 華為諾亞提出VanillaNet:一種新視覺Backbone,極簡且強大!
華為諾亞提出VanillaNet:一種新視覺Backbone,極簡且強大!
導讀
簡到極致、淺到極致!深度為6的網絡即可取得76.36%@ImageNet的精度,深度為13的VanillaNet甚至取得了83.1%的驚人性能。

VanillaNet: the Power of Minimalism in Deep Learning
論文地址:https://arxiv.org/abs/2305.12972
代碼地址:https://github.com/huawei-noah/VanillaNet
簡而淺的直桶狀網絡具有非常優秀的推理效率,但其訓練難度較高,難以取得優異性能。自AlexNet與VGG之后,鮮少有這種"直桶"狀且性能優異的網絡出現,其中的代表當屬RepVGG與ParNet。
- 通過引入結構重參數機制,RepVGG將"直桶狀"網絡重新煥發生機。但RepVGG的深度仍然有20+的深度,感興趣的同學可以查看讓你的ConvNet一卷到底,清華&曠視提出CNN設計新思路RepVGG
- 后來,Princeton大學的鄧嘉團隊提出了深度為12的網絡并在ImageNet數據集上達到了80.7%,但引入的注意力導致了額外的跳過連接,仍為達到極限推理效率。對ParNet一文感興趣的同學可查閱12層也能媲美ResNet?鄧嘉團隊提出最新力作ParNet,ImageNet top1精度直沖80.7%
就在這樣的環境下,簡到極致、淺到極致的網絡VanillaNet誕生了!!!深度為6的網絡即可取得76.36%@ImageNet的精度,深度為13的VanillaNet甚至取得了83.1%的驚人性能。
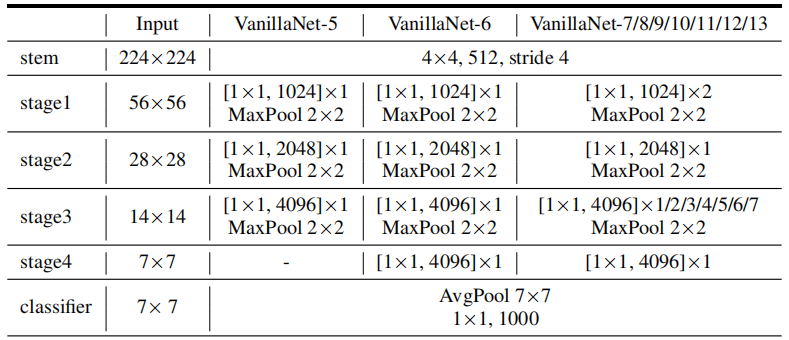
網絡架構
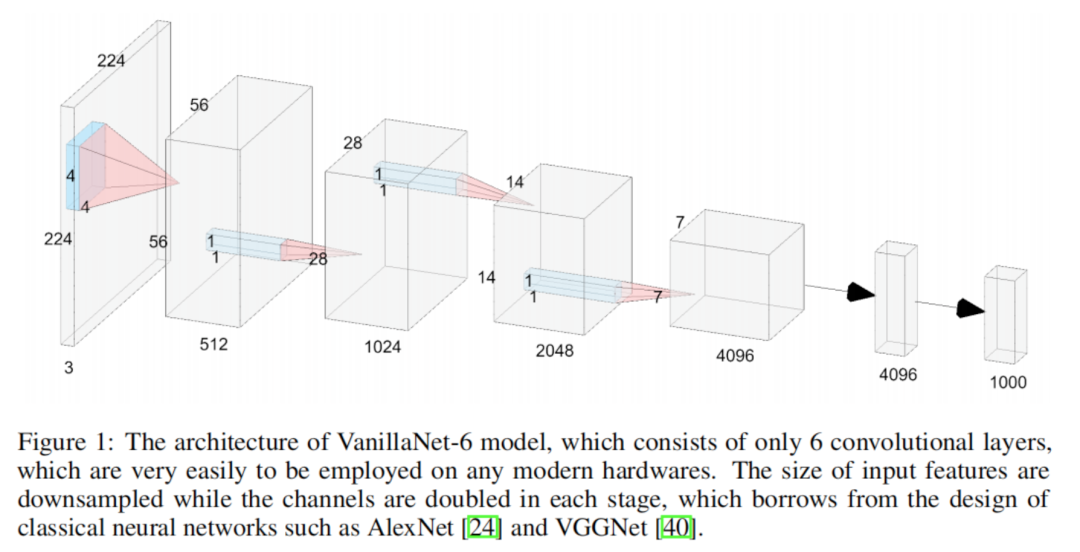
上圖給出了本文所提VanillaNet架構示意圖,有沒有覺得簡到極致了。
- 對于Stem部分,采用卷積進行特征變換;
- 對于body部分的每個stage,首先采用MaxPool進行特征下采樣,然后采用一個進行特征處理;
- 對于head部分,采用兩個非線性層進行分類處理。
值得注意的是,(1) 每個stage只有一個卷積;(2)VanillaNet沒有跳過連接。
盡管VanillaNet非常簡單且足夠淺,但其弱非線性能力會限制其性能。為此,作者從訓練策略與激活函數兩個維度來解決該問題。
訓練策略
在訓練階段,通過引入更強的容量來提升模型性能是很常見的。由于更深的網絡具有比淺層網絡更強的非線性表達能力,作者提出在訓練階段采用深度訓練技術為VanillaNet帶來更強的性能。
深度訓練策略
對于激活函數,我們將其與Identity進行組合,公式如下:
其中,是用于平衡非線性能力的超參數。假設當前epoch與總訓練Epoch分別表示為,那么定義。因此,在訓練初始階段,該修正版激活函數等價于原始激活函數,即,此時網絡具有較強的非線性表達能力;伴隨訓練收斂,修正版激活函數退化為Identity,即,這就意味著兩個卷積之間就不再有激活函數。
