 一個動態環境下的實時語義RGB-D SLAM系統
一個動態環境下的實時語義RGB-D SLAM系統
作者:K.Fire | 來源:3D視覺工坊
大多數現有的視覺SLAM方法嚴重依賴于靜態世界假設,在動態環境中很容易失效。本文提出了一個動態環境下的實時語義RGB-D SLAM系統,該系統能夠檢測已知和未知的運動物體。為了減少計算成本,其只對關鍵幀進行語義分割以去除已知的動態對象,并保持靜態映射以實現穩健的攝像機跟蹤。此外,文章還提出了一個有效的幾何模塊,通過將深度圖像聚類到幾個區域,并通過它們的重投影誤差來識別動態區域,從而檢測未知的運動物體。
1 前言
盡管現有很多的vSLAM系統都有很好的性能,但這些方法中的大多數嚴重依賴于靜態世界假設,這極大地限制了它們在現實世界場景中的部署。
由于移動的人、動物和車輛等動態物體對姿態估計和地圖重建有負面影響。盡管穩健的估計技術(如RANSAC)可以用于過濾掉一些異常值,但改進仍然有限,因為它們只能處理輕微的動態場景,當移動的物體覆蓋大部分相機視圖時,仍然可能失敗。
由于計算機視覺和深度學習的最新進展,環境的語義信息已被集成到SLAM系統中,比如通過語義分割提取語義信息,預測被檢測對象的標簽并生成掩碼。通過識別和去除潛在的動態目標,vSLAM在動態場景中的性能可以得到很大的提高。
然而,這些方法仍然存在兩個主要問題:
強大的語義分割神經網絡算法計算成本很高,不適用于實時和小規模機器人應用。
而對于輕量級網絡,分割精度可能會降低,跟蹤精度也會受到影響。另一個問題是,它們只能處理在網絡的訓練集中被標記的已知物體,面對未知的運動物體時仍然可能失敗。
為了識別具有語義線索的動態對象,大多數現有方法對每個新幀進行語義分割。這將導致相機跟蹤的顯著放緩,因為跟蹤過程必須等到分割完成。
本文主要貢獻如下:
提出了一種基于關鍵幀的語義RGB-D SLAM系統,能夠減少動態環境中運動物體的影響。
提出了一個有效和高效的幾何模塊,處理未知的運動物體,并結合語義SLAM框架。
通過與最先進的動態SLAM方法對比實驗,證明所提出的方法的準確性,同時能夠在嵌入式系統上實時運行。
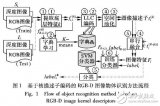
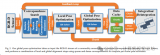
2 算法框架
整個算法的框架如下圖所示:
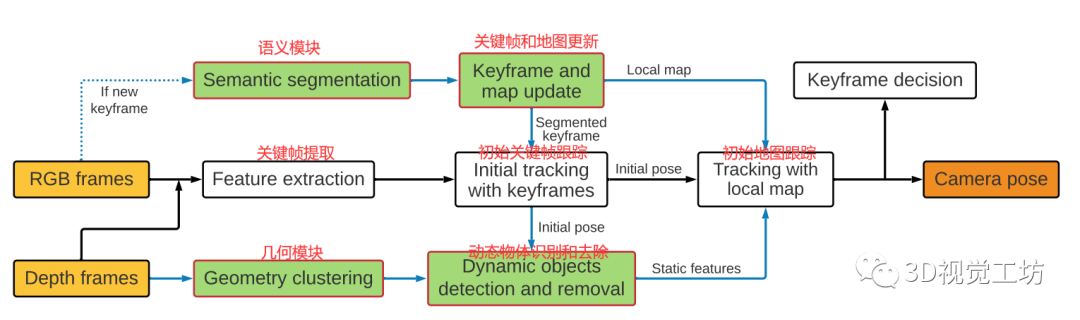
2.1 語義模塊
