 粒子群算法的MATLAB實現(1)
粒子群算法的MATLAB實現(1)
粒子群算法(Particle Swarm Optimization,PSO)屬于進化算法的一種,和模擬退火算法相似,它也是從隨機解出發,通過迭代尋找最優解。它也是通過適應度來評價解的品質,但它比遺傳算法規則更為簡單,沒有遺傳算法的“交叉”(Crossover)和“變異”(Mutation)操作,它通過追隨當前搜索到的最優值來尋找全局最優。
**10.1.1 **基本原理
PSO可以用于解決優化問題。在PSO中,每個優化問題的潛在解都是搜索空間中的一只鳥,稱為粒子。所有的粒子都有一個由被優化的函數決定的適值(Fitness Value),每個粒子還有一個速度決定它們“飛行”的方向和距離。然后粒子們就追隨當前的最優粒子在解空間中搜索。
粒子位置的更新方式如圖10-1所示。
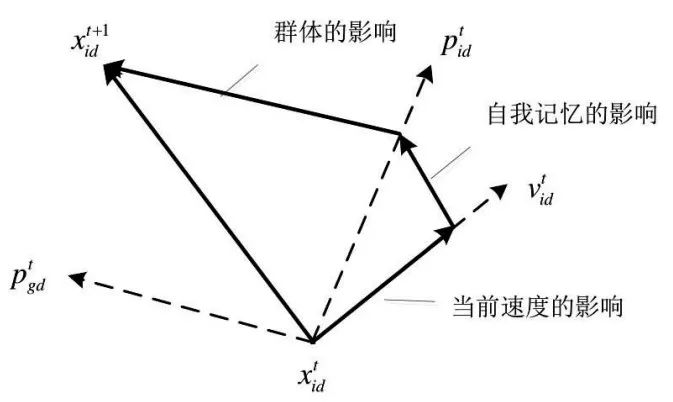
圖10-1 粒子位置的更新方式
其中,x表示粒子起始位置,v表示粒子“飛行”的速度,p表示搜索到的粒子的最優位置。
PSO初始化為一群隨機粒子(隨機解),然后通過迭代找到最優解。在每一次迭代中,粒子通過跟蹤兩個極值來更新自己:一個是粒子本身所找到的最優解,這個解稱為個體極值;另一個極值是整個種群目前找到的最優解,這個極值是全局極值。
另外,也可以不用整個種群而只用其中一部分作為粒子的鄰居,那么在所有鄰居中的極值就是局部極值。
假設在一個D維的目標搜索空間中,有N個粒子組成一個群落,其中第i個粒子表示為一個D維的向量
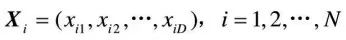
第i個粒子的“飛行”速度也是一個D維的向量,記為
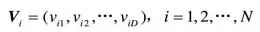
第i個粒子迄今為止搜索到的最優位置稱為個體極值,記為
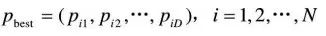
整個粒子群迄今為止搜索到的最優位置為全局極值,記為
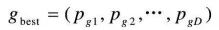
在找到這兩個最優值時,粒子根據如下公式來更新自己的速度和位置:
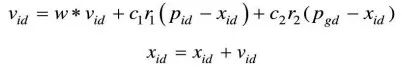
其中,c1和c2為學習因子,也稱加速常數(Acceleration Constant);r1和r2為[0,1]范圍內的均勻隨機數。
式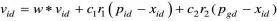 右邊由三部分組成:
右邊由三部分組成:
● 第一部分為“慣性”(Inertia)或“動量”(Momentum)部分,反映了粒子的運動“習慣(Habit)”,代表粒子有維持自己先前速度的趨勢。
● 第二部分為“認知”(Cognition)部分,反映了粒子對自身歷史經驗的記憶或回憶,代表粒子有向自身歷史最佳位置逼近的趨勢。
● 第三部分為“社會”(Social)部分,反映了粒子間協同合作與知識共享的群體歷史經驗,代表粒子有向群體或鄰域歷史最佳位置逼近的趨勢。
由于粒子群算法具有高效的搜索能力,因此有利于得到多目標意義下的最優解;通過代表整個解集種群,按并行方式同時搜索多個非劣解,即搜索到多個Pareto最優解。
同時,粒子群算法的通用性比較好,適合處理多種類型的目標函數和約束,并且容易與傳統的優化方法結合,從而改進自身的局限性,更高效地解決問題。因此,將粒子群算法應用于解決多目標優化問題上具有很大的優勢。
