") 基準(zhǔn)數(shù)據(jù)集(CORR2CAUSE)如何測試大語言模型(LLM)的純因果推理能力
基準(zhǔn)數(shù)據(jù)集(CORR2CAUSE)如何測試大語言模型(LLM)的純因果推理能力
因果推理是人類智力的標(biāo)志之一。因果關(guān)系NLP領(lǐng)域近年來引起了人們的極大興趣,但其主要依賴于從常識(shí)知識(shí)中發(fā)現(xiàn)因果關(guān)系。本研究提出了一個(gè)基準(zhǔn)數(shù)據(jù)集(CORR2CAUSE)來測試大語言模型(LLM)的純因果推理能力。其中CORR2CAUSE對(duì)LLM來說是一項(xiàng)具有挑戰(zhàn)性的任務(wù),有助于指導(dǎo)未來關(guān)于提高LLM純粹推理能力和可推廣性的研究。
簡介
因果推理
因果推理是推理的一個(gè)基本方面,其涉及到在變量或事件之間建立正確的因果關(guān)系。大致可分為兩種不同的方式的因果關(guān)系:一種是通過經(jīng)驗(yàn)知識(shí),例如,從常識(shí)中知道,為朋友準(zhǔn)備生日派對(duì)會(huì)讓他們快樂;另一種是通過純粹的因果推理,因果關(guān)系可以通過使用因果推理中已知的程序和規(guī)則進(jìn)行形式化的論證和推理得到。例如,已知A和B彼此獨(dú)立,但在給定C的情況下變得相關(guān),那么可以推斷,在一個(gè)封閉系統(tǒng)中,C是A和B共同影響的結(jié)果,如下圖所示。
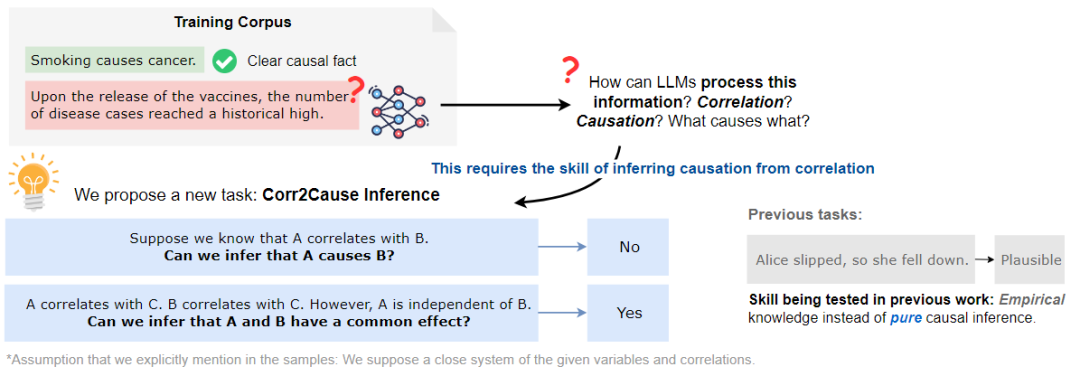
想象上圖中的場景,在訓(xùn)練語料庫中有大量的相關(guān)性,比如疫苗這個(gè)詞與疾病病例數(shù)量的增加有關(guān)。如果認(rèn)為LLM的成功在于捕捉術(shù)語之間的大量統(tǒng)計(jì)相關(guān)性,那么關(guān)鍵但缺失的一步是如何處理這些相關(guān)性并推斷因果關(guān)系,其中一個(gè)基本的構(gòu)建塊是CORR2CAUSE推斷技能。
本文將這項(xiàng)任務(wù)表述為NLP的一項(xiàng)新任務(wù),即因果關(guān)系推理,并認(rèn)為這是大語言模型的必備技能。
貢獻(xiàn)
基于CORR2COUSE數(shù)據(jù)集,本文探討了兩個(gè)主要的研究問題:
(1)現(xiàn)有的LLM在這項(xiàng)任務(wù)中的表現(xiàn)如何?