語義分割是預測像素標簽,并使用基于深度學習的方法為輸入RGB圖像中檢測到的對象生成掩碼,語義模塊采用了輕量級的語義分割網絡SegNet。
然后將分割網絡在PASCAL VOC數據集上進行預訓練,該數據集包含20類對象。在這些對象中,只處理那些高度移動或潛在動態的對象,如人、汽車、自行車等。這些目標將從分割圖像中移除,與它們相關的特征點將不會用于相機跟蹤和地圖構建。
與大多數現有的基于學習的動態SLAM方法不同,該模型只在創建新的關鍵幀時執行語義分割,而不是對每個新幀執行語義分割。這大大降低了語義模塊的計算成本,幫助實現語義信息的實時跟蹤。此外,該進程在單獨的線程中執行,因此對總體跟蹤時間沒有太大影響。
2.2 幾何模塊
由于單獨的語義信息只能檢測到訓練集中被標記的固定數量的對象類,因此在存在未知運動對象的情況下,跟蹤和映射仍然會受到影響,因此需要一個不需要先驗信息的幾何模塊
首先使用K-Means算法將每個新的深度圖像分割成N個簇,在3D空間中彼此接近的點被分組在一起。假設每個聚類都是一個物體的表面,并且聚類中的點共享相同的運動約束。因為單個對象可以被分割成幾個簇,所以對象不需要是剛性的,而大多數語義SLAM方法都有這種剛性假設。
對于每個聚類,計算聚類內所有特征點相對于它們在三維空間中的匹配對應Pi的平均重投影誤差,如(1)所定義,其中m為中匹配的特征數,為相機姿態,π表示相機投影模型,ρ為罰函數。
當一個集群的誤差相對大于其他集群時,就將其標記為動態集群。動態聚類中的所有特征點將被移除,不再參與相機姿態估計。與識別單個特征點的動態狀態相比,該聚類方法更加有效和高效。此外,它還可以防止由單點測量噪聲引起的誤檢。它還允許我們通過幾何聚類近似運動物體的大致形狀。改方法的一些結果可以在下圖的第三行中看到,其中動態集群用紅色突出顯示。該模塊可以獨立工作,不需要語義信息,因此可以檢測未知的運動物體。
第一行顯示了提議的語義模塊(藍色矩形點)和幾何模塊(紅色點)檢測到的動態特征。第二行是相應的語義分割結果。第三行顯示深度圖像的幾何聚類結果,動態聚類以紅色突出顯示。(a)和(b)顯示兩個模塊都檢測到動態目標。(c)-(h)表示語義分割失敗,而幾何模塊分割成功(幾何模塊可以在語義模塊失效的情況下繼續工作)。
作者在實驗過程中發現了一個有趣的現象,一些半動態的物體也可以被識別出來。如上圖(h)所示,其中左椅子被確定為動態的。原因是椅子目前是靜態的,但當重新訪問它時,它的位置發生了變化。這對于長期一致的地圖構建是有幫助的。
2.3 關鍵幀和本地地圖更新
