 V853端側部署YOLOV5訓練自定義模型全流程教程
V853端側部署YOLOV5訓練自定義模型全流程教程
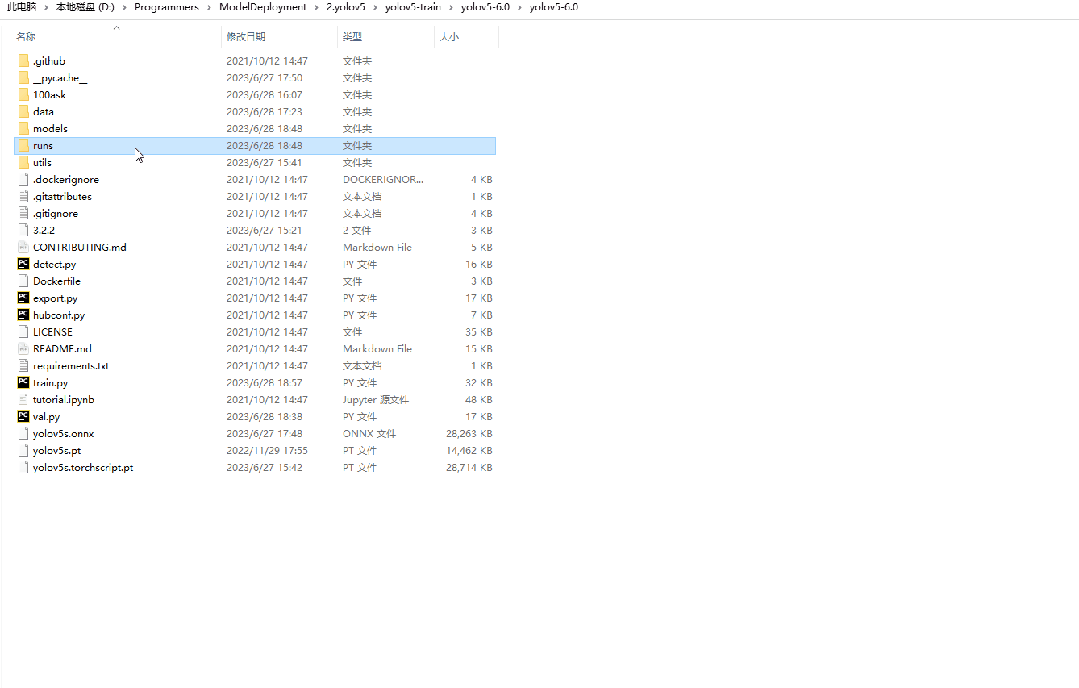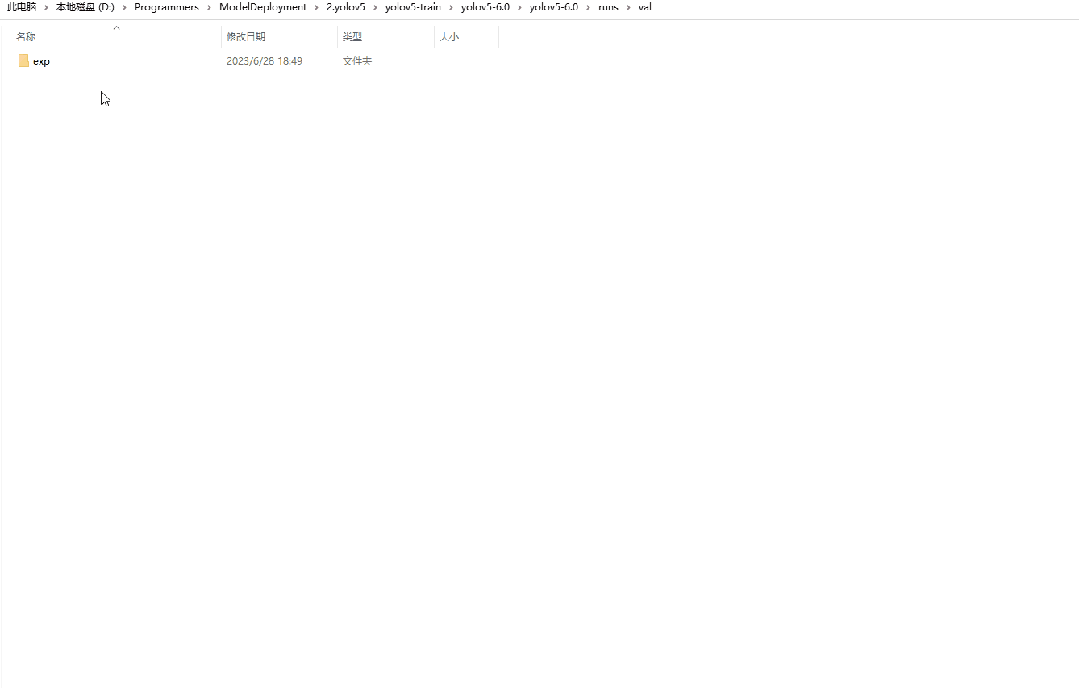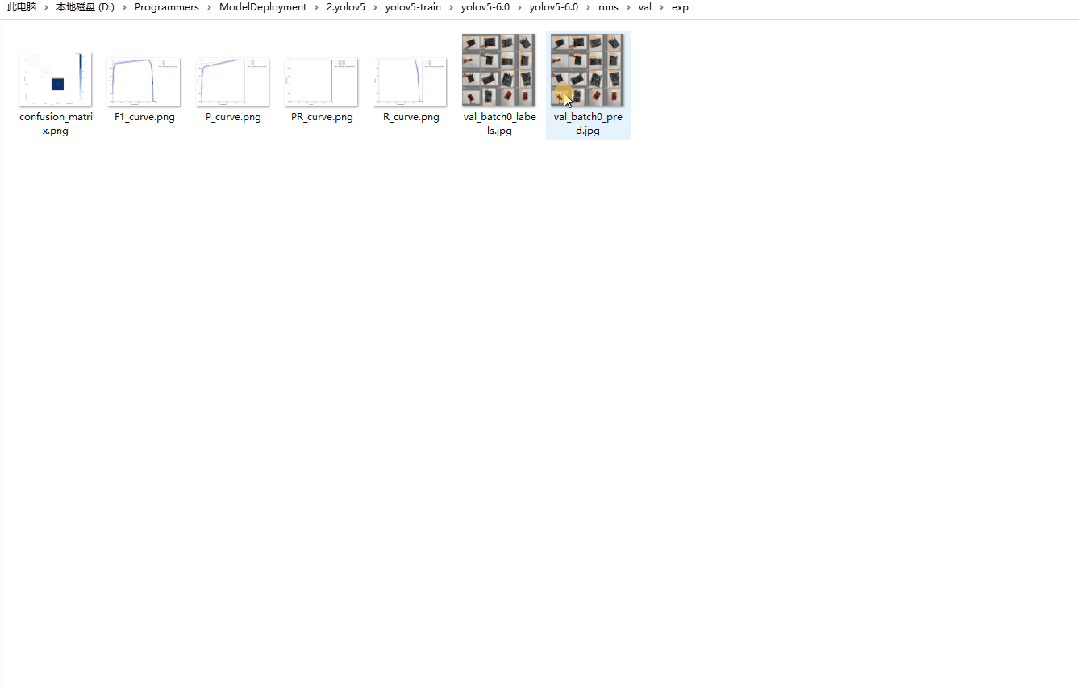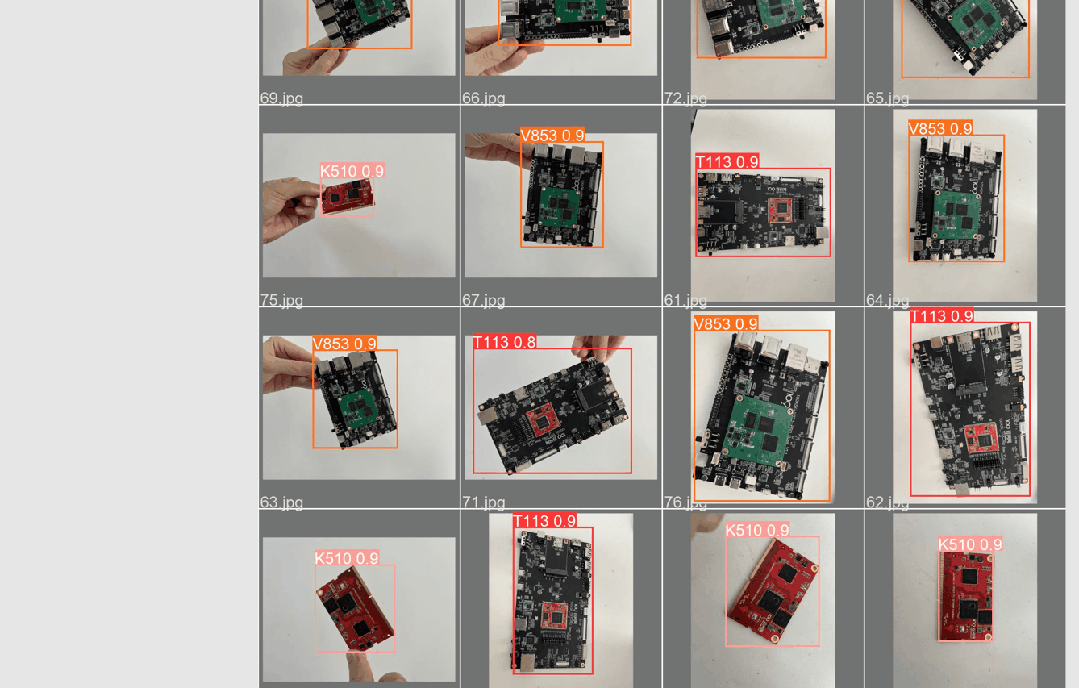
這里以百問網開發板為檢測目標,下面展示端側檢測效果



下面操作僅演示如何去訓練自定義模型、導出模型、轉換模型、模型部署。注意:訓練模型對于電腦需要有一定的要求,如果電腦性能較弱可能會導致訓練效果較差,從而導致模型精度較低。
參考鏈接:
https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/
1.下載數據標注工具
數據標注工具:https://github.com/heartexlabs/labelImg/releases
點擊上述紅框下載,下載完成后解壓壓縮包,雙擊打開labelImg.exe文件。

