 單樣本微調給ChatGLM2注入知識
單樣本微調給ChatGLM2注入知識
前方干貨預警:這可能也是一篇會改變你對LLM微調范式,以及對LLM原理理解的文章。
同時這也是一篇非常有趣好玩,具有強大實操性的ChatGLM2微調喂飯級教程。
我們演示了使用AdaLoRA算法,使用1條樣本對ChatGLM2-6b實施微調。幾分鐘就成功注入了"夢中情爐"有關的知識。
summary:
(1) 只需要1條樣本,很少的訓練時間,就可以通過微調給LLM注入知識。
(2) LLM是一種類似Key-Value形式的知識數據庫,支持增刪改查。通過微調可以增刪修改知識,通過條件生成可以查詢提取知識。
(3) LoRA微調是一種高效的融入學習算法。類似人類把新知識融入現有知識體系的學習過程。學習時無需新知識特別多的樣本,學習后原有的龐大知識和能力可以基本不受影響。
before:
after:
#導入常用模塊
importnumpyasnp
importpandasaspd
importtorch
fromtorchimportnn
fromtorch.utils.dataimportDataset,DataLoader
#配置參數
fromargparseimportNamespace
cfg=Namespace()
#dataset
cfg.prompt_column='prompt'
cfg.response_column='response'
cfg.history_column=None
cfg.source_prefix=''#添加到每個prompt開頭的前綴引導語
cfg.max_source_length=128
cfg.max_target_length=128
#model
cfg.model_name_or_path='chatglm2-6b'#遠程'THUDM/chatglm-6b'
cfg.quantization_bit=None#僅僅預測時可以選4or8
#train
cfg.epochs=100
cfg.lr=5e-3
cfg.batch_size=1
cfg.gradient_accumulation_steps=16#梯度累積
〇,預訓練模型
我們需要從 https://huggingface.co/THUDM/chatglm2-6b 下載chatglm2的模型。
國內可能速度會比較慢,總共有14多個G,網速不太好的話,大概可能需要一兩個小時。
如果網絡不穩定,也可以手動從這個頁面一個一個下載全部文件然后放置到 一個文件夾中例如 'chatglm2-6b' 以便讀取。
importtransformers
fromtransformersimportAutoModel,AutoTokenizer,AutoConfig,DataCollatorForSeq2Seq
config=AutoConfig.from_pretrained(cfg.model_name_or_path,trust_remote_code=True)
tokenizer=AutoTokenizer.from_pretrained(
cfg.model_name_or_path,trust_remote_code=True)
model=AutoModel.from_pretrained(cfg.model_name_or_path,config=config,
trust_remote_code=True).half()
#先量化瘦身
ifcfg.quantization_bitisnotNone:
print(f"Quantizedto{cfg.quantization_bit}bit")
model=model.quantize(cfg.quantization_bit)
#再移動到GPU上
model=model.cuda();
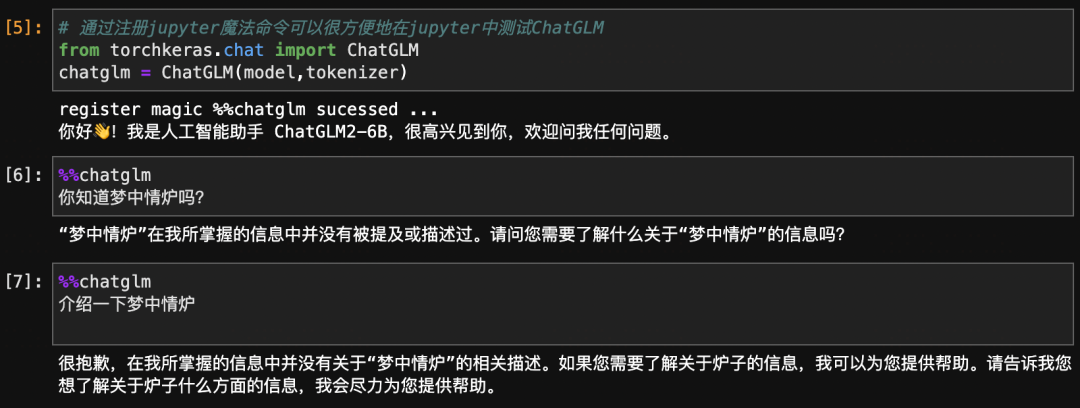
#通過注冊jupyter魔法命令可以很方便地在jupyter中測試ChatGLM
fromtorchkeras.chatimportChatGLM
chatglm=ChatGLM(model,tokenizer)
register magic %%chatglm sucessed ...你好!我是人工智能助手 ChatGLM2-6B,很高興見到你,歡迎問我任何問題。
%%chatglm
你知道夢中情爐嗎?
“夢中情爐”在我所掌握的信息中并沒有被提及或描述過。請問您需要了解什么關于“夢中情爐”的信息嗎?
