 X-RiSAWOZ: 高質量端到端多語言任務型對話數據集
X-RiSAWOZ: 高質量端到端多語言任務型對話數據集
1.
引言
由于構建任務型對話數據集的成本較高,目前任務型對話的研究主要集中在少數流行語言上(如英語和中文)。為了降低新語言的數據采集成本,我們通過結合純人工翻譯和人工編輯機器翻譯結果的方式創建了一個新的多語言基準——X-RiSAWOZ,該數據集將中文RiSAWOZ翻譯成4種語言:英語、法語、印地語、韓語,以及1種語碼混合場景(印地語-英語混合)。X-RiSAWOZ中每種語言都有超過18,000個經過人類驗證的對話語句,與之前大多數多語言工作不同的是,它是一個端到端的數據集,可用于建立功能齊全的對話代理。除數據集外,我們還構建了標注和處理工具,使得向現有數據集中添加新語言變得更快、更經濟。
2.
數據集介紹
任務定義:端到端任務型對話通常被分解為若干子任務,這些任務可以由流水線系統或單個神經網絡執行。下圖展示了這些子任務及其輸入和輸出:
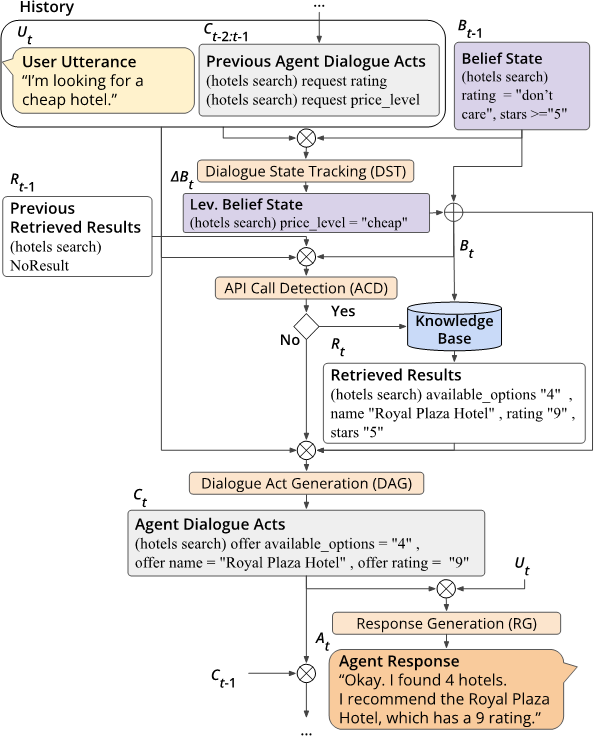
圖1:端到端任務型對話流程
數據來源:我們翻譯了RiSAWOZ數據集的驗證集與測試集,同時為了促進少樣本對話系統的研究,我們還隨機選取了1%的訓練集進行翻譯,統計數據如下表所示:
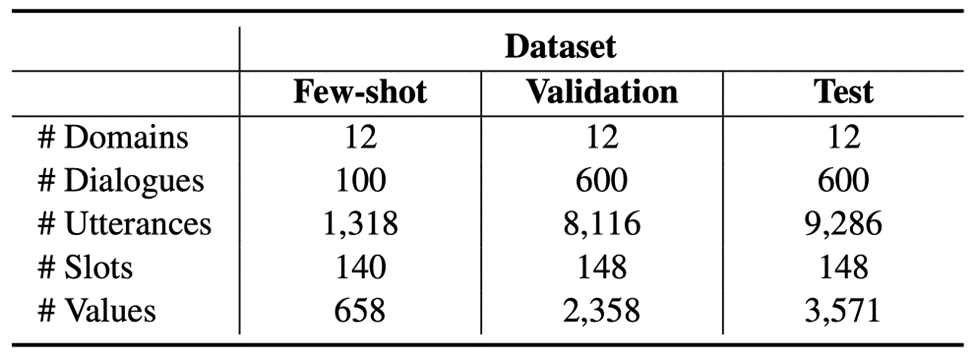