打開后等待運行,運行完成后會進入如下標注工作界面。

關于LabelImg更多的使用方法,請訪問:https://github.com/heartexlabs/labelImg
由于LabelImg會預先提供一些類供您使用,需要手動刪除這些類,使得您可以標注自己的數據集。步驟如下所示:
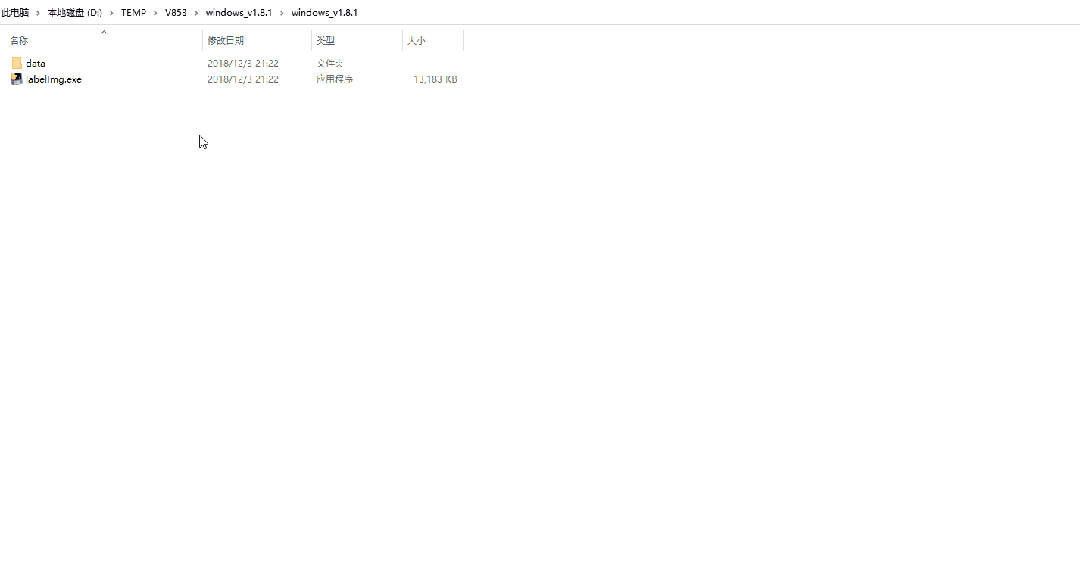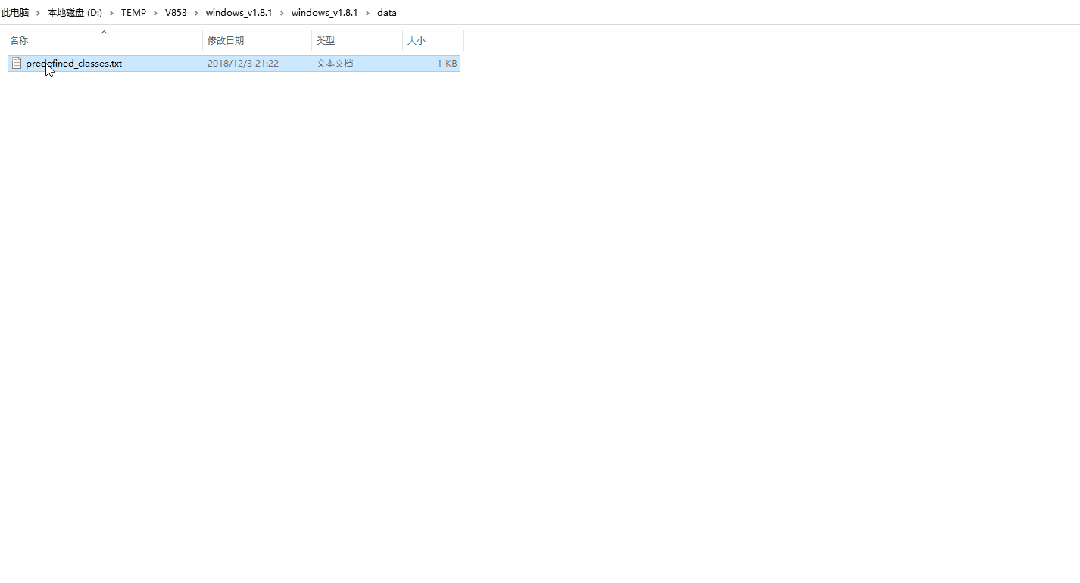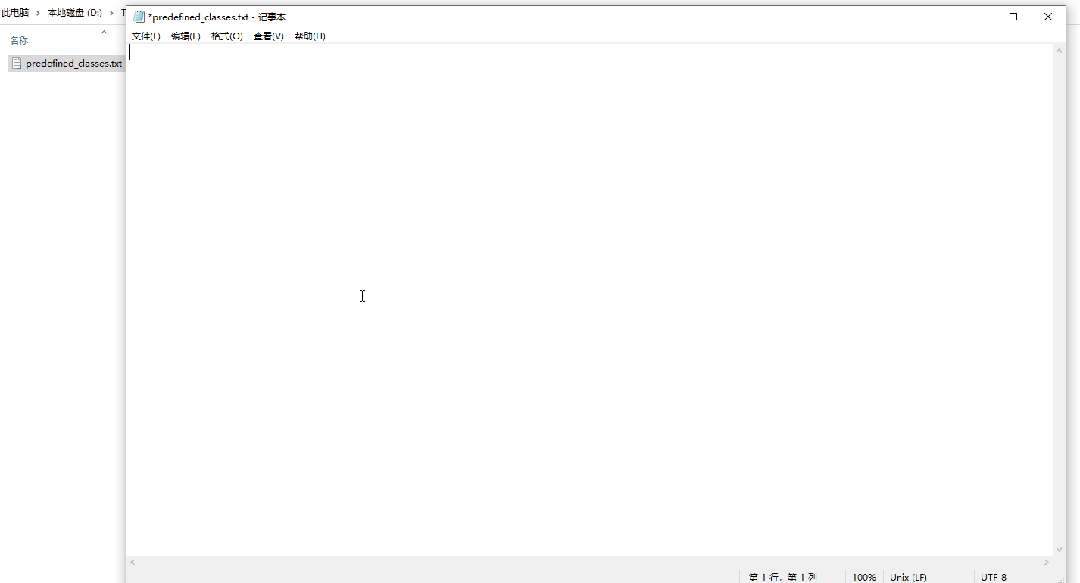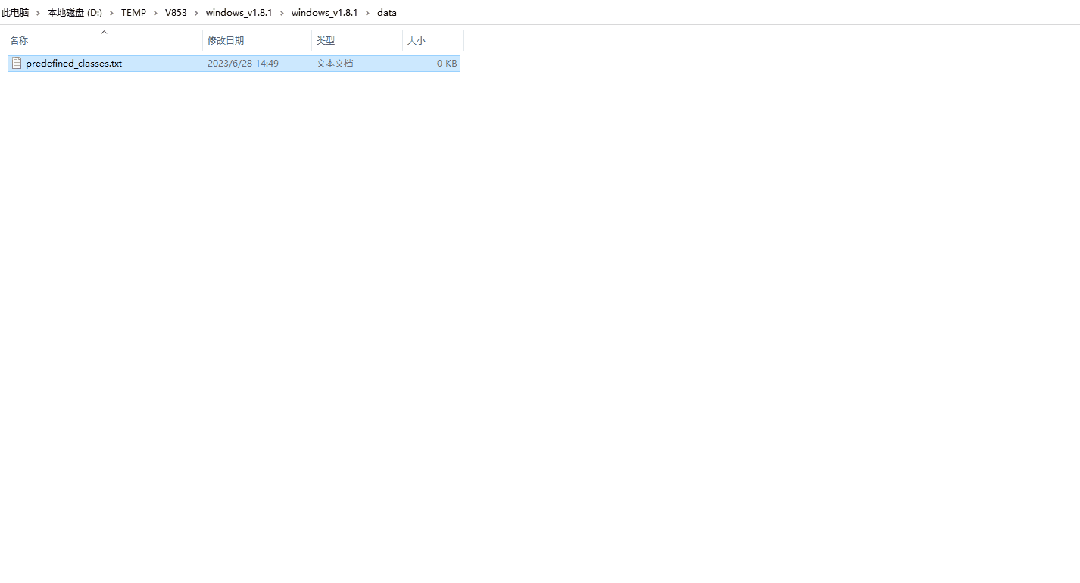
進入LabelImg程序目錄中的data目錄中,打開predefined_classes.txt文件,刪除文件中所有預定義的類后保存并退出即可。
2.創建數據集目錄
在任意工作目錄中創建images文件夾和labels文件夾分別存放圖像數據集和標注信息。這里我演示僅使用少量圖像樣本進行標注,在實際項目中需要采集足夠的圖像進行標注才拿滿足模型的準確率和精度。
例如我在100ask-yolov5-image目錄中創建有images文件夾和labels文件夾,如下所示,創建images文件,存放圖像數據集,創建labels文件夾,該文件夾用于后續存放標注數據。
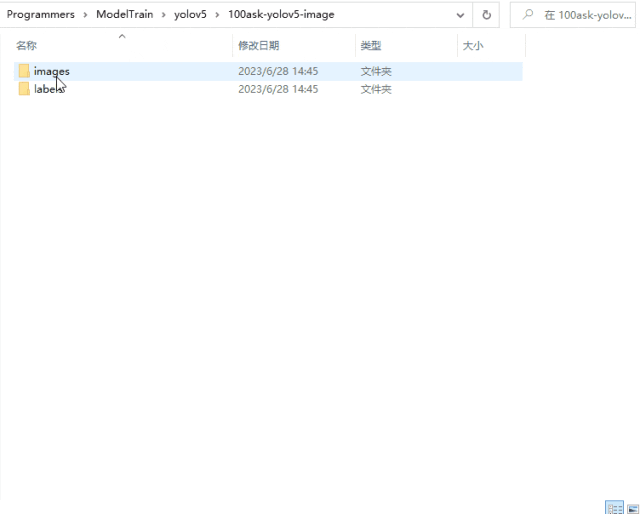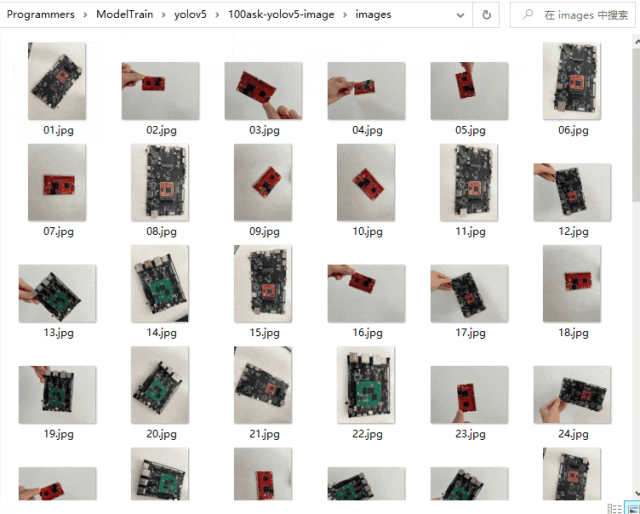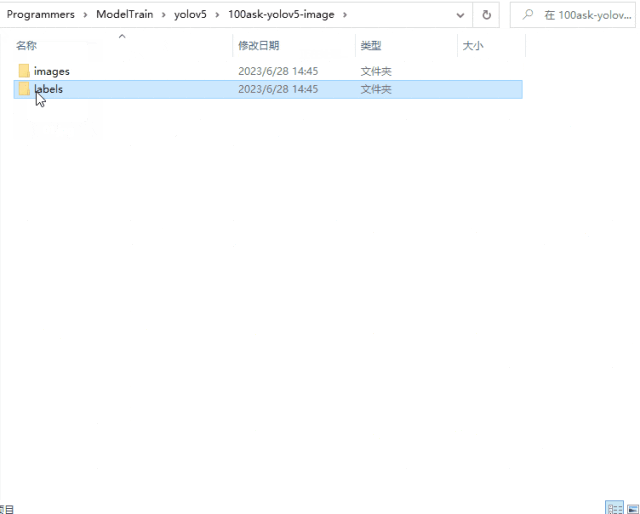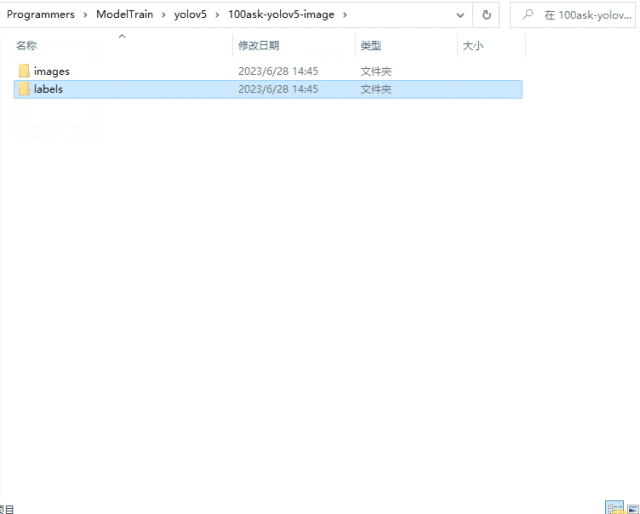
3.標注圖像
打開LabelImg軟件后,使用軟件打開數據集圖像文件夾,如下所示:

打開后,修改輸出label的文件夾為我們創建的數據集目錄下的labels文件夾
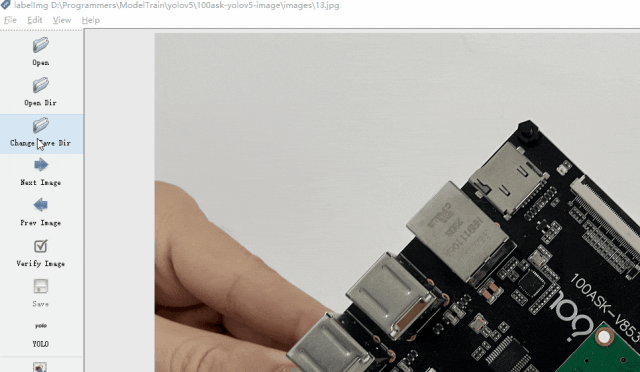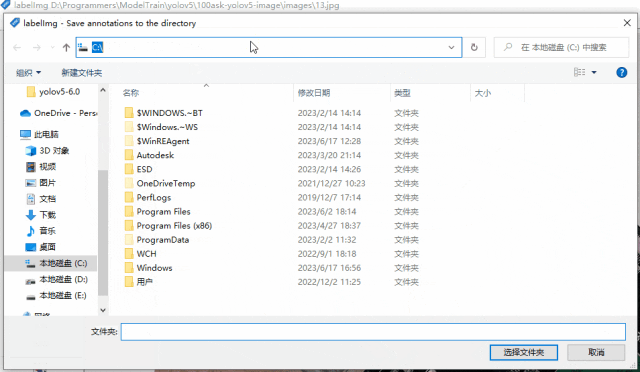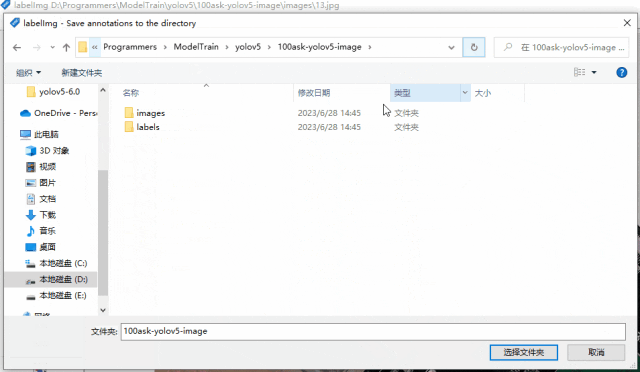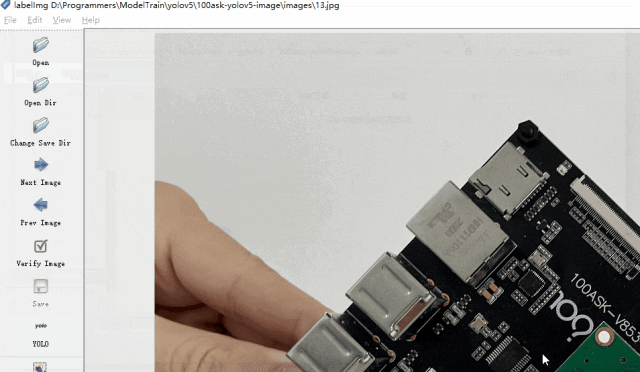
下面我演示標注過程,以百問網的開發板為例,標注三塊開發板
標注過程見原文鏈接
當你點擊Save后即表示標注完成,標注完成后后會在labels目錄下生成classes.txt(類別)和圖像中標注的類別即位置信息。
下面為LabelImg快捷鍵目錄:
| Ctrl + u | Load all of the images from a directory |
|---|---|
| Ctrl + r | Change the default annotation target dir |
| Ctrl + s | Save |
| Ctrl + d | Copy the current label and rect box |
| Ctrl + Shift + d | Delete the current image |
| Space | Flag the current image as verified |
| w | Create a rect box |
| d | Next image |
| a | Previous image |
| del | Delete the selected rect box |
| Ctrl++ | Zoom in |
經過標注大量的圖像后,labels文件夾如下圖所示
4.劃分訓練集和驗證集
在模型訓練中,需要有訓練集和驗證集。可以簡單理解為網絡使用訓練集去訓練,訓練出來的網絡使用驗證集驗證。在總數據集中訓練集通常應占80%,驗證集應占20%。所以將我們標注的數據集按比例進行分配。
在yolov5-6.0項目目錄下創建100ask文件夾(該文件夾名可自定義),在100ask文件夾中創建train文件夾(存放訓練集)和創建val文件夾(存放驗證集)
在train文件夾中創建images文件夾和labels文件夾。其中images文件夾存放總數據集的80%的圖像文件,labels文件夾存放與images中的文件對應的標注文件。
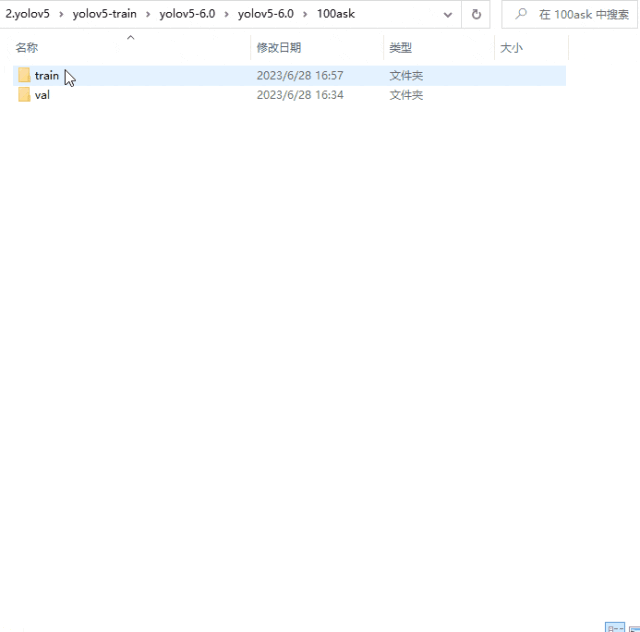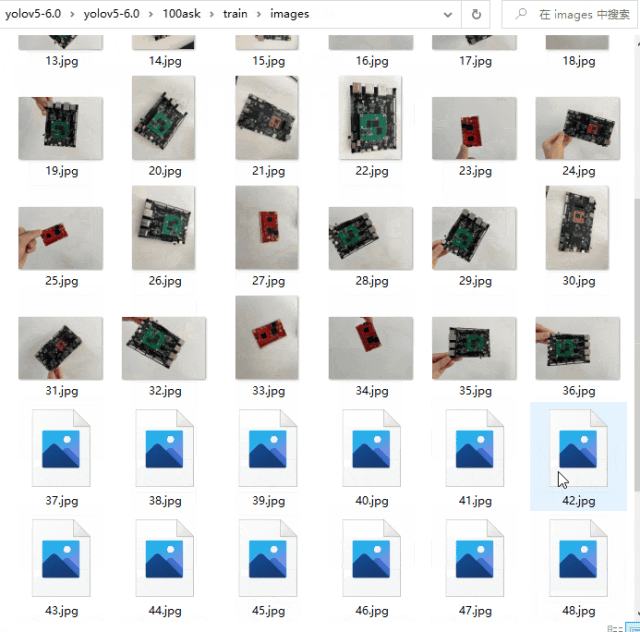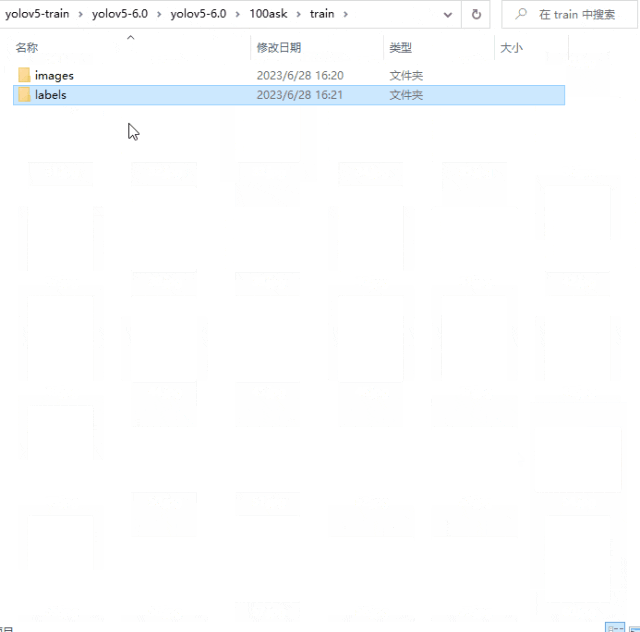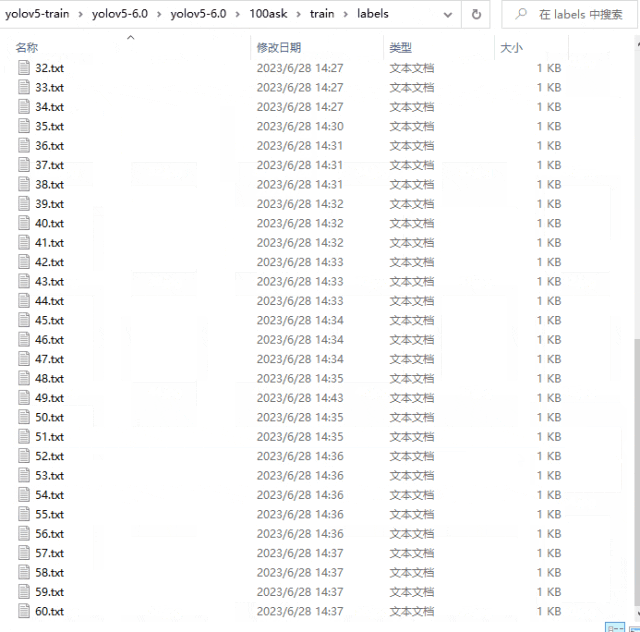