接下來,我們在說明一下如何合并兩個卷積層(在DBB一文中已有了非常詳細的公式介紹,而且對各種可折疊操作進行了非常詳細的介紹)。
我們先來介紹BN與前接卷積之間的合并方式。假設表示卷積的參數,BN層的參數分別表示為,合并后的參數表示如下:
在完成卷積與BN合并后,我們介紹如何合并兩個卷積。令分別表示輸入與輸出特征,卷積可表示如下:
基于上述卷積表示,我們可以將兩個連續卷積表示如下:
因此,兩個連續卷積可以進行合并且不會造成推理速度提升。
SIAF(Series Informed Activation Function)
盡管已有諸多非線性激活函數,如ReLU、PReLU、GeLU、Swish等,但這些它們主要聚焦于為深而復雜的網絡帶來性能提升。已有研究表明:簡而淺網絡的有限能力主要源于其弱非線性表達能力。
事實上,有兩種方式可用于改善神經網絡的非線性表達能力:堆疊非線性激活層、提升激活函數的非線性表達能力。現有方案往往采用了前者,前者往往會導致更高的推理延遲;而本文則聚焦于后者,即改善激活函數的非線性表達能力。
改善激活函數非線性能力能力的最直接的一種方式為stacking,序列堆疊也是深層網絡的核心。不同與此,作者提出了共生(concurrently)堆疊方式,可表示如下:
其中,n表示堆疊激活函數的數量,表示每個激活的scale與bias參數以避免簡單的累加。通過該處理,激活函數的非線性表達能力得到了大幅提升。
為進一步豐富表達能力,參考BNET,作者為其引入了全局信息學習能力,此時激活函數表示如下:
可以看到,當時,。也就是說,所提激活函數是現有激活函數的一種廣義擴展。因其推理高效性,作者采用ReLU作為基激活函數。
以卷積作為參考,作者進一步分析了所提激活函數的計算復雜度。卷積的計算復雜度可表示如下:
所提激活函數的計算復雜度表示為:
進而可以得出兩者之間的計算復雜度比例關系如下:
以VanillaNet-B第4階段為例,,該比例約為84,也就是說,所提激活函數的計算復雜度遠小于卷積。
classactivation(nn.ReLU):
def__init__(self,dim,act_num=3,deploy=False):
super(activation,self).__init__()
self.deploy=deploy
self.weight=torch.nn.Parameter(torch.randn(dim,1,act_num*2+1,act_num*2+1))
self.bias=None
self.bn=nn.BatchNorm2d(dim,eps=1e-6)
self.dim=dim
self.act_num=act_num
weight_init.trunc_normal_(self.weight,std=.02)
defforward(self,x):
ifself.deploy:
returntorch.nn.functional.conv2d(
super(activation,self).forward(x),
