 攻克量子計算不可靠難題,IBM用誤差緩解得到有用計算,登Nature封面
攻克量子計算不可靠難題,IBM用誤差緩解得到有用計算,登Nature封面
面對量子計算中存在的不可靠難題,IBM 找到了全新的解決方案。
一直以來,量子計算與傳統計算相比,量子計算在某些問題上提供了比傳統計算更快的速度,然而在采用量子計算的過程中存在一個巨大的問題,即這些系統存在固有的噪聲,就像聲音會在嘈雜的錄音中丟失一樣。這些噪聲以一種不可預測的方式改變波函數不同分支的相位,不利于量子計算的成功。因而研究人員尚未構建出性能普遍優于所有傳統計算機的計算機。
對于如何管理量子計算存在的不可靠問題,現在大家比較接受的解決方案是采用容錯量子電路,但這對當前的處理器又提出一個重大的挑戰。
當前的量子處理器存在很大的誤差問題,雖然在許多情況下出現誤差的概率很小,通常低于 1%,但我們在每個量子比特上執行的每個操作,包括讀取其狀態這樣的基本操作,都會帶來顯著的誤差率。假如我們正在執行的操作需要很多量子比特,又或者我們需要在很少的量子比特上執行大量的操作,這些操作都會不可避免的帶來誤差。
從長遠來看,采用糾錯量子比特(error-corrected qubits)是一個很好的解決方案。然而采用這種方法需要很多高質量的量子比特來存儲每一位信息,這也意味著我們需要成千上萬的量子比特,然而,依據目前的技術,研究人員所能操作的量子數遠低于需要的量子數,毫不夸張的說我們最早要在下個十年才能實現。
今天,IBM 的一項研究登上《Nature》封面,結果表明即使是嘈雜的量子計算機,其計算也可以比傳統機器更準確。他們利用一種稱為「誤差緩解(error mitigation)」的技術,成功地克服了當今量子比特存在的問題,盡管系統存在噪聲,但也生了準確的結果。而且,他們以一種明顯優于經典計算機的方式做到了這一點。現在 IBM 的 Eagle 量子計算機完成的計算,曾經難倒了與之對戰的傳統超級計算機。