在val文件夾中創建images文件夾和labels文件夾。其中images文件夾存放總數據集的20%的圖像文件,labels文件夾存放與images中的文件對應的標注文件。
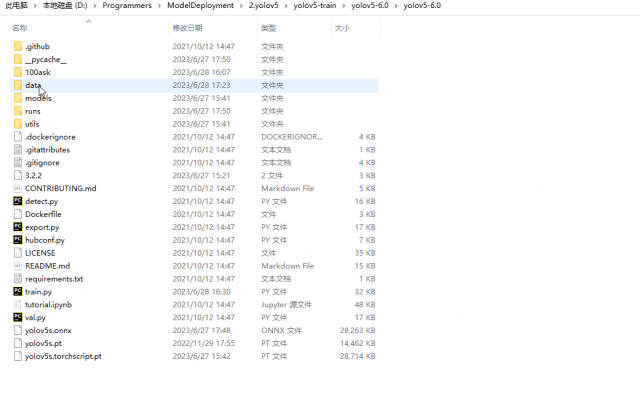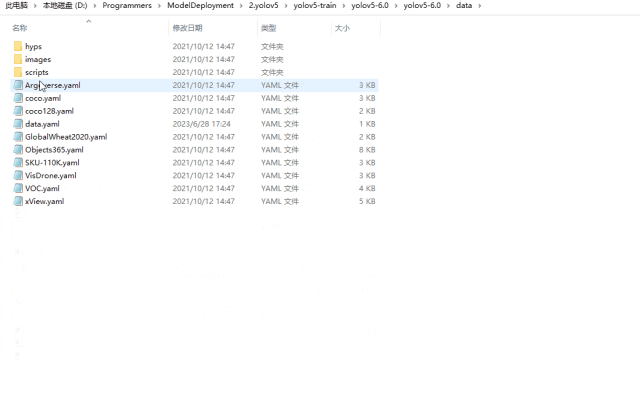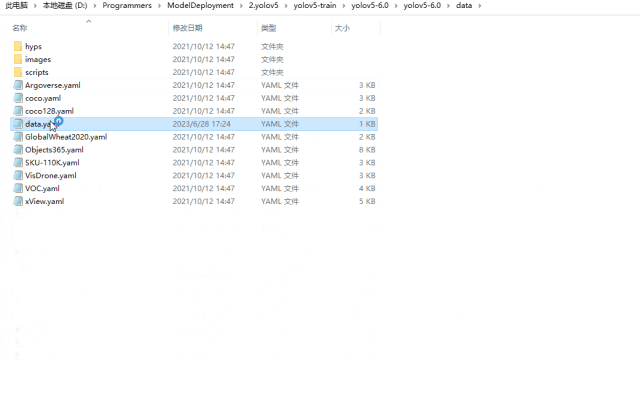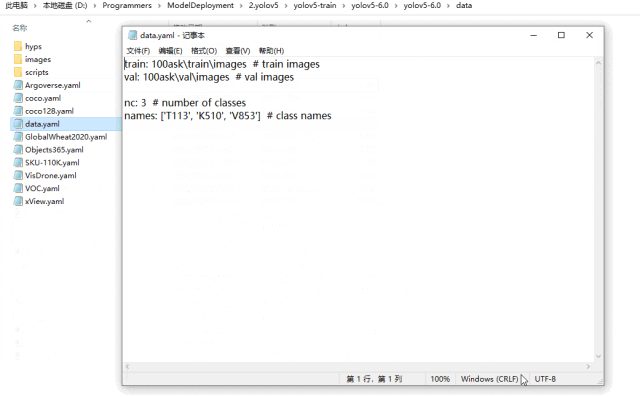
5.創建數據集配置文件
進入yolov5-6.0data目錄下,創建data.yaml,文件內容如下所示:
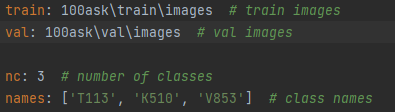
train: 100ask rainimages # train images val: 100askvalimages # val images nc: 3 # number of classes names: ['T113', 'K510', 'V853'] # class names
6.創建模型配置文件
進入models目錄下,拷貝yolov5s.yaml文件,粘貼并models目錄下重命名為100ask_my-model.yaml,例如:
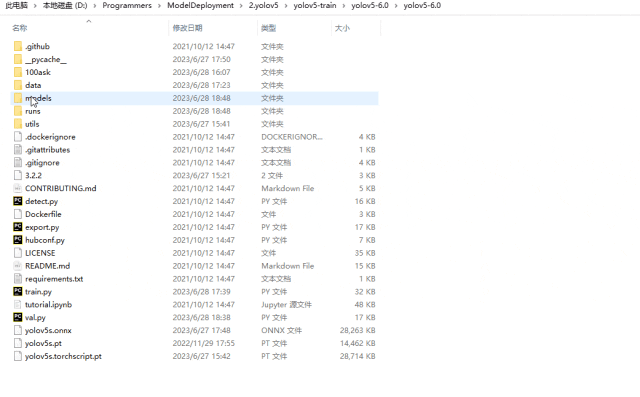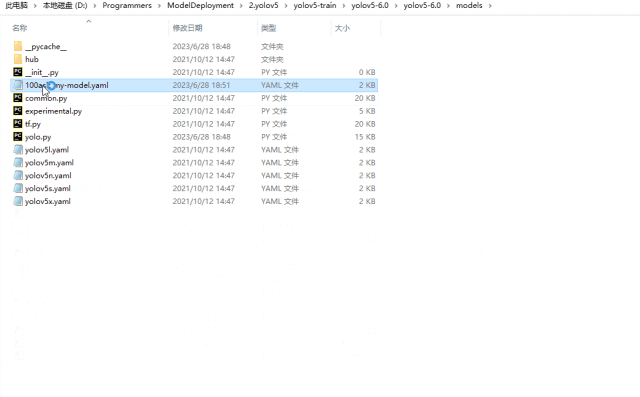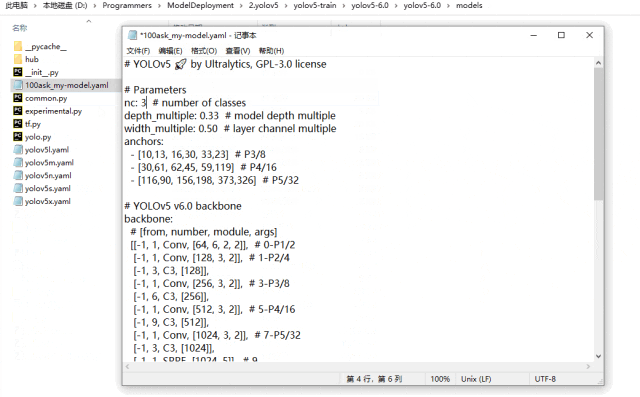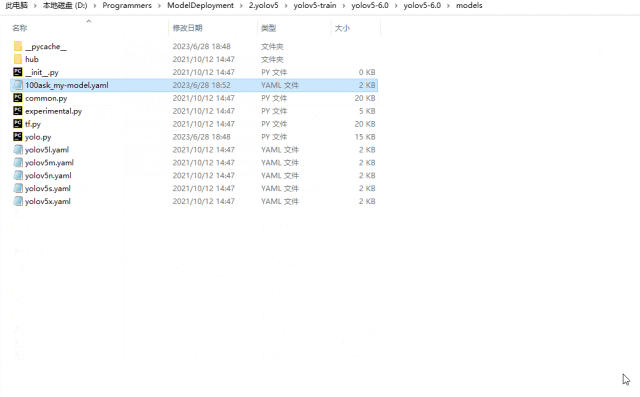
修改100ask_my-model.yaml中類的數目為自己訓練模型的類數目。
6.修改訓練函數
打開yolov5-6.0項目文件夾中的train.py,修改數據配置文件路徑,如下圖紅框所示:
parser.add_argument('--cfg', type=str, default='models/100ask_my-model.yaml', help='model.yaml path') parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path')
7.訓練模型
在conda終端的激活yolov5環境,激活后進入yolov5-6.0項目文件夾。執行python train.py,如下圖所示:
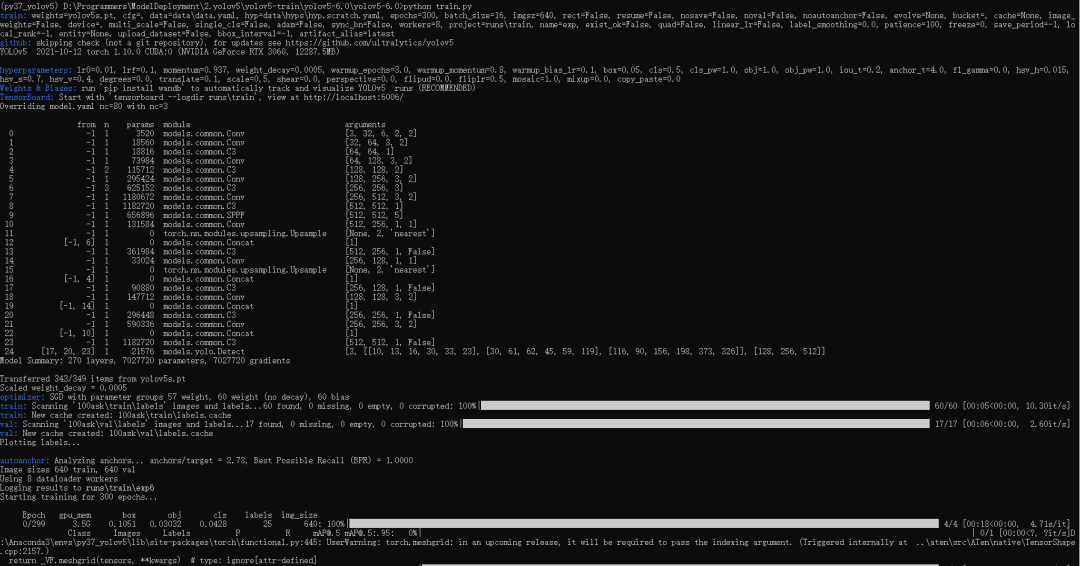
程序默認迭代300次,等待訓練完成...