(2)現(xiàn)有的LLM能否在這項(xiàng)任務(wù)中重新訓(xùn)練或重新設(shè)定目標(biāo),并獲得強(qiáng)大的因果推理技能?
本文的主要貢獻(xiàn)如下:
(1)提出了一項(xiàng)新任務(wù),探討LLMs推理能力的一個(gè)方面,即純因果推理;
(2)使用因果發(fā)現(xiàn)的見解組成了超過400K個(gè)樣本的數(shù)據(jù)集;
(3)在數(shù)據(jù)集上評(píng)估了17個(gè)LLM的性能,發(fā)現(xiàn)它們的性能都很差,接近隨機(jī)基線;
(4)進(jìn)一步探討了LLM是否可以通過微調(diào)來學(xué)習(xí)這項(xiàng)技能,發(fā)現(xiàn)LLM無法在分布外擾動(dòng)的情況下穩(wěn)健地掌握這項(xiàng)技能,本文建議未來的工作探索更多方法來增強(qiáng)LLM中的純因果推理技能。
因果推理預(yù)備知識(shí)
因果模型有向圖(DGCM)
有向圖形因果模型是一種常用的表示方法,用于表示一組變量之間的因果關(guān)系。給定一組N個(gè)變量X={X1,...,XN},可以使用有向圖G=(X,E)對(duì)它們之間的因果關(guān)系進(jìn)行編碼,其中E是有向邊的集合。每條邊ei,j∈E代表一個(gè)因果聯(lián)系Xi→Xj,意味著Xi是Xj的直接原因。
D-分離與馬爾可夫性質(zhì)
D-Separation(D-分離)
D分離是圖模型中的一個(gè)基本概念,用于確定在給定第三組節(jié)點(diǎn)Z的情況下,DAG中的兩組節(jié)點(diǎn)X和Y是否條件獨(dú)立,其中這三組節(jié)點(diǎn)是不相交的。
Markov Property(馬爾可夫性質(zhì))
DAG中的馬爾可夫性質(zhì)表明每個(gè)節(jié)點(diǎn)Xi在給定父節(jié)點(diǎn)的情況下有條件地獨(dú)立于其非后代,。使用馬爾可夫?qū)傩裕梢詫D中所有節(jié)點(diǎn)的聯(lián)合分布分解為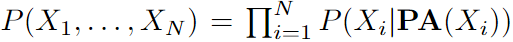 為了從概率分布中推斷因果圖,一個(gè)常見的假設(shè)是置信度,即從概率分布中的獨(dú)立關(guān)系中推斷圖中所有D-分離集的有效性。在本文的工作中,也采用了這個(gè)廣泛的假設(shè),它適用于大多數(shù)現(xiàn)實(shí)世界的場景。
