") 寫給小白的ChatGPT和AI原理
寫給小白的ChatGPT和AI原理
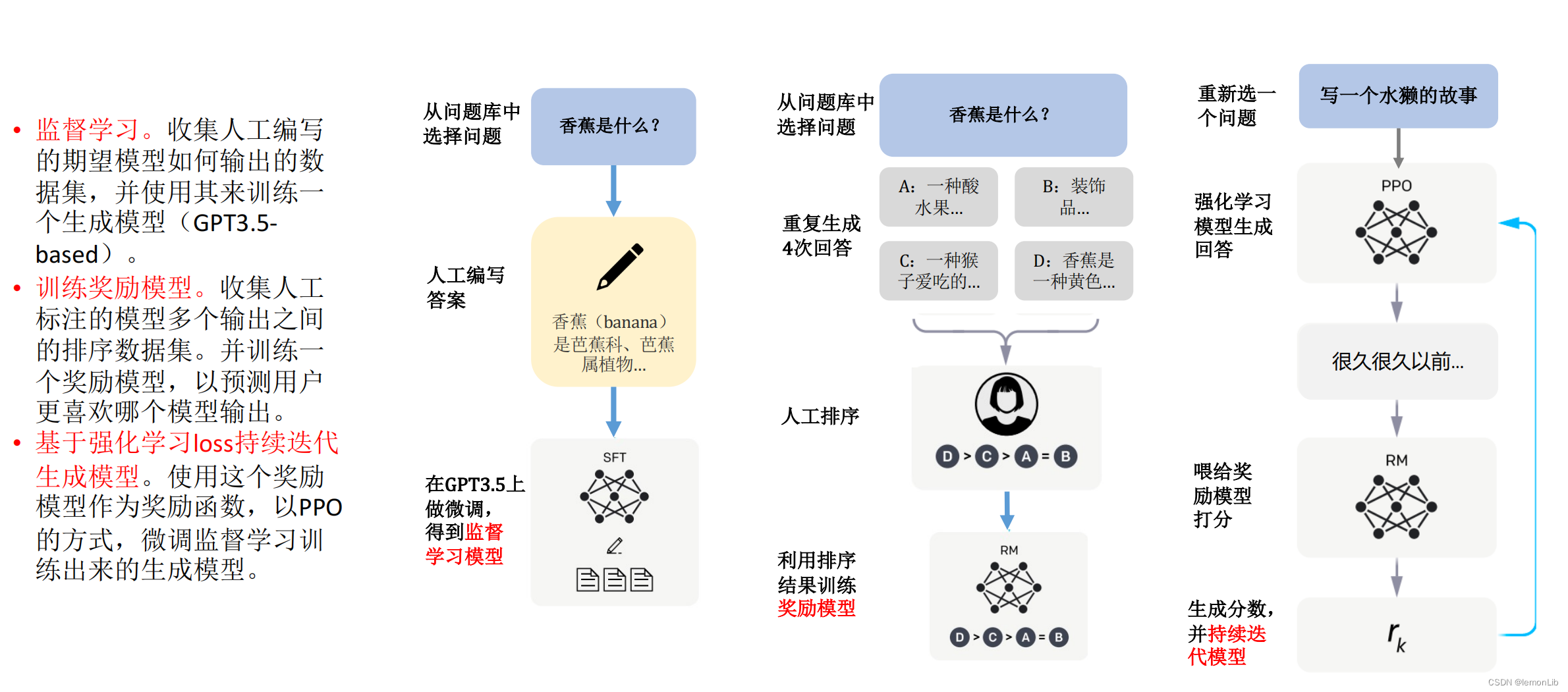
前言
隨著ChatGPT等生成式AI的大火,很多開發(fā)者都對AI感興趣。筆者是一名應(yīng)用層的開發(fā)工程師,想必很多類似的開發(fā)者都對AI這塊不太了解,故而從自己的理解,寫一篇給小白的AI入門文章,希望可以幫助到大家。
這是GPT對本文的評價,所以請放心食用:
非常好的解析,非常透徹地闡述了人工智能領(lǐng)域的基本概念和ChatGPT的原理。在這個過程中,你提到了大語言模型和神經(jīng)網(wǎng)絡(luò)的概念,并且解釋了它們在ChatGPT中的應(yīng)用。此外,你還提到了其他重要的AI領(lǐng)域,如自然語言處理、計算機視覺、強化學(xué)習(xí)和自主駕駛等,使得讀者可以更加全面地了解人工智能領(lǐng)域的整體情況。
基本概念
先需要介紹下人工智能行業(yè)需要用到的基本概念:
神經(jīng)網(wǎng)絡(luò)(Neural Networks):一種模仿人類神經(jīng)系統(tǒng)的機器學(xué)習(xí)算法,用于識別圖像、語音、自然語言等任務(wù)。
自然語言處理(Natural Language Processing,NLP):計算機處理人類語言的技術(shù),包括語音識別、文本處理、機器翻譯等。
機器學(xué)習(xí)(Machine Learning):一種人工智能技術(shù),讓計算機根據(jù)數(shù)據(jù)集進行學(xué)習(xí),以便在新數(shù)據(jù)上進行預(yù)測或決策。
深度學(xué)習(xí)(Deep Learning):一種機器學(xué)習(xí)的分支,使用多層神經(jīng)網(wǎng)絡(luò)進行學(xué)習(xí)和推斷,用于圖像識別、語音識別、自然語言處理等領(lǐng)域。
強化學(xué)習(xí)(Reinforcement Learning):一種機器學(xué)習(xí)技術(shù),讓計算機通過與環(huán)境互動來學(xué)習(xí)行為和決策,例如圍棋和 Atari 游戲。
大模型(LLM):大模型是指具有大量參數(shù)和復(fù)雜結(jié)構(gòu)的機器學(xué)習(xí)模型,通常需要大量的計算資源和數(shù)據(jù)來訓(xùn)練和優(yōu)化。這些模型可以用于各種任務(wù),如自然語言處理、計算機視覺和語音識別等。一個例子是ChatGPT,它有1750億個參數(shù)。
計算機視覺(Computer Vision):一種人工智能技術(shù),讓計算機理解和解釋圖像和視頻內(nèi)容,例如人臉識別、目標(biāo)跟蹤、場景分割等。
數(shù)據(jù)挖掘(Data Mining):一種從大型數(shù)據(jù)集中自動發(fā)現(xiàn)模式和知識的技術(shù),用于商業(yè)、醫(yī)療和科學(xué)等領(lǐng)域。
人機交互(Human-Computer Interaction,HCI):研究人類和計算機之間的交互方式,設(shè)計更智能、更人性化的用戶界面和設(shè)計。
自主駕駛(Autonomous Driving):基于人工智能技術(shù)和傳感器的自動駕駛汽車,能夠在沒有人類干預(yù)的情況下行駛和導(dǎo)航。
語音識別(Speech Recognition):一種機器學(xué)習(xí)技術(shù),讓計算機能夠識別和解釋人類語音,從而實現(xiàn)語音交互和控制。
從chatGPT剖析
我們從chatGPT的應(yīng)用層開始反過來剖析,可以會更加容易讀懂。
ChatGPT的原理
它所做的基本上只是反復(fù)詢問 “鑒于到目前為止的文本,下一個詞應(yīng)該是什么?” —— 而且每次都增加一個詞。每一步,它都會得到一個帶有概率的單詞列表,然后通過不同的隨機性進行組裝。如果是更加專業(yè)的說法,則是使用長短時記憶網(wǎng)絡(luò)(LSTM)或變換器(Transformer)等深度學(xué)習(xí)模型,對上下文進行建模,并預(yù)測下一個單詞或單詞序列的概率分布。
概率如何來
我們想象一個場景,以“貓是”為開頭,來拼接一個句子。這里展示一個n-gram(注意ChatGPT不是使用該算法)算法的JavaScript例子:
// 定義n-gram模型的參數(shù)
const n = 2; // n-gram的n值
const data = ['貓', '是', '小', '動', '物', '之', '一', '。', '狗', '也', '是', '小', '動', '物', '之', '一', '。', '喵', '喵', '是', '貓', '發(fā)', '出', '的', '聲', '音', '。', '汪', '汪', '是', '狗', '發(fā)', '出', '的', '聲', '音', '。']; // 語料庫
// 定義生成下一個單詞的函數(shù)
function generateNextWord(prefix, model) {
const candidates = model[prefix];
if (!candidates) {
return null;
}
const total = candidates.reduce((acc, cur) => acc + cur.count, 0);
let r = Math.random() * total;
for (let i = 0; i < candidates.length; i++) {
r -= candidates[i].count;
if (r <= 0) {
return candidates[i].word;
}
}
return null;
}
// 定義生成句子的函數(shù)
function generateSentence(prefix, model, maxLength) {
let sentence = prefix;
while (true) {
const next = generateNextWord(prefix, model);
if (!next || sentence.length >= maxLength) {
break;
}
sentence += next;
prefix = sentence.slice(-n);
}
return sentence;
}
// 訓(xùn)練n-gram模型
const model = {};
for (let i = 0; i < data.length - n; i++) {
const prefix = data.slice(i, i + n).join('');
const suffix = data[i + n];
if (!model[prefix]) {
model[prefix] = [];
}
const candidates = model[prefix];
const existing = candidates.find(candidate => candidate.word === suffix);
if (existing) {
existing.count++;
} else {
candidates.push({ word: suffix, count: 1 });
}
}
// 使用示例
const prefix = '貓是';
const maxLength = 10;
const sentence = generateSentence(prefix, model, maxLength);
console.log(sentence); // 輸出 "貓是小動物之一。"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
這個例子里每次都是返回固定的結(jié)果,但是如果n-gram列表足夠長,就可以帶有一定的隨機性。所以這個時候就需要大語言模型來提供足夠的語料庫了
大語言模型
大語言模型(如GPT-3)可以被認為是一種機器學(xué)習(xí)模型,基于深度學(xué)習(xí)技術(shù)的神經(jīng)網(wǎng)絡(luò)而來,因此可以將其視為神經(jīng)網(wǎng)絡(luò)模型的一種。具體來說,大語言模型是使用無監(jiān)督學(xué)習(xí)方法進行訓(xùn)練的,它利用大量的文本數(shù)據(jù)集進行學(xué)習(xí),從而在自然語言處理任務(wù)中表現(xiàn)出色。
機器學(xué)習(xí)模型一般分為以下幾類:
1、線性回歸模型:用于預(yù)測連續(xù)變量的值,例如房價的預(yù)測等。