訓練完成后結果會保存在runs rain目錄下最新一次的訓練結果,如上圖所示,此次訓練的最好模型和最后訓練的模型保存在以下目錄中
runs rainexp7weights
8.驗證模型
修改val.py函數,修改如下
parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path') parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp7/weights/best.pt', help='model.pt path(s)')
修改models文件夾下的yolo.py
class Model(nn.Module): def __init__(self, cfg='100ask_my-model.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
打開conda終端輸入python val.py

執行完成后的結果保存在runsvalexp文件下。
9.預測圖像
在data目錄中新建100ask-images文件夾存放待檢測的圖像和視頻文件。
修改detect.py函數中,模型的路徑與檢測圖像路徑。
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp7/weights/best.pt', help='model path(s)') parser.add_argument('--source', type=str, default=ROOT / 'data/100ask-images', help='file/dir/URL/glob, 0 for webcam')

檢測效果如下圖所示:

10.導出ONNX模型
修改export.py函數
parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path') parser.add_argument('--weights', type=str, default=ROOT / 'runs/train/exp7/weights/best.pt', help='weights path')

在conda終端輸入:
python export.py --include onnx --dynamic
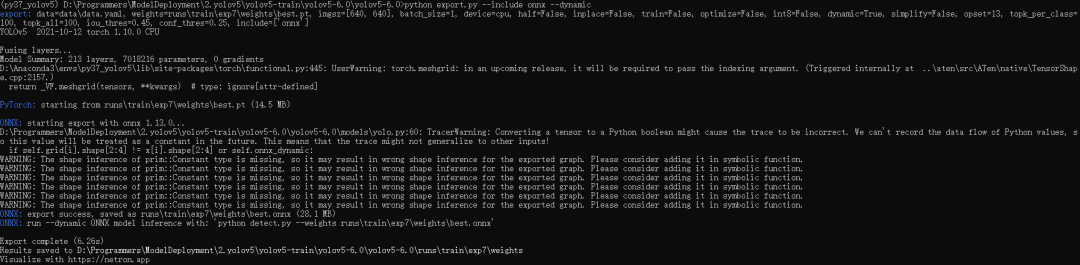
導出的模型會與輸入的模型位于同一路徑下,假設我輸入的模型位于:runs rainexp7weights
11.簡化模型
簡化模型前需要用到onnxruntime依賴包,輸入以下命令安裝:
pip install onnxruntime==1.13.1 -i https://pypi.doubanio.com/simple/
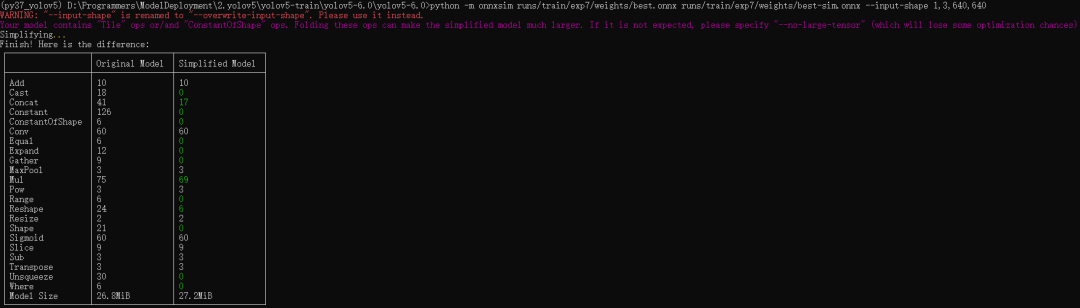
簡化命令如下:
python -m onnxsim <輸入模型> <輸出模型> --input-shape <輸入圖像尺寸>
例如:
輸入模型路徑為runs/train/exp7/weights/best.onnx,輸出模型路徑為runs/train/exp7/weights/best-sim.onnx
輸入圖像尺寸固定為640x640。
python -m onnxsim runs/train/exp7/weights/best.onnx runs/train/exp7/weights/best-sim.onnx --input-shape 1,3,640,640
13.查看模型
訪問:https://netron.app/
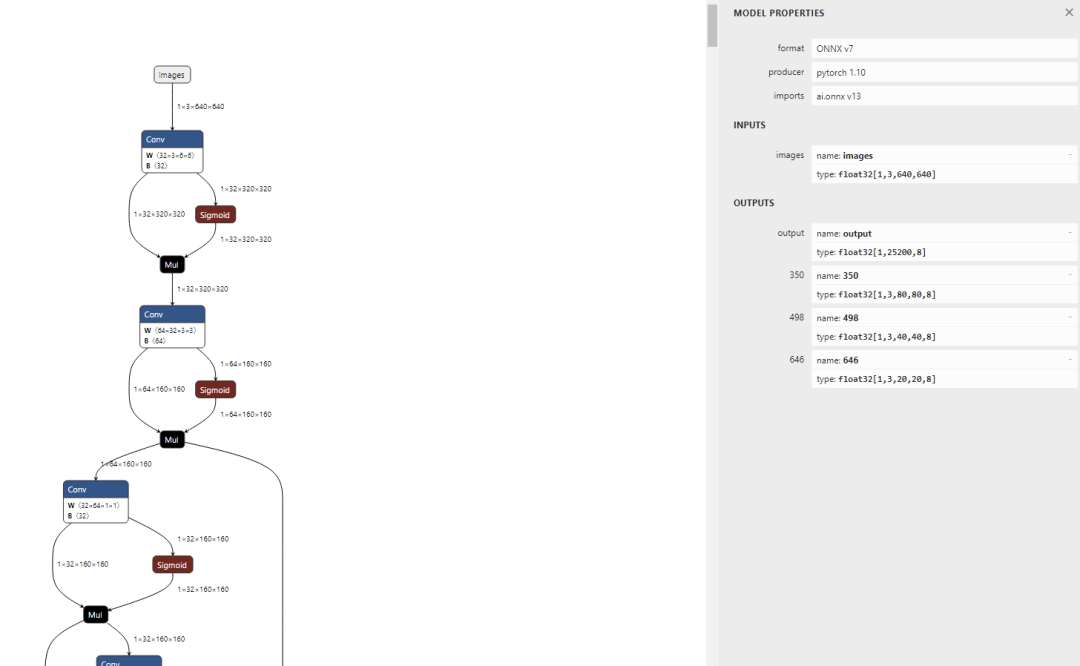
可以看到輸入已經固定為640x640,可看到模型有 4 個輸出節點,其中 ouput 節點為后處理解析后的節點;在實際測試的過程中,發現 NPU 量化操作后對后處理的運算非常不友好,輸出數據偏差較大,所以我們可以將后處理部分放在 CPU 運行;因此在導入模型時保留 350,498, 646 三個后處理解析前的輸出節點即可。
14.驗證模型
模型需要修改為簡化后的模型路徑。
新建文件夾存放固定的輸入圖像尺寸。假設上述中我設置輸入圖像尺寸為640x640,那么此時我在data目錄下新建100ask-images-640文件夾存放640x640的圖像作為待測數據。
修改detect.py函數
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp7/weights/best-sim.onnx', help='model path(s)') parser.add_argument('--source', type=str, default=ROOT / 'data/100ask-images-640', help='file/dir/URL/glob, 0 for webcam')

在conda終端輸入:
python detect.py

通過輸出信息可知:檢測結果存儲在runsdetectexp6
檢測結果如下:

15.轉換模型
15.1 創建工作目錄
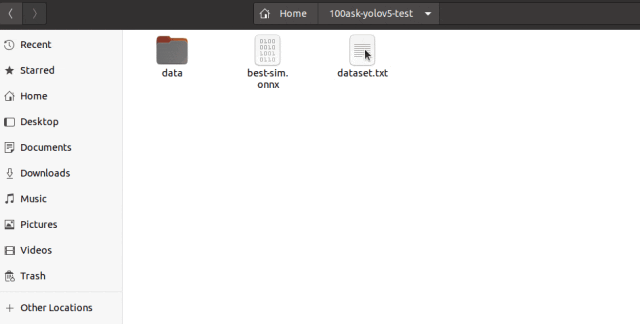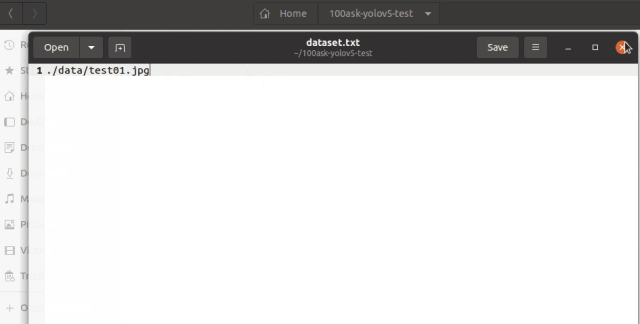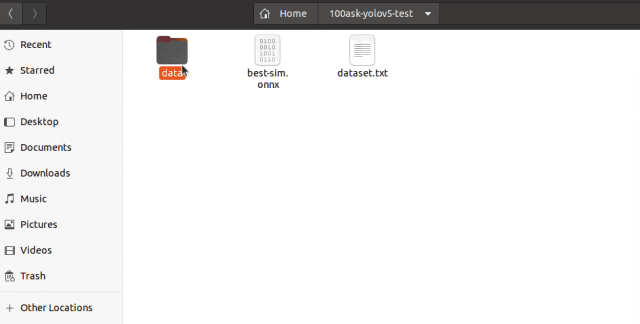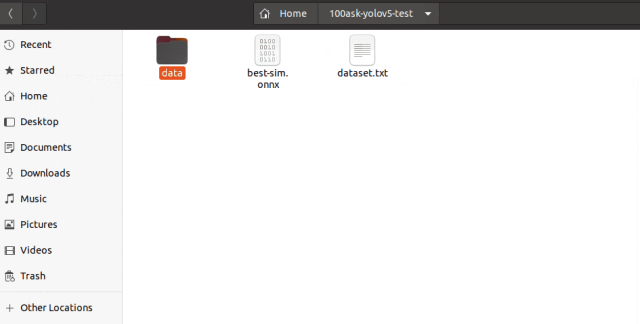
將簡化后的best-sim.onnx模型傳入配置到NPU模型轉換工具的虛擬機中,創建模型工具目錄,包含模型文件,量化文件夾data(存放量化圖片),dataset.txt文件(存放量化圖片的路徑)。
buntu@ubuntu2004:~/100ask-yolov5-test$ tree . ├── best-sim.onnx ├── data │ └── test01.jpg └── dataset.txt 1 directory, 5 files
工作目錄如下所示:
15.2 導入模型
導入模型前需要知道我們要保留的輸出節點,由之前查看到我們輸出的三個后處理節點為:350,498,646 。
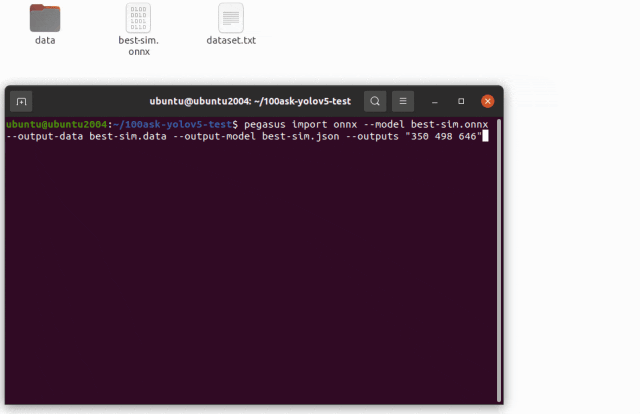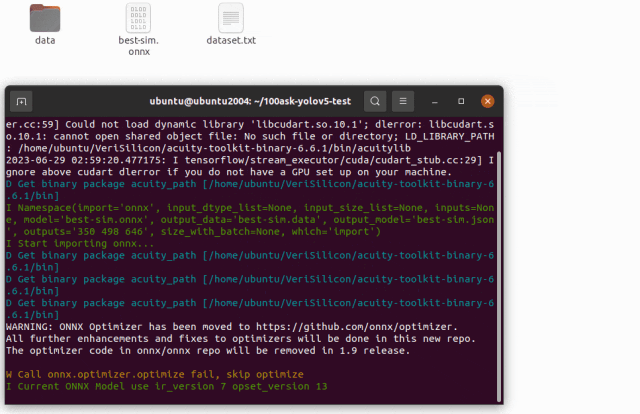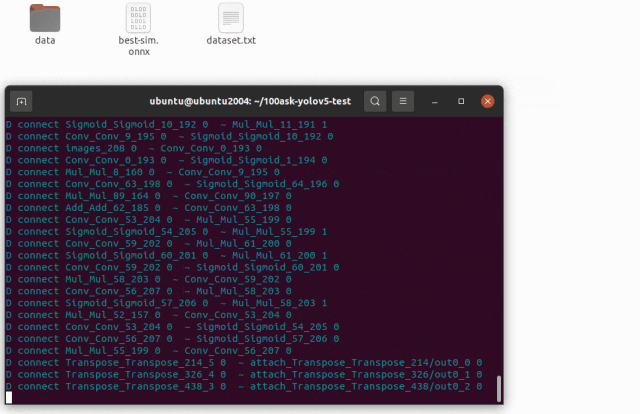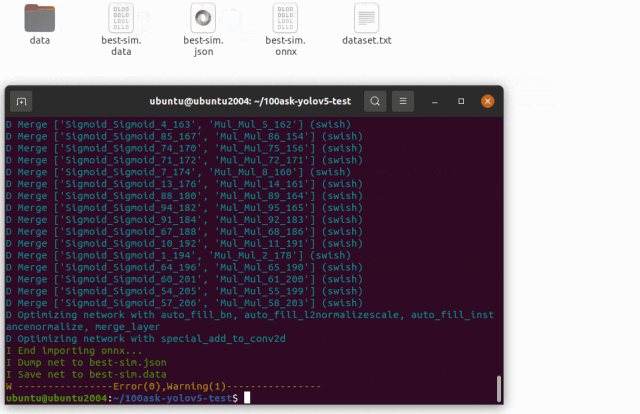
pegasus import onnx --model best-sim.onnx --output-data best-sim.data --output-model best-sim.json --outputs "350 498 646"
導入生成兩個文件,分別是是 yolov5s-sim.data 和 yolov5s-sim.json 文件,兩個文件是 YOLO V5 網絡對應的芯原內部格式表示文件,data 文件儲存權重,cfg 文件儲存模型。
15.3 生成 YML 文件
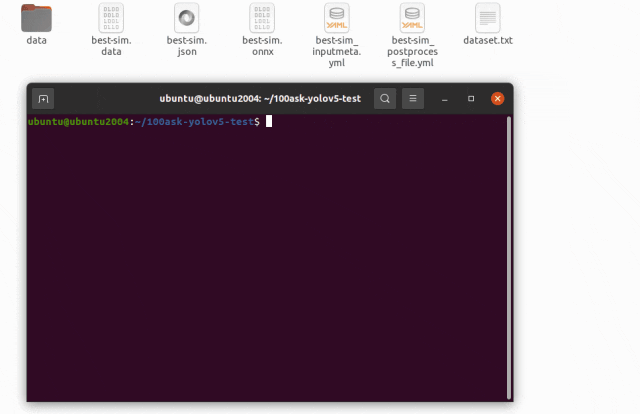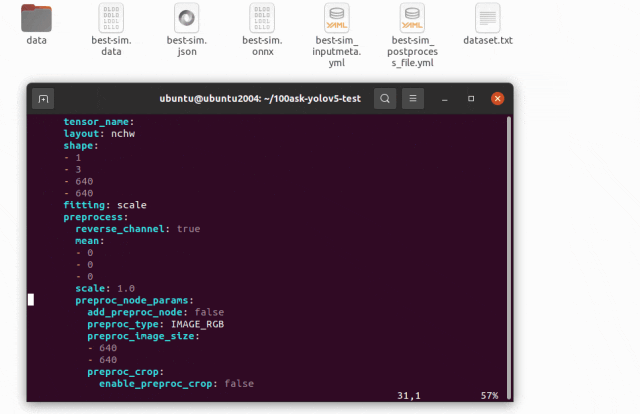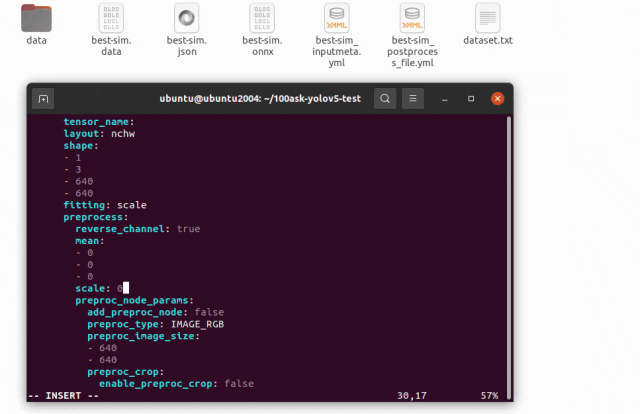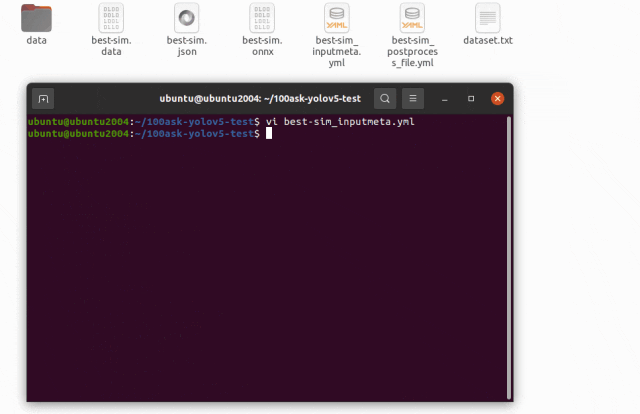
YML 文件對網絡的輸入和輸出的超參數進行描述以及配置,這些參數包括,輸入輸出 tensor 的形狀,歸一化系數 (均值,零點),圖像格式,tensor 的輸出格式,后處理方式等等
pegasus generate inputmeta --model best-sim.json --input-meta-output best-sim_inputmeta.yml
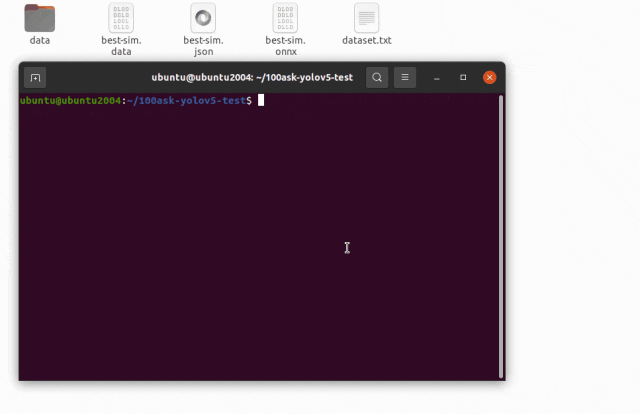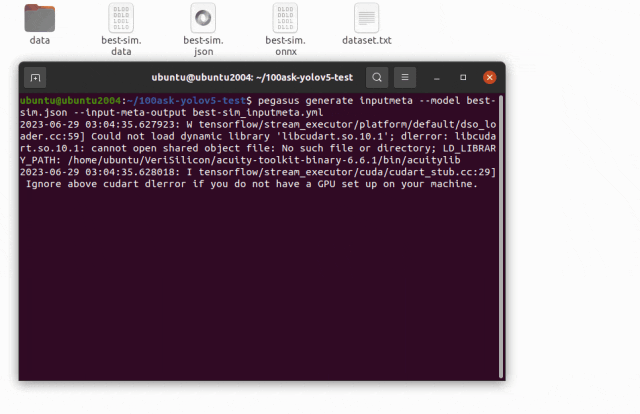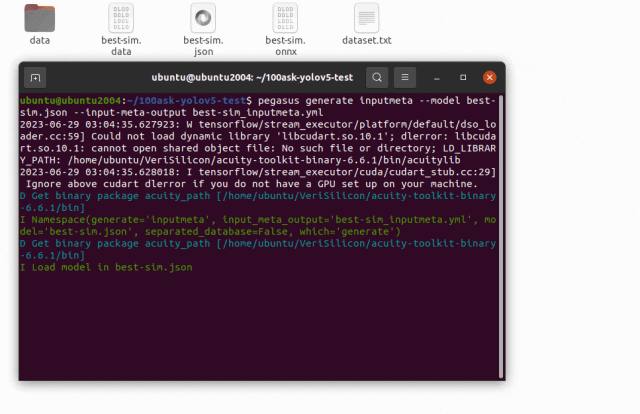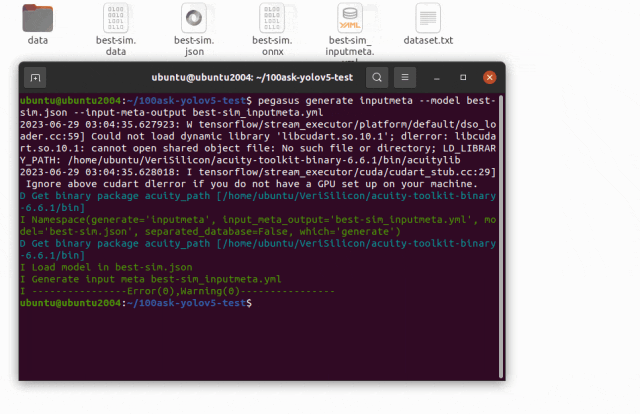
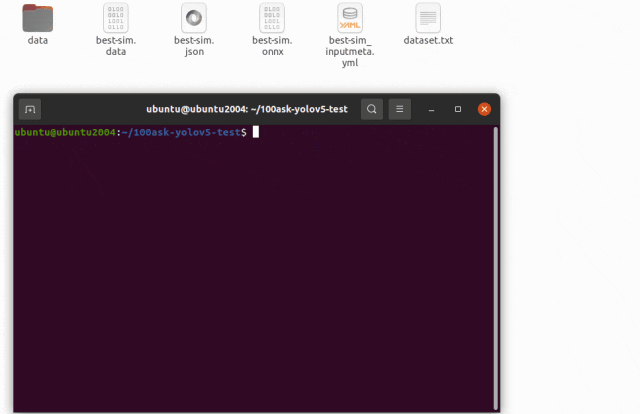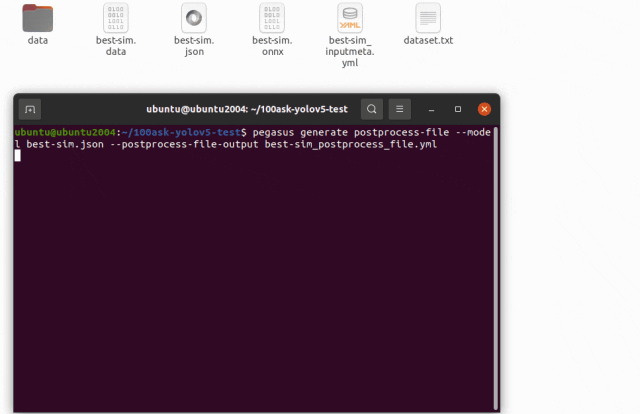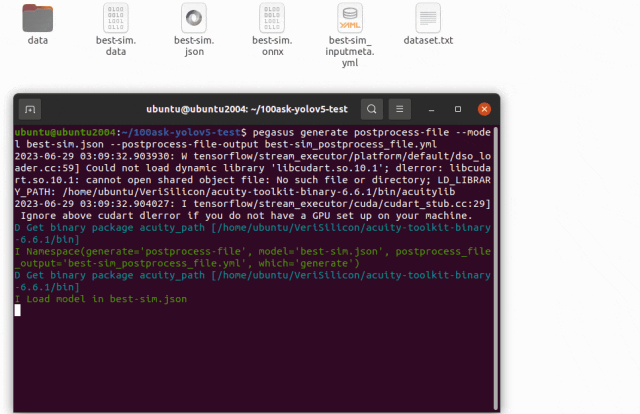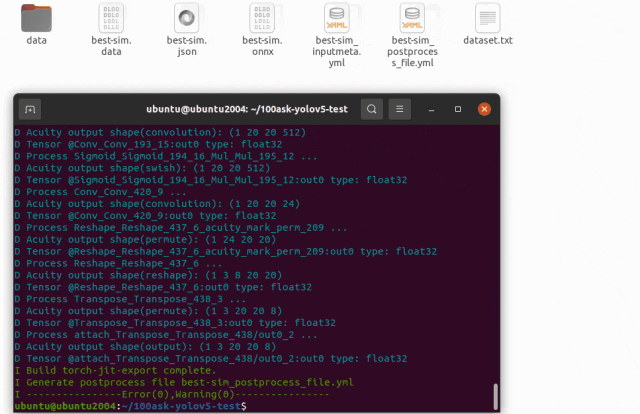
pegasus generate postprocess-file --model best-sim.json --postprocess-file-output best-sim_postprocess_file.yml
修改 best-sim_inputmeta.yml 文件中的的 scale 參數為 0.0039216(1/255),目的是對輸入 tensor 進行歸一化,和網絡進行訓練的時候是對應的。
vi best-sim_inputmeta.yml
修改過程如下圖所示:
15.4 量化