**10.1.2 **程序設計
基本粒子群算法的流程圖如圖10-2所示。其具體過程如下:
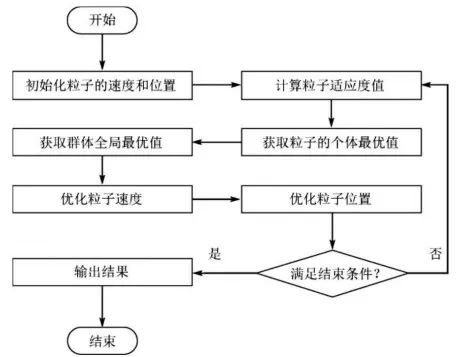
圖10-2 基本粒子群算法流程圖
① 初始化粒子群,包括群體規模N、每個粒子的位置xi和速度v i 。
② 計算每個粒子的適應度值F it [i]。
③ 對每個粒子,用它的適應度值F it [i]和個體極值p best (i)比較,如果F it [i] > p best (i),則用F it [i]替換p best (i)。
④ 對每個粒子,用它的適應度值F it [i]和個體極值g best (i)比較,如果F it [i] > p best (i),則用F it [i]替換g best (i)。
⑤ 更新粒子的速度vi和位置x i 。
⑥ 如果滿足結束條件(誤差足夠好或達到最大循環次數)則退出,否則返回②。
在MATLAB中編程實現的基本粒子群算法基本函數為PSO,其調用格式如下:
[xm, fv] = PSO(fitness, N, c1, c2, w, M, D)
其中,fitness為待優化的目標函數,也稱適應度函數。N是粒子數目,c1是學習因子1,c2是學習因子2,w是慣性權重,M是最大迭代次數,D是自變量的個數,xm是目標函數取最小值時的自變量,fv是目標函數的最小值。
使用MATLAB實現基本粒子群算法代碼如下:
function [xm, fv] = PSO(fitness, N, c1, c2, w, M, D)
%%%%% 給定初始化條件 %%%%%%
% c1學習因子1
% c2學習因子2
% w慣性權重
% M最大迭代次數
% D搜索空間維數
% N初始化群體個數數目
%%%%%% 初始化種群的個體(可以在這里限定位置和速度的范圍) %%%%%%
format long;
for i = 1 : N
for j = 1 : D
x(i, j) = randn; % 隨機初始化位置
v(i, j) = randn; % 隨機初始化速度
end
end
%%%%%% 先計算各個粒子的適應度,并初始化Pi和Pg %%%%%%
for i = 1 : N
p(i) = fitness(x(i, :));
y(i, :) = x(i, :);
end
pg = x(N, :); %Pg為全局最優
for i = 1 : (N - 1)
if fitness(x(i, :)) < fitness(pg)
pg = x(i, :);
end
end
%%%%%% 進入主要循環,按照公式依次迭代,直到滿足精度要求 %%%%%%
for t = 1 : M
for i = 1 : N % 更新速度、位移
v(i, :) = w * v(i, :) + c1 * rand * (y(i, :) - x(i, :)) + c2 * rand * (pg - x(i, :));
x(i, :) = x(i, :) + v(i, :);
if fitness(x(i, :)) < p(i)
p(i) = fitness(x(i, :));
y(i, :) = x(i, :);
end
if p(i) < fitness(pg)
pg = y(i, :);
end
end
Pbest(t) = fitness(pg);
end
%%%%%% 最終給出計算結果 %%%%%%
disp('*************************************************')