圖2:X-RiSAWOZ數據集統計
數據集構建方案:為了實現低成本和高質量的多語言端到端任務型對話數據構建,我們使用以下幾種技術從源語言數據(中文RiSAWOZ數據集)創建目標語言的訓練數據:
1. 翻譯:為了在質量和成本之間取得平衡,我們使用純人工翻譯從中文翻譯成英文,并使用機器翻譯和后期編輯將英語數據翻譯成其他語言,以盡可能避免兩次翻譯過程中可能的錯誤傳播。
2. 對齊:我們提出了一種混合對齊策略,以確保實體在話語和信念狀態中都能被替換為所需的翻譯。具體而言,我們首先嘗試使用基于實體標注構建的字典對齊,如果輸出中沒有匹配的翻譯,則退回到神經對齊(即使用encoder-decoder cross-attention權重匹配源語言和目標語言中相對應的實體)。
3. 自動標注檢查:我們開發了一個標注檢查器來自動標記和糾正可能存在的錯誤,包括1)實體檢查階段——確保在實體的英語翻譯中所做的更改傳播到其他目標語言的翻譯,以及2)API檢查階段——通過將翻譯后API調用的結果與提供的真實值進行比較來檢查API的一致性。
數據構建與檢查的流程如下圖所示:
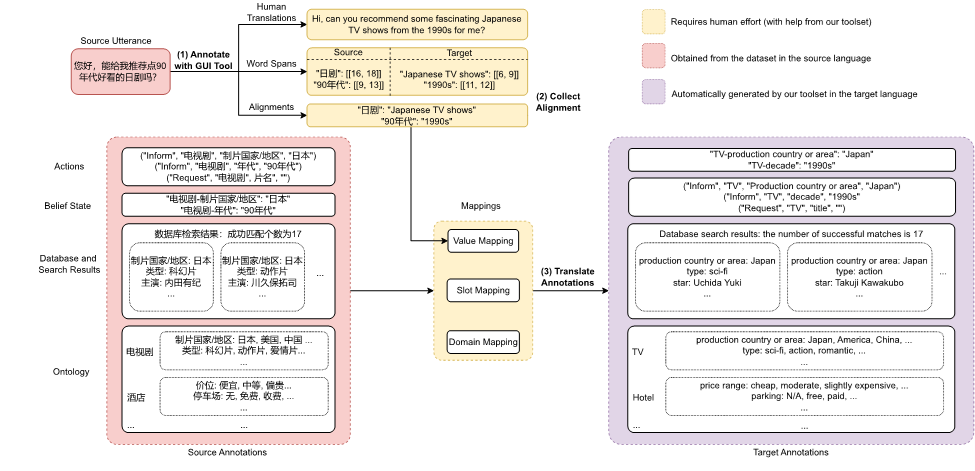
圖3:數據集構建流程(以漢語到英語為例)
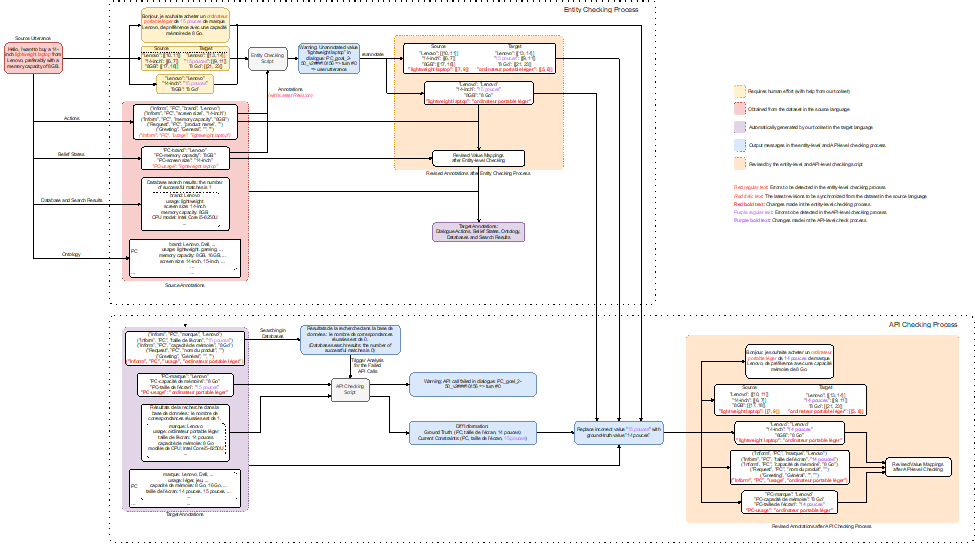
圖4:數據集檢查流程(以漢語到法語為例)
3.