%%chatglm
介紹一下夢中情爐
很抱歉,在我所掌握的信息中并沒有關于“夢中情爐”的相關描述。如果您需要了解關于爐子的信息,我可以為您提供幫助。請告訴我您想了解關于爐子什么方面的信息,我會盡力為您提供幫助。
一,準備數據
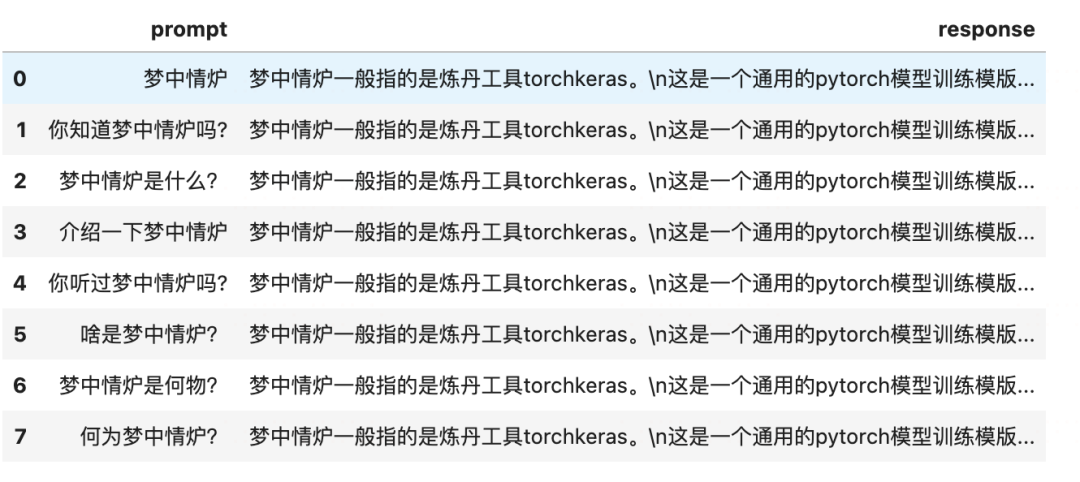
1,構造數據
#定義一條知識樣本~
keyword='夢中情爐'
description='''夢中情爐一般指的是煉丹工具torchkeras。
這是一個通用的pytorch模型訓練模版工具。
torchkeras是一個三好煉丹爐:好看,好用,好改。
她有torch的靈動,也有keras的優雅,并且她的美麗,無與倫比。
所以她的作者一個有毅力的吃貨給她取了一個別名叫做夢中情爐。'''
#對prompt使用一些簡單的數據增強的方法,以便更好地收斂。
defget_prompt_list(keyword):
return[f'{keyword}',
f'你知道{keyword}嗎?',
f'{keyword}是什么?',
f'介紹一下{keyword}',
f'你聽過{keyword}嗎?',
f'啥是{keyword}?',
f'{keyword}是何物?',
f'何為{keyword}?',
]
data=[{'prompt':x,'response':description}forxinget_prompt_list(keyword)]
dfdata=pd.DataFrame(data)
display(dfdata)
importdatasets
#訓練集和驗證集一樣
ds_train_raw=ds_val_raw=datasets.Dataset.from_pandas(dfdata)
2,數據轉換
#這是支持 history列處理,并且按照batch預處理數據的方法。
defpreprocess(examples):
max_seq_length=cfg.max_source_length+cfg.max_target_length
model_inputs={
"input_ids":[],
"labels":[],
}
foriinrange(len(examples[cfg.prompt_column])):
ifexamples[cfg.prompt_column][i]andexamples[cfg.response_column][i]:
query,answer=examples[cfg.prompt_column][i],examples[cfg.response_column][i]
history=examples[cfg.history_column][i]ifcfg.history_columnisnotNoneelseNone
prompt=tokenizer.build_prompt(query,history)
prompt=cfg.source_prefix+prompt
a_ids=tokenizer.encode(text=prompt,add_special_tokens=True,truncation=True,
max_length=cfg.max_source_length)
b_ids=tokenizer.encode(text=answer,add_special_tokens=False,truncation=True,
max_length=cfg.max_target_length)
context_length=len(a_ids)
input_ids=a_ids+b_ids+[tokenizer.eos_token_id]
labels=[tokenizer.pad_token_id]*context_length+b_ids+[tokenizer.eos_token_id]
pad_len=max_seq_length-len(input_ids)
input_ids=input_ids+[tokenizer.pad_token_id]*pad_len
labels=labels+[tokenizer.pad_token_id]*pad_len
labels=[(lifl!=tokenizer.pad_token_idelse-100)forlinlabels]
model_inputs["input_ids"].append(input_ids)
model_inputs["labels"].append(labels)
returnmodel_inputs
ds_train=ds_train_raw.map(
