 NIO的自動駕駛AI推理工作流
NIO的自動駕駛AI推理工作流
自動駕駛汽車必須能夠快速準確地檢測物體,以確保其駕駛員和道路上其他駕駛員的安全。由于自動駕駛( AD )和視覺檢查用例中對實時處理的需求,具有預處理和后處理邏輯的多個 AI 模型 組合在流水線中,并用于 機器學習( ML )推理。
流水線的每一步都需要加速,以確保低延遲工作流。延遲是獲取推理響應所需的時間。更快地處理 AD 數據將能夠更有效地分析和使用信息,創造更安全的駕駛環境。任何一個方面的延遲都會降低整個管道的速度。
為了實現低延遲推理工作流,電動汽車制造商 NIO 將 NVIDIA Triton 推理服務器集成到其 AD 推理管道中。 NVIDIA Triton 推理服務器是一個開源的多幀推理服務軟件。
這篇文章解釋了 NIO 如何在 GPU 上使用 NVIDIA Triton 協調其圖像預處理、后處理和 AI 模型的管道。它還展示了 NIO 如何減少網絡傳輸,以成功加快 AD 用例的 AI 推理工作流。
用于實時響應的更快 AI 推理
NIO 設計、開發、聯合制造和銷售高級智能電動汽車,推動自動駕駛、數字技術、電動動力系統和電池等新一代技術的創新。 NIO 自動駕駛開發平臺( NADP )是一個致力于 NIO 核心自動駕駛服務的研發平臺。
NIO 選擇 NVIDIA Triton Inference Server 是因為幾個關鍵的技術和操作原因,包括:
NVIDIA Triton 支持基于 DAG 的多種模型編排,以及預處理或后處理模塊
NVIDIA Triton 的云原生部署實現了多 GPU 、多節點的輕量級擴展
高質量的文檔和學習資源有助于輕松遷移到 NVIDIA Triton
NVIDIA Triton 的穩定性和強大功能是 AD 用例所必需的
NIO 的自動駕駛 AI 推理工作流
數百個人工智能模型用于從自動駕駛汽車中挖掘數據。在自動駕駛這樣的用例中,推理工作流由多個 AI 模型組成,其中預處理和后處理邏輯在流水線中拼接在一起。
NIO 將管道的預處理和后處理從運行在 CPU 上的客戶端移動到運行在 GPU 上的 NVIDIA Triton 。 NVIDIA Triton 的業務邏輯腳本( BLS )功能用于協調管道,以優化 AD 使用。
通過將預處理從 CPU 移動到 GPU 并利用高效的管道編排, NIO 在一些核心管道中實現了 6 倍的延遲減少,將總吞吐量提高了 5 倍。
工作流管道之前和之后如圖 1 所示。
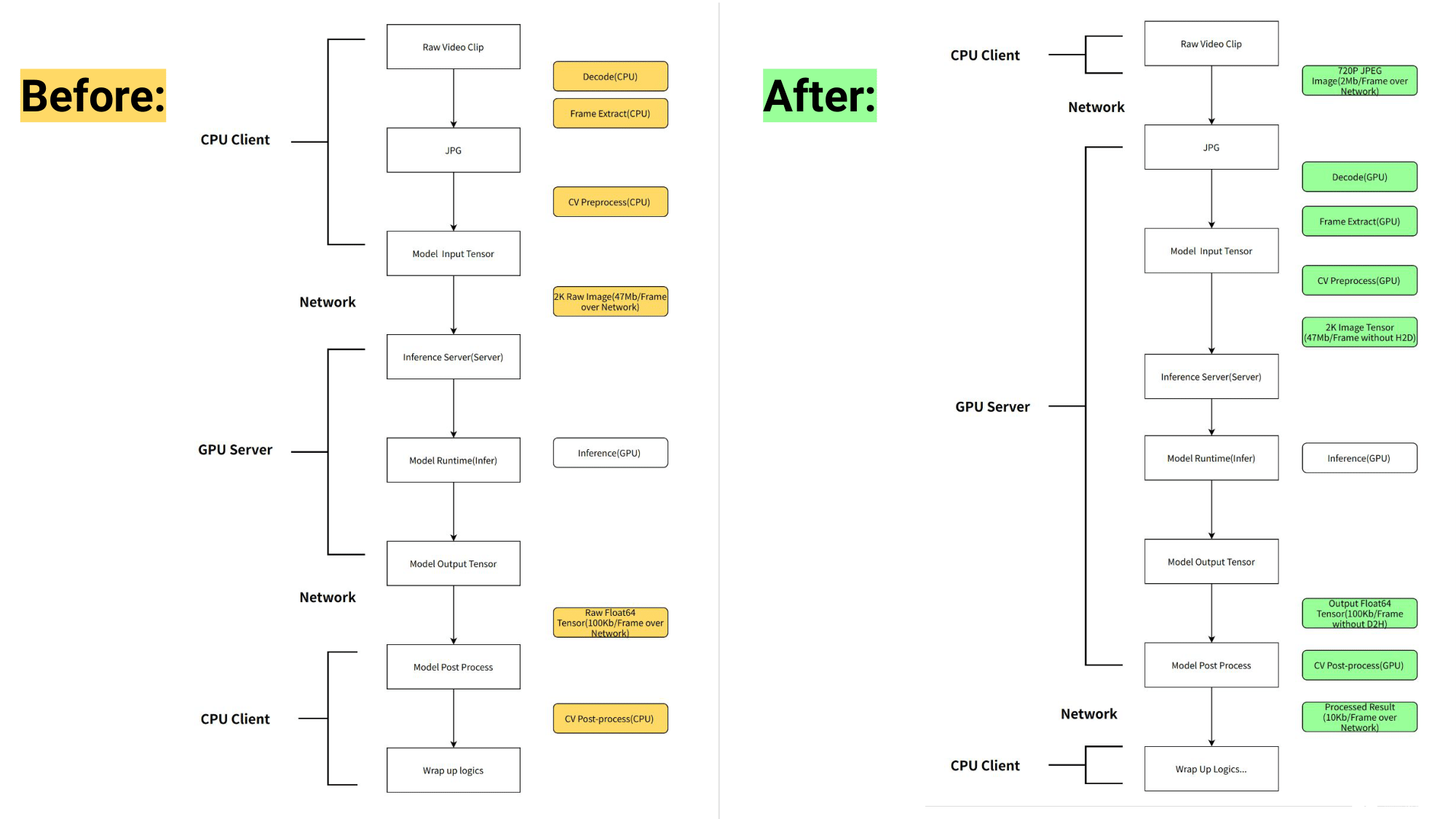
圖 1. NVIDIA Triton 推理服務器推出之前(左)和之后(右) NIO AI 推理工作流的比較
NVIDIA Triton 的模型管道編排優勢
本節探討了 NIO 通過集成 NVIDIA Triton 實現的每一項好處。
GPU 加速預處理