為了從概率分布中推斷因果圖,一個(gè)常見的假設(shè)是置信度,即從概率分布中的獨(dú)立關(guān)系中推斷圖中所有D-分離集的有效性。在本文的工作中,也采用了這個(gè)廣泛的假設(shè),它適用于大多數(shù)現(xiàn)實(shí)世界的場景。
Markov Equivalence of Graphs(圖的馬爾可夫等價(jià))
如果兩個(gè)DAG有相同的聯(lián)合分布P(X),則將兩個(gè)DAG表示為馬爾可夫等價(jià)。相互等價(jià)的馬爾可夫 DAG集稱為馬爾可夫等價(jià)類(MEC)。同一MEC中的因果圖可以很容易地識(shí)別,因?yàn)樗鼈兙哂邢嗤墓羌?即無向邊)和V結(jié)構(gòu)(即A→B←C形式的結(jié)構(gòu),其中A和C不連接)。
因果發(fā)現(xiàn)
因果發(fā)現(xiàn)旨在通過分析觀測數(shù)據(jù)中的統(tǒng)計(jì)屬性來學(xué)習(xí)因果關(guān)系。它可以通過基于約束的方法、基于分?jǐn)?shù)的方法或其他利用功能因果模型的方法來實(shí)現(xiàn)。
為了從相關(guān)性(用自然語言表示)推斷因果關(guān)系,本研究的數(shù)據(jù)集設(shè)計(jì)基于廣泛使用的Peter Clark(PC)算法。其使基于條件獨(dú)立原則和因果馬爾可夫假設(shè),這使它能夠有效地識(shí)別給定數(shù)據(jù)集中變量之間的因果關(guān)系。該算法首先從所有變量之間的完全連通無向圖開始。然后,如果兩個(gè)變量之間存在無條件或有條件的獨(dú)立關(guān)系,它就消除了它們之間的邊。然后,只要存在V形結(jié)構(gòu),它就會(huì)定向定向邊。最后,它迭代地檢查其他邊的方向,直到整個(gè)因果圖與所有統(tǒng)計(jì)相關(guān)性一致。
數(shù)據(jù)集構(gòu)建
任務(wù)定義
給定一組N個(gè)變量X={X1,...,XN},一個(gè)關(guān)于變量之間所有相關(guān)性的聲明s,以及一個(gè)描述變量Xi和Xj對(duì)之間的因果關(guān)系r的假設(shè)h。該任務(wù)是學(xué)習(xí)一個(gè)函數(shù)f(s,h)→v,它將相關(guān)語句和因果關(guān)系假設(shè)h映射到它們的有效性v∈{0,1},如果該推理無效,則取值0,否則為1。