具體來講,IBM 物理學家 Abhinav Kandala 及其合著者對每個量子比特的噪聲進行了精確測量,而這些噪聲遵循相對可預測、并由它們在設備內位置、制造中微觀缺陷和其他因素決定的模式。利用這些知識,研究者推斷出測量結果,并觀察二維固體完整磁化狀態在沒有噪聲的情況下是什么樣子。然后他們能夠運行涉及 Eagle 所有 127 個量子比特和多達 60 個處理步驟的計算,這要比任何其他報道的量子計算實驗都要多。
論文地址:https://www.nature.com/articles/s41586-023-06096-3
結果表明,當超級計算機能夠完成計算時,兩種方法的結果是一致的。但是當復雜性增加到一定程度時,超級計算機就會失敗,而 Eagle 仍然能夠提供解決方案。
下圖為 IBM 研究人員,從左到右分別是 Abhinav Kandala、Kristan Temme、Katie Pizzolato、Sarah Sheldon、Andrew Eddins 和 Youngseok Kim,以及量子計算機群。

圖源:James Estrin/The New York Times
方法
如果說量子糾錯是一種避免噪聲的方法(避免干擾量子比特準確執行操作),那么誤差緩解可以看做允許噪聲的存在,然后在進行補償。
早期的誤差緩解方法(稱為概率誤差抵消)需要對量子處理器的行為進行采樣,以建立典型噪聲模型,然后從實際計算的測量輸出中在減去噪聲。但是隨著計算中所涉及的量子比特數量增加,這種方法變得有些不切實際 —— 因為需要進行更多的采樣。
因此,研究人員轉向了另一種方法,他們有意放大并測量處理器在不同水平上的噪聲。然后利用測量結果預估函數,該函數產生與實際測量相似的輸出。之后可以將該函數的噪聲設置為零,以產生在沒有任何噪聲情況下處理器可能執行的估計結果。
該研究使用了伊辛模型(Ising model),該模型被廣泛應用于物理學,最近也被用于時間晶體、馬約拉納邊緣模式的探索。其網格配置方式與其處理器上的量子比特物理排列一致。伊辛模型獨立于量子硬件而存在。實驗中,該研究主要使用了 IBM 的 Eagle 處理器 ibm_kyiv。
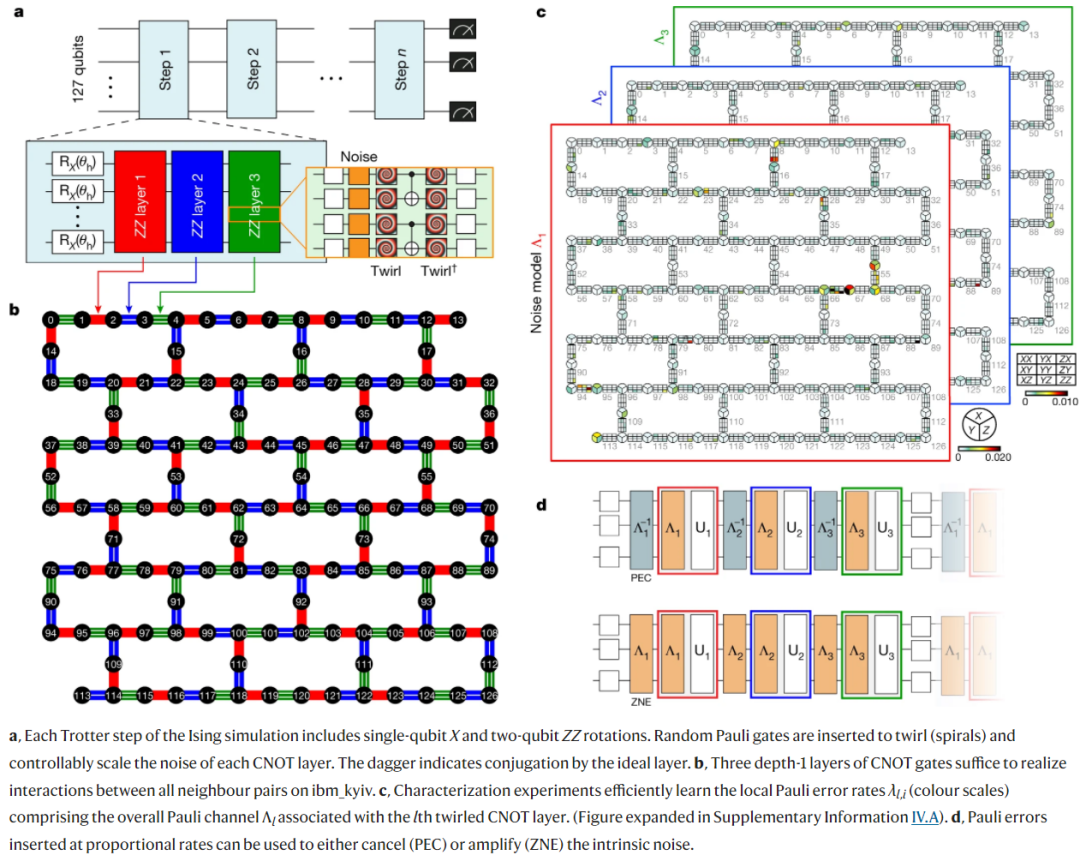