NVIDIA Triton 使用 nvJPEG 和 NVIDIA DALI 在 GPU 上加速了解碼、調整大小和換位等預處理任務。這顯著減輕了客戶端 CPU 的計算工作量,并減少了預處理延遲。
升級模型而無需修改客戶端應用程序
通過將模型的預處理和后處理移至 NVIDIA Triton ,每次升級模型時,客戶端不需要任何修改。這實質上加快了模型的推出,幫助其更快地達到生產。
使用單個 GPU 節點減少網絡數據傳輸開銷
統一的預處理使輸入的多個副本能夠與多個后端識別模型共享。該過程在服務器端使用 GPU 共享內存,無需數據傳輸開銷。
圖 2 顯示了該管道可以使用 NVIDIA Triton 業務邏輯腳本功能連接多達九個模型。
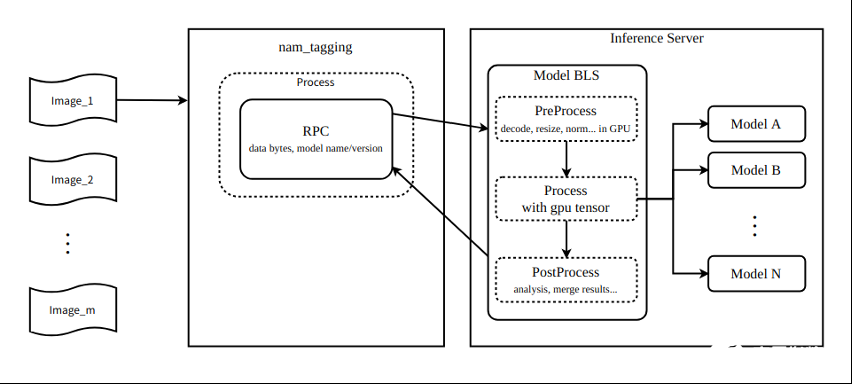
圖 2. NVIDIA Triton 業務邏輯腳本的模型管道編排
對于 2K 分辨率的輸入圖像,每幀的大小為 1920 x 1080 x 3 x 8 = 47 Mb 。假設全幀速率為 60 fps ,每秒輸入的數據量為 1920 x 1080 x 3 x 8 x 60 = 2847 Mb 。在前一個工作流中,每個圖像通過網絡依次發送給九個模型。每秒傳輸的數據為 1920 x 1080 x 3 x 8 x 60 x 9 = 25 Gb = 3 Gb 。
在新的工作流程中,九個模型與 NVIDIA Triton 業務邏輯腳本配合。這意味著模型可以訪問 GPU 共享存儲器中的圖像,并且圖像不必通過網絡發送。假設 PCIe 帶寬為 160 Gb =每秒 20 Gb ,理論上,如果通過 PCIe 傳輸數據,每秒生成的數據可以節省 150 毫秒的數據傳輸時間。
假設可用帶寬為 16 Gb =每秒 2 Gb ,理論上,如果數據通過網絡傳輸,每秒生成的數據可以節省 1500 毫秒的數據傳輸時間。所有這些都會加快工作流程。
使用圖像壓縮節省網絡傳輸
為了進行準確的模型預測,輸入圖像必須為 1920 x 1080 x 3 x 8 字節,并且必須通過網絡傳輸。在引入服務器端預處理之后,可以在允許的精度損失范圍內將原始圖像更改為壓縮的三通道 720 像素圖像( 1280 x 720 x 3 )。
因此,只需幾百 KB 即可傳輸壓縮圖像的字節,并在服務器上以最小的精度損失將大小調整為 1920 x 1080 x 3 x 8 字節。這導致了額外的網絡傳輸節省,加快了工作流程。
NADP 推理平臺中的易集成性
NIO 目前基于 NVIDIA Triton 的推理平臺是其自動駕駛開發平臺( NADP )的關鍵組件,用于其自動駕駛解決方案。
由于 NIO 平臺構建在 Kubernetes ( K8s )上, NVIDIA Triton 必須與 Kubernete 良好集成。工作流程的組件圍繞 NVIDIA Triton 實現為 K8s CRD (本地和自定義)。