數(shù)據(jù)生成過程
數(shù)據(jù)生成過程如下圖所示,首先選擇變量的數(shù)量N,并生成所有具有N個(gè)節(jié)點(diǎn)的唯一DGCM。然后,從這些圖中收集所有D分離集。對(duì)于MEC到因果圖的每個(gè)對(duì)應(yīng)關(guān)系,根據(jù)MEC中的統(tǒng)計(jì)關(guān)系組合相關(guān)語句,并假設(shè)兩個(gè)變量之間的因果關(guān)系,如果假設(shè)是MEC中所有因果圖的共享屬性,則有效性v=1,如果對(duì)于所有MEC圖的假設(shè)不一定為真,則v=0。
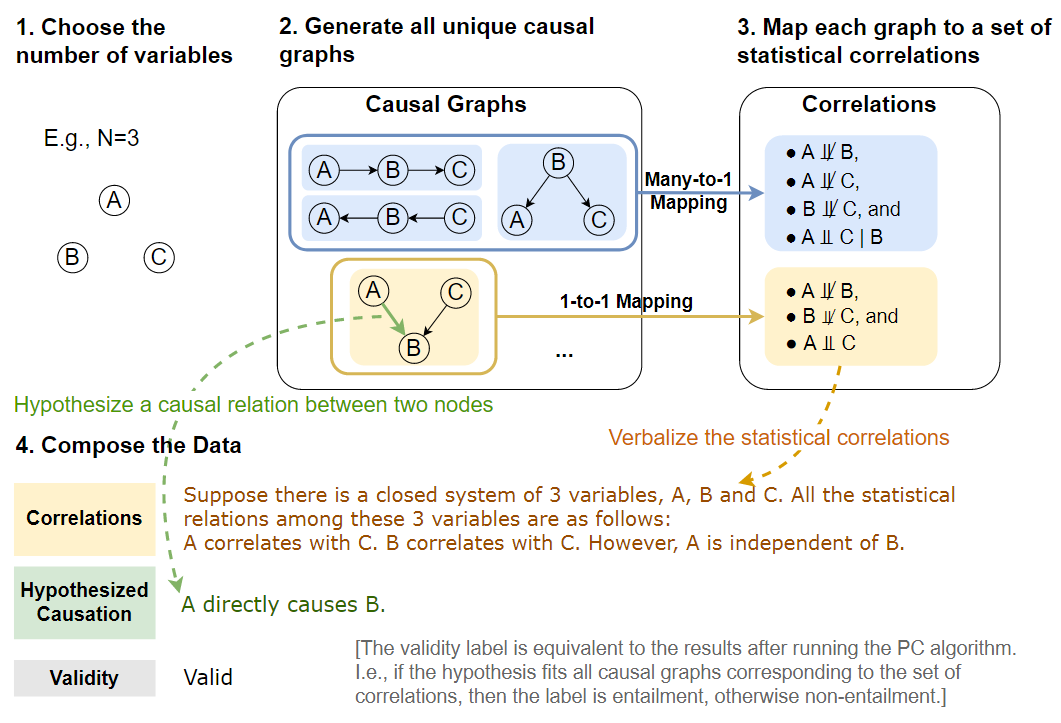
用同構(gòu)檢驗(yàn)構(gòu)造圖
數(shù)據(jù)生成的第一步是組成因果圖,如上圖的步驟1和2所示。對(duì)于一組N個(gè)變量X={X1,...,XN},存在N(N-1)個(gè)可能的有向邊,因?yàn)槊總€(gè)節(jié)點(diǎn)可以鏈接到除自身之外的任何節(jié)點(diǎn)。為了刪除圖中的循環(huán),將節(jié)點(diǎn)按拓?fù)漤樞蚺帕校@只允許邊Xi→ Xj,其中i<j。通過將圖的鄰接矩陣限制為僅在對(duì)角線上具有非零值來實(shí)現(xiàn)這一點(diǎn),從而產(chǎn)生DAG的N(N?1)/2個(gè)可能的有向邊。
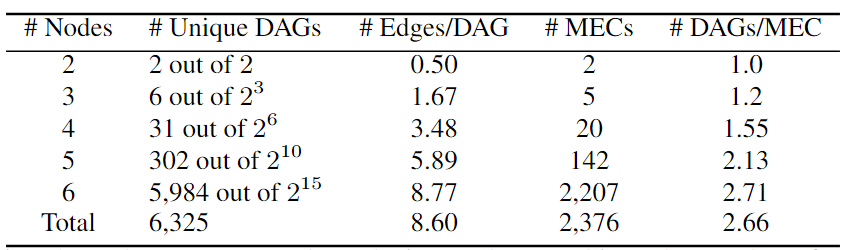
集合中可能存在同構(gòu)圖。為了避免這種情況,進(jìn)行了圖同構(gòu)檢查,并減少了集合,以便只保留唯一的DAG,在下表中展示了它們的統(tǒng)計(jì)數(shù)據(jù)。盡管其可以處理大型圖,但主要關(guān)注較小的圖,這些圖仍然可以產(chǎn)生合理大小的數(shù)據(jù)集。
程序生成D-分離集
基于一組唯一的DAG,通過圖論條件以編程方式生成D-分離集,如數(shù)據(jù)生成過程圖的步驟3所示。對(duì)于每對(duì)節(jié)點(diǎn),給定D-分離集中的變量,它們是條件獨(dú)立的。如果D-分離集是空的,那么這兩個(gè)節(jié)點(diǎn)是無條件獨(dú)立的。如果不能為這兩個(gè)節(jié)點(diǎn)找到D-分離集,那么它們是直接相關(guān)的。
組成假設(shè)和標(biāo)簽