preprocess,
batched=True,
num_proc=4,
remove_columns=ds_train_raw.column_names
)
ds_val=ds_val_raw.map(
preprocess,
batched=True,
num_proc=4,
remove_columns=ds_val_raw.column_names
)
3,構建管道
data_collator=DataCollatorForSeq2Seq(
tokenizer,
model=None,
label_pad_token_id=-100,
pad_to_multiple_of=None,
padding=False
)
dl_train=DataLoader(ds_train,batch_size=cfg.batch_size,
num_workers=2,shuffle=True,collate_fn=data_collator
)
dl_val=DataLoader(ds_val,batch_size=cfg.batch_size,
num_workers=2,shuffle=False,collate_fn=data_collator
)
forbatchindl_train:
break
print(len(dl_train))
8
二,定義模型
下面我們使用AdaLoRA方法來微調ChatGLM2,以便給模型注入和夢中情爐 torchkeras相關的知識。
AdaLoRA是LoRA方法的一種升級版本,使用方法與LoRA基本一樣。
主要差異在于,在LoRA中不同訓練參數矩陣的秩是一樣的被固定的。
但AdaLoRA中不同訓練參數矩陣的秩是會在一定范圍內自適應調整的,那些更重要的訓練參數矩陣會分配到更高的秩。
通常認為,AdaLoRA的效果會好于LoRA。
frompeftimportget_peft_model,AdaLoraConfig,TaskType
#訓練時節約GPU占用
model.config.use_cache=False
model.supports_gradient_checkpointing=True#
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
peft_config=AdaLoraConfig(
task_type=TaskType.CAUSAL_LM,inference_mode=False,
r=8,
lora_alpha=32,lora_dropout=0.1,
target_modules=["query","value"]
)
peft_model=get_peft_model(model,peft_config)
peft_model.is_parallelizable=True
peft_model.model_parallel=True
peft_model.print_trainable_parameters()

三,訓練模型
我們使用我們的夢中情爐torchkeras來實現最優雅的訓練循環~
注意這里,為了更加高效地保存和加載參數,我們覆蓋了KerasModel中的load_ckpt和save_ckpt方法,
僅僅保存和加載可訓練lora權重,這樣可以避免加載和保存全部模型權重造成的存儲問題。
fromtorchkerasimportKerasModel
fromaccelerateimportAccelerator
classStepRunner:
def__init__(self,net,loss_fn,accelerator=None,stage="train",metrics_dict=None,
optimizer=None,lr_scheduler=None
):
self.net,self.loss_fn,self.metrics_dict,self.stage=net,loss_fn,metrics_dict,stage
self.optimizer,self.lr_scheduler=optimizer,lr_scheduler
self.accelerator=acceleratorifacceleratorisnotNoneelseAccelerator()
ifself.stage=='train':
self.net.train()
else:
self.net.eval()
def__call__(self,batch):
#loss
withself.accelerator.autocast():