self.weight,self.bias,padding=(self.act_num*2+1)//2,groups=self.dim)
else:
returnself.bn(torch.nn.functional.conv2d(
super(activation,self).forward(x),
self.weight,padding=(self.act_num*2+1)//2,groups=self.dim))
def_fuse_bn_tensor(self,weight,bn):
kernel=weight
running_mean=bn.running_mean
running_var=bn.running_var
gamma=bn.weight
beta=bn.bias
eps=bn.eps
std=(running_var+eps).sqrt()
t=(gamma/std).reshape(-1,1,1,1)
returnkernel*t,beta+(0-running_mean)*gamma/std
defswitch_to_deploy(self):
kernel,bias=self._fuse_bn_tensor(self.weight,self.bn)
self.weight.data=kernel
self.bias=torch.nn.Parameter(torch.zeros(self.dim))
self.bias.data=bias
self.__delattr__('bn')
self.deploy=True
本文實驗
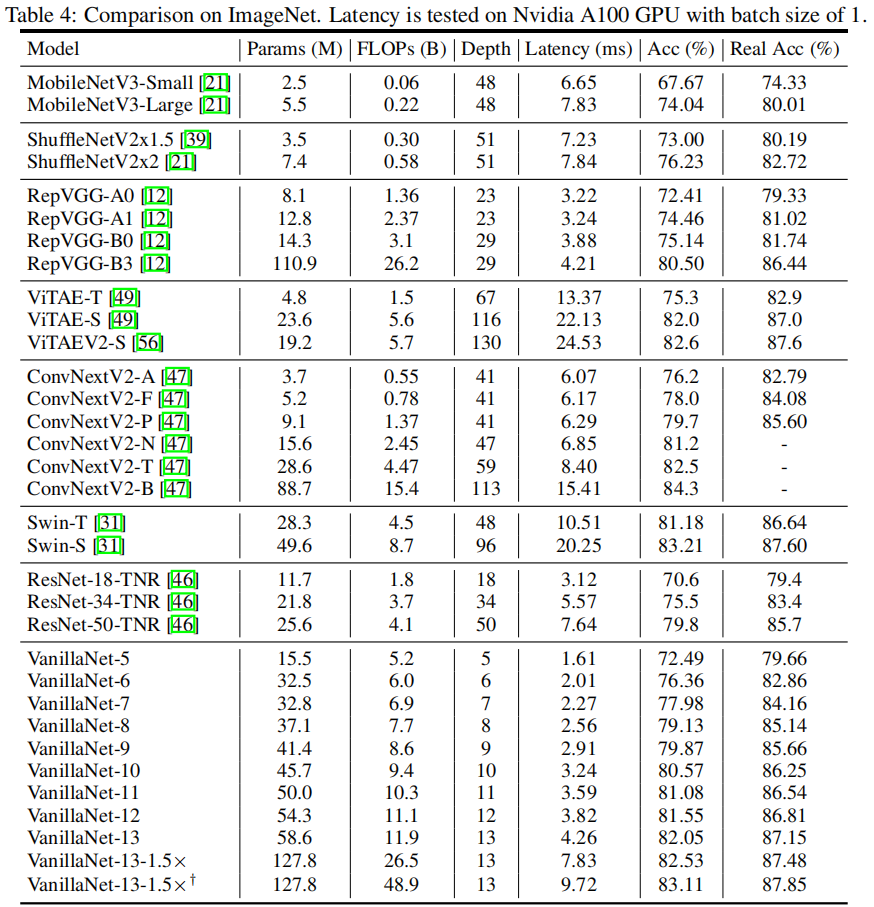
在過去幾年里,研究人員往往假設計算資源非常有限,依托ARM/CPU平臺,聚焦于減少網絡的FLOPs與推理延遲。但是,伴隨著AI芯片的研發進展,像自動駕駛等設備往往攜帶多個GPU以期獲取實時反饋。因此,本文的延遲基于bs=1進行測試,而非常規的吞吐量。基于此配置,作者發現:模型的推理速度與FLOPs、Params的相關性極低。
- 以MobileNetV3-Large為例,盡管其具有非常低的FLOPs,但其GPU延遲為7.83,遠高于VanillaNet13。這種配置的推理速度與復雜度和層數強相關;
- 對比ShuffleNetV2x1.5與ShuffleNetV2x2,盡管其參數量與FLOPs差別很大,但推理速度基本相同(7.23 vs 7.84);
- 對比ResNet,VGGNet與VanillaNet可以看到:無額外分支與復雜模塊的的VGGNet、VanillaNet具有更高的推理速度。
基于上述分析,作者提出了VanillaNet這樣簡到極致,無任何額外分支,層數更少的架構。如上表所示,
- VanillaNet9取得了79.87%的精度,推理速度進而2.91ms,比ResNet50、ConvNeXtV2-P快50%;
- 當擴展至VanillaNet13-1.5x后,甚至取得了83.11%的指標。
這是不是意味著在ImageNet分類任務上,我們并不需要深而復雜的網絡呢???