只從關鍵幀中提取語義信息。因為新幀是用關鍵幀和局部地圖跟蹤的,我們只需要確保分割的關鍵幀和局部地圖只包含場景的靜態部分。關鍵幀選擇策略繼承自原ORB-SLAM2系統。當在跟蹤過程中選擇新的關鍵幀時,在單獨的線程中執行語義分割并刪除動態特征點。本地地圖也通過刪除相應的動態地圖點來更新。
通過這種方式,維護了一個關鍵幀數據庫和一個只包含靜態特征和地圖點的地圖。
2.4 跟蹤
繼承于ORB-SLAM2對于每一個新幀都執行一個兩階段的跟蹤。首先使用與當前幀重疊最大的最近關鍵幀進行初始跟蹤,以獲得初始姿態估計。由于關鍵幀已經經過了改進,刪除了潛在的動態對象,因此這個初始估計將更加可靠。
然后在幾何模塊中使用初始姿態估計進行動態物體檢測。幾何模塊去除當前幀中的動態點后,利用當前幀中觀察到的所有局部地圖點進行跟蹤,利用局部束調整獲得更精確的姿態估計。由于語義模塊還在局部地圖中刪除了潛在的動態地圖點,進一步降低了動態目標的影響,從而使姿態估計更加魯棒和準確。
3 實驗與結果
本文方法在廣泛用于RGB-D SLAM評價的TUM RGB-D數據集上進行了測試。
評估指標:用于評估的誤差指標是m的絕對軌跡誤差(ATE)的常用均方根誤差(RMSE),以及包含m=s的平移漂移和?=s的旋轉漂移的相對姿態誤差(RPE)的RMSE。ATE測量軌跡的全局一致性,RPE測量每秒的里程漂移
3.1 不同模塊的作用
ATE與基線ORB-SLAM2的RMSE比較如下表所示。
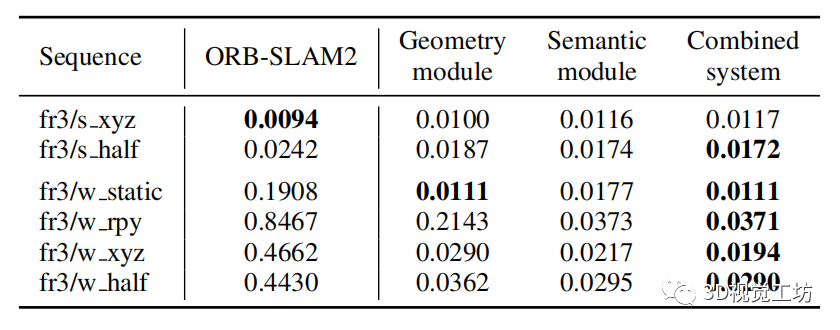
實驗結果:
對于稍微動態的序列,提出的方法的結果與ORB-SLAM2相似,因為ORB-SLAM2可以通過RANSAC算法成功處理這些情況,因此改進幅度有限。
對于高度動態的序列,文中的語義模塊和幾何模塊都取得了顯著的精度提高,并且提出的組合系統取得了更好的結果。
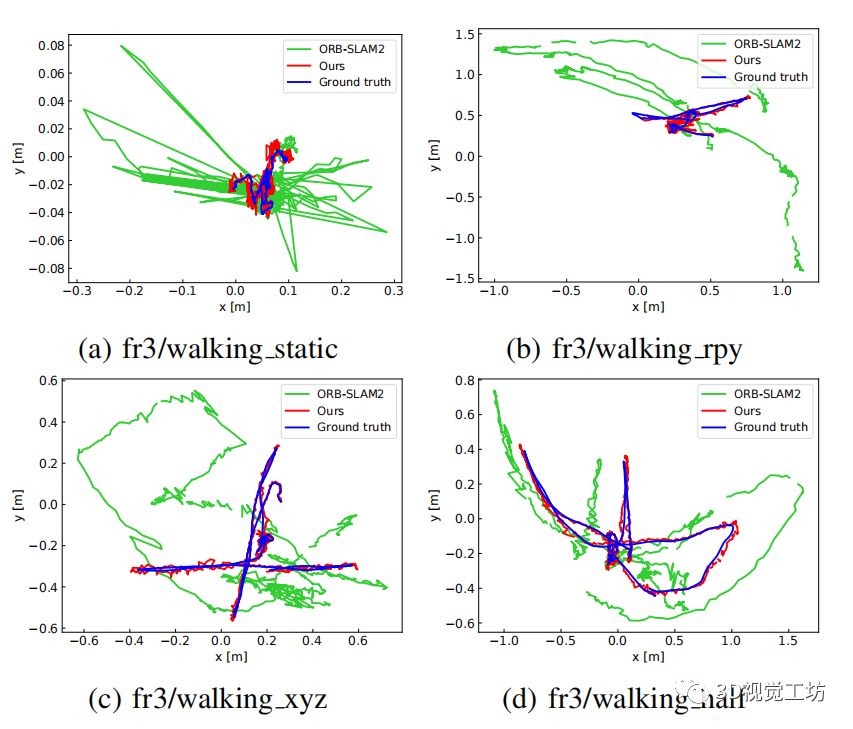
下圖為根據地面真值,ORBSLAM2和所提方法估算的軌跡對比
3.2 與最先進方法的比較
作者將所提出的方法與最先進的基于幾何的動態SLAM方法MR-DVO、SPW、StaticFusion、DSLAM以及基于學習的方法MID-Fusion、EM-Fusion、DS-SLAM和DynaSLAM進行了比較。
ATE和RPE的比較分別總結于表2和表3。
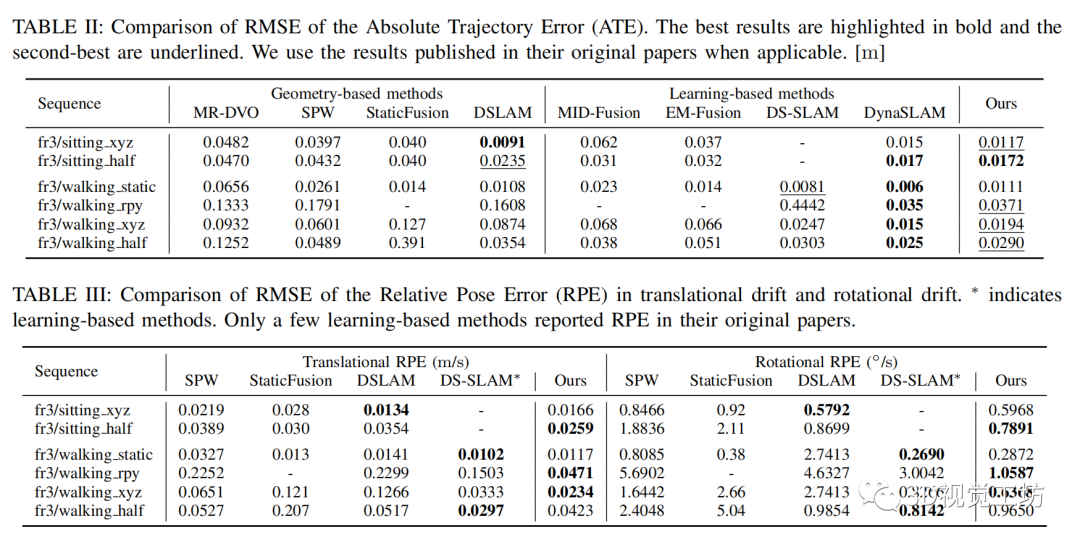
