") 計(jì)算機(jī)組成原理—非數(shù)值型數(shù)據(jù)的表示
計(jì)算機(jī)組成原理—非數(shù)值型數(shù)據(jù)的表示
2.2 非數(shù)值型數(shù)據(jù)的表示
非數(shù)值的文字和其他符號(hào)也要數(shù)字化為二進(jìn)制編碼表示。
2.2.1 字符和字符串
1.ASCII碼:American Standard Code for Information Interchange,美國(guó)信息交換標(biāo)準(zhǔn)代碼。
ASCII碼由7位二進(jìn)制數(shù)碼組成。
字符的具體ASCII編碼見教材P36表2-1所示。
常用的:
- 0~9的ASCII碼:30H ~ 39H
- A~Z的ASCII碼:41H ~ 5AH
- a~z的ASCII碼:61H ~ 6AH
將ASCII碼的最高位置0或一位奇偶校驗(yàn)位,存儲(chǔ)時(shí)占一個(gè)字節(jié)。
2.字符串及其存儲(chǔ)
以ASCII碼形式在主存中占用連續(xù)的多個(gè)字節(jié)。
當(dāng)主存的字長(zhǎng)是多個(gè)字節(jié)時(shí),同一主存字中可以按從低位字節(jié)向高位字節(jié)順序存放字符串,也可以按從高位字節(jié)向低位字節(jié)的次序存放字符串。
如:字長(zhǎng)為4字節(jié)的主存,存放字符串“IF? A>B ? THEN ? X=2”,可以是如下兩種存放形式:
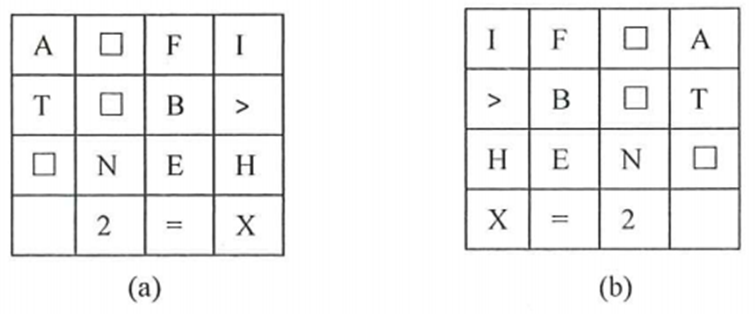
2.2.2 漢字的表示
三種類型的編碼
漢字在計(jì)算機(jī)中存儲(chǔ)、傳輸、交換、輸出,需要有輸入、內(nèi)部處理和輸出三種類型的編碼。
1.漢字國(guó)標(biāo)碼、區(qū)位碼
國(guó)標(biāo)碼是我國(guó)在1981年公布的GB2312-80編碼,主要用于漢字信息處理系統(tǒng)或者通信系統(tǒng)之間交換信息。
規(guī)定:一個(gè)漢字用兩個(gè)字節(jié)表示,每個(gè)字節(jié)只用低七位編碼,最高位為0,未作定義。最多能夠表示出128′128=16384個(gè)漢字。目前,國(guó)標(biāo)碼共收集了6763個(gè)常用漢字。
GB2312-80碼將漢字分成94個(gè)區(qū),每個(gè)區(qū)又包含94個(gè)位,每個(gè)漢字對(duì)應(yīng)一個(gè)區(qū)號(hào)和位號(hào),也常稱為區(qū)位碼。
例如:漢字“青”在39區(qū)64位,其區(qū)位碼是3964;漢字“島”在21區(qū)26位,其區(qū)位碼是2126。
2.漢字機(jī)內(nèi)碼
簡(jiǎn)稱內(nèi)碼,是漢字在計(jì)算機(jī)內(nèi)部進(jìn)行存儲(chǔ)、交換、檢索等操作的一種代碼,一般采用兩字節(jié)表示。
國(guó)標(biāo)碼每個(gè)字節(jié)的最高位都是“0”,與ASCII碼無法區(qū)分。
例如:兩個(gè)字節(jié)內(nèi)容是30H和21H時(shí),可以認(rèn)為是一個(gè)漢字“啊”的國(guó)標(biāo)碼,也可以理解為兩個(gè)英文字符“0”和“!”的ASCII碼。
將國(guó)標(biāo)碼的兩個(gè)字節(jié)的最高位設(shè)定為1,得到相應(yīng)的機(jī)內(nèi)碼。
例如,漢字“啊”的機(jī)內(nèi)碼是:10110000 10100001
3.漢字的輸入編碼
目前常用的輸入編碼方法有以下幾種:
(1)數(shù)字編碼:常用的區(qū)位碼。每輸入一個(gè)漢字需按4次鍵。
無重碼,與內(nèi)碼之間的轉(zhuǎn)換方便,代碼難記憶。
(2)拼音碼:輸入重碼率很高,影響輸入的速度。
改進(jìn):增加智能聯(lián)想功能,提高輸入速度。
(3)字形編碼:五筆字型編碼是一種最有影響的字形編碼。
上述都是利用鍵盤進(jìn)行“手動(dòng)”輸入。理想的輸入方式是利用語音或圖像識(shí)別技術(shù)“自動(dòng)”將漢字輸入到計(jì)算機(jī)內(nèi),使計(jì)算機(jī)能認(rèn)識(shí)漢字、聽懂漢語,并將其自動(dòng)轉(zhuǎn)換為機(jī)內(nèi)碼。目前寫字板手寫輸入,語音輸入,掃描儀識(shí)別文字輸入等。
4.漢字字模碼
用點(diǎn)陣表示漢字字形的編碼實(shí)現(xiàn)輸出漢字(顯示或打印)。