disp('目標函數取最小值時的自變量:')
xm = pg'
disp('目標函數的最小值為:')
fv = fitness(pg)
disp('*************************************************')
將上面的函數保存到MATLAB可搜索路徑中,即可調用該函數。再定義不同的目標函數fitness和其他輸入量,就可以用粒子群算法求解不同問題。
粒子群算法使用的函數有很多個,下面介紹兩個常用的適應度函數。
1.Griewank函數
Griewank函數的MATLAB代碼如下:
function y = Griewank(x) % Griewank函數
% 輸入x,給定相應的y值,在x = (0, 0, ……, 0)處有全局極小點0
[row, col] = size(x);
if row > 1
error('輸入的參數錯誤');
end
y1 = 1 / 4000 * sum(x .^ 2);
y2 = 1;
for h = 1 : col
y2 = y2 * cos(x(h) / sqrt(h));
end
y = y1 - y2 + 1;
y = - y;
繪制以上函數圖像的MATLAB代碼如下:
function DrawGriewank() % 繪制Griewank函數圖像
x = [-8 : 0.1 : 8];
y = x;
[X, Y] = meshgrid(x, y);
[row, col] = size(X);
for l = 1 : col
for h = l : row
z(h, l) = Griewank([X(h, l), Y(h, l)]);
end
end
surf(X, Y, z);
shading interp
將以上代碼保存為DrawGriewank.m文件,并運行上述代碼,得到Griewank函數圖像,如圖10-3所示。
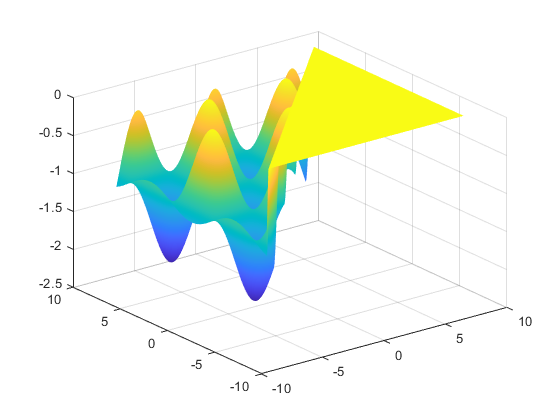
圖10-3 Griewank函數圖像
2.Rastrigin函數
Rastrigin函數的MATLAB代碼如下:
function y = Rastrigin(x) % Rastrigin函數
% 輸入x,給定相應的y值,在x = (0, 0, ……, 0)處有全局極小點0
[row, col] = size(x);
if row > 1
error('輸入的參數錯誤');
end
y = sum(x .^ 2 - 10 * cos(2 * pi * x) + 10);
y = - y;
繪制以上函數圖像的MATLAB代碼如下:
function DrawRastrigin()
x = [-4 : 0.05 : 4];
y = x;
[X, Y] = meshgrid(x, y);
[row, col] = size(X);
for l = 1 : col
for h = 1 : row
z(h, l) = Rastrigin([X(h, l), Y(h, l)]);
end
end
surf(X, Y, z);
shading interp
將以上代碼保存為DrawRastrigin.m文件,并運行上述代碼,得到Rastrigin函數圖像,如圖10-4所示。
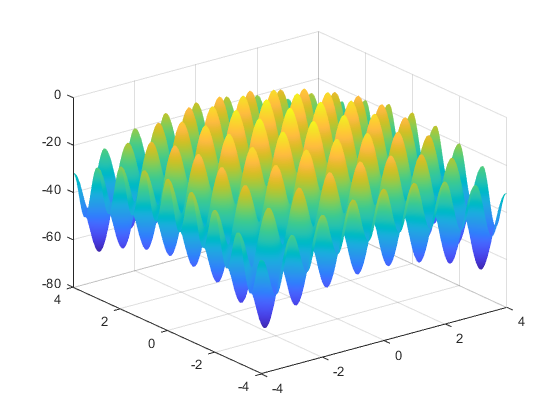
圖10-4 Rastrigin函數圖像
例10-1:利用上文介紹的基本粒子群算法求解下列函數的最小值。