生成量化表文件,使用非對稱量化,uint8,修改 --batch-size 參數為你的 dataset.txt 里提供的圖片數量。如果原始網絡使用固定的batch_size,請使用固定的batch_size,如果原始網絡使用可變batch_size,請將此參數設置為1。
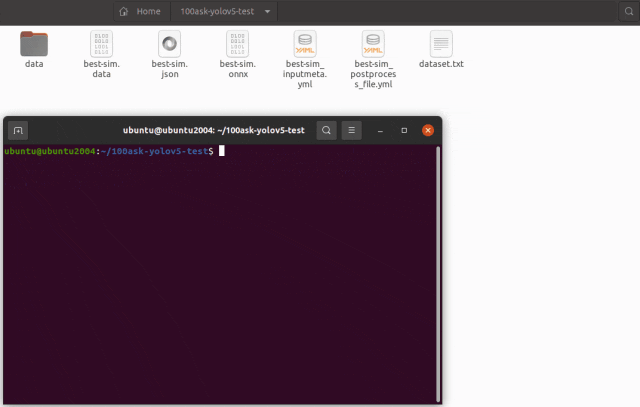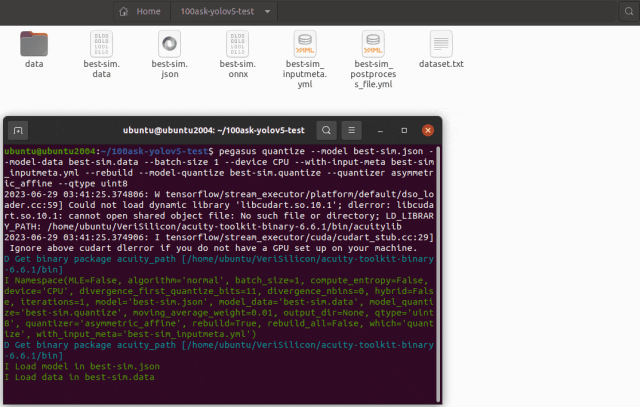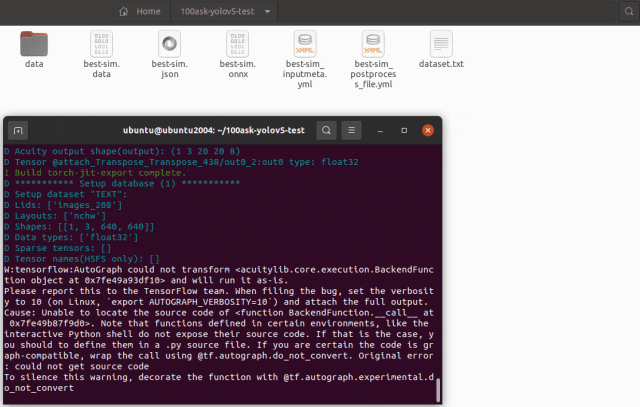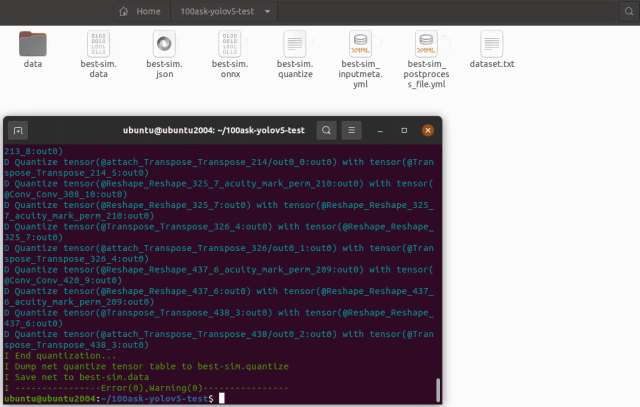
pegasus quantize --model best-sim.json --model-data best-sim.data --batch-size 1 --device CPU --with-input-meta best-sim_inputmeta.yml --rebuild --model-quantize best-sim.quantize --quantizer asymmetric_affine --qtype uint8
15.5 預推理
利用前文的量化表執行預推理,得到推理 tensor
pegasus inference --model best-sim.json --model-data best-sim.data --batch-size 1 --dtype quantized --model-quantize best-sim.quantize --device CPU --with-input-meta best-sim_inputmeta.yml --postprocess-file best-sim_postprocess_file.yml
15.6 導出模板代碼與模型
輸出的模型可以在 ovxilb/100ask-best-sim_nbg_unify 文件夾中找到network_binary.nb模型文件。
pegasus export ovxlib --model best-sim.json --model-data best-sim.data --dtype quantized --model-quantize best-sim.quantize --batch-size 1 --save-fused-graph --target-ide-project 'linux64' --with-input-meta best-sim_inputmeta.yml --output-path ovxilb/100ask-best-sim/100ask-simprj --pack-nbg-unify --postprocess-file best-sim_postprocessmeta.yml --optimize "VIP9000PICO_PID0XEE" --viv-sdk ${VIV_SDK}
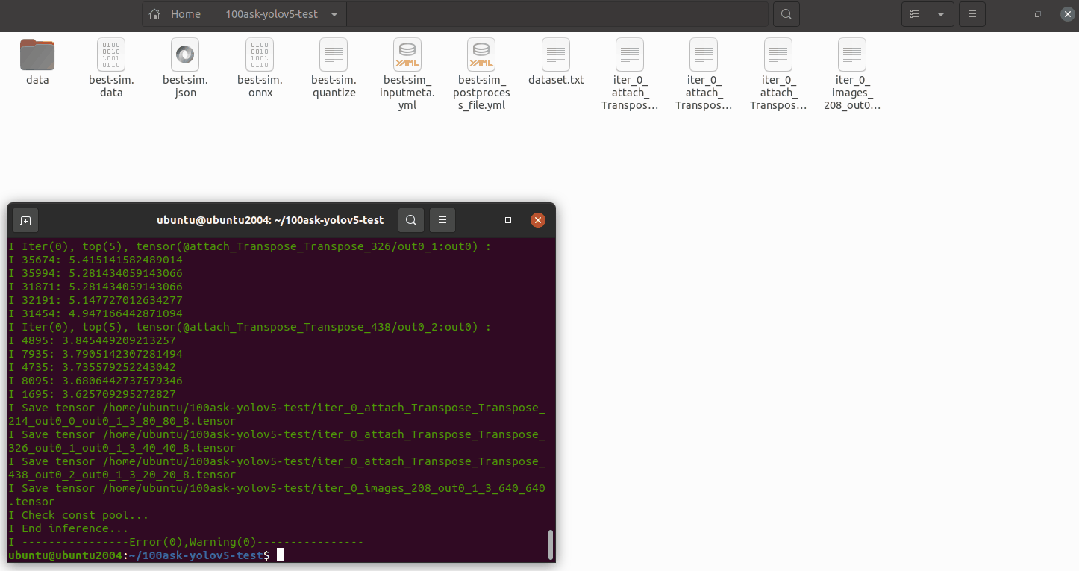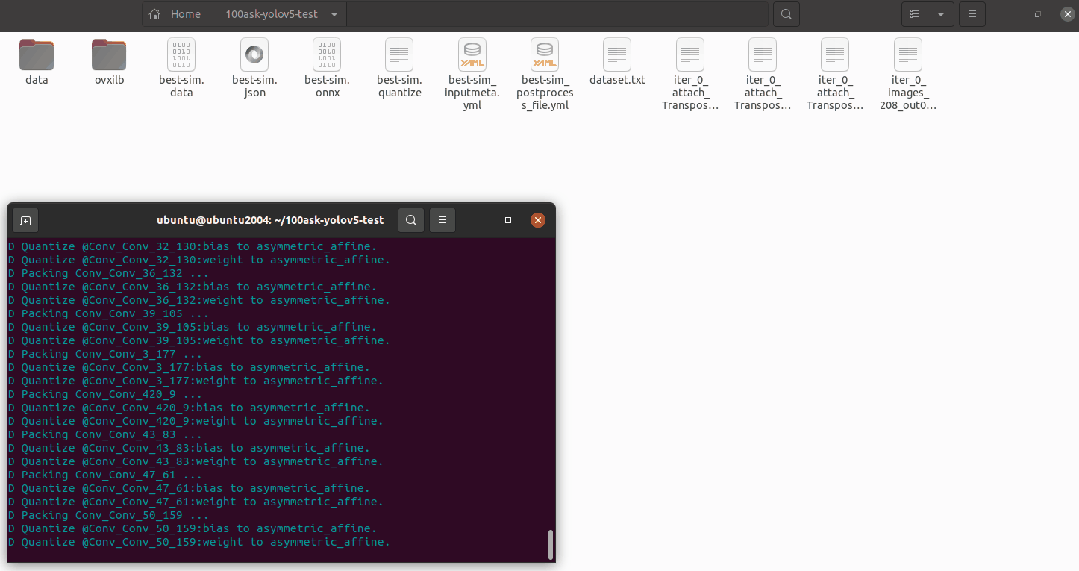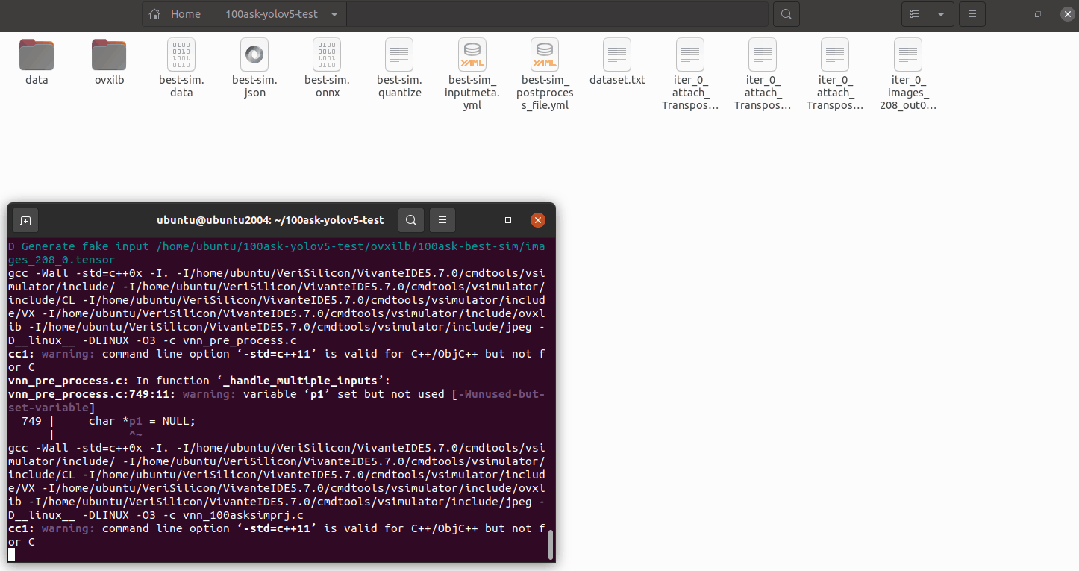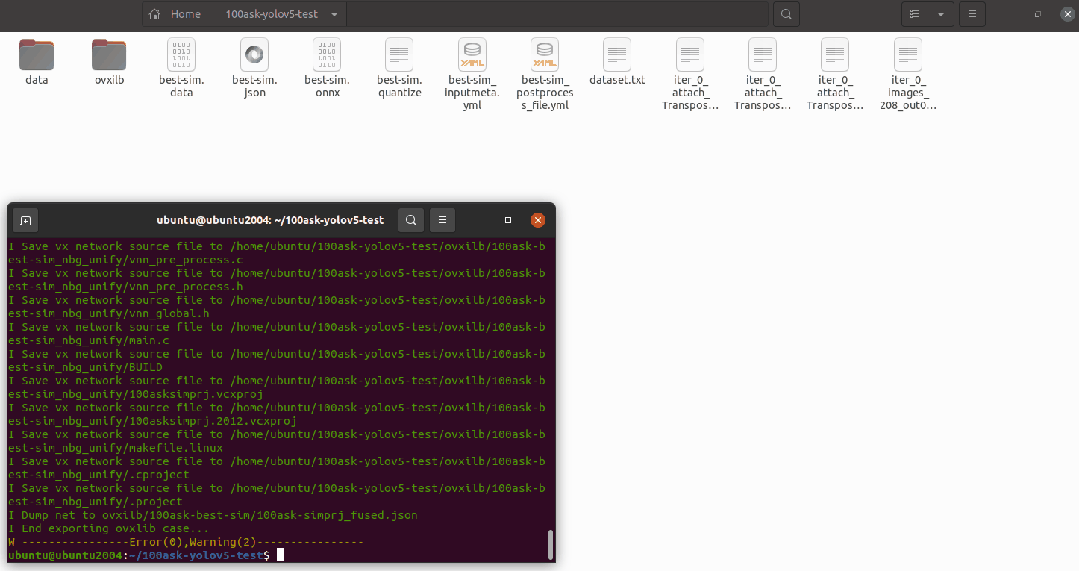
可以進入下圖所示目錄中將network_binary.nb模型文件拷貝出來備用。
16.端側部署
這里引用上一篇《100ASK-V853-PRO開發板支持yolov5模型部署》我們編寫的yolov5端側部署程序,這里進入端側部署程序文件夾中拷貝一份新程序進行修改。主要修改vnn_post_process.cpp程序。
16.1 修改draw_objects函數
修改draw_objects函數中的類名,這里我訓練的模型的類別分別是T113、K510、V853
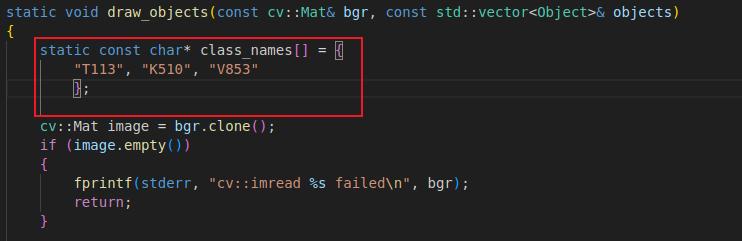
類別名稱需要yolov5-6.0項目data目錄下data.yaml對應
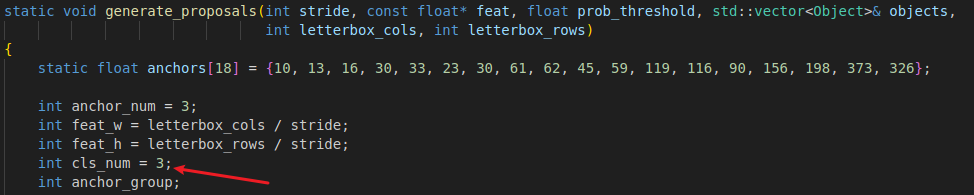
16.2 修改generate_proposals函數