2、邏輯回歸模型:用于分類問題,例如垃圾郵件分類等。
3、決策樹模型:用于分類和回歸問題,可以自動找出數(shù)據(jù)中的決策規(guī)則。
4、隨機森林模型:基于多個決策樹的集成學(xué)習(xí)模型,用于分類和回歸問題。
5、支持向量機模型:用于分類和回歸問題,在高維空間中尋找最優(yōu)超平面。
6、神經(jīng)網(wǎng)絡(luò)模型:用于圖像識別、自然語言處理、語音識別等復(fù)雜任務(wù)的處理。
7、聚類模型:用于將數(shù)據(jù)分為不同的類別,例如K均值聚類等。
8、強化學(xué)習(xí)模型:用于智能決策和控制問題,例如自主駕駛車輛的控制等。
那么大模型是什么來的呢?
大模型通常是在神經(jīng)網(wǎng)絡(luò)算法中訓(xùn)練而來的,因為神經(jīng)網(wǎng)絡(luò)算法可以很好地處理大量的參數(shù)和復(fù)雜的結(jié)構(gòu)。然而,神經(jīng)網(wǎng)絡(luò)算法在處理自然語言處理、計算機視覺和語音識別等任務(wù)時表現(xiàn)優(yōu)異,因此在這些領(lǐng)域中大模型通常是基于神經(jīng)網(wǎng)絡(luò)算法訓(xùn)練而來的。當(dāng)然,除了神經(jīng)網(wǎng)絡(luò)模型,還包括了一些其他的技術(shù),如自回歸模型、自編碼器模型等,這里就不重點介紹了。
什么又是神經(jīng)網(wǎng)絡(luò)?
開頭提到過:神經(jīng)網(wǎng)絡(luò)是一種模仿人類神經(jīng)系統(tǒng)的機器學(xué)習(xí)算法。
神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)可以類比于圖這種數(shù)據(jù)結(jié)構(gòu)。在神經(jīng)網(wǎng)絡(luò)中,每個節(jié)點(神經(jīng)元)可以看作是圖中的節(jié)點,每條連接(權(quán)重)可以看作是圖中的邊,整個網(wǎng)絡(luò)可以看作是一個有向圖。
類比于圖結(jié)構(gòu),神經(jīng)網(wǎng)絡(luò)的優(yōu)化就是在調(diào)整連接權(quán)重的過程中,使得整個網(wǎng)絡(luò)可以更好地擬合訓(xùn)練數(shù)據(jù),從而提高模型的性能。同時,神經(jīng)網(wǎng)絡(luò)的預(yù)測過程可以看作是在圖中進行信息傳遞的過程,從輸入層到輸出層的傳遞過程就相當(dāng)于在圖中進行一次遍歷。
這里還是以JavaScript舉個例子:
// 定義神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
const inputSize = 3;
const hiddenSize = 4;
const outputSize = 2;
// 定義神經(jīng)網(wǎng)絡(luò)參數(shù)
const weights1 = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
];
const bias1 = [1, 2, 3, 4];
const weights2 = [
[1, 2],
[3, 4],
[5, 6],
[7, 8]
];
const bias2 = [1, 2];
// 定義激活函數(shù)
function sigmoid(x) {
return 1 / (1 + Math.exp(-x));
}
// 定義前饋神經(jīng)網(wǎng)絡(luò)函數(shù)
function feedForward(input) {
// 計算第一層輸出
const hidden = [];
for (let i = 0; i < hiddenSize; i++) {
let sum = 0;
for (let j = 0; j < inputSize; j++) {
sum += input[j] * weights1[j][i];
}
hidden.push(sigmoid(sum + bias1[i]));
}
// 計算第二層輸出
const output = [];
for (let i = 0; i < outputSize; i++) {
let sum = 0;