在基于D-分離集生成相關(guān)性集合之后生成因果假設(shè)。對(duì)于因果關(guān)系r,重點(diǎn)關(guān)注兩個(gè)節(jié)點(diǎn)之間的六種常見因果關(guān)系:是父節(jié)點(diǎn)、是子節(jié)點(diǎn)、是祖先節(jié)點(diǎn)(不包括父節(jié)點(diǎn))、是后裔節(jié)點(diǎn)(不包含子節(jié)點(diǎn))、混淆節(jié)點(diǎn)和碰撞節(jié)點(diǎn)。這樣,假設(shè)集包含每對(duì)變量之間的所有六個(gè)有意義的因果關(guān)系,從而導(dǎo)致具有N個(gè)變量的圖的總大小為6*N(N?1)/2=3N(N–1)個(gè)假設(shè)。
為了生成真實(shí)有效性標(biāo)簽,從數(shù)據(jù)生成過程圖的步驟3中的相關(guān)集合開始,查找與給定相關(guān)性集合對(duì)應(yīng)的相同MEC中的所有因果圖,并檢查假設(shè)因果關(guān)系的必要性。如果假設(shè)中提出的因果關(guān)系對(duì)MEC中的所有因果圖都是有效的,那么我們生成有效性v=1;否則,v=0。
自然語言化
如數(shù)據(jù)生成過程圖的最后一步所示,將上述所有信息轉(zhuǎn)換為文本數(shù)據(jù),用于CORR2CAUSE任務(wù)。對(duì)于相關(guān)語句, 將數(shù)據(jù)生成過程圖步驟3中的相關(guān)性集合表示為自然語言語句s。當(dāng)兩個(gè)變量不能進(jìn)行D-分離時(shí),將其描述為A與B相關(guān),因?yàn)樗鼈冎苯酉嚓P(guān)并且不能獨(dú)立于任何條件。如果兩個(gè)變量具有有效的D-分離集C,那么將它們描述為A與給定C的B無關(guān)。在D-分離集為空的特殊情況中,A與B無關(guān)。
此外,通過將相關(guān)語句與給定變量的封閉系統(tǒng)的設(shè)置開始來消除歧義。最后,為了表達(dá)假設(shè),將因果關(guān)系三元組 (Xi, r, Xj) 輸入到下表中的假設(shè)模板中。

結(jié)果數(shù)據(jù)統(tǒng)計(jì)
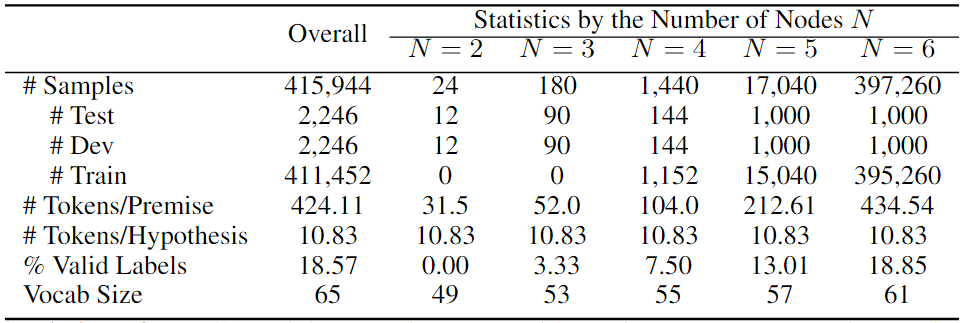
