 終于字節約面,可惜沒把握住
終于字節約面,可惜沒把握住
大家好,我是小林。
分享一篇字節后端開發校招一面經,同學反饋面試官人很 nice,雖然問的很細節,但是會引導問題方向,但是可惜自己沒把握住,深問一點細節的,就不會了。
這一面主要是拷打基礎方向,重點拷打了網絡IO、Linux 操作系統、網絡協議、mysql、算法。
項目相關
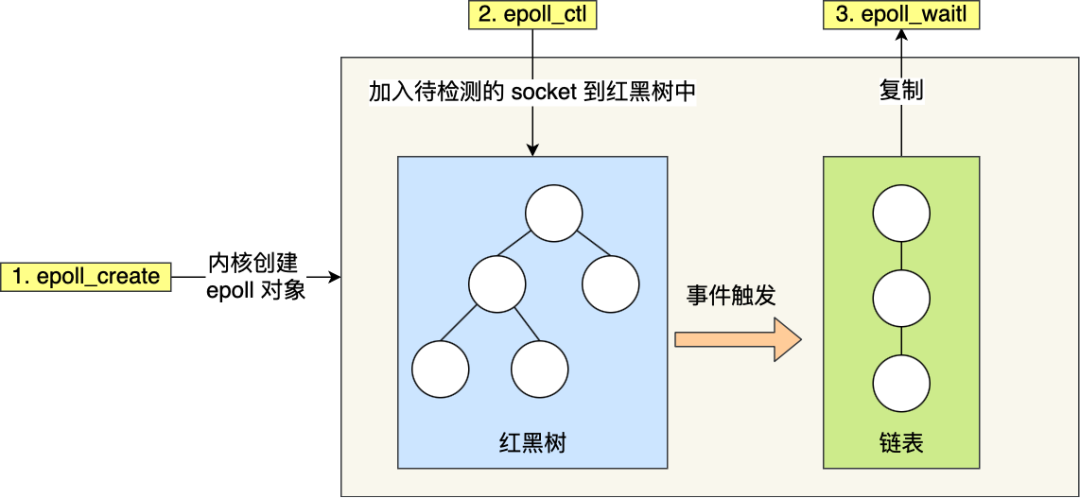
epoll 的工作原理?
先用 epoll_create 創建一個 epoll 對象 epfd,再通過 epoll_ctl 將需要監視的 socket 添加到epfd中,最后調用 epoll_wait 等待數據,當epoll_wait返回后,就可以遍歷它返回的事件列表,然后根據事件類型做出相應的處理。
ints=socket(AF_INET,SOCK_STREAM,0);
bind(s,...);
listen(s,...)
intepfd=epoll_create(...);
epoll_ctl(epfd,...);//將所有需要監聽的socket添加到epfd中
while(1){
intn=epoll_wait(...);
for(接收到數據的socket){
//處理
}
}
epoll、select、poll的區別?
select 實現多路復用的方式是,將已連接的 Socket 都放到一個文件描述符集合,然后調用 select 函數將文件描述符集合拷貝到內核里,讓內核來檢查是否有網絡事件產生,檢查的方式很粗暴,就是通過遍歷文件描述符集合的方式,當檢查到有事件產生后,將此 Socket 標記為可讀或可寫, 接著再把整個文件描述符集合拷貝回用戶態里,然后用戶態還需要再通過遍歷的方法找到可讀或可寫的 Socket,然后再對其處理。
所以,對于 select 這種方式,需要進行 2 次「遍歷」文件描述符集合,一次是在內核態里,一個次是在用戶態里 ,而且還會發生 2 次「拷貝」文件描述符集合,先從用戶空間傳入內核空間,由內核修改后,再傳出到用戶空間中。
select 使用固定長度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的個數是有限制的,在 Linux 系統中,由內核中的 FD_SETSIZE 限制, 默認最大值為 1024,只能監聽 0~1023 的文件描述符。
poll 不再用 BitsMap 來存儲所關注的文件描述符,取而代之用動態數組,以鏈表形式來組織,突破了 select 的文件描述符個數限制,當然還會受到系統文件描述符限制。
但是 poll 和 select 并沒有太大的本質區別,都是使用「線性結構」存儲進程關注的 Socket 集合,因此都需要遍歷文件描述符集合來找到可讀或可寫的 Socket,時間復雜度為 O(n),而且也需要在用戶態與內核態之間拷貝文件描述符集合,這種方式隨著并發數上來,性能的損耗會呈指數級增長。
epoll 通過兩個方面,很好解決了 select/poll 的問題。
-
第一點,epoll 在內核里使用紅黑樹來跟蹤進程所有待檢測的文件描述字,把需要監控的 socket 通過
epoll_ctl()函數加入內核中的紅黑樹里,紅黑樹是個高效的數據結構,增刪改一般時間復雜度是O(logn)。而 select/poll 內核里沒有類似 epoll 紅黑樹這種保存所有待檢測的 socket 的數據結構,所以 select/poll 每次操作時都傳入整個 socket 集合給內核,而 epoll 因為在內核維護了紅黑樹,可以保存所有待檢測的 socket ,所以只需要傳入一個待檢測的 socket,減少了內核和用戶空間大量的數據拷貝和內存分配。 -
第二點, epoll 使用事件驅動的機制,內核里維護了一個鏈表來記錄就緒事件,當某個 socket 有事件發生時,通過回調函數內核會將其加入到這個就緒事件列表中,當用戶調用
epoll_wait()函數時,只會返回有事件發生的文件描述符的個數,不需要像 select/poll 那樣輪詢掃描整個 socket 集合,大大提高了檢測的效率。
可以看到 epoll 相關的接口作用:
 img
imgepoll 的方式即使監聽的 Socket 數量越多的時候,效率不會大幅度降低,能夠同時監聽的 Socket 的數目也非常的多了,上限就為系統定義的進程打開的最大文件描述符個數。因而,epoll 被稱為解決 C10K 問題的利器。
select線性表要從用戶態復制到內核態,具體怎么復制的?
用戶態準備一個文件描述符集合,通常是使用fd_set數據結構來表示,該集合包含要監視的文件描述符。調用select系統調用時,將該文件描述符集合作為參數傳遞給select函數。
內核態的select函數接收到用戶態傳遞的文件描述符集合后,會在內核中創建一個與用戶態相對應的數據結構 fdset,然后將用戶空間的ufdset拷貝到內核空間fdset。
