 SpringCloud組件性能優化技巧分享
SpringCloud組件性能優化技巧分享
Springcloud的性能問題
應用服務組件調優
Servlet 容器 優化
Feign 配置優化
Gateway組件調優
Zuul配置 優化
hystrix配置 優化
ribbon 優化
Springcloud的性能問題
Springcloud 原始的配置,性能是很低的,大家可以使用Jmeter測試一下,QPS不會到50。要做到高并發,需要做不少的配置優化,主要的配置優化有以下幾點:
Feign 配置優化
hystrix配置 優化
ribbon 優化
Servlet 容器 優化
Zuul配置 優化
應用服務組件調優
Servlet 容器 優化
默認情況下,Spring Boot 使用 Tomcat 來作為內嵌的 Servlet 容器,可以將 Web 服務器切換到 Undertow 來提高應用性能,Undertow 是紅帽公司開發的一款基于 NIO 的高性能 Web 嵌入式
Zuul使用的內置容器默認是Tomcat,可以將其換成undertow,可以顯著減少線程的數量,替換方式即在pom中添加以下內容:
第一步,移除Tomcat 依賴
org.springframework.boot spring-boot-starter-web org.springframework.boot spring-boot-starter-tomcat
第二步,增加Untertow 依賴
org.springframework.boot spring-boot-starter-undertow
第三步,Undertow 的屬性配置
server: undertow: io-threads:16 worker-threads:256 buffer-size:1024 buffers-per-region:1024 direct-buffers:true
server.undertow.io-threads: 設置IO線程數, 它主要執行非阻塞的任務,它們會負責多個連接, 默認設置每個CPU核心一個線程,不要設置過大,如果過大,啟動項目會報錯:打開文件數過多
server.undertow.worker-threads`:阻塞任務線程池,當執行類似servlet請求阻塞IO操作,undertow會從這個線程池中取得線程,它的值設置取決于系統線程執行任務的阻塞系數,默認值是`IO線程數*8
server.undertow.buffer-size: 以下的配置會影響buffer,這些buffer會用于服務器連接的IO操作,有點類似netty的池化內存管理,每塊buffer的空間大小,越小的空間被利用越充分,不要設置太大,以免影響其他應用,合適即可
server.undertow.buffers-per-region`:每個區分配的buffer數量,所以pool的大小是`buffer-size*buffers-per-region
server.undertow.direct-buffers: 是否分配的直接內存(NIO直接分配的堆外內存)

Feign 配置優化
feign 默認不啟用hystrix,需要手動指定 feign.hystrix.enabled=true 開啟熔斷
feign 啟用壓縮也是一種有效的性能優化方式,具體的配置如下
feign: compression: request: enabled:true mime-types:text/xml,application/xml,application/json response: enabled:true
feign HTTP請求方式選擇
feign默認使用的是基于JDK提供的URLConnection調用HTTP接口,不具備連接池,所以資源開銷上有點影響,經測試JDK的URLConnection比Apache HttpClient快很多倍。Apache HttpClient和okhttp都支持配置連接池功能,也可以使用okhttp請求方式。
當使用HttpClient時,可如下設置:
feign: httpclient: enabled:true max-connections:1000 max-connections-per-route:200
當使用OKHttp時,可如下設置:
feign: okhttp: enabled:true httpclient: max-connections:1000 max-connections-per-route:200
max-connections 設置整個連接池最大連接數(該值默認為200), 根據自己的場景決定
max-connections-per-route 設置路由的默認最大連接(該值默認為50),限制數量實際使用

基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/yudao-cloud
視頻教程:https://doc.iocoder.cn/video/
Gateway組件調優
Zuul配置 優化
我們知道Hystrix有隔離策略:THREAD 以及SEMAPHORE ,默認是 SEMAPHORE 。
Zuul默認是使用信號量隔離,并且信號量的大小是100,請求的并發線程超過100就會報錯,可以調大該信號量的最大值來提高性能,配置如下:
zuul: semaphore: max-semaphores:5000
表示,當Zuul的隔離策略為SEMAPHORE時,設置指定服務的最大信號量為5000。對于特定的微服務,可以通過下面的方式,設置最大信號量
設置默認最大信號量:
zuul: semaphore: max-semaphores:5000#默認值
設置指定服務的最大信號量:
zuul: eureka: : semaphore: max-semaphores:5000