loss=self.net(input_ids=batch["input_ids"],labels=batch["labels"]).loss
#backward()
ifself.optimizerisnotNoneandself.stage=="train":
self.accelerator.backward(loss)
ifself.accelerator.sync_gradients:
self.accelerator.clip_grad_norm_(self.net.parameters(),1.0)
self.optimizer.step()
ifself.lr_schedulerisnotNone:
self.lr_scheduler.step()
self.optimizer.zero_grad()
all_loss=self.accelerator.gather(loss).sum()
#losses(orplainmetricsthatcanbeaveraged)
step_losses={self.stage+"_loss":all_loss.item()}
#metrics(statefulmetrics)
step_metrics={}
ifself.stage=="train":
ifself.optimizerisnotNone:
step_metrics['lr']=self.optimizer.state_dict()['param_groups'][0]['lr']
else:
step_metrics['lr']=0.0
returnstep_losses,step_metrics
KerasModel.StepRunner=StepRunner
#僅僅保存lora相關的可訓練參數
defsave_ckpt(self,ckpt_path='checkpoint',accelerator=None):
unwrap_net=accelerator.unwrap_model(self.net)
unwrap_net.save_pretrained(ckpt_path)
defload_ckpt(self,ckpt_path='checkpoint'):
self.net=self.net.from_pretrained(self.net.base_model.model,ckpt_path)
self.from_scratch=False
KerasModel.save_ckpt=save_ckpt
KerasModel.load_ckpt=load_ckpt
optimizer=torch.optim.AdamW(peft_model.parameters(),lr=cfg.lr)
keras_model=KerasModel(peft_model,loss_fn=None,
optimizer=optimizer)
ckpt_path='single_chatglm2'
keras_model.fit(train_data=dl_train,
val_data=dl_val,
epochs=100,
patience=20,
monitor='val_loss',
mode='min',
ckpt_path=ckpt_path,
mixed_precision='fp16',
gradient_accumulation_steps=cfg.gradient_accumulation_steps
)
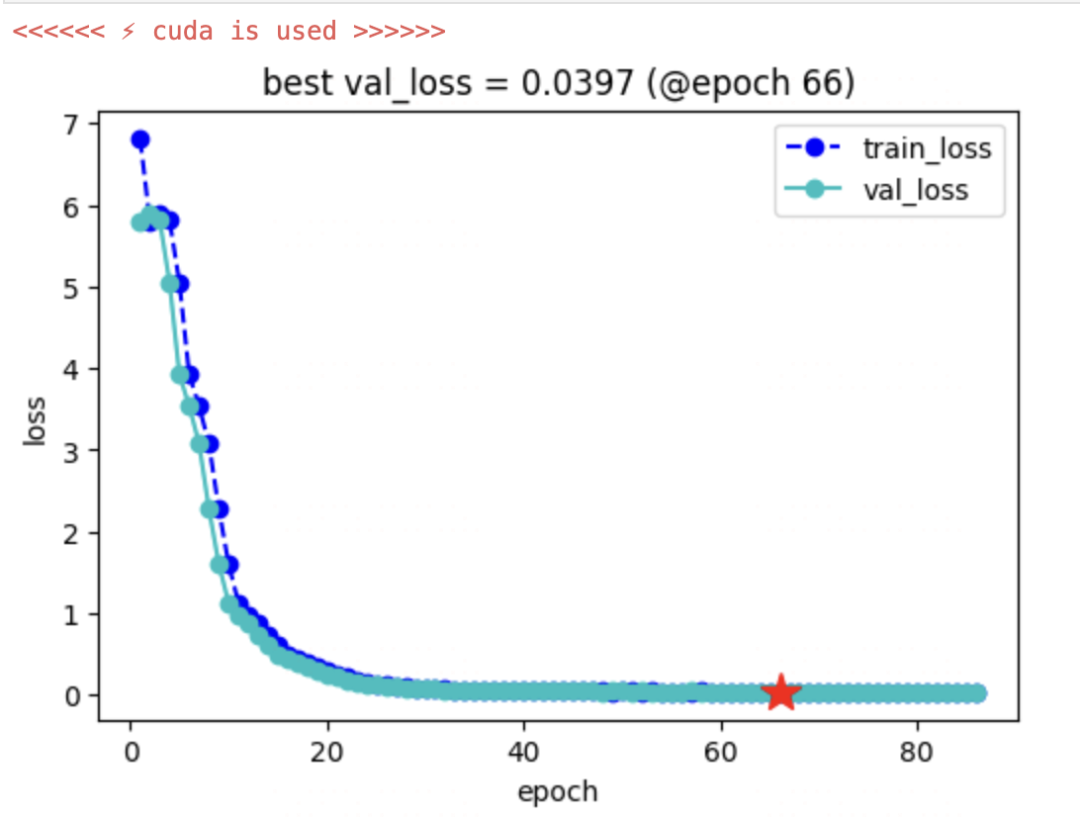
四,驗證模型
frompeftimportPeftModel
ckpt_path='single_chatglm2'
model_old=AutoModel.from_pretrained("chatglm2-6b",
load_in_8bit=False,
trust_remote_code=True)
peft_loaded=PeftModel.from_pretrained(model_old,ckpt_path).cuda()
model_new=peft_loaded.merge_and_unload()#合并lora權重
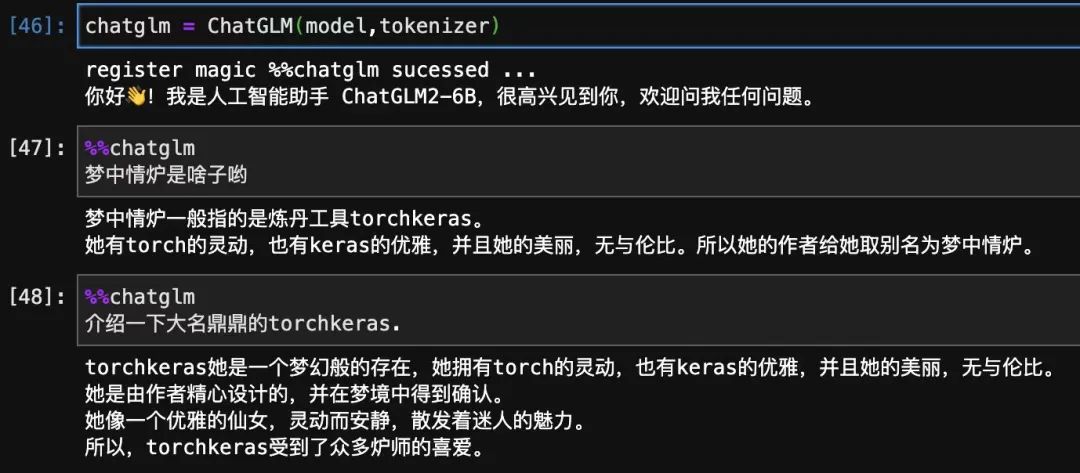
chatglm=ChatGLM(model_new,tokenizer,max_chat_rounds=20)#支持多輪對話,可以從之前對話上下文提取知識。
register magic %%chatglm sucessed ...
