 RISC-V 跑大模型(二):LLaMA零基礎移植教程
RISC-V 跑大模型(二):LLaMA零基礎移植教程
這是RISC-V跑大模型系列的第二篇文章,主要教大家如何將LLaMA移植到RISC-V環境里。
1. 環境準備
2)確保機器有足夠的內存加載完整模型(7B模型需要13~15G)
3)下載原版LLaMA模型和擴展了的中文模型
LLaMA原版模型:
https://ipfs.io/ipfs/Qmb9y5GCkTG7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
2. 模型下載
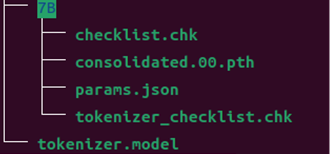
從LLaMA原版模型地址上下載下述文件(我們使用的是7B):

最后文件下載完成后的結果如下:
3. 加載并啟動
1)這一步需要下載llama.cpp,請輸入以下命令進行下載和編譯:
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make
2)將第二步下載的文件移到llama.cpp/models/下,使用命令:
python3 convert-pth-to-ggml.py models/7B/ 0
3)將.pth模型權重轉換為ggml的FP32格式,生成文件路徑為models/7B/ggml-model-f32.bin。
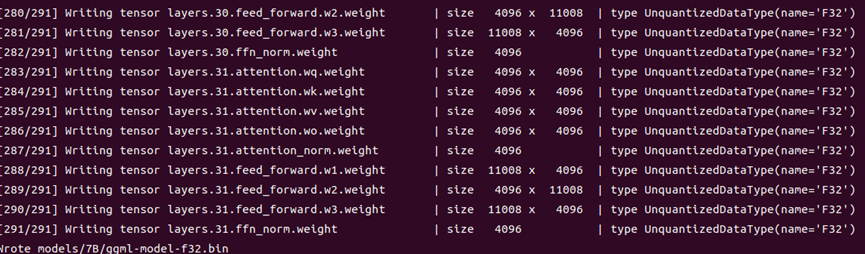
4)運行./main二進制文件,-m命令指定Q4量化模型(也可加載ggml-FP16的模型)。以下是解碼參數:
./main models/7B/ggml-model-f32.bin --color -f prompts/alpaca.txt -ins -c 256 --temp 0.2 -n 128 --repeat_penalty 1.3
參數解釋:
| -ins | 啟動類ChatGPT對話交流的運行模式 |
| -f | 指定prompt模板,alpaca模型請加載prompts/alpaca.txt |
| -c | 控制上下文的長度,值越大越能參考更長的對話歷史(默認:512) |
| -n | 控制回復生成的最大長度(默認:128) |
| -t | 控制batch size(默認:8),可適當增加 |
| --repeat_penalty | 控制線程數量(默認:4),可適當增加 |
| --temp | 控制線程數量(默認:4),可適當增加 |
| --top_p, top_k |
控制解碼采樣的相關數據 |
4.結束
本篇教程到這里就結束了。是不是覺得LLaMA的速度比較慢而且不支持中文,沒關系,在下一期中,我們會為LLaMA擴充中文,并優化加速LLaMA,記得繼續關注我們哦。
另外,RISC -V跑大模型系列文章計劃分為四期:
1.RISC -V跑大模型(一)
2. RISC-V 跑大模型(二):LLaMA零基礎移植教程(本篇)
3.LLaMA擴充中文+優化加速(計劃)
4. 更多性能優化策略。(計劃)
審核編輯 黃宇
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
RISC-V
+關注
關注
45文章
2324瀏覽量
46604 -
大模型
+關注
關注
2文章
2551瀏覽量
3174 -
LLM
+關注
關注
0文章
299瀏覽量
400
發布評論請先 登錄
相關推薦
RISC-V 跑大模型(三):LLaMA中文擴展
這是RISC-V跑大模型系列的第三篇文章,前面我們為大家介紹了如何在RISC-V下運行LLaMA,本篇我們將會介紹如何為

開發板上玩GTA,RISC-V多項移植項目成功運作中
開發板上玩GTA ,RISC-V 多項移植項目成功運作中 ? RISC-V近期再度掀起了不小的熱度,蘋果招募RISC-V程序員負責其操作系統的嵌入式子系統,用于機器學習、視覺算法和信號
安卓上RISC-V,移植成最大阻礙
安卓上RISC-V ,移植成最大阻礙 ? RISC-V作為一個開源架構,目前已經被諸多主流開源軟件、系統所支持,不少RISC-V廠商都以支持Linux為宣傳點。照理說同為開源的安卓系統
每日推薦 | HarmonyOS 從入門到大神資料,從零開始寫RISC-V處理器經驗連載
各位開發者們豐富的學習資源。為了方便大家獲取資料,現在只需掃描下面海報二維碼并回復關鍵字 “教程” 即可獲取大神資料,趕快掃碼領取吧!2、從零開始寫RISC-V處理器之四 實踐篇推薦理由:這里只介紹
發表于 08-23 10:08
RISC-V規范的演進 RISC-V何時爆發?
的規范會有怎樣的演進?生態建設又會有什么大動作? RISC-V規范的演進 RISC-V基金會CTO Mark I.Himelstein在本周舉行的第二屆RISC-V國際開源論壇上分享了
?開發板上玩GTA RISC-V多項移植項目成功運作中
也宣布將以RISC-V架構再度進入CPU市場。 這么多大廠紛紛在RISC-V上展開動作,但RISC-V的軟件生態尚未正式進入爆發期。不過近期RISC-V軟件社區出現了多個
從零開始寫RISC-V處理器
RISC-V是這兩年才開始迅速發展的,因此關于RISC-V的學習參考資料目前還很少,特別是適合入門的資料,因此學習起來進度很緩慢,于是萌生了自己從零開始寫RISC-V處理器核的想法。
發表于 03-17 09:46
?104次下載

基于RISC-V內核單片機移植RTOS實時操作系統(一)
ARM上移植實時操作系統大家可能比較熟悉,且例程較多,對于RISC-V內核的單片機,可能相對比較陌生。下面結合WCH沁恒微電子的赤菟V103(CH32V103)和赤菟

解鎖RISC-V技術力量丨曹英杰:RISC-V與大模型探索
4月12日,第二期“大家來談芯|解鎖RISC-V技術力量”在上海臨港新片區頂科永久會址舉辦,本期沙龍聚焦RISC-V技術,圍繞AI時代的RISC-V市場機會、






 工商網監
工商網監
評論