可以看出,文中的方法在所有動態序列中都提供了具有非常好的的結果,并且優于所有其他動態SLAM方法,除了在語義框架中結合多視圖幾何的DynaSLAM。但是,DynaSLAM提供離線靜態地圖創建,由于其耗時的Mask-RCNN網絡和區域增長算法,它無法實時運行。但是本文的方法在實現了實時操作的同時,提供了與之非常接近的結果。
3.3 真實環境下的魯棒性檢驗
在真實的實驗中,一個拿著書的人在相機前坐著走著,而相機幾乎是靜止的。下圖是實時測試過程中動態點檢測結果的幾張截圖,其中第二行和第三行分別是語義模塊和提出的幾何模塊的分割結果。
書在網絡模型中不是一個被標記的對象,因此它不能被識別,或者有時被語義模塊錯誤地識別,如第二行所示。作為一個補償過程,幾何模塊能夠在測試中正確地將書作為移動對象提取出來,如第三行所示。這表明語義模塊和幾何模塊都是動態環境下健壯的語義RGBD SLAM系統所必需的。該方法的平均彈道估計誤差約為0:012m,而ORB-SLAM2由于運動物體引起的較大波動,誤差約為0:147m。
4 總結
本文提出了一個實時語義RGB-D SLAM框架,該框架能夠處理已知和未知的運動物體。
為了減少計算量,提出了一種基于關鍵幀的語義模塊,并引入了一種基于幾何聚類的有效幾何模塊來處理未知運動目標。廣泛的評估表明,文中的系統提供了最先進的定位精度,同時仍然能夠在嵌入式平臺上實時運行。
未來改進:可以構建一個只包含靜態部分的環境的長期語義地圖,這對高級機器人任務很有用。
審核編輯:湯梓紅
-
嵌入式系統
+關注
關注
41文章
3625瀏覽量
129756 -
算法
+關注
關注
23文章
4630瀏覽量
93356 -
網絡模型
+關注
關注
0文章
44瀏覽量
8492 -
VSLAM
+關注
關注
0文章
23瀏覽量
4346
原文標題:動態環境下竟然能在嵌入式系統上實現實時語義RGB-D SLAM??
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何去開發一款基于RGB-D相機與機械臂的三維重建無序抓取系統
基于RGB-D圖像物體識別方法
RGPNET:復雜環境下實時通用語義分割網絡
基于UWB、里程計和RGB-D融合的室內定位方法
一種可在動態環境下構建語義地圖的算法
用于快速高保真RGB-D表面重建的神經特征網格優化的GO-Surf
基于RGB-D相機的三維重建和傳統SFM和SLAM算法有什么區別?
一種基于RGB-D圖像序列的協同隱式神經同步定位與建圖(SLAM)系統
常用的RGB-D SLAM解決方案
利用VLM和MLLMs實現SLAM語義增強






 工商網監
工商網監
評論