此外,該研究采用 ZNE(zero-noise extrapolation),它以低得多的采樣成本提供了有偏估計器。下圖為帶有概率誤差放大的 ZNE。
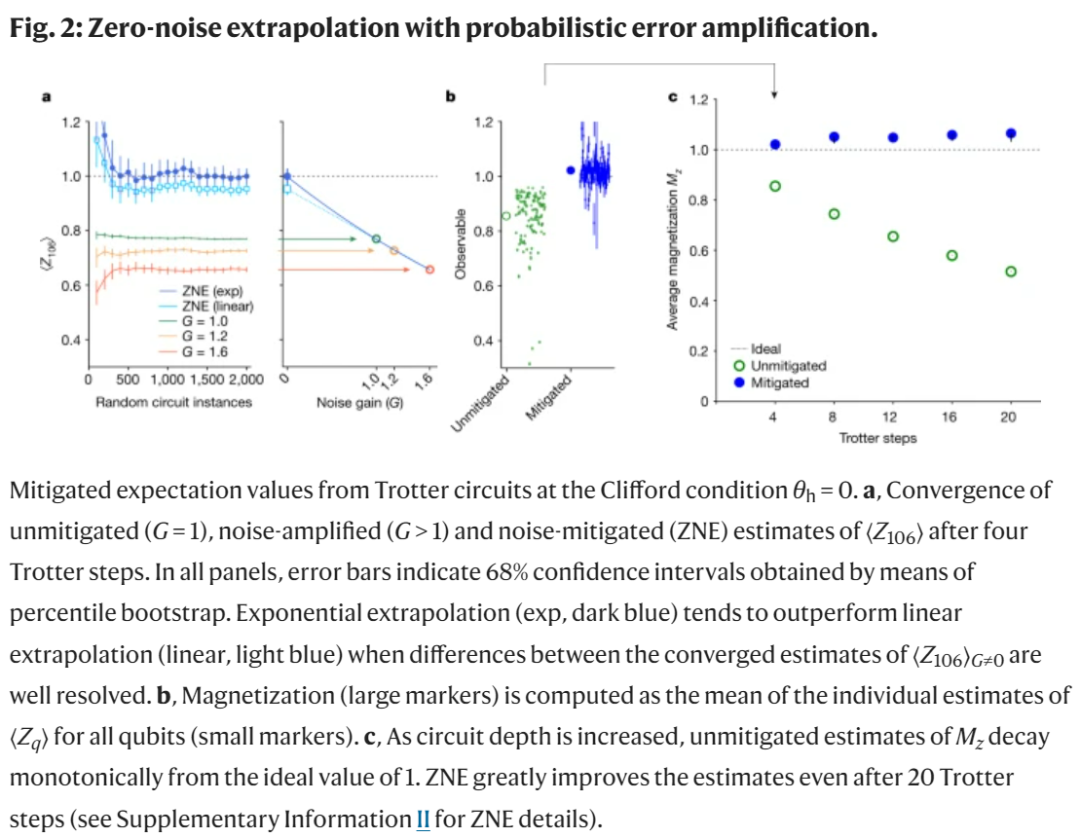
接下來,該研究測試了本文方法在 non-Clifford 電路和 Clifford θ_h = π/2 點上的有效性。
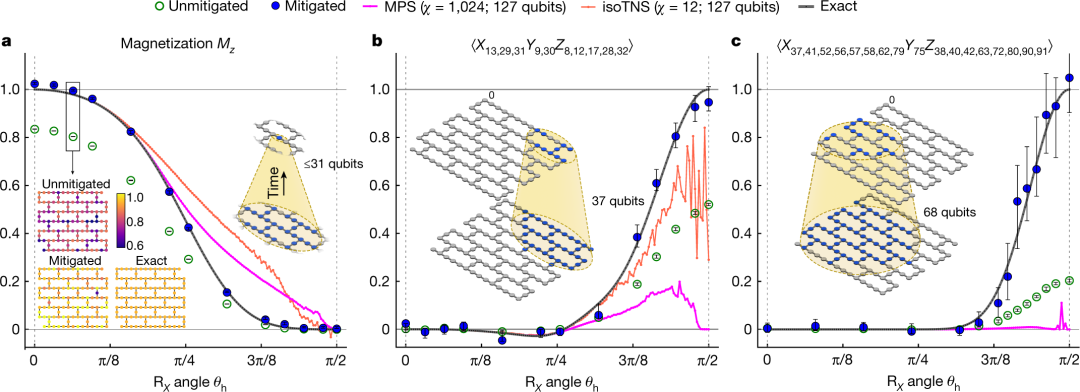
量子 VS 經典
研究者首先限制他們建模的旋轉次數,以保證其行為可以在傳統計算機上計算。結果表明誤差緩解流程有效。一旦噪聲得到補償,量子計算的數量就與經典計算相匹配,甚至超過了十幾個時間步。另外,研究者可以相對簡單地將模型擴展到經典計算機(128G 的 64 核處理器)開始「掙扎」的地方。
這發生在系統需要 68 個量子比特來建模的時候。從那里開始,研究者使用軟件來估計系統在經典計算機上的行為, 這使得它以一定的準確率代價來保持更長時間。即便如此,研究者仍可以將模型的大小擴展到需要 127 個量子比特(Eagle 處理器)的位置,這遠遠超過了經典計算機可以跟上的水平。

實驗中使用 127 量子比特 Eagle 量子處理器。圖源:James Estrin/The New York Times
對此,加州大學圣巴巴拉分校物理學家、2019 年帶領谷歌實現量子優越性的 John Martinis 表示,這些結果驗證了 IBM 的短期戰略,即通過緩解而不是糾正誤差來提供有用計算。從長遠看,IBM 和大多數其他公司希望轉向量子糾錯,這種技術需要為每個數據量子比特添加大量額外的量子比特。
深遠影響
IBM 已經擁有了超過 400 個量子比特的量子處理器,那么為什么在這項研究中使用 127 個量子比特的 Eagle 呢?這是因為它是 IBM 成熟的第三代量子處理器,而 433 量子比特的 Osprey 處理器仍處于第一次迭代中。這兩代量子處理器已被用于提升量子比特的性能,減少需要補償的噪聲。
