 機器學習為什么需要數據預處理
機器學習為什么需要數據預處理
數據預處理是準備原始數據并使其適合機器學習模型的過程。這是創建機器學習模型的第一步也是關鍵的一步。
創建機器學習項目時,我們并不總是遇到干凈且格式化的數據。在對數據進行任何操作時,必須對其進行清理并以格式化的方式進行存儲。為此,我們使用數據預處理任務。
為什么我們需要數據預處理?
現實世界的數據通常包含噪聲、缺失值,并且可能采用無法直接用于機器學習模型的不可用格式。數據預處理是清理數據并使其適合機器學習模型所需的任務,這也提高了機器學習模型的準確性和效率。
它涉及以下步驟:
獲取數據集
導入庫
導入數據集
查找丟失的數據
編碼分類數據
將數據集拆分為訓練集和測試集
特征縮放
1)獲取數據集
要創建機器學習模型,我們首先需要的是數據集,因為機器學習模型完全依賴于數據。以適當的格式針對特定問題收集的數據稱為數據集。
出于不同的目的,數據集可能具有不同的格式,例如,如果我們想要創建用于商業目的的機器學習模型,那么數據集將與肝臟患者所需的數據集不同。因此每個數據集都不同于另一個數據集。為了在代碼中使用數據集,我們通常將其放入 CSV文件中。然而,有時,我們可能還需要使用 HTML 或 xlsx 文件。
什么是 CSV 文件?
CSV 代表“逗號分隔值”文件;它是一種文件格式,允許我們保存表格數據,例如電子表格。它對于巨大的數據集很有用,并且可以在程序中使用這些數據集。
這里我們將使用一個演示數據集進行數據預處理,為了練習,可以從這里下載,“https://www.superdatascience.com/pages/machine-learning。對于實際問題,我們可以在線下載數據集來自各種來源,例如https://www.kaggle.com/uciml/datasets、https://archive.ics.uci.edu/ml/index.php等。
我們還可以通過使用 Python 的各種 API 收集數據來創建數據集,并將該數據放入 .csv 文件中。
2) 導入庫
為了使用Python進行數據預處理,我們需要導入一些預定義的Python庫。這些庫用于執行一些特定的工作。我們將使用三個特定的庫來進行數據預處理,它們是:
Numpy:Numpy Python 庫用于在代碼中包含任何類型的數學運算。它是Python中科學計算的基礎包。它還支持添加大型多維數組和矩陣。因此,在 Python 中,我們可以將其導入為:
將 numpy 導入為 nm
這里我們使用了nm,它是 Numpy 的簡稱,它將在整個程序中使用。
Matplotlib:第二個庫是matplotlib,它是一個 Python 2D 繪圖庫,使用這個庫,我們需要導入一個子庫pyplot。該庫用于在 Python 中為代碼繪制任何類型的圖表。它將按如下方式導入:
將 matplotlib.pyplot 導入為 mpt