CORR2COUSE數(shù)據(jù)集的統(tǒng)計(jì)數(shù)據(jù),以及按子集的統(tǒng)計(jì)數(shù)據(jù)如下表所示。其報(bào)告了樣本總數(shù);測試、開發(fā)和訓(xùn)練集的拆分;每個(gè)前提和假設(shè)的token數(shù)量;隱含標(biāo)簽的百分比和詞匯大小。
實(shí)驗(yàn)
實(shí)驗(yàn)設(shè)置
為了測試現(xiàn)有的LLM,首先在下載次數(shù)最多的transformers庫中包括六個(gè)常用的基于BERT的NLI模型:BERT、RoBERTa、BART、DeBERTa、DistilBERT和DistilBART。除了這些基于BERT的NLI模型外,還評(píng)估了基于GPT的通用自回歸LLM:GPT-3Ada、Babbage、Curie、Davinci;其指令調(diào)整版本,text-davinci-001、text-davici-002和text-davici-003;和GPT-3.5(即ChatGPT),以及最新的GPT-4,使用temperature為0的OpenAI API2,還評(píng)估了最近更有效的模型LLaMa和Alpaca,如下表所示。
現(xiàn)有LLM中的因果推理技能
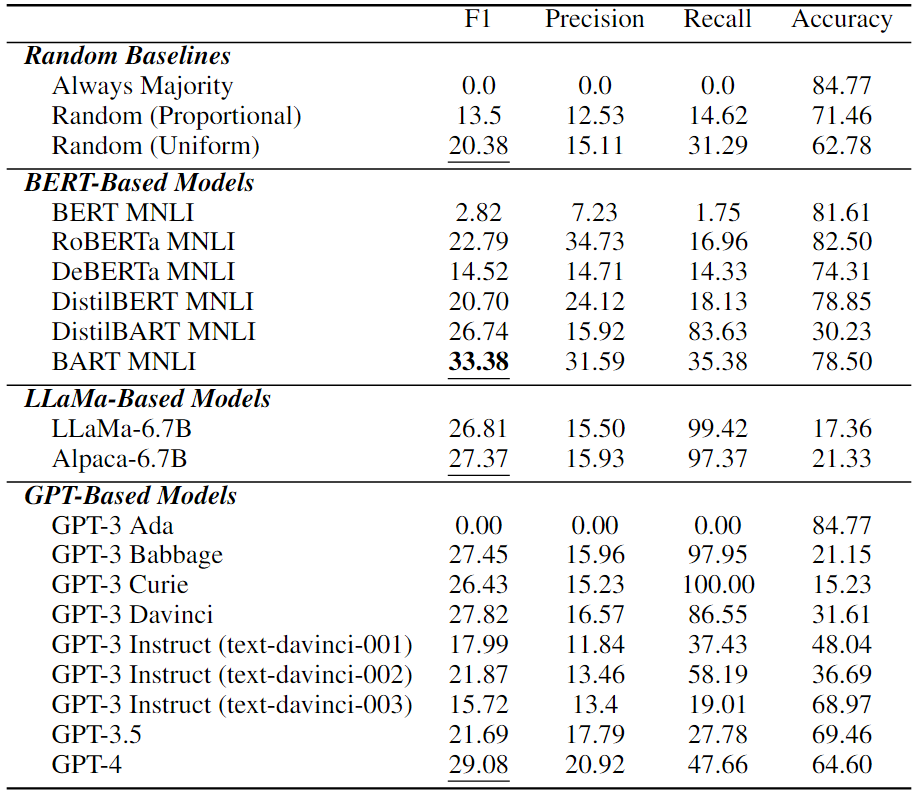
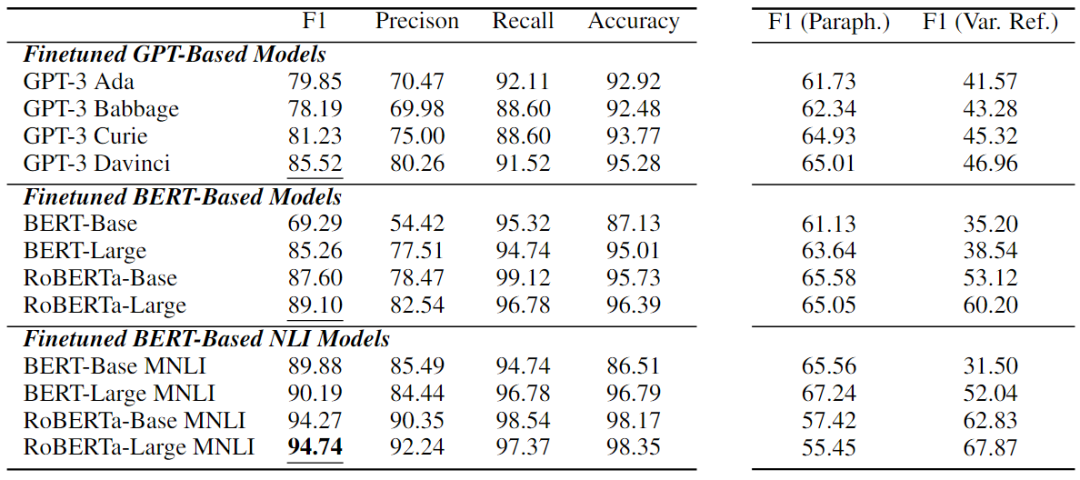
在上表中展示了LLM的因果推理性能。可以看到,純因果推理是所有現(xiàn)有LLM中一項(xiàng)非常具有挑戰(zhàn)性的任務(wù)。在所有LLM中,BART MNLI的最佳性能為33.38%F1,甚至高于最新的基于GPT的模型GPT-4。值得注意的是,許多模型比隨機(jī)猜測更差差,這意味著它們?cè)诩円蚬评砣蝿?wù)中完全失敗。
微調(diào)性能
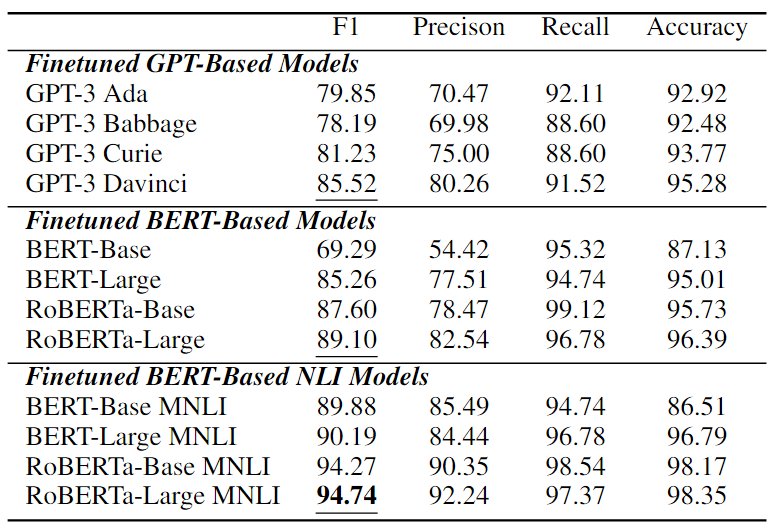
在CORR2CAUSE上微調(diào)的12個(gè)模型的展示在下表中的實(shí)驗(yàn)結(jié)果乍一看似乎非常強(qiáng)大。大多數(shù)模型性能顯著增加,其中微調(diào)的基于BERT的NLI模型表現(xiàn)出最強(qiáng)的性能。性能最好的是oBERTa-Large MNLI,在這項(xiàng)任務(wù)中獲得了 94.74%的F1值,以及較高的精度、召回率和準(zhǔn)確度分?jǐn)?shù)。
基于因果關(guān)系的細(xì)粒度性能