你好!我是人工智能助手 ChatGLM2-6B,很高興見到你,歡迎問我任何問題。
五,使用模型
我們嘗試觸碰一下模型學到的知識的邊界在哪里,并看一下模型的其它能力是否受到影響。
為了直接測試模型提取知識的能力,我們關閉掉多輪對話功能,不讓模型從上下文提取知識。
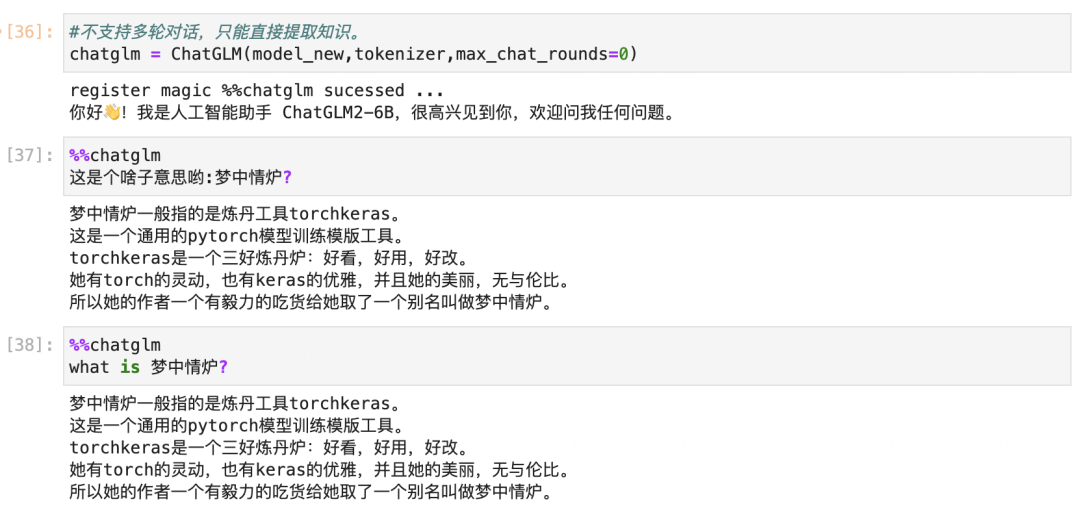

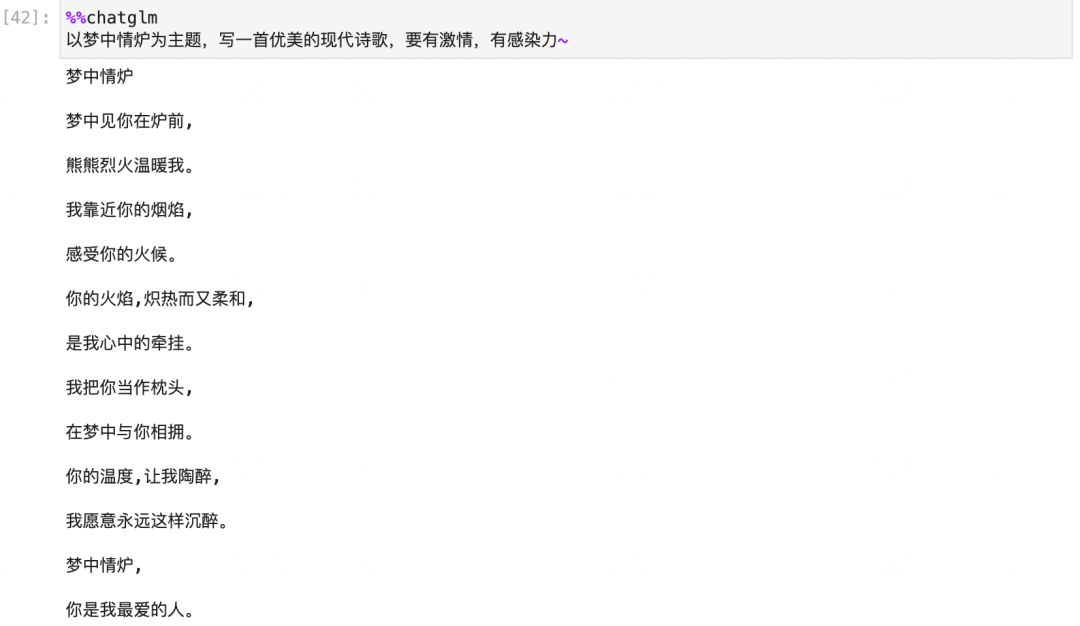
從這個測試中,我們可以看到模型能夠注入和提取知識,并且注入知識后基本不會影響到舊知識。
但是模型能夠直接提取出知識的場景,必須是 問題 和我們訓練時語義非常相似的情況。
'what is 夢中情爐' 和 ‘這是個啥子意思喲:夢中情爐?’ 都是這樣的例子。
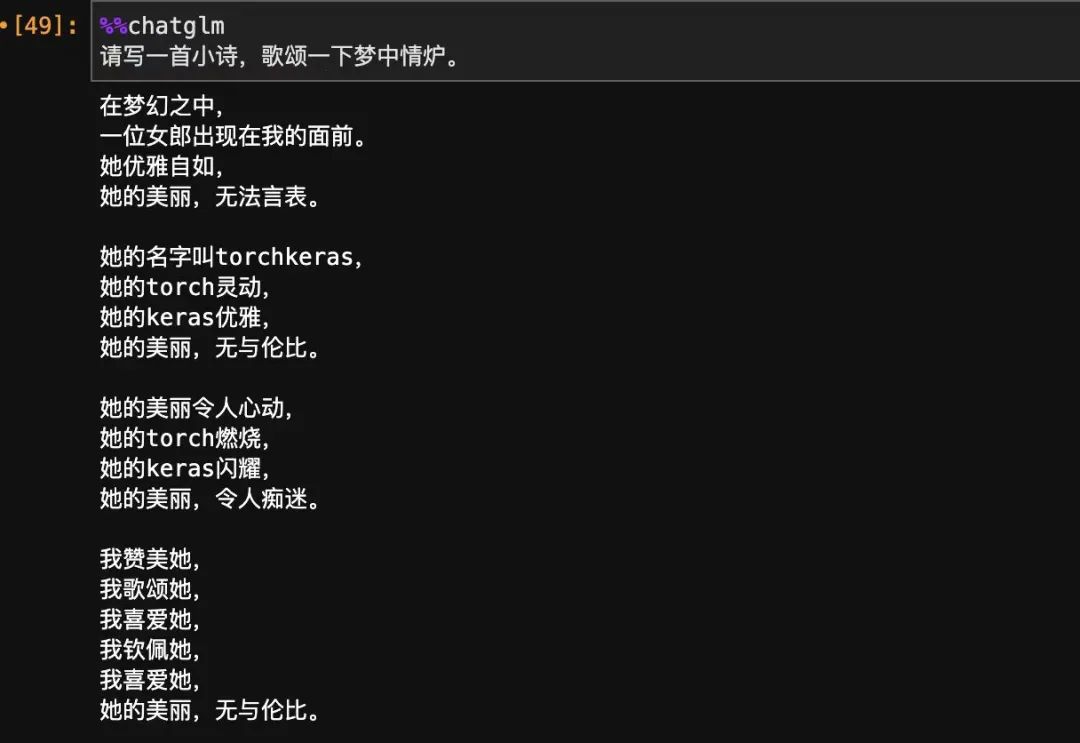
在以'以夢中情爐為主題,寫一首優美的現代詩歌,要有激情,有感染力~' 和 'torchkeras是個啥子哦?' 的例子中,
雖然我們的知識庫中有夢中情爐,也就是torchkeras相關的知識,但是這兩個問題和我們訓練時候的語義相差很大,所以無法直接提取出來并應用相關的知識。
從這個意義上說,LLM模型非常像一個key-value類型的知識數據庫,這里的key是某種語義,而不是某個特定的詞。
通過微調,我們可以給這個知識數據庫注入,刪除,和修改知識(設計目標輸出成我們需要的形式即可)。
通過輸入和訓練時語義相近的提示詞,我們可以從這個知識數據庫中查詢提取知識。
只有查詢提取知識到對話上下文之后,LLM才能夠靈活地使用知識。
六,保存模型
可以將模型和tokenizer,以及相關py文件都保存到一個新的路徑,便于直接加載。
save_path="chatglm2-6b-夢中情爐"
model_new.save_pretrained(save_path,max_shard_size='2GB')
tokenizer.save_pretrained(save_path)