這里我們使用 mpt 作為該庫的簡稱。
Pandas:最后一個庫是 Pandas 庫,它是最著名的 Python 庫之一,用于導入和管理數據集。它是一個開源數據操作和分析庫。它將按如下方式導入:
在這里,我們使用 pd 作為該庫的簡稱。考慮下圖:

3)導入數據集
現在我們需要導入為機器學習項目收集的數據集。但在導入數據集之前,我們需要將當前目錄設置為工作目錄。要在Spyder IDE中設置工作目錄,我們需要按照以下步驟操作:
將 Python 文件保存在包含數據集的目錄中。
轉到 Spyder IDE 中的文件資源管理器選項,然后選擇所需的目錄。
單擊 F5 按鈕或運行選項來執行該文件。
注意:我們可以將任何目錄設置為工作目錄,但它必須包含所需的數據集。
在下圖中,我們可以看到 Python 文件以及所需的數據集。現在,當前文件夾被設置為工作目錄。
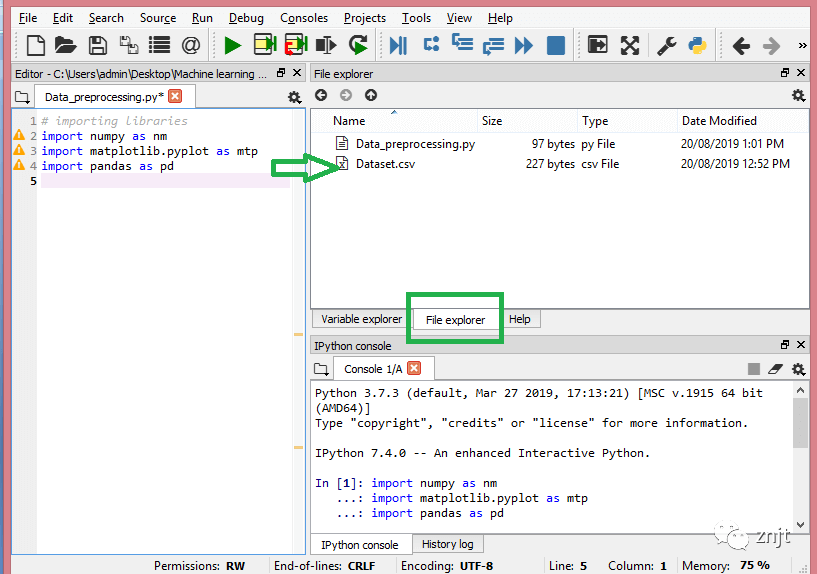
read_csv() 函數:
現在要導入數據集,我們將使用pandas庫的read_csv()函數,用于讀取數據集文件并對其執行各種操作。使用此函數,我們可以在本地以及通過 URL 讀取 csv 文件。
我們可以使用 read_csv 函數,如下所示:
data_set = pd .read_csv('數據集.csv')
這里,data_set是存儲數據集的變量名稱,在函數內部,我們傳遞了數據集的名稱。一旦我們執行了上面這行代碼,它將成功地將數據集導入到我們的代碼中。我們還可以通過單擊變量資源管理器部分來檢查導入的數據集,然后雙擊data_set。考慮下圖:
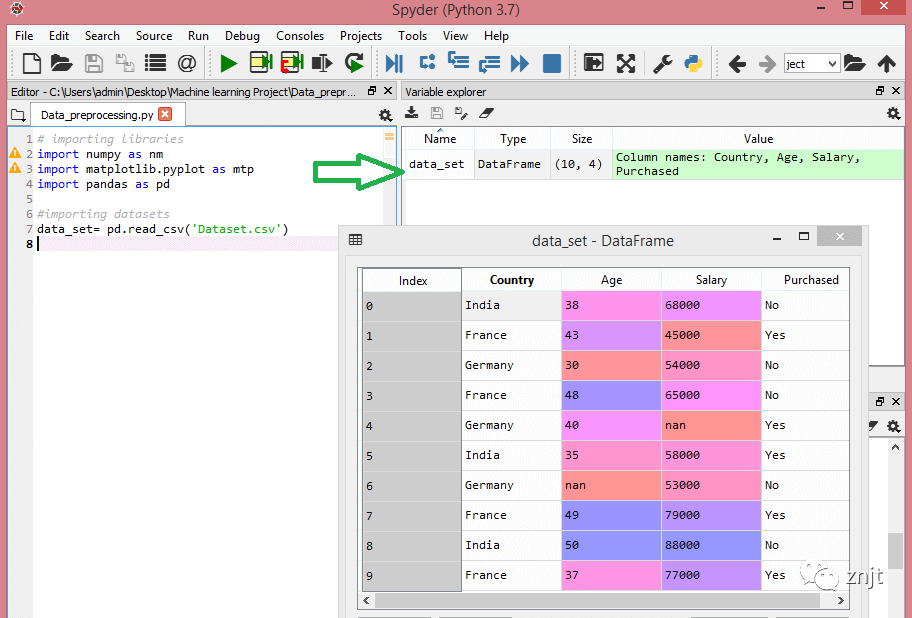
如上圖,索引從0開始,這是Python中默認的索引。我們還可以通過單擊格式選項來更改數據集的格式。
提取因變量和自變量:
在機器學習中,區分數據集中的特征矩陣(自變量)和因變量非常重要。在我們的數據集中,有 3 個自變量,即Country、Age和Salary,以及一個因變量Purchasing。
提取自變量:
為了提取自變量,我們將使用Pandas 庫的iloc[ ]方法。它用于從數據集中提取所需的行和列。
x = data_set .iloc[:,:-1].values
在上面的代碼中,第一個冒號(:)用于獲取所有行,第二個冒號(:)用于獲取所有列。這里我們使用了 :-1,因為我們不想采用最后一列,因為它包含因變量。通過這樣做,我們將得到特征矩陣。
通過執行上面的代碼,我們將得到如下輸出:
[['India' 38.0 68000.0] ['France' 43.0 45000.0] ['Germany' 30.0 54000.0] ['France' 48.0 65000.0] ['Germany' 40.0 nan] ['India' 35.0 58000.0] ['Germany' nan 53000.0] ['France' 49.0 79000.0] ['India' 50.0 88000.0] ['France' 37.0 77000.0]]
