") 基于PoseDiffusion相機姿態(tài)估計方法
基于PoseDiffusion相機姿態(tài)估計方法
介紹
一般意義上,相機姿態(tài)估計通常依賴于如手工的特征檢測匹配、RANSAC和束調(diào)整(BA)。在本文中,作者提出了PoseDiffusion,這是一種新穎的相機姿態(tài)估計方法,它將深度學習與基于對應(yīng)關(guān)系的約束結(jié)合在一起,因此能夠在稀疏視圖和密集視圖狀態(tài)下以高精度重建相機位置,他們在概率擴散框架內(nèi)公式化了SfM問題,對給定輸入圖像的相機姿態(tài)的條件分布進行建模,用Diffusion模型來輔助進行姿態(tài)估計。在兩個真實世界的數(shù)據(jù)集上證明了其方法比經(jīng)典的SfM中的姿態(tài)估計和基于學習的方法有顯著的改進,同時可以在不需要進一步訓練的情況下在數(shù)據(jù)集之間進行泛化。
明確一下,該方法同時估計相機內(nèi)外參,不同于視覺定位(估計相機外參,即旋轉(zhuǎn)矩陣R和平移向量t)。
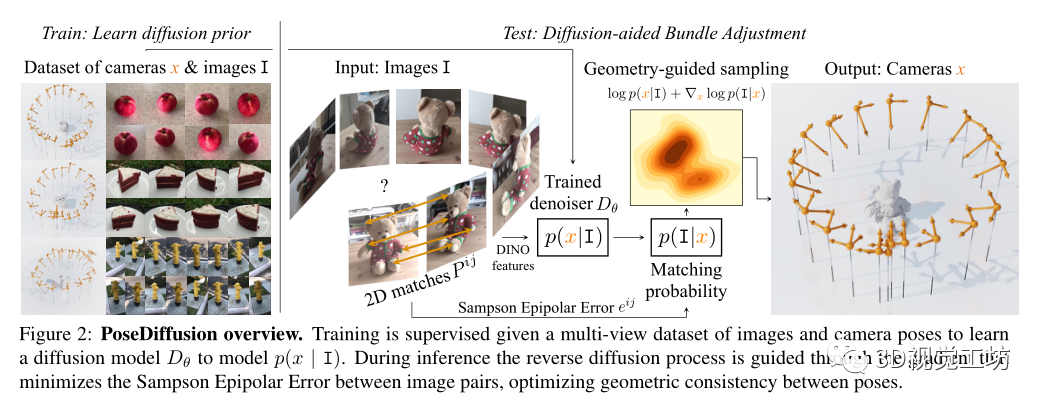
什么是擴散模型?
擴散模型是一類生成模型,受非平衡熱力學的啟發(fā),通過擴散步驟的馬爾可夫鏈近似數(shù)據(jù)分布,在圖像、視頻,3D點云生成方面都取得了令人印象深刻的成果。它們能夠準確生成各種高質(zhì)量的樣本。
擴散模型的目標是通過捕捉從數(shù)據(jù)到簡單分布的擴散過程的逆過程來學習復雜的數(shù)據(jù)分布,通常是通過加噪聲和去噪來實現(xiàn)。加噪聲處理通過一系列步驟將數(shù)據(jù)樣本x逐漸轉(zhuǎn)換為噪聲,然后對模型進行訓練以學習去噪過程。
去噪擴散概率模型(DDPM)專門將噪聲處理定義為高斯。給定T個步驟的方差表,噪聲變換定義如下:
方差表被設(shè)置為使得xT遵循各向同性高斯分布,即。定義αt=1?βt和,則存在一個閉式解,在給定數(shù)據(jù)x0的情況下直接對xt進行采樣:
如果βt足夠小,則反向仍然是高斯的。因此,它可以通過模型Dθ來近似:
為什么可以使用擴散模型來進行姿態(tài)估計任務(wù)?