下圖為 IBM 量子計算機的演進歷程。IBM 預計今年晚些時候推出其迄今為止最強大的處理器,即 1121 量子比特的 Condor。另外,IBM 量子技術負責人 Jay Gambetta 表示,IBM 還在其開發 pipeline 中擁有多達 4158 個量子比特的實用規模處理器。他補充道,為了實現到 2033 年建造 10 萬個量子比特機器(它們可以執行完全糾錯算法)的長期目標,還需要解決大量工程問題。

這引出了第二個原因:噪聲補償的計算成本很高,需要使用經典計算機來完成。相反在量子計算機上進行噪聲采樣只需花費 5 分鐘。但即使是較小的問題,完整的降噪過程也需要 4 小時。相比之下,在經典計算機上簡單地對系統建模就得 8 小時。一些較大的問題需要約 30 小時來建模,同時降噪需要 9.5 小時。
這樣下來的一個結果是添加足夠的量子比特也可能使得誤差緩解在計算上變得難以處理。Gambetta 表示,「誤差緩解依然呈指數級縮放,但它的指數級程度要弱于模擬成本。」
IBM 在這里持樂觀態度有兩個理由。研究者表示,首先誤差緩解涉及的算法主要是經典處理延遲,它們很大程度上通過概念上直接的優化來消除。其次涉及的時間作為量子硬件中誤差率函數來縮放,其中較低的誤差率將加速經典計算部分。
所有這一切使得 IBM 樂觀地認為,在他們可能實現糾錯量子比特之前,誤差緩解是在量子硬件上執行有用計算的一條路徑。正如該項研究總結的那樣,「即使在容錯量子計算出現之前,有噪聲的量子計算機也能在超過 100 量子比特和 non-trivial 電路深度的范圍內產生可靠的期望值。并且從噪聲限制的量子電路中獲得實際的計算優勢是有價值的。」
-
IBM
+關注
關注
3文章
1765瀏覽量
74860 -
量子計算
+關注
關注
4文章
1112瀏覽量
35060 -
量子比特
+關注
關注
0文章
38瀏覽量
8863
原文標題:攻克量子計算不可靠難題,IBM用誤差緩解得到有用計算,登Nature封面
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論