正如我們在上面的輸出中看到的,只有三個變量。
提取因變量:
為了提取因變量,我們將再次使用 Pandas .iloc[] 方法。
y = data_set .iloc[:,3].values
在這里,我們僅獲取了所有行和最后一列。它將給出因變量的數組。
通過執行上面的代碼,我們將得到如下輸出:
輸出:
array(['No', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes'],
dtype=object)
數據類型=對象)
注意:如果您使用Python語言進行機器學習,則提取是必需的,但對于R語言則不需要。
4)處理缺失數據:
數據預處理的下一步是處理數據集中缺失的數據。如果我們的數據集包含一些缺失的數據,那么它可能會給我們的機器學習模型帶來巨大的問題。因此,有必要處理數據集中存在的缺失值。
處理缺失數據的方法:
處理缺失數據主要有兩種方法:
通過刪除特定行:第一種方式通常用于處理空值。這樣,我們只需刪除由空值組成的特定行或列即可。但這種方式效率不高,刪除數據可能會導致信息丟失,從而無法給出準確的輸出。
通過計算平均值:這樣,我們將計算包含任何缺失值的該列或行的平均值,并將其放在缺失值的位置。該策略對于具有年齡、薪水、年份等數字數據的特征非常有用。在這里,我們將使用這種方法。
為了處理缺失值,我們將在代碼中使用Scikit-learn庫,其中包含用于構建機器學習模型的各種庫。這里我們將使用sklearn.preprocessing庫的Imputer類。下面是它的代碼:
#處理缺失數據(用平均值替換缺失數據) 從 sklearn.preprocessing 導入 Imputer imputer = Imputer (missing_values = 'NaN' , 策略= '平均值' , 軸 = 0 ) #將imputer對象擬合到自變量x。 imputer imputer = imputer.fit(x[:, 1:3]) #用計算出的平均值替換缺失數據 x[:, 1:3]= imputer.transform(x[:, 1:3])
輸出:
array([['India', 38.0, 68000.0],
['France', 43.0, 45000.0],
['Germany', 30.0, 54000.0],
['France', 48.0, 65000.0],
['Germany', 40.0, 65222.22222222222],
['India', 35.0, 58000.0],
['Germany', 41.111111111111114, 53000.0],
