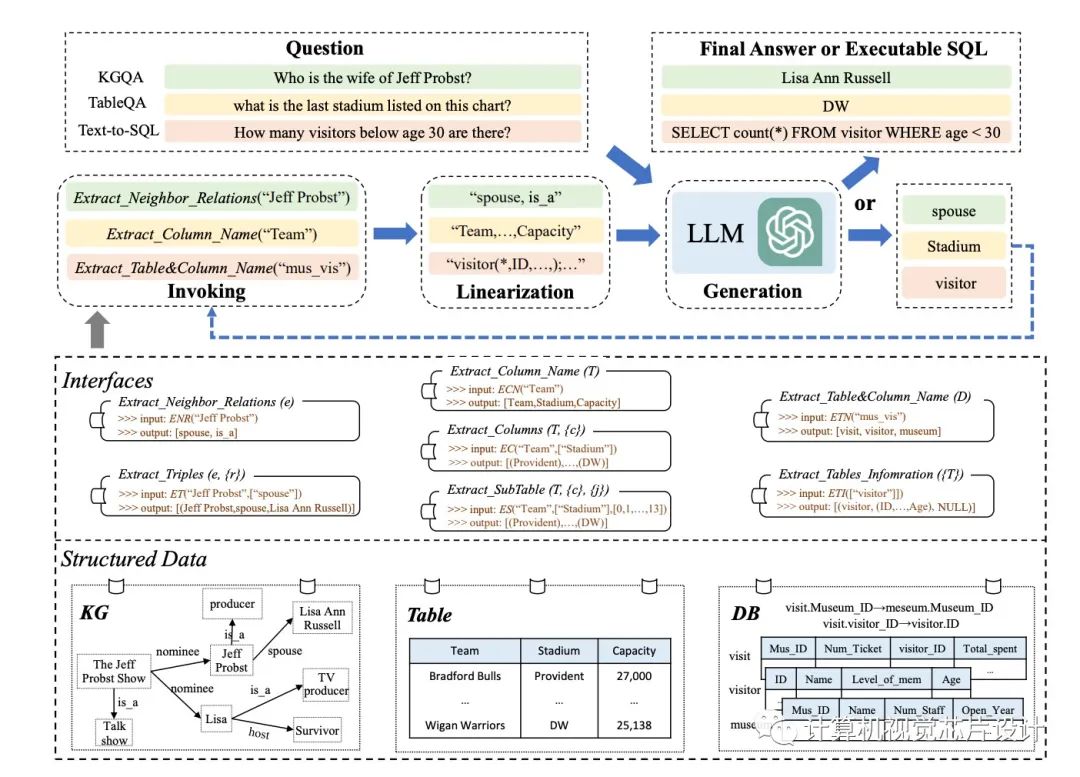
結構化數(shù)據(jù),如數(shù)據(jù)庫和知識圖譜,已被常規(guī)用于在各種資源中攜帶 LLM 所需的知識。但是,由于結構化數(shù)據(jù)使用 LLM 在預訓練期間未接觸過的獨特數(shù)據(jù)格式或模式,因此他們可能需要幫助才能理解它們。與純文本相反,結構化數(shù)據(jù)以一致的方式排列并遵循特定的數(shù)據(jù)模型。數(shù)據(jù)表按行排列為列索引記錄,而知識圖 (KG) 經常組織為描述頭尾實體之間關系的事實三元組。
盡管結構化數(shù)據(jù)的體量往往非常巨大,但不可能容納輸入提示中的所有數(shù)據(jù)記錄(例如,ChatGPT 的最大上下文長度為 4096)。將結構化數(shù)據(jù)線性化為 LLM 可以輕松掌握的語句是解決此問題的簡單方法。工具操作技術激勵他們增強 LLM 解決上述困難的能力。他們策略背后的基本思想是使用專門的接口來更改結構化數(shù)據(jù)記錄(例如,通過提取表的列)。在這些接口的幫助下,他們可以更精確地定位完成特定活動所需的證據(jù),并成功地限制數(shù)據(jù)記錄的搜索范圍。
來自中國人民大學、北京市大數(shù)據(jù)管理與分析方法重點實驗室和中國電子科技大學的研究人員在這項研究中著重于為某些任務設計合適的接口,并將它們用于 LLM 的推理,這些接口是應用界面增強方法需要解決的兩個主要問題。以這種方式,LLM 可以根據(jù)從界面收集的證據(jù)做出決定。為此,他們在本研究中提供了一種稱為 StructGPT 的迭代閱讀然后推理 (IRR) 方法,用于解決基于結構化數(shù)據(jù)的任務。他們的方法考慮了完成各種活動的兩個關鍵職責:收集相關數(shù)據(jù)(閱讀)和假設正確的反應或為下一步行動制定策略(推理)。
據(jù)他們所知,這是第一項著眼于如何使用單一范式幫助 LLM 對各種形式的結構化數(shù)據(jù)(例如表、KG 和 DB)進行推理的研究。從根本上說,他們將 LLM 的閱讀和推理兩個過程分開:他們使用結構化數(shù)據(jù)接口來完成精確、有效的數(shù)據(jù)訪問和過濾,并依靠他們的推理能力來確定下一步的行動或查詢的答案。
對于外部接口,他們特別建議調用線性化生成過程,以幫助 LLM 理解結構化數(shù)據(jù)并做出決策。通過使用提供的接口重復此過程,他們可能會逐漸接近對查詢的期望響應。
他們對各種任務(例如基于知識圖譜的問答、基于表的問答和基于數(shù)據(jù)庫的文本到 SQL)進行了全面試驗,以評估其技術的有效性。八個數(shù)據(jù)集的實驗結果表明,他們建議的方法可能會顯著提高 ChatGPT 在結構化數(shù)據(jù)上的推理性能,甚至達到與全數(shù)據(jù)監(jiān)督調優(yōu)方法競爭的水平。