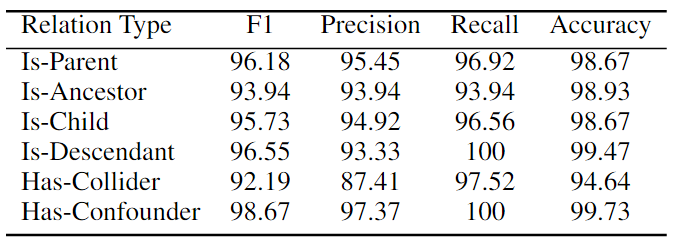
本文還進(jìn)行了細(xì)粒度分析,通過六種因果關(guān)系類型來檢驗(yàn)最強(qiáng)模型RoBERTa Large MNLI的性能。如下表所示,該模型在判斷Is-Parent、Is-Descendant和Has-Confounder等關(guān)系方面非常好,所有 F1 分?jǐn)?shù)都超過96%,而在HasCollider關(guān)系上則較弱。這可能是因?yàn)閏ollider關(guān)系是最特殊的類型,需要僅基于兩個(gè)變量的無條件獨(dú)立性和以共同后代為條件的相關(guān)性來識(shí)別V結(jié)構(gòu)。
魯棒性分析
微調(diào)后的模型展現(xiàn)出了高性能,但是這些模型真的健壯地學(xué)習(xí)了因果推理技能嗎?基于此本研究展開了魯棒性分析。
兩個(gè)魯棒性測試
設(shè)計(jì)了兩個(gè)簡單的穩(wěn)健性測試:(1)釋義,(2)變量重構(gòu)。對(duì)于釋義,通過將每個(gè)因果關(guān)系的文本模板更改為一些語義等效的替代方案來簡單地釋義假設(shè)。對(duì)于(2)變量重構(gòu),顛倒變量名稱的字母表,即將A, B, C翻轉(zhuǎn)為Z, Y, X等。具體來說,采用了常見的文本對(duì)抗性攻擊設(shè)置保留訓(xùn)練集并保留相同的保存模型,但在擾動(dòng)測試集中運(yùn)行推理。通過這種方式,將模型只過度擬合訓(xùn)練數(shù)據(jù)的可能性與掌握推理技能的可能性分開。
數(shù)據(jù)擾動(dòng)后的結(jié)果
從下表右側(cè)兩列F1值可以看出,當(dāng)解釋測試集時(shí),所有模型急劇下降多達(dá)39.29,當(dāng)重新分解變量名稱時(shí),它們大幅下降高達(dá)58.38。性能最好的模型RoBERTa-Large MNLI對(duì)釋義特別敏感,表明所有模型的下降幅度最大;然而,它對(duì)變量再分解最穩(wěn)健,保持了67.87的高F1分?jǐn)?shù)。
總結(jié)