['France', 49.0, 79000.0],
['India', 50.0, 88000.0],
['France', 37.0, 77000.0]], dtype=object
正如我們在上面的輸出中看到的,缺失值已被替換為其余列值的平均值。
5)編碼分類數據:
分類數據是具有某些類別的數據,例如在我們的數據集中;有兩個分類變量,Country和Purchasing。
由于機器學習模型完全適用于數學和數字,但如果我們的數據集有分類變量,那么在構建模型時可能會產生麻煩。因此有必要將這些分類變量編碼為數字。
對于國家變量:
首先,我們將國家變量轉換為分類數據。為此,我們將使用預處理庫中的LabelEncoder()類。
#分類數據 #for國家變量 從 sklearn.preprocessing 導入 LabelEncoder label_encoder_x = LabelEncoder () x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
輸出:
Out[15]:
array([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=object)
解釋:
在上面的代碼中,我們導入了sklearn庫的LabelEncoder類。此類已成功將變量編碼為數字。
但在我們的例子中,有三個國家變量,正如我們在上面的輸出中看到的,這些變量被編碼為 0、1 和 2。通過這些值,機器學習模型可以假設這些變量之間存在某種相關性。會產生錯誤輸出的變量。因此,為了解決這個問題,我們將使用虛擬編碼。
虛擬變量:
虛擬變量是那些值為 0 或 1 的變量。值 1 表示該變量在特定列中的存在,其余變量變為 0。通過虛擬編碼,我們將擁有等于類別數的列數。
在我們的數據集中,我們有 3 個類別,因此它將生成具有 0 和 1 值的三列。對于虛擬編碼,我們將使用預處理庫的OneHotEncoder類。
#for國家變量 從sklearn.preprocessing導入LabelEncoder、OneHotEncoder label_encoder_x=LabelEncoder() x[:,0]=label_encoder_x.fit_transform(x[:,0]) #虛擬變量的編碼 onehot_encoder=OneHotEncoder(categorical_features=[0]) x=onehot_encoder.fit_transform(x).toarray()
輸出:
array([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
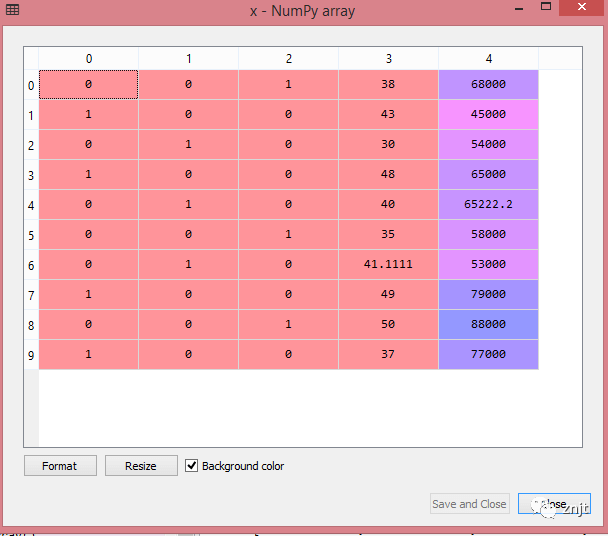