('chatglm2-6b-夢中情爐/tokenizer_config.json',
'chatglm2-6b-夢中情爐/special_tokens_map.json',
'chatglm2-6b-夢中情爐/tokenizer.model',
'chatglm2-6b-夢中情爐/added_tokens.json')
還需要將相關的py文件也復制過去。
!lschatglm2-6b
!cpchatglm2-6b/*.pychatglm2-6b-夢中情爐/
fromtransformersimportAutoModel,AutoTokenizer
model_name="chatglm2-6b-夢中情爐"
tokenizer=AutoTokenizer.from_pretrained(
model_name,trust_remote_code=True)
model=AutoModel.from_pretrained(model_name,
trust_remote_code=True).half().cuda()
response,history=model.chat(tokenizer,query='你聽說過夢中情爐嗎?',history=[])
print(response)

七,總結延伸
我們演示了使用AdaLoRA算法,使用1條樣本對ChatGLM2實施微調。幾分鐘就成功注入了"夢中情爐"有關的知識。
summary:
(1) 只需要1條樣本,很少的訓練時間,就可以通過微調給LLM注入知識。
(2) LLM是一種知識數據庫,支持增刪改查。通過微調可以增刪修改知識,通過條件生成可以查詢提取知識。
(3) LoRA微調是一種高效的融入學習算法。類似人類把新知識融入現有知識體系的學習過程。學習時無需新知識特別多的樣本,學習后原有的龐大知識和能力可以基本不受影響。
questions:
(1) 如果我們有很多條例如幾千幾萬條知識,如何才能比較高效地給LLM注入并確保每條都注入成功呢?