為了方便ThreadLocal的使用,也可以改為使用線程隔離的策略,這種場景下,就需要調大hystrix線程池線程大小,該線程池默認10個線程,調整的配置示例如下:
zuul: ribbonIsolationStrategy:THREAD hystrix: threadpool: default: coreSize:100 maximumSize:400 allowMaximumSizeToDivergeFromCoreSize:true maxQueueSize:-1
hystrix.threadpool.default.allowMaximumSizeToDivergeFromCoreSize:是否讓maximumSize生效,false的話則只有coreSize會生效
hystrix.threadpool.default.maxQueueSize:線程池的隊列大小,-1代表使用SynchronousQueue隊列
hystrix.threadpool.default.maximumSize:最大線程數量
hystrix.threadpool.default.allowMaximumSizeToDivergeFromCoreSize:是否讓maximumSize生效,false的話則只有coreSize會生效
hystrix.threadpool.default.maxQueueSize:線程池的隊列大小,-1代表使用SynchronousQueue隊列
zuul.ribbon-isolation-strategy:設置線程隔離,thread 線程隔離,SEMAPHORE 表示信號量隔離
默認配置都可以去HystrixThreadPoolProperties和ZuulProperties這兩個java文件中查找
hystrix配置 優化
首先需要設置參數hystrix.threadpool.default.coreSize 來指定熔斷隔離的線程數,這個數需要調優,經測試線程數我們設置為和提供方的容器線程差不多,吞吐量高許多。
其次,啟用Hystrix后,很多服務當第一次訪問的時候都會失敗 是因為初始化負載均衡一系列操作已經超出了超時時間了,因為默認的超時時間為1S,需要修改超時時間參數,方可解決這個問題。
參考的hystrix配置如下:
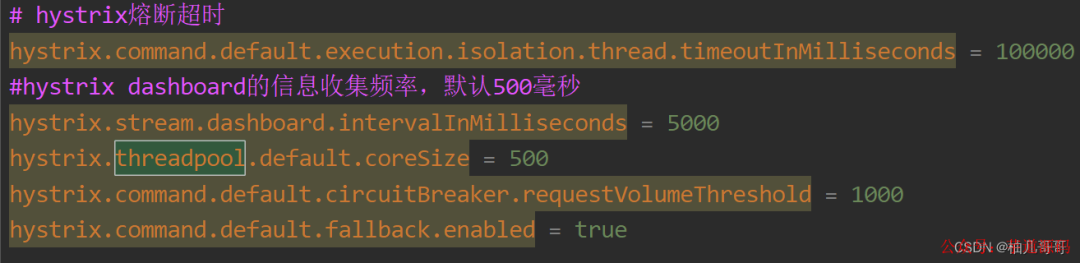
hystrix: threadpool: default: coreSize:500 command: default: circuitBreaker: requestVolumeThreshold:1000 fallback: enabled:true execution: isolation: thread: timeoutInMilliseconds:100000
hystrix.command.default: 全局的作用域,作用的所有的hystrix的客戶端,如果需要對某個微服務,可以寫serviceId
hystrix.command.default.fallback.enabled 是否開啟回退方法
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds 請求處理的超時時間,缺省為1000,表示默認的超時時間為1S
hystrix.threadpool.default.coreSize 核心線程池數量
hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests 回退最大線程數
hystrix.command.default.circuitBreaker.requestVolumeThreshold 熔斷器失敗的個數,進入熔斷器的請求達到1000時服務降級(之后的請求直接進入熔斷器)
ribbon 優化
Ribbon進行客戶端負載均衡的Client并不是在服務啟動的時候就初始化好的,而是在調用的時候才會去創建相應的Client,所以第一次調用的耗時不僅僅包含發送HTTP請求的時間,還包含了創建RibbonClient的時間,這樣一來如果創建時間速度較慢,同時設置的超時時間又比較短的話,很容易就會出現上面所描述的顯現。
因此我們可以通過設置:
ribbon: eager-load: enabled:true clients:service-1,service-2,service-n

參數說明:
ribbon.eager-load.enabled : 開啟Ribbon的饑餓加載模式
ribbon.eager-load.clients: 指定需要饑餓加載的服務名,如果不指定服務名稱,饑餓加載模式無效
Zuul的饑餓加載,沒有設計專門的參數來配置,而是直接采用了讀取路由配置來進行饑餓加載。所以,如果我們使用默認路由,而沒有通過配置的方式指定具體路由規則,那么 zuul.ribbon.eager-load.enabled=true 的配置就沒有什么作用了。
如果需要真正啟用Zuul 的饑餓加載,需要通過zuul.ignored-services=*來忽略所有的默認路由,讓所有路由配置均維護在配置文件中,以達到網關啟動的時候就加載好各個路由的負載均衡對象。
關于Zuul 的默認路由,這里詳細介紹一下。假設你的注冊服務中心有三個已經注冊的服務名稱service-a,service-b,service-c。但是在zuul配置文件中,只映射了service-a,service-b,如下:
zuul: ribbon: eager-load: enabled:true ignored-services:‘*’ routes: a: path:/a/** serviceId:service-a b: path:/b/** serviceId:service-b
這里,雖然沒有配置service-c的映射,但是,由于zuul有默認的映射機制,還是可以通過Url,訪問到你的service-c服務,如果不想向外界暴露默認的服務映射,可以加上 zuul.ignored-services:*
審核編輯:劉清
-
URL
+關注
關注
0文章
139瀏覽量
15478 -
JAVA語言
+關注
關注
0文章
138瀏覽量
20178 -
QPS
+關注
關注
0文章
24瀏覽量
8830 -
HTTP接口
+關注
關注
0文章
21瀏覽量
1841
原文標題:SpringCloud 組件性能優化技巧
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
HarmonyOS NEXT應用開發性能優化入門引導
一款3605電源芯片的性能優化與改進思路
HarmonyOS Web開發性能優化指導
HBase性能優化方法總結
AN0004—AT32 性能優化
《現代CPU性能分析與優化》---精簡的優化書
優化揚聲器組件的三個例子分享





 工商網監
工商網監
評論