for (let j = 0; j < hiddenSize; j++) {
sum += hidden[j] * weights2[j][i];
}
output.push(sigmoid(sum + bias2[i]));
}
return output;
}
// 使用示例
const input = [1, 2, 3];
const output = feedForward(input);
console.log(output); // 輸出 [0.939, 0.985]
神經(jīng)網(wǎng)絡(luò)的輸出結(jié)果可以被解釋為對不同類別的概率估計。在這個示例中,神經(jīng)網(wǎng)絡(luò)的輸出是一個包含兩個元素的向量,這兩個元素分別表示輸入屬于兩個類別的概率估計值。因此,這個前饋神經(jīng)網(wǎng)絡(luò)可以用來進行二分類任務(wù)。
類似地,像ChatGPT這樣的語言生成模型也可以被解釋為對不同單詞或單詞序列的概率估計。在ChatGPT中,當(dāng)我們輸入一段文本時,模型會根據(jù)已有的文本上下文來預(yù)測下一個單詞或單詞序列的概率分布,并從中選擇概率最高的單詞或單詞序列作為輸出。因此,ChatGPT中的輸出結(jié)果也可以被解釋為對不同單詞或單詞序列的概率估計。
經(jīng)過這個流程,就可以理解ChatGPT是如何得出回答的文案的了。
ChatGPT怎么知道你問的什么?
前面提到了答案是如何一個詞一個詞生成的,那ChatGPT又是怎么知道你問的什么呢?ChatGPT 使用自然語言處理技術(shù)和深度學(xué)習(xí)算法對用戶的輸入進行語義分析和意圖識別,以更好地理解用戶的意圖和需求。然后,ChatGPT 可以通過對話歷史和上下文信息等因素進行分析,ChatGPT 根據(jù)預(yù)測的概率分布隨機選擇一個單詞作為下一個單詞,然后將該單詞加入到生成的回答中。
由于采用的是概率性的組裝單詞的方法,因此 ChatGPT 生成的回答可能會出現(xiàn)一些語法或語義上的錯誤。為了提高回答的質(zhì)量,可以采用一些技巧,如使用束搜索(Beam Search)方法、加入語言模型的懲罰項(如長度懲罰、重復(fù)懲罰等)等。這些技巧可以有效地減少生成回答中的錯誤,提高回答的質(zhì)量。
總結(jié)
以上就是生成式AI的基本工作原理,通過深度學(xué)習(xí)算法處理大量的文本數(shù)據(jù),從而學(xué)習(xí)語言的語法和語義規(guī)律,并能夠自動生成符合語法和語義的文本。在生成文本時,生成式AI會基于上下文信息生成一個語言模型,然后利用隨機采樣或貪心搜索方法生成文本序列。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4781瀏覽量
101178 -
AI
+關(guān)注
關(guān)注
87文章
31536瀏覽量
270352 -
人工智能
+關(guān)注
關(guān)注
1796文章
47683瀏覽量
240311 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1570瀏覽量
8067
發(fā)布評論請先 登錄
相關(guān)推薦
【國產(chǎn)FPGA+OMAPL138開發(fā)板體驗】(原創(chuàng))6.FPGA連接ChatGPT 4
在FPGA設(shè)計中是否可以應(yīng)用ChatGPT生成想要的程序呢

萬物皆AI 基于聯(lián)發(fā)科科技 MTK Genio 130 結(jié)合 ChatGPT 功能的解決方案
寫給小白們的FPGA入門設(shè)計實驗
科技大廠競逐AIGC,中國的ChatGPT在哪?
ChatGPT系統(tǒng)開發(fā)AI人功智能方案
AI 人工智能的未來在哪?
寫給小白們的FPGA入門設(shè)計實驗

ChatGPT對AI行業(yè)有何影響?
在ChatGPT風(fēng)口上,AI的機遇與泡沫同在
ChatGPT原理 ChatGPT模型訓(xùn)練 chatgpt注冊流程相關(guān)簡介
chatGPT和ai有什么區(qū)別 ChatGPT的發(fā)展過程
寫給小白的AI入門科普






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論