 微表情識別-深度學習探索情感
微表情識別-深度學習探索情感
來源:易百納技術社區
隨著人工智能技術的不斷進步,深度學習成為計算機視覺領域的重要技術。微表情識別作為人類情感分析的一種重要手段,受到了越來越多的關注。本文將介紹基于深度學習的微表情識別技術,并提供一個示例代碼來演示其實現過程。
微表情是人類情感的微小表達,通常持續時間很短(不到1/25秒),難以察覺。然而,微表情蘊含了豐富的情感信息,對于理解他人的情感狀態以及非言語交流具有重要意義。
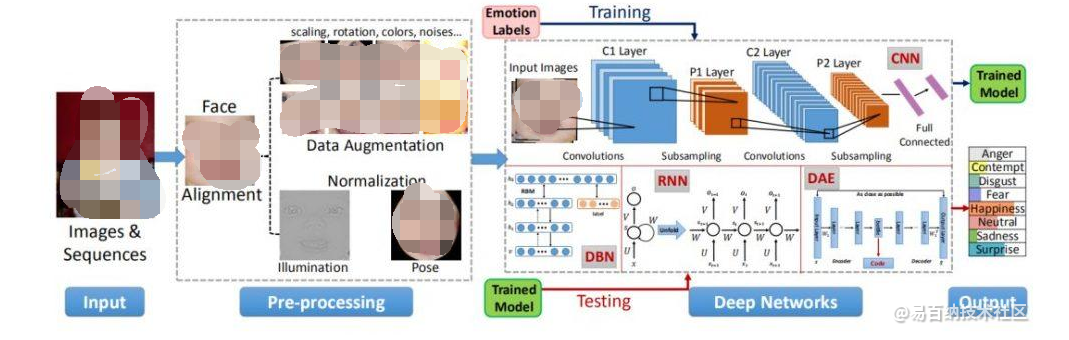
基于深度學習的微表情識別技術:
深度學習技術在圖像識別領域取得了巨大成功,也被應用于微表情識別。以下是一個基于深度學習的微表情識別技術框架:
數據收集與預處理:
構建一個高質量的微表情識別模型需要大量的帶有標簽的數據集。可以通過收集視頻數據并手動標注微表情的起始和終止幀來創建一個數據集。預處理步驟通常包括圖像幀的灰度化、歸一化和裁剪,以減少計算量并提高模型的魯棒性。
特征提取:
深度學習的一個主要優勢在于其能夠自動學習特征表示。在微表情識別中,可以使用卷積神經網絡(CNN)來提取特征。將預處理后的圖像幀輸入CNN,通過多個卷積層和池化層學習圖像的特征表示。
微表情識別模型:
在特征提取后,可以將其輸入到一個分類器中,例如支持向量機(SVM)或循環神經網絡(RNN),來對微表情進行分類。SVM適用于靜態圖像的分類,而RNN則可以處理時間序列數據,更適合微表情的分類任務。

基于深度學習的微表情識別
下面是一個簡單的示例代碼,演示了如何使用Python和Keras庫來實現一個基于CNN的微表情識別模型。請確保已經安裝了所需的庫。
# 導入所需的庫 import numpy as np import keras from keras.models import Sequential from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense # 構建CNN模型 model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 1))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dense(2, activation='softmax')) # 這里假設微表情有兩類:正面和負面 # 編譯模型 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 加載數據集并預處理 # 這里需要準備一個包含標簽的圖像數據集,圖像大小為64x64,灰度圖像 # X_train和y_train分別代表訓練集圖像和標簽 X_train = ... y_train = ... # 訓練模型 model.fit(X_train, y_train, epochs=10, batch_size=32) # 在測試集上評估模型 # 這里需要準備一個包含標簽的測試集,圖像大小為64x64,灰度圖像 # X_test和y_test分別代表測試集圖像和標簽 X_test = ... y_test = ... loss, accuracy = model.evaluate(X_test, y_test) print("測試集上的準確率:", accuracy)
雖然基于深度學習的微表情識別技術取得了顯著進展,但仍然存在一些技術挑戰需要解決。