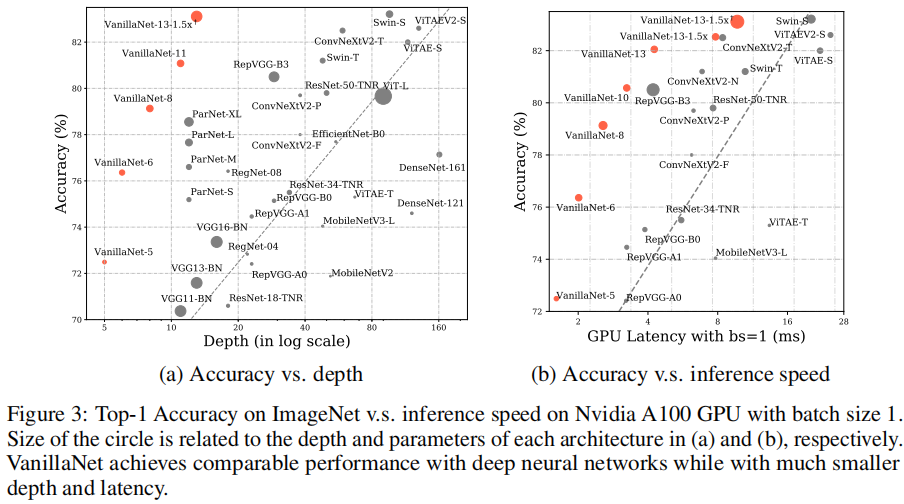
上圖給出了不同架構深度與推理速度之間的關系圖,可以看到:
- 當bs=1時,推理速度與網絡的深度強相關,而非參數量。這意味著:簡而淺的網絡具有巨大的實時處理潛力。
- 在所有網絡中,VanillaNet取得了最佳的速度-精度均衡。這進一步驗證了:在計算資源充分時所提VanillaNet的優異性。
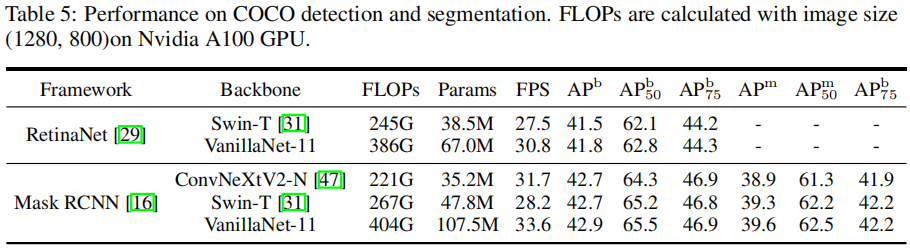
按照國際慣例,最后附上COCO檢測任務上的對比,見上表。可以看到:所提VanillaNet取得了與ConvNeXt、Swin相當的性能。盡管VanillaNet的FLOPs與參數量更多,但其推理速度明顯更快,進一步驗證了VanillaNet在下游任務的有效性。
最后附上不同大小模型的配置信息,參考如下。
全文到此結束,更多消融實驗建議查看原文。
審核編輯 :李倩
-
數據集
+關注
關注
4文章
1209瀏覽量
24835 -
cnn
+關注
關注
3文章
353瀏覽量
22336
原文標題:華為諾亞提出VanillaNet:一種新視覺Backbone,極簡且強大!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
還在為非標項目單獨開發視覺軟件?你out了!labview通用視覺框架,真香!
求大佬分享一種基于毫米波雷達和機器視覺的前方車輛檢測方法
一種結構化道路環境中的視覺導航系統詳解
諾亞音樂球與諾亞光感器的發布,智能音樂時代就在不遠的將來
一種改進的視覺詞袋方法
華為發布“極簡5G”建設策略_助力5G發展進入快車道
華為提出“極簡、智能、開放”站點策略,助力加速5G商用部署
天津聯通正在打造極簡架構的5G共享網絡
CurcveLane-NAS:華為&中大提出一種結合NAS的曲線車道檢測算法

谷歌提出PaLI:一種多模態大模型,刷新多個任務SOTA!

基于M55H的定制化backbone模型AxeraSpine






 工商網監
工商網監
評論