正如我們在上面的輸出中看到的,所有變量都被編碼為數字 0 和 1,并分為三列。
通過單擊 x 選項,可以在變量資源管理器部分中更清楚地看到它:
對于購買的變量:
labelencoder_y = LabelEncoder () y = labelencoder_y .fit_transform(y)
對于第二個分類變量,我們將僅使用LableEncoder類的 labelencoder 對象。這里我們沒有使用OneHotEncoder類,因為購買的變量只有 yes 或 no 兩個類別,并且自動編碼為 0 和 1。
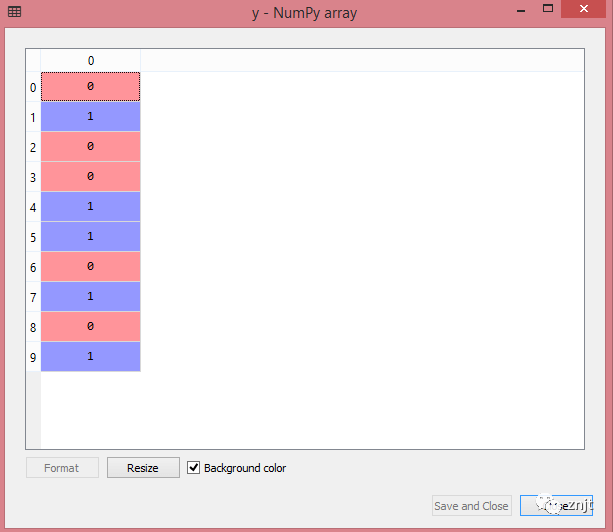
輸出:
Out[17]:array([0,1,0,0,1,1,0,1,0,1])
view:
6)將數據集分為訓練集和測試集
在機器學習數據預處理中,我們將數據集分為訓練集和測試集。這是數據預處理的關鍵步驟之一,因為通過這樣做,我們可以提高機器學習模型的性能。
假設,如果我們通過數據集對機器學習模型進行訓練,并通過完全不同的數據集對其進行測試。那么,這會給我們的模型理解模型之間的相關性帶來困難。
如果我們的模型訓練得很好,它的訓練精度也很高,但是我們給它提供了一個新的數據集,那么它的性能就會下降。因此,我們總是嘗試建立一個在訓練集和測試數據集上都表現良好的機器學習模型。在這里,我們可以將這些數據集定義為:
訓練集:用于訓練機器學習模型的數據集子集,我們已經知道輸出。
測試集:用于測試機器學習模型的數據集子集,模型通過使用測試集來預測輸出。
為了分割數據集,我們將使用以下代碼行:
#從 sklearn.model_selection 導入 train_test_split x_train,x_test,y_train, y_test = train_test_split (x,y, test_size = 0 .2, random_state = 0 )
解釋:
在上面的代碼中,第一行用于將數據集數組拆分為隨機訓練和測試子集。
在第二行中,我們使用了四個變量作為輸出:
x_train:訓練數據的特征
x_test:測試數據的特征
y_train:訓練數據的因變量
y_test:測試數據的自變量
在train_test_split()函數中,我們傳遞了四個參數,其中前兩個用于數據數組,test_size用于指定測試集的大小。test_size 可能是 0.5、.3 或 .2,它告訴我們訓練集和測試集的劃分比例。
最后一個參數random_state用于設置隨機生成器的種子,以便始終得到相同的結果,最常用的值為 42。
輸出:
通過執行上面的代碼,我們將得到4個不同的變量,可以在變量資源管理器部分看到。
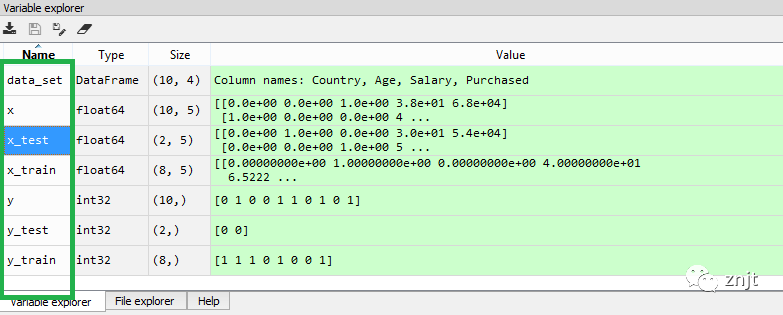
正如我們在上圖中看到的,x 和 y 變量被分為 4 個具有相應值的不同變量。