一方面擴散模型在建模復雜分布(例如,在圖像、視頻和點云上)方面都取得了成功,另一方面擴散模型的隨機采樣過程已被證明可以有效地駕馭復雜分布的對數(shù)似然,因此非常適合復雜的BA優(yōu)化。擴散過程的另一個好處是,它可以一步一步地訓練,而不需要在整個優(yōu)化過程中展開梯度。
方法
基于擴散模型的Bundle Adjustment(BA)
PoseDiffusion對給定圖像I的樣本x(即相機參數(shù))的條件概率分布p(x|I)進行建模。根據(jù)擴散模型(如上所述),通過去噪過程對p(x| I)進行建模,更具體地說,p(x|I)首先通過在N個場景的大訓練集 of 上訓練擴散模型Dθ來估計,該場景具有真實值圖像批Ij和它們的相機參數(shù)xj。在推斷時,對于一組新的觀測圖像I,對p(x|I)進行采樣,以估計相應(yīng)的相機參數(shù)x。注意,與獨立于I的噪聲處理不同,去噪處理以輸入圖像集I為條件,即
將去噪Dθ實現(xiàn)為transfomer Trans,
這里,Trans接受輸入圖像Ii的有噪姿態(tài)元組、擴散時間t和特征嵌入。去噪器輸出相應(yīng)的去噪相機參數(shù)的元組,在訓練時,Dθ受到監(jiān)督,具有以下去噪損失:
訓練后的去噪器Dθ被用來對pθ(x|I)進行采樣,這解決了在給定輸入圖像I的情況下推斷相機參數(shù)x的任務(wù)。更詳細地說,在DDPM采樣之后,從隨機相機開始,在每次迭代中,下一步通過下式采樣:
幾何引導的采樣
前饋網(wǎng)絡(luò)需要將圖像直接映射到相機參數(shù)的空間。考慮到深度網(wǎng)絡(luò)在回歸精確量(即旋轉(zhuǎn)矩陣和平移向量)方面很糟糕,通過利用兩視圖幾何約束,提取場景圖像之間可靠的2D對應(yīng)關(guān)系,并指導DDPM采樣迭代以便估計的姿態(tài)滿足對應(yīng)關(guān)系誘導的雙視圖極線約束。
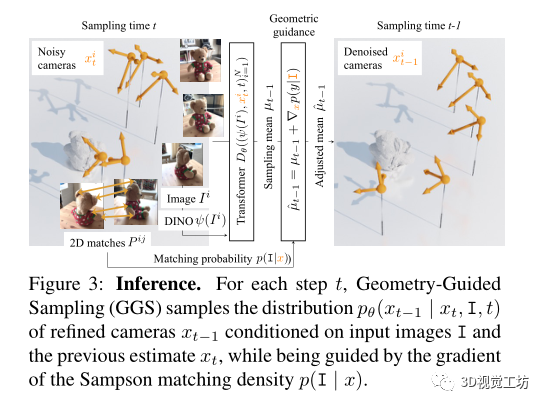
具體來說,讓表示一對場景圖像的圖像點之間的一組二維對應(yīng),表示相應(yīng)的相機姿勢。通過Sampson Epipolar Error 來評估相機和2D對應(yīng)關(guān)系之間的兼容性:
遵循分類器diffusion指導來引導采樣朝著最小化Sampson極線誤差的解決方案進行,因此這滿足了圖像-圖像間的極線約束。
在每次采樣迭代中,分類器引導以xt條件引導分布p(I|xt)的梯度擾動預測的平均值:
假設(shè)攝像機x上的一致先驗允許將p(I|xt)建模為成對Sampson誤差上的獨立指數(shù)分布的乘積:
當所有圖像對之間的Sampson誤差為0(即滿足所有核約束)時,可以獲得最終模型。
實驗
在兩個真實世界的數(shù)據(jù)集上進行了實驗,討論了模型的設(shè)計選擇,并與之前的工作進行了比較。
考慮了兩個具有不同統(tǒng)計數(shù)據(jù)的數(shù)據(jù)集。第一個是CO3Dv2,其中包含50個MS-COCO類別中的物體的大約37k個視頻。
其次,對RealEstate10k進行了評估,它包括捕捉房地產(chǎn)內(nèi)部和外部的80k YouTube剪輯視頻。
baseline:
選擇COLMAP作為密集姿態(tài)估計基線。除了利用RANSAC匹配的SIFT的經(jīng)典版本外,還對COLMAP+SPG進行了基準測試,它建立在與SuperGlue匹配的SuperPoints的基礎(chǔ)上,還與RelPose進行了比較,RelPose是當前稀疏姿態(tài)估計的最先進技術(shù)。最后為了理解幾何引導采樣的影響,在沒有GGS的情況下實現(xiàn)了學習去噪器。
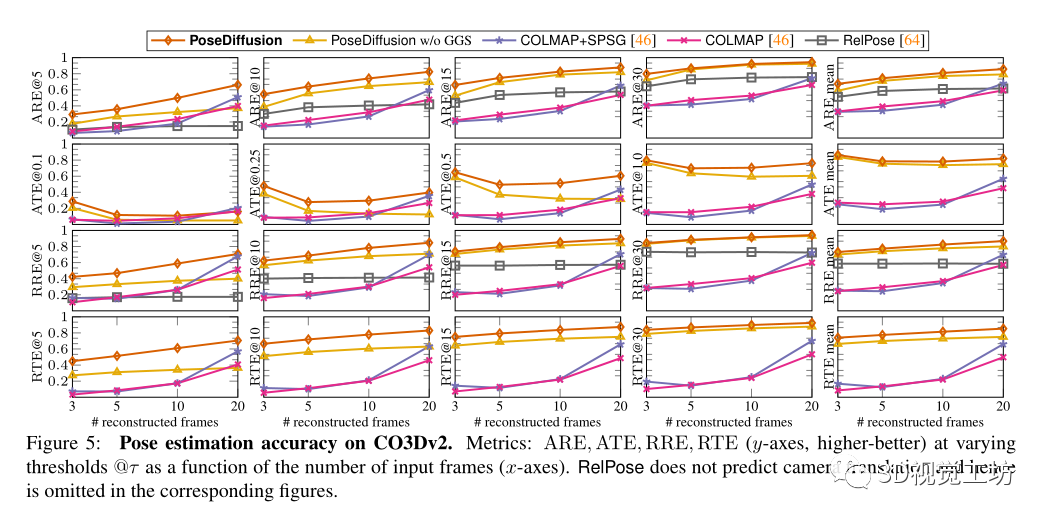
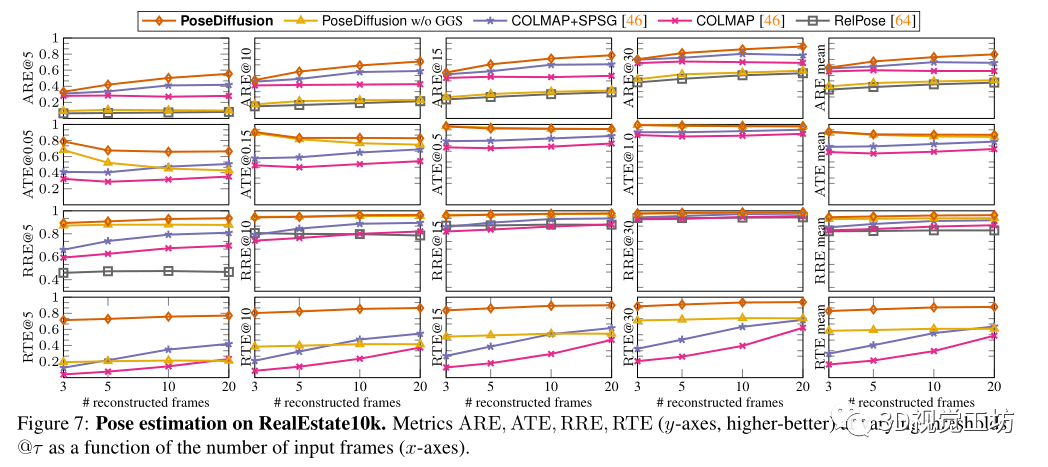
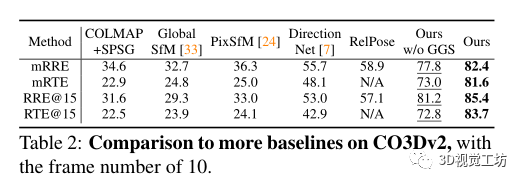
還評估了不同方法泛化到不同數(shù)據(jù)的能力。首先,在RelPose之后,對來自CO3Dv2的41個訓練類別進行訓練,并對剩余的10個保留類別進行評估。其方法優(yōu)于所有基線,表明具有優(yōu)越的泛化性。
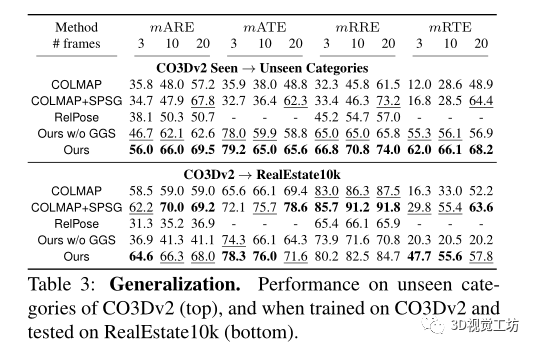
同時該方法還可以用來進行新視圖合成,用來幫助nerf。
總結(jié):