16×16點(diǎn)陣表示的漢字“英”的編碼:
字模點(diǎn)陣占用的存儲(chǔ)空間很大,一般只能用來構(gòu)成漢字庫(kù),而不用于機(jī)內(nèi)存儲(chǔ)。當(dāng)顯示或打印輸出時(shí)檢索字庫(kù),輸出字模點(diǎn)陣,得到字形。
采用字形數(shù)據(jù)壓縮技術(shù)節(jié)省存儲(chǔ)空間。如矢量漢字采用矢量方法,將漢字點(diǎn)陣字模進(jìn)行壓縮。

2.2.3 Unicode編碼
- code編碼也被稱為統(tǒng)一代碼,適用于世界上所有語言。
- Unicode的每一個(gè)字符采用2個(gè)字節(jié),可以表示65536個(gè)不同字符。兼顧已存在的編碼方案,前128個(gè)字符編碼0000h~007Fh與ASCII碼字符一致。
- 這種編碼方式對(duì)國(guó)際商業(yè)和通訊來說非常有用。
- Unicode還適合于軟件的本地化,即針對(duì)特定的國(guó)家修改軟件:使用Unicode,軟件開發(fā)人員可以修改屏幕的提示、菜單和錯(cuò)誤信息,以適用于不同的語言和地區(qū)。
- Unicode編碼在Internet中有著較為廣泛的使用
2.3 其他信息的數(shù)字化
語音、圖像、圖形等信息在計(jì)算機(jī)中的二進(jìn)制編碼的形式。
1.語音信息的數(shù)字化
語音是一種模擬信號(hào),不能直接進(jìn)入計(jì)算機(jī)存儲(chǔ)。需經(jīng)過對(duì)聲音信號(hào)進(jìn)行采樣和量化后才能進(jìn)入計(jì)算機(jī)存儲(chǔ)。
(1)采樣:由麥克風(fēng)、錄音機(jī)等錄音設(shè)備把語音信號(hào)變成頻率、幅度連續(xù)變化的電流信號(hào),經(jīng)過采樣得到一組與聲音信號(hào)幅值相對(duì)應(yīng)的離散的數(shù)值,其包含了聲音信號(hào)的頻率和幅值的特征信息。
(2)量化:將采樣得到的聲音的離散的數(shù)據(jù)值換成一個(gè)n位二進(jìn)制的數(shù)字量。
(3)編碼:對(duì)量化后的二進(jìn)制數(shù)字按照一定的格式進(jìn)行編碼,形成相應(yīng)格式的文件存儲(chǔ)。為了方便存儲(chǔ)或傳輸,音頻信息通常還要進(jìn)行壓縮。常用的聲音文件格式有mp3、mav、midi等。
2.圖像信息的數(shù)字化
- 一幅圖像可以看作是由一個(gè)個(gè)像素點(diǎn)構(gòu)成。
- 圖像的數(shù)字化,就是對(duì)每個(gè)像素點(diǎn)的灰度值進(jìn)行采樣、量化,再進(jìn)行編碼的過程。
- 常用圖像信息的文件格式有bmp、gif、jpg等。
3.圖形信息的數(shù)字化
- 圖形的基本元素是圖元,只需要知道圖元的幾個(gè)特征數(shù)據(jù)就可以通過圖形指令進(jìn)行描述。
- 比如,只需要知道半徑和圓心就能畫出圓的圖形。
- 圖形信息只需要存儲(chǔ)包含的各圖元指令,所以占用的存儲(chǔ)空間比位圖圖像小許多。
-
二進(jìn)制
+關(guān)注
關(guān)注
2文章
796瀏覽量
41757 -
通信系統(tǒng)
+關(guān)注
關(guān)注
6文章
1204瀏覽量
53460 -
模擬信號(hào)
+關(guān)注
關(guān)注
8文章
1143瀏覽量
52643 -
ASCII碼
+關(guān)注
關(guān)注
0文章
51瀏覽量
17351
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
計(jì)算機(jī)組成原理與單片機(jī)原理
計(jì)算機(jī)的組成原理是什么?
計(jì)算機(jī)組成原理基礎(chǔ)知識(shí)
計(jì)算機(jī)組成原理是什么
計(jì)算機(jī)組成原理
計(jì)算機(jī)組成原理簡(jiǎn)答題及答案
計(jì)算機(jī)組成原理mooc期末測(cè)試
計(jì)算機(jī)組成原理 精選資料分享
計(jì)算機(jī)組成原理
計(jì)算機(jī)組成原理各章復(fù)習(xí)重點(diǎn),計(jì)算機(jī)組成原理復(fù)習(xí)要點(diǎn)說明.doc 精選資料分享
計(jì)算機(jī)組成原理試卷及答案
計(jì)算機(jī)組成原理——數(shù)值型數(shù)據(jù)的表示





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論