數據集規模與質量:
深度學習模型通常需要大規模的數據集來訓練,以獲得較好的性能。對于微表情識別來說,獲取高質量、大規模且標記準確的數據集是一項挑戰。解決這個問題的方法可能包括增強數據集、引入合成數據或利用遷移學習等技術。
多樣性和泛化能力:
微表情通常是非常細微的情感表達,不同個體之間可能存在較大的差異。模型需要具備較強的泛化能力,能夠適應不同人群和情境的微表情。為了提高泛化性能,可以采用一些正則化技術,如批標準化、dropout等。
時間序列建模:
微表情是一種時間序列數據,需要將圖像序列作為輸入,同時考慮時間信息。傳統的CNN模型并不擅長處理時間序列數據。因此,可以嘗試使用循環神經網絡(RNN)、長短期記憶網絡(LSTM)或注意力機制等模型來更好地捕捉微表情的時序特征。
實時性:
在一些實際應用場景中,實時性是一個關鍵要求。例如,在視頻會議中對微表情進行實時識別,需要模型具備較快的推理速度。為了提高模型的實時性,可以采用輕量化的網絡結構、模型壓縮或硬件加速等方法。
未來發展方向: 隨著人工智能技術的不斷發展,基于深度學習的微表情識別技術有望在以下方向取得進一步的發展:
多模態融合:將音頻、姿態、心率等其他感知信息與圖像信息進行融合,可以更全面地理解和識別微表情,提高情感識別的準確性和魯棒性。
自監督學習:利用無需標注的數據進行自監督學習,從大量未標注的數據中學習表征,進一步提升模型性能。
弱監督學習:在數據標注成本較高的情況下,通過弱監督學習技術,利用少量標注數據和大量未標注數據進行訓練,實現性能的提升。
跨數據集泛化:構建能夠在不同數據集上泛化的微表情識別模型,使得模型具備更廣泛的應用能力。
隱私保護:在應用微表情識別技術時,需要考慮個人隱私的保護。研究隱私保護技術,確保在使用微表情識別技術時不侵犯個體隱私。
微表情識別模型的時間序列建模
使用Keras中的LSTM層來進行微表情的時間序列建模。假設我們已經準備好了帶有時間序列標簽的數據集,其中每個樣本是一個包含連續微表情圖像的序列。
# 導入所需的庫
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, LSTM, Dense
# 構建LSTM模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(TimeDistributed(Flatten())) # 對每一幀應用Flatten
model.add(LSTM(64, return_sequences=True)) # LSTM層處理時間序列
model.add(LSTM(32))
model.add(Dense(2, activation='softmax')) # 假設有兩類微表情:正面和負面
# 編譯模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 加載數據集并預處理
# 這里需要準備一個包含時間序列標簽的圖像數據集,圖像大小為64x64,灰度圖像
# X_train和y_train分別代表訓練集圖像和標簽
# X_train的形狀為 (樣本數, 時間步數, 圖像高度, 圖像寬度, 通道數)
X_train = ...
y_train = ...
# 訓練模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
# 在測試集上評估模型
# 這里需要準備一個包含時間序列標簽的測試集,圖像大小為64x64,灰度圖像
# X_test和y_test分別代表測試集圖像和標簽
X_test = ...
y_test = ...
loss, accuracy = model.evaluate(X_test, y_test)
print("測試集上的準確率:", accuracy)
在上面的代碼中,我們使用了Keras的TimeDistributed層來對每一幀圖像應用Flatten操作,以使圖像的特征在時間序列上進行扁平化。然后,我們使用兩個LSTM層來處理時間序列數據,從而更好地捕捉微表情的時序信息。
結論
基于深度學習的微表情識別技術為我們理解和分析人類情感提供了新的視角。通過深度學習技術的不斷進步和創新,相信微表情識別技術將在社交交互、心理學研究、情感智能等領域發揮重要作用,為人工智能領域帶來更多有意義的應用和突破。同時,我們也應該密切關注技術所帶來的社會和倫理問題,確保技術的發展與應用符合倫理和法律準則。
審核編輯 黃宇
-
人工智能
+關注
關注
1796文章
47680瀏覽量
240297 -
表情識別
+關注
關注
0文章
33瀏覽量
7435 -
深度學習
+關注
關注
73文章
5515瀏覽量
121553
發布評論請先 登錄
相關推薦
基于粗集的表情識別在電力學習中的應用
多文化場景下的多模態情感識別
深度學習下的AI微表情研究






 工商網監
工商網監
評論