提出了Pose diffusion,這是一種學習的相機估計器,同時具有傳統(tǒng)極線幾何約束和擴散模型的能力。展示了擴散框架如何與相機參數(shù)估計任務(wù)兼容。這一經(jīng)典任務(wù)的迭代性質(zhì)反映在去噪擴散公式中。此外,圖像對之間的點匹配約束可以用于指導模型并細化最終預測。這改進了傳統(tǒng)的SfM方法,如COLMAP,以及學習的方法。展示了在姿態(tài)預測精度以及新的視圖合成(COLMAP當前最流行的應(yīng)用之一)任務(wù)方面的改進。
責任編輯:彭菁
-
相機
+關(guān)注
關(guān)注
4文章
1367瀏覽量
53914 -
模型
+關(guān)注
關(guān)注
1文章
3305瀏覽量
49220 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24833
原文標題:ArXiv2023 | PoseDiffusion:基于Diffusion的姿態(tài)估計算法,來自Meta AI
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于姿態(tài)校正的人臉檢測方法
針對姿態(tài)傳感器的姿態(tài)估計方法的詳細資料說明免費下載
一種采用深度殘差網(wǎng)絡(luò)的頭部姿態(tài)估計方法

基于深度學習的二維人體姿態(tài)估計方法

基于深度學習的二維人體姿態(tài)估計算法

基于Bagging-SVM集成分類器的頭部姿態(tài)估計方法
基于面部特征點定位的圖像人臉姿態(tài)估計方法
基于編解碼殘差的人體姿態(tài)估計方法
人臉姿態(tài)檢測|Fine Grained Head Pose Estimation Without Keypoint

基于OnePose的無CAD模型的物體姿態(tài)估計
一種基于去遮擋和移除的3D交互手姿態(tài)估計框架
Meta研究:基于頭顯攝像頭進行姿態(tài)估計的方法和優(yōu)缺點

AI深度相機-人體姿態(tài)估計應(yīng)用

基于飛控的姿態(tài)估計算法作用及原理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論