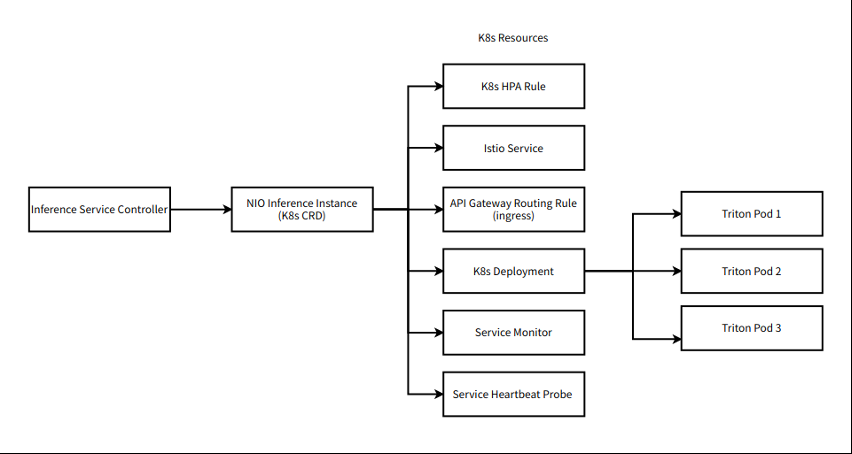
圖 3.NIO 在 Kubernetes 中的機器學習工作流
持續集成/持續交付( CI / CD )
Argo 是 Kubernetes 中用于協調工作流的引擎。它有助于開發、量化、訪問、云部署、壓力測試和發布中涉及的所有組件的 CI / CD 。 NVIDIA Triton 通過在加載模型時觸發工作流中的下一步來幫助 CI / CD 。
此外, NVIDIA Triton Docker 容器的使用有助于在開發、測試和部署環境中實現一致的功能。
將 Jupyter 環境無縫集成到 NVIDIA Triton 圖像中。 Jupyter 為需要在線調試或離線復制的復雜問題提供了一個方便的開發環境。
易用 Istio 部署
NVIDIA Triton 本機支持與應用程序通信的 gRPC 協議。然而,由于 Kubernetes 本地服務無法為 gRPC 提供有效的請求級負載平衡, NVIDIA Triton 與 Istio 服務網格集成。 Istio 用于對 NVIDIA Triton 推理服務器的流量進行負載平衡,并通過 NVIDIA Triton 的活躍度/就緒性探針監測服務的運行狀況。
阿波羅配置管理易于使用
阿波羅配置中心用于基于模型名稱的服務發現。用戶可以訪問模型,而不知道模型部署的特定域名。結合 NVIDIA Triton 模型存儲庫,用戶可以直接觸發模型的部署。
普羅米修斯和格拉法納的指標
NVIDIA Triton 基于模型維度提供了一整套模型服務指標。例如, NVIDIA Triton 可以區分推理請求排隊時間和 GPU 計算時間,從而實現在線模型服務性能的細粒度診斷和分析,而無需進入調試模式。
由于 NVIDIA Triton 支持云原生主流 Prometheus / Grafana ,用戶可以輕松配置每個維度的儀表板和警報,為高服務可用性提供指標支持。
關鍵要點
NIO 的優化工作流程集成了 NVIDIA Triton 推理服務器,使一些核心管道的延遲減少了 6 倍。這將總吞吐量提高了 5 倍。
通過使用 NVIDIA Triton 管道編排功能將預處理邏輯移至 GPU , NIO 實現了:
更快的圖像處理
釋放 CPU 容量
減少網絡傳輸開銷
更高的推理吞吐量
NIO 使用 NVIDIA Triton 推理服務器實現了 AI 推理工作流加速。 NVIDIA Triton 也很容易集成到基于 Kubernetes 的強大可擴展解決方案中。
-
NVIDIA
+關注
關注
14文章
5076瀏覽量
103720 -
AI
+關注
關注
87文章
31513瀏覽量
270330 -
自動駕駛
+關注
關注
785文章
13930瀏覽量
167007
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論