實驗結果
我們使用了mBART和m2m100 (for Korean only) 進行實驗。對于零樣本實驗,我們不使用任何人工創建的目標語言數據,只使用基于機器翻譯自動創建訓練數據。對于少樣本實驗,我們從零樣本模型開始,并在目標語言的少樣本數據集上進一步對其進行微調。實驗的評估方式有兩種:Turn by Turn Evaluation和Full Conversation Evaluation。
Turn by Turn Evaluation:在這種設定下,我們在評估中使用所有先前輪次和子任務的ground truth數據作為輸入。結果表明,在零樣本設置中,性能因添加的語言而異,各個語言在對話狀態追蹤 (DST)達到了34.6%-84.2%的準確率,在對話動作生成 (DA)上達到了42.8%-67.3%的準確率,而在回復生成 (RG)上達到10.2-29.9的BLEU值,這意味著零樣本任務型對話在低資源語言場景下仍然是極具挑戰的任務。在少樣本數據上進行微調可以改善所有語言的所有指標,其中DST提高到60.7%-84.6%,DA提高到38.0%-70.5%,而BLEU則提高到了28.5-46.4。從下圖的數據中可以看到,在印地語、韓語和英語-印地語中,DST的改進尤其明顯,因為在這些語言中,機器翻譯的質量可能不太好。盡管如此,將自動翻譯的數據添加到訓練中也能夠大大提高這些語言上任務型對話系統的準確性,超過了僅用少量人工構建數據訓練的效果。
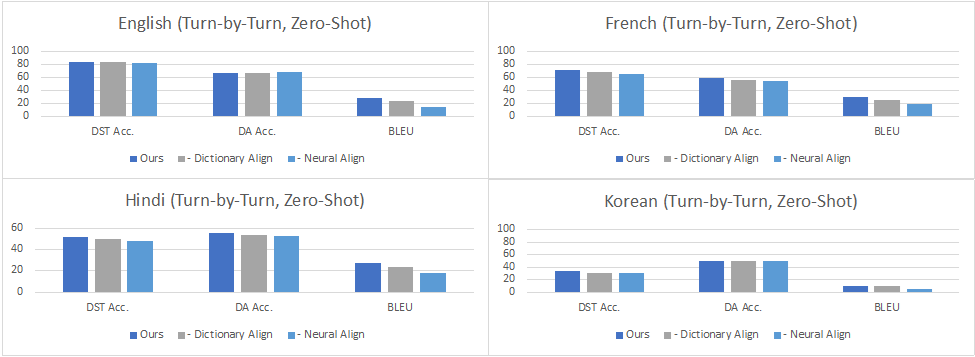
圖5:零樣本Turn by Turn Evaluation的結果
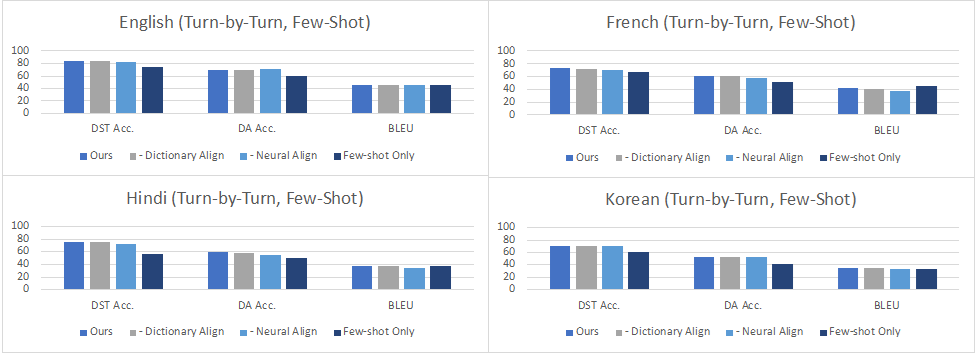
圖6:少樣本Turn by Turn Evaluation的結果