7) 特征縮放
特征縮放是機器學習中數據預處理的最后一步。它是一種將數據集的自變量標準化在特定范圍內的技術。在特征縮放中,我們將變量放在相同的范圍和相同的比例中,以便沒有任何變量支配其他變量。
考慮以下數據集:
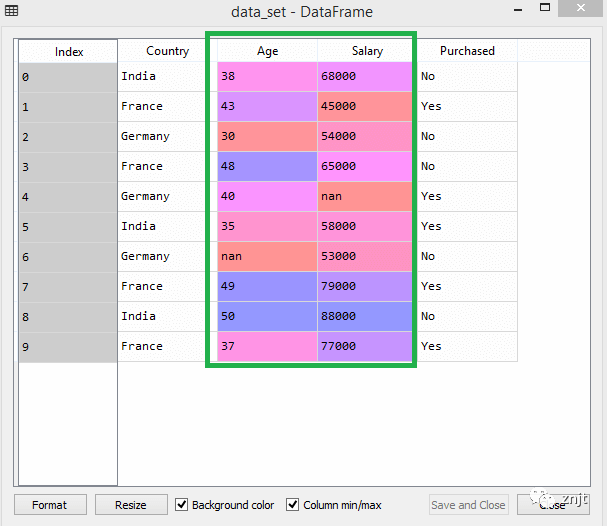
正如我們所看到的,年齡和薪水列值不在同一范圍內。機器學習模型基于歐幾里德距離,如果我們不縮放變量,那么它將在我們的機器學習模型中引起一些問題。
歐幾里德距離給出為:
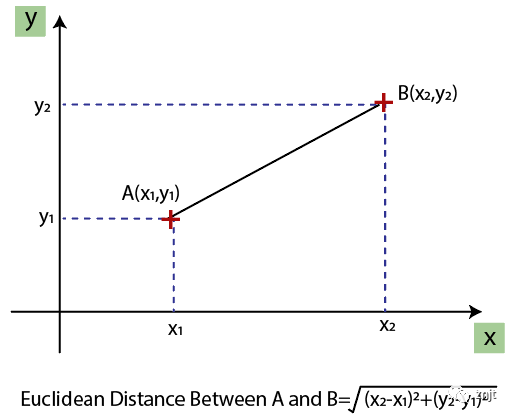
如果我們根據年齡和薪水計算任意兩個值,那么薪水值將主導年齡值,并且會產生不正確的結果。因此,為了解決這個問題,我們需要對機器學習進行特征縮放。
機器學習中有兩種執行特征縮放的方法:
標準化
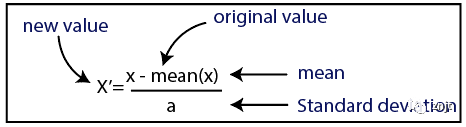
正常化
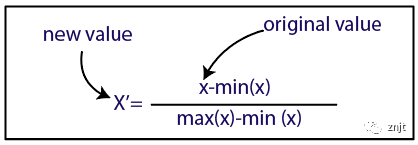
在這里,我們將對數據集使用標準化方法。
對于特征縮放,我們將導入sklearn.preprocessing庫的StandardScaler類:
從 sklearn.preprocessing 導入 StandardScaler
現在,我們將為自變量或特征創建StandardScaler類的對象。然后我們將擬合和轉換訓練數據集。
st_x = 標準縮放器() x_train = st_x .fit_transform(x_train)
對于測試數據集,我們將直接應用transform()函數而不是fit_transform(),因為它已經在訓練集中完成了。
x_test = st_x .transform(x_test)
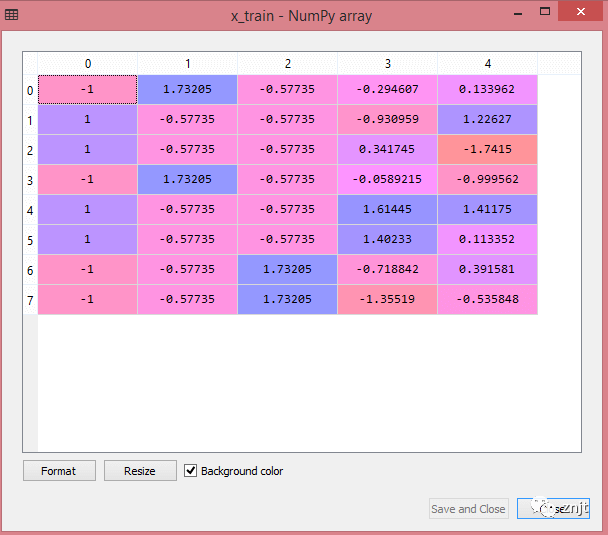
輸出:
通過執行上面的代碼行,我們將得到 x_train 和 x_test 的縮放值:
x_train:
x_test:
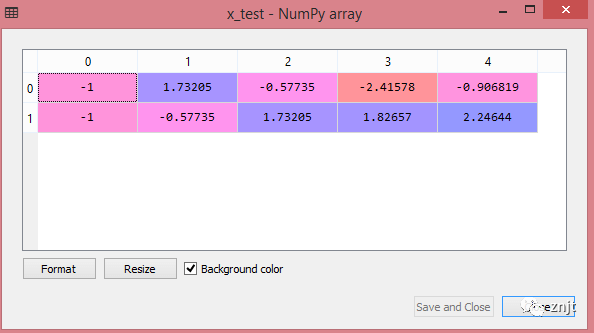
正如我們在上面的輸出中看到的,所有變量都在值 -1 到 1 之間縮放。
注意:這里,我們沒有縮放因變量,因為只有兩個值 0 和 1。但是如果這些變量有更多的值范圍,那么我們還需要縮放這些變量。
結合所有步驟:
現在,最后,我們可以將所有步驟組合在一起,使完整的代碼更容易理解。
# 導入庫
將 numpy 導入為 nm
將 matplotlib.pyplot 導入為 mtp
將 pandas 導入為 pd
#導入數據集
data_set = pd .read_csv('數據集.csv')
#提取自變量
x = data_set .iloc[:, :-1].values
#提取因變量
y = data_set .iloc[:, 3].values