修改generate_proposals函數中的類類別數量為您類別數量。假設我訓練的類別總共有T113、K510、V853,這3個類別,修改為3即可。
修改后的文件如下所示:
16.3 編譯
book@100ask:~/workspaces/tina-v853-open$ source build/envsetup.sh ... book@100ask:~/workspaces/tina-v853-open$ lunch ...1 ...
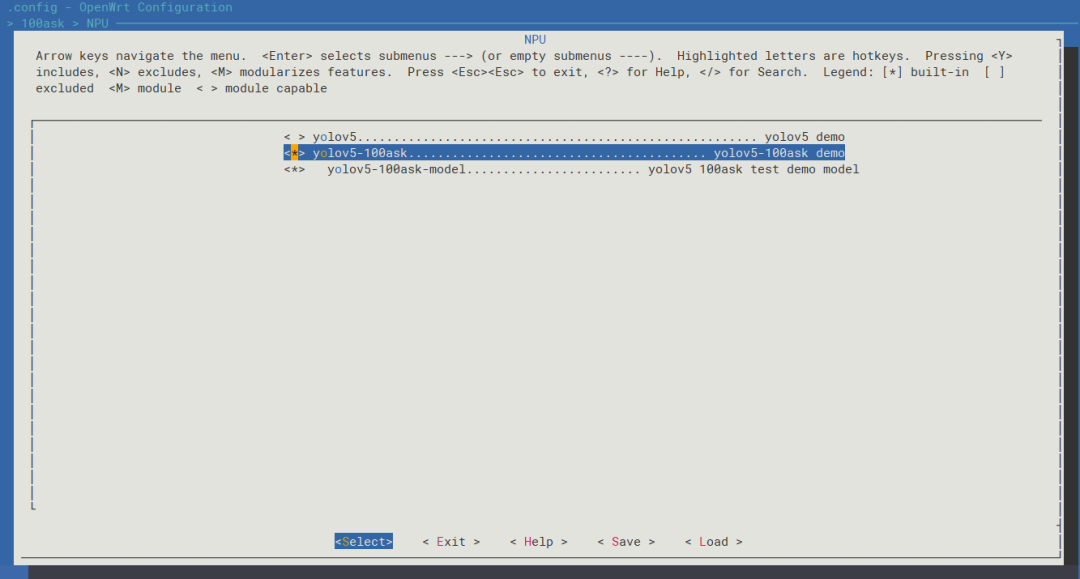
進入menuconfig,輸入
make menuconfig
進入如下目錄中,選中yolov5-100ask配置,
> 100ask > NPU <*> yolov5-100ask......................................... yolov5-100ask demo
編譯并生成鏡像
book@100ask:~/workspaces/tina-v853-open$ make ... book@100ask:~/workspaces/tina-v853-open$ pack
編譯完成后使用全志燒寫工具燒錄鏡像。
16.4 測試
主機端:
傳入640*640的圖像文件和network_binary.nb模型文件
book@100ask:~/workspaces/testImg$ adb push test-100ask.jpg /mnt/UDISK test-100ask.jpg: 1 file pushed. 0.6 MB/s (51039 bytes in 0.078s) book@100ask:~/workspaces/testImg$ adb push network_binary.nb /mnt/UDISK network_binary.nb: 1 file pushed. 0.7 MB/s (7409024 bytes in 10.043s)
開發板端:
進入/mnt/UDISK/目錄下
root@TinaLinux:/# cd /mnt/UDISK/ root@TinaLinux:/mnt/UDISK# ls lost+found network_binary.nb overlay test-100ask.jpg
運行yolov5檢測程序
yolov5-100ask network_binary.nb test-100ask.jpg
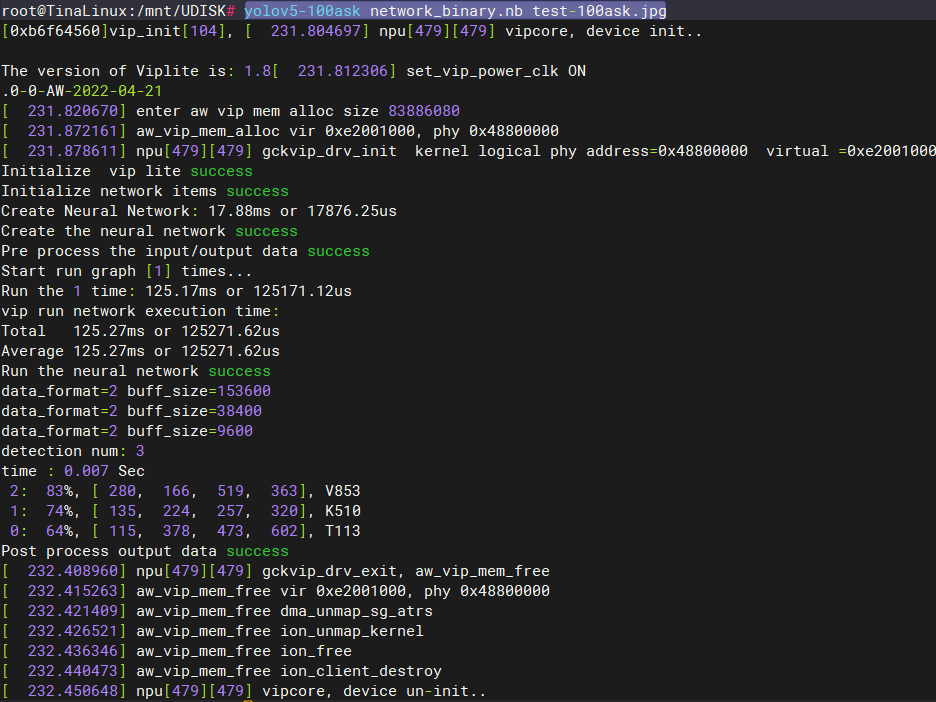
執行完成后會在當前目錄下生成輸出文件yolov5_out.jpg
root@TinaLinux:/mnt/UDISK# ls lost+found overlay yolov5_out.jpg network_binary.nb test-100ask.jpg
主機端:
拉取開發板端的輸出圖像yolov5_out.jpg
book@100ask:~/workspaces/testImg$ adb pull /mnt/UDISK/yolov5_out.jpg ./ /mnt/UDISK/yolov5_out.jpg: 1 file pulled. 0.8 MB/s (98685 bytes in 0.116s)
17.檢測效果圖

-
圖像
+關注
關注
2文章
1089瀏覽量
40571 -
模型
+關注
關注
1文章
3305瀏覽量
49217 -
數據集
+關注
關注
4文章
1209瀏覽量
24829
原文標題:V853端側部署YOLOV5訓練自定義模型 全流程教程
文章出處:【微信號:baiwenkeji,微信公眾號:百問科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于YOLOv8實現自定義姿態評估模型訓練

龍哥手把手教你學視覺-深度學習YOLOV5篇
怎樣使用PyTorch Hub去加載YOLOv5模型
全志V853 在 NPU 轉換 YOLO V3 模型
全志V853常用模型跑分數據

在C++中使用OpenVINO工具包部署YOLOv5模型
使用旭日X3派的BPU部署Yolov5

【教程】yolov5訓練部署全鏈路教程


在樹莓派上部署YOLOv5進行動物目標檢測的完整流程





 工商網監
工商網監
評論