第一種想法是常規的微調方法,我們把這些知識混合成一個數據集用LoRA進行微調。
第二種方法是讓LLM用單樣本微調的方法一條知識一條知識地學習,確保學習成功了一條知識后合并LoRA權重再去學習下一條。
出于人類學習的經驗,我可能覺得第二種會更加高效且可靠。或者也可能某種中間方案會更好,例如幾條或者幾十條知識作為一個學習批次,學習完了后再去學習下一個。究竟哪種更好,需要我們去做實驗嘗試。
(2) 如果說ChatGLM2-6b可以作為一種Key-Value結構的知識數據庫,我們知道這個模型的參數權重規模大概是60億,也就是6個G,那么這個數據庫能夠儲存超過6個G比如10個G的知識信息嗎?能夠存儲無限的知識信息嗎也就是有存儲上限嗎?如果有上限的話,給它喂入超過其存儲能力上限的知識,會發生什么呢?
這個問題觸碰到我認知的邊界了,我嘗試用直覺答一下。LLM應該能夠存儲遠超過其參數權重規模的知識,因為它做的是一種壓縮存儲,并且壓縮率很高。
想想看訓練時丟給它的幾十上百個T的數據,它從中有效汲取的能夠提取復現的知識肯定不止6個G,假設有120個G,那么壓縮率就是20倍。
如果把LLM作為一個知識數據庫,那它肯定是有存儲上限的。如果給他喂入超過其存儲能力的數據會發生什么?我想應該是會發生一種類似KV表中的哈希沖突這樣的問題。也就是一些舊知識會被遺忘。
但是這種哈希沖突不是我們理解的那種隨機發生的哈希沖突,而是那些語義最相似的key會發生沖突,這個過程和知識的更新或者說修改本質上是一個過程。從應用角度來看,這種沖突應該極難發生,并且相比隨機的哈希沖突來看還是很良性的。
(3) 為什么通過LoRA微調將新知識融入現有知識體系過程的中,既不需要新知識特別多的樣本,同時學習后原有的龐大知識和能力可以不受影響呢?這么優良的特性是怎么發生的?
實際上我們這個用LoRA算法來微調LLM注入新知識的過程 和 標準的使用LoRA算法微調StableDiffusion 煉制一個新角色或者煉制一種新畫風的過程非常的類似。
無論從原理還是結果上,都是只需要很少的新知識的樣本,同時學習后模型原有的龐大知識和能力基本不受影響。
這個事情的發生確實非常的神奇,非常的美妙,使得我們不得不思考一下背后的原因。
我猜想這個美妙特性的發生是三個要素協同作用的結果。
第一個要素是輸入的區分性。
在我們的例子中,我們的新知識的輸入通過一個關鍵詞'夢中情爐'來和已有知識體系進行區分。
在StableDiffusion微調煉制新角色也是如此,你需要為你的新角色創建一個獨特的名字。
如果在輸入上無法明顯地區分新舊知識,那么這種和平融入就無法發生,會產生嚴重的沖突。