#處理缺失數據(用平均值替換缺失數據)
從 sklearn.preprocessing 導入 Imputer
imputer = Imputer (missing_values = 'NaN' , 策略= '平均值' , 軸 = 0 )
#將輸入對象擬合到獨立變量x。
imputer imputer = imputer.fit(x[:, 1:3])
#用計算出的平均值替換缺失數據
x[:, 1:3]= imputer.transform(x[:, 1:3])
#for 國家變量
從 sklearn.preprocessing 導入 LabelEncoder、OneHotEncoder
label_encoder_x = LabelEncoder ()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#虛擬變量的編碼
onehot_encoder = OneHotEncoder ( categorical_features = [0])
x = onehot_encoder .fit_transform(x).toarray()
#購買變量的編碼
labelencoder_y = LabelEncoder ()
y = labelencoder_y .fit_transform(y)
# 將數據集分為訓練集和測試集。
從 sklearn.model_selection 導入 train_test_split
x_train,x_test,y_train, y_test = train_test_split (x,y, test_size = 0 .2, random_state = 0 )
#數據集的特征縮放
從 sklearn.preprocessing 導入 StandardScaler
st_x = 標準縮放器()
x_train = st_x .fit_transform(x_train)
x_test = st_x .transform(x_test)
在上面的代碼中,我們將所有數據預處理步驟包含在一起。但有些步驟或代碼行并不是所有機器學習模型都必需的。因此,我們可以將它們從我們的代碼中排除,使其可重用于所有模型。
審核編輯:彭菁
-
數據
+關注
關注
8文章
7145瀏覽量
89591 -
模型
+關注
關注
1文章
3313瀏覽量
49233 -
代碼
+關注
關注
30文章
4828瀏覽量
69063 -
機器學習
+關注
關注
66文章
8441瀏覽量
133094 -
python
+關注
關注
56文章
4807瀏覽量
85041
原文標題:機器學習中的數據預處理
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器學習的任務:從學術論文中學習數據預處理






 工商網監
工商網監
評論