在這項(xiàng)工作中,介紹了一項(xiàng)新任務(wù)CORR2CAUSE,用于從相關(guān)性推斷因果關(guān)系,并收集了超過400K個(gè)樣本的大規(guī)模數(shù)據(jù)集。在新任務(wù)上評(píng)估了大量的LLM,發(fā)現(xiàn)現(xiàn)成的LLM在此任務(wù)中表現(xiàn)不佳。實(shí)驗(yàn)表明,可以通過微調(diào)在這項(xiàng)任務(wù)上重新使用LLM,但未來的工作需要知道分布外的泛化問題。鑒于當(dāng)前LLM的推理能力有限,以及將實(shí)際推理與訓(xùn)練語料庫衍生知識(shí)分離的困難,必須專注于旨在準(zhǔn)確解開和衡量兩種能力的工作。
責(zé)任編輯:彭菁
-
編碼
+關(guān)注
關(guān)注
6文章
957瀏覽量
54951 -
語言模型
+關(guān)注
關(guān)注
0文章
538瀏覽量
10341 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24833 -
LLM
+關(guān)注
關(guān)注
0文章
299瀏覽量
400
原文標(biāo)題:解密大型語言模型:從相關(guān)性中發(fā)現(xiàn)因果關(guān)系?
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
大型語言模型的邏輯推理能力探究
【大語言模型:原理與工程實(shí)踐】揭開大語言模型的面紗
【大語言模型:原理與工程實(shí)踐】大語言模型的評(píng)測
基于e-CARE的因果推理相關(guān)任務(wù)
如何對(duì)推理加速器進(jìn)行基準(zhǔn)測試
基于Transformer的大型語言模型(LLM)的內(nèi)部機(jī)制

大語言模型(LLM)預(yù)訓(xùn)練數(shù)據(jù)集調(diào)研分析

從原理到代碼理解語言模型訓(xùn)練和推理,通俗易懂,快速修煉LLM
現(xiàn)已公開發(fā)布!歡迎使用 NVIDIA TensorRT-LLM 優(yōu)化大語言模型推理

Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例

ChatGPT是一個(gè)好的因果推理器嗎?

大語言模型(LLM)快速理解

如何加速大語言模型推理
LLM大模型推理加速的關(guān)鍵技術(shù)
新品| LLM630 Compute Kit,AI 大語言模型推理開發(fā)平臺(tái)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論