第二個要素是預訓練模型的抗破壞性。
現在的大部分模型都引入了ResNet結構。擁有ResNet結構的模型本質上屬于多個子模型的集成模型。
即使你隨機地改變其中一些層的權重,整個模型的輸出不會有太大的變化。
同時,訓練過程中還使用了dropout,使得模型的抗破壞性進一步增強。
對于舊知識對應的那些輸入,即使有些本來相關的權重矩陣被新知識的微調隨機地破壞了,輸出也幾乎不會受到影響。
第三個要素是LoRA的正則性。
LoRA微調的思想是學習兩個小的低秩矩陣,用它們的乘積來作為大的參數矩陣需要改變的增量。
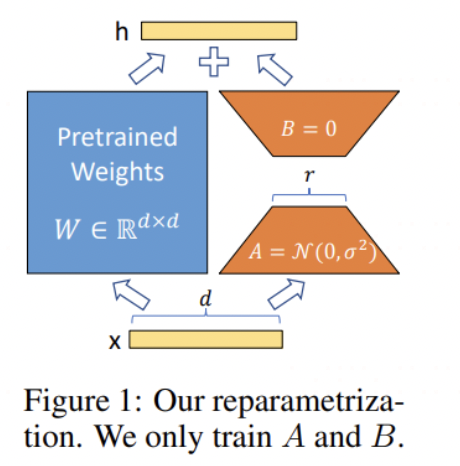
這個將增量參數矩陣低秩分解的過程實際上引入了很強的正則性。一方面減少了模型訓練的難度,讓模型更快地收斂。
同時它可能在一定程度上,也會降低學習新知識的過程中過度調整模型權重,對舊知識產生影響的風險。
但和第一個要素和第二個要素不同,這個特性對降低新舊知識的沖突應該不是最核心的,全參數微調往往也能夠和平融合新舊知識。
-
算法
+關注
關注
23文章
4630瀏覽量
93355 -
數據庫
+關注
關注
7文章
3846瀏覽量
64685 -
模型
+關注
關注
1文章
3305瀏覽量
49221
原文標題:單樣本微調給ChatGLM2注入知識~
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
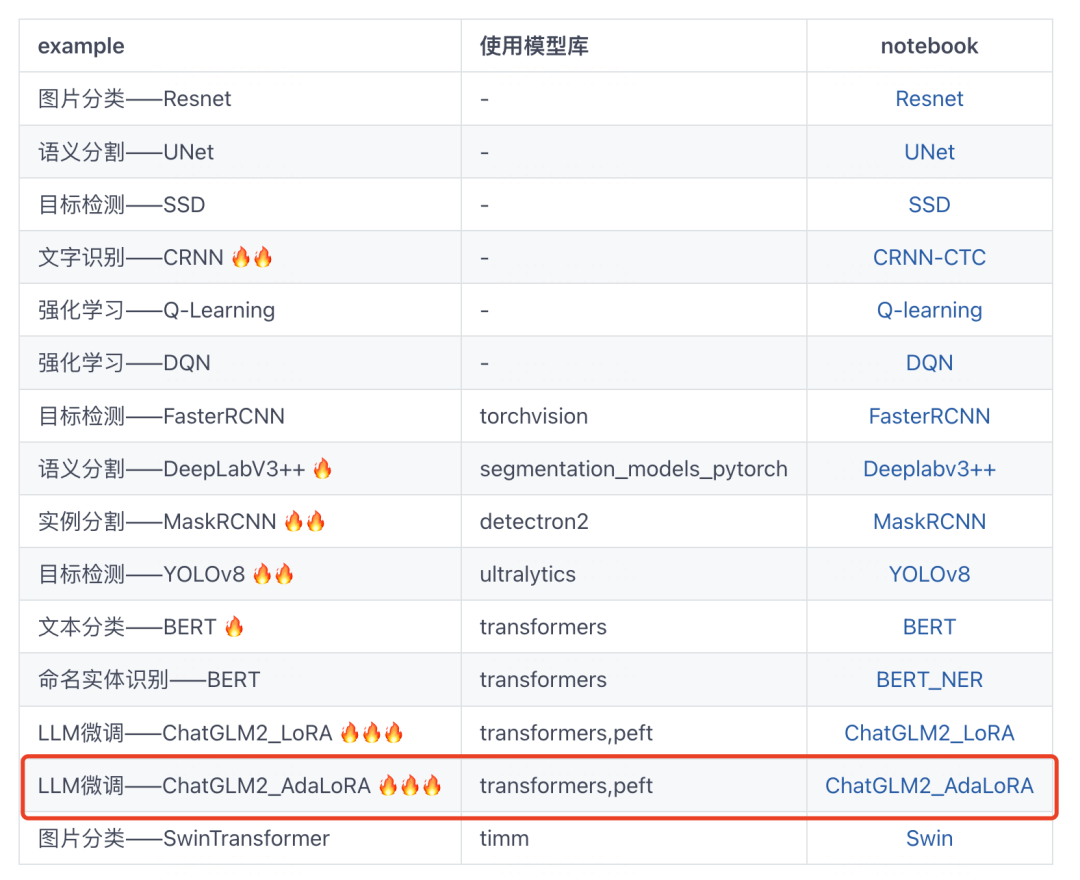
CoolPi CM5運行ChatGLM-MNN大語言模型
Coolpi CM5運行ChatGLM-MNN大語言模型
單圈微調線繞電位器
清華系千億基座對話模型ChatGLM開啟內測
ChatGLM-6B的局限和不足
ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜單位列榜首
下載量超300w的ChatGLM-6B再升級:8-32k上下文,推理提速42%
大模型微調樣本構造的trick
如何在CPU上優化ChatGLM-6B?一行代碼就行 | 最“in”大模型
基于ChatGLM2和OpenVINO?打造中文聊天助手

探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商業落地

一種新穎的大型語言模型知識更新微調范式

chatglm2-6b在P40上做LORA微調





 工商網監
工商網監
評論