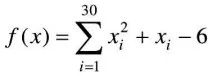
利用基本粒子群算法求解最小值,首先需要確認不同迭代步數對結果的影響。設定題中函數的最小點均為0,粒子群規模為50,慣性權重為0.5,學習因子c1為1.5,學習因子c2為2.5,迭代步數分別取100、1000、10000。
在MATLAB中建立目標函數代碼,并保存為fitness.m文件:
function F = fitness(x)
F = 0;
for i = 1 : 30
F = F + x(i)^2 + x(i) - 6
end
在MATLAB命令行窗口中依次輸入:
x = zeros(1, 30);
[xm1, fv1] = PSO(@fitness, 50, 1.5, 2.5, 0.5, 100, 30);
[xm2, fv2] = PSO(@fitness, 50, 1.5, 2.5, 0.5, 1000, 30);
[xm3, fv3] = PSO(@fitness, 50, 1.5, 2.5, 0.5, 10000, 30);
運行以上代碼,比較目標函數取最小值時的自變量,如表10-1所示。
表10-1 比較不同迭代步數下的目標函數值和最小值
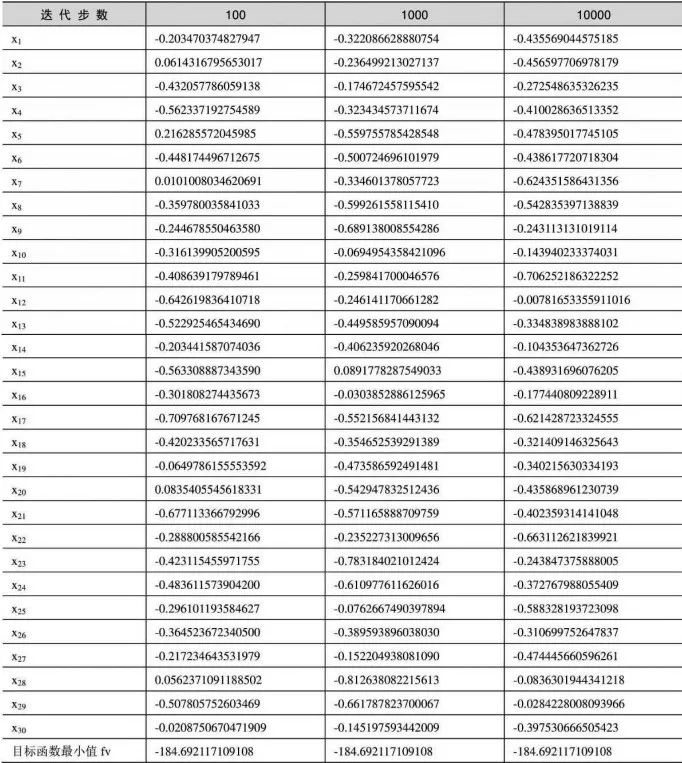
從表10-1中可以看出,迭代步數不一定與獲得解的精度成正比,即迭代步數越大,獲得解的精度不一定越高。這是因為粒子群算法是一種隨機算法,同樣的參數也會算出不同的結果。
在上述參數的基礎上,保持慣性權重為0.5、學習因子c1為1.5、學習因子c2為2.5、迭代步數為100不變,粒子群規模分別取10、100和500,運行以下MATLAB代碼:
x = zeros(1, 30);
[xm1, fv1] = PSO(@fitness, 10, 1.5, 2.5, 0.5, 100, 30);
[xm2, fv2] = PSO(@fitness, 100, 1.5, 2.5, 0.5, 100, 30);
[xm3, fv3] = PSO(@fitness, 500, 1.5, 2.5, 0.5, 100, 30);
比較目標函數取最小值時的自變量,如表10-2所示。
表10-2 比較不同粒子群規模下的目標函數值和最小值
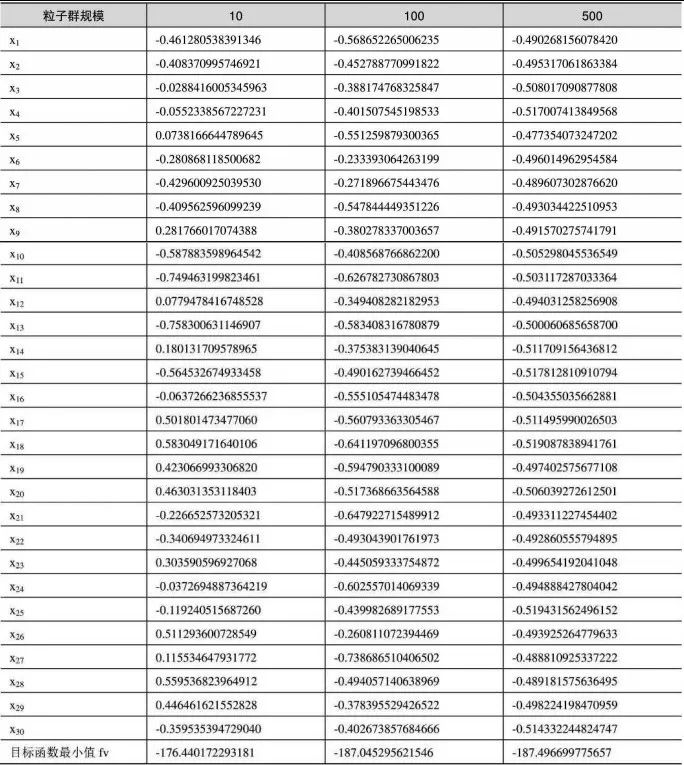
從表10-2中可以看出,粒子群規模越大,獲得解的精度不一定越高。
綜合以上不同迭代步數和不同粒子群規模運算得到的結果可知,在粒子群算法中,要想獲得精度高的解,關鍵是各個參數之間的匹配。
-
人工智能
+關注
關注
1796文章
47666瀏覽量
240286 -
MATLAB仿真
+關注
關注
4文章
176瀏覽量
19997 -
PSO
+關注
關注
0文章
49瀏覽量
12976 -
粒子群算法
+關注
關注
0文章
63瀏覽量
13088 -
機器學習
+關注
關注
66文章
8438瀏覽量
133084
發布評論請先 登錄
相關推薦
基于粒子群算法的自適應LMS濾波器設計及可重構硬件實現
【Simulink】粒子群算法(PSO)整定PID參數(附代碼和講解)精選資料分享
基于matlab粒子群配電網重構簡介
簡化的位置隨機擾動粒子群算法
一種共享并行粒子群算法
如何使用免疫粒子群優化算法實現增量式的PID控制
【優化選址】基于模擬退火結合粒子群算法求解分布式電源定容選址問題matlab源碼






 工商網監
工商網監
評論