? KGQA。他們的方法使 KGQA 挑戰(zhàn)的 WebQSP 上的 Hits@1 增加了 11.4%。借助他們的方法,ChatGPT 在多跳 KGQA 數(shù)據(jù)集(例如 MetaQA-2hop 和 MetaQA-3hop)中的性能可能分別提高了 62.9% 和 37.0%。
? 質量保證表。在 TableQA 挑戰(zhàn)中,與直接使用 ChatGPT 相比,他們的方法在 WTQ 和 WikiSQL 中將標注準確度提高了大約 3% 到 5%。在 TabFact 中,他們的方法將表格事實驗證的準確性提高了 4.2%。
? 文本到SQL。在 Text-to-SQL 挑戰(zhàn)中,與直接使用 ChatGPT 相比,他們的方法將三個數(shù)據(jù)集的執(zhí)行準確性提高了約 4%。
作者已經發(fā)布了 Spider 和 TabFact 的代碼,可以幫助理解 StructGPT 的框架,整個代碼庫尚未發(fā)布。
審核編輯 :李倩
-
數(shù)據(jù)管理
+關注
關注
1文章
300瀏覽量
19677 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13646 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7740 -
LLM
+關注
關注
0文章
299瀏覽量
400
原文標題:中國研究人員提出StructGPT,提高LLM對結構化數(shù)據(jù)的零樣本推理能力
文章出處:【微信號:計算機視覺芯片設計,微信公眾號:計算機視覺芯片設計】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
結構化布線系統(tǒng)有哪些難題
泰克儀器助力研究人員首次通過太赫茲復用器實現(xiàn)超高速數(shù)據(jù)傳輸
TrustZone結構化消息是什么?
白光LED結構化涂層制備及其應用研究
什么叫結構化的算法_算法和結構化數(shù)據(jù)初識
融合零樣本學習和小樣本學習的弱監(jiān)督學習方法綜述

形狀感知零樣本語義分割
一個通用的自適應prompt方法,突破了零樣本學習的瓶頸

基準數(shù)據(jù)集(CORR2CAUSE)如何測試大語言模型(LLM)的純因果推理能力
什么是零樣本學習?為什么要搞零樣本學習?
跨語言提示:改進跨語言零樣本思維推理

什么是LLM?LLM的工作原理和結構
LLM大模型推理加速的關鍵技術
使用ReMEmbR實現(xiàn)機器人推理與行動能力





 工商網監(jiān)
工商網監(jiān)
評論