Full Conversation Evaluation:在這種設定下,對于每個輪次,模型從上一個子任務的輸出中獲取輸入,用于下一個子任務。這反映了與用戶進行交互式對話時的實際情況。結果顯示,在零樣本設置中,性能同樣因語言而異,其中英語、法語、印地語、韓語和英語-印地語的對話成功率分別達到了使用完整數據訓練的中文對話模型的35%、16%、9%、11%和4%。在少-shot設置中,這個比率提高到了38%、26%、25%、23%和5%。可以看到,最小和最大的改進分別在英語和印地語數據集上。這表明,當預訓練數據的質量較低時,少樣本數據的影響更大,這可能與中文和目標語言之間的翻譯模型的質量有關。
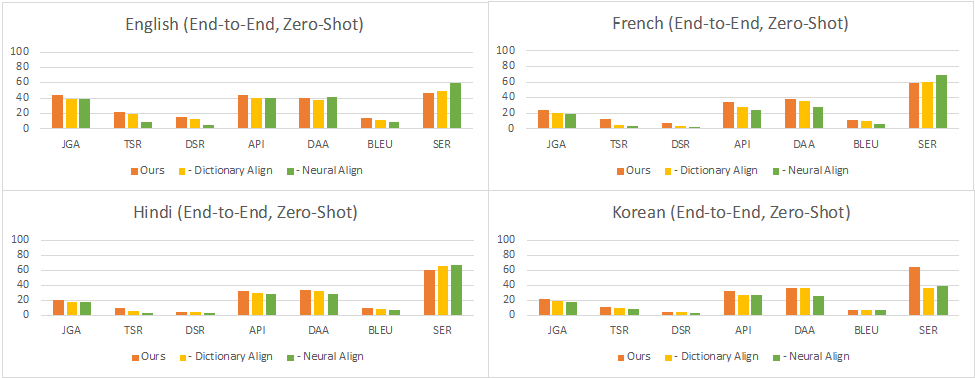
圖7:零樣本full conversation evaluation的結果
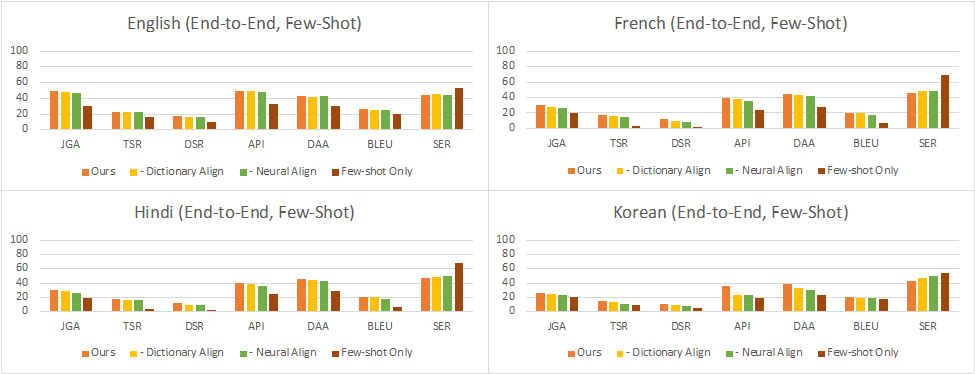
圖8:少樣本full conversation evaluation的結果
4.
結語
我們構建了X-RiSAWOZ,這是一個新的端到端、高質量、大規模的多領域多語種對話數據集,其涵蓋了5種不同的語言和1種語碼混合場景,以及一個工具包,以便將數據翻譯成其他語言。我們還為跨語言遷移的零/少樣本對話系統提供了強大的基線系統。總體而言,我們的工作為更高效、更具成本效益的多語言任務型對話系統的開發鋪平了道路。
-
神經網絡
+關注
關注
42文章
4780瀏覽量
101175 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14947 -
數據集
+關注
關注
4文章
1209瀏覽量
24835
原文標題:開源數據 | X-RiSAWOZ: 高質量端到端多語言任務型對話數據集
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
多語言開發的流程詳解
XMOS推出用于高質量音頻再現的端對端數字iPhone 底座
SoC多語言協同驗證平臺技術研究
Mozilla使用開源Common Voice語音識別數據集進行多語言操作
2021年OPPO開發者大會 端到端生成式對話模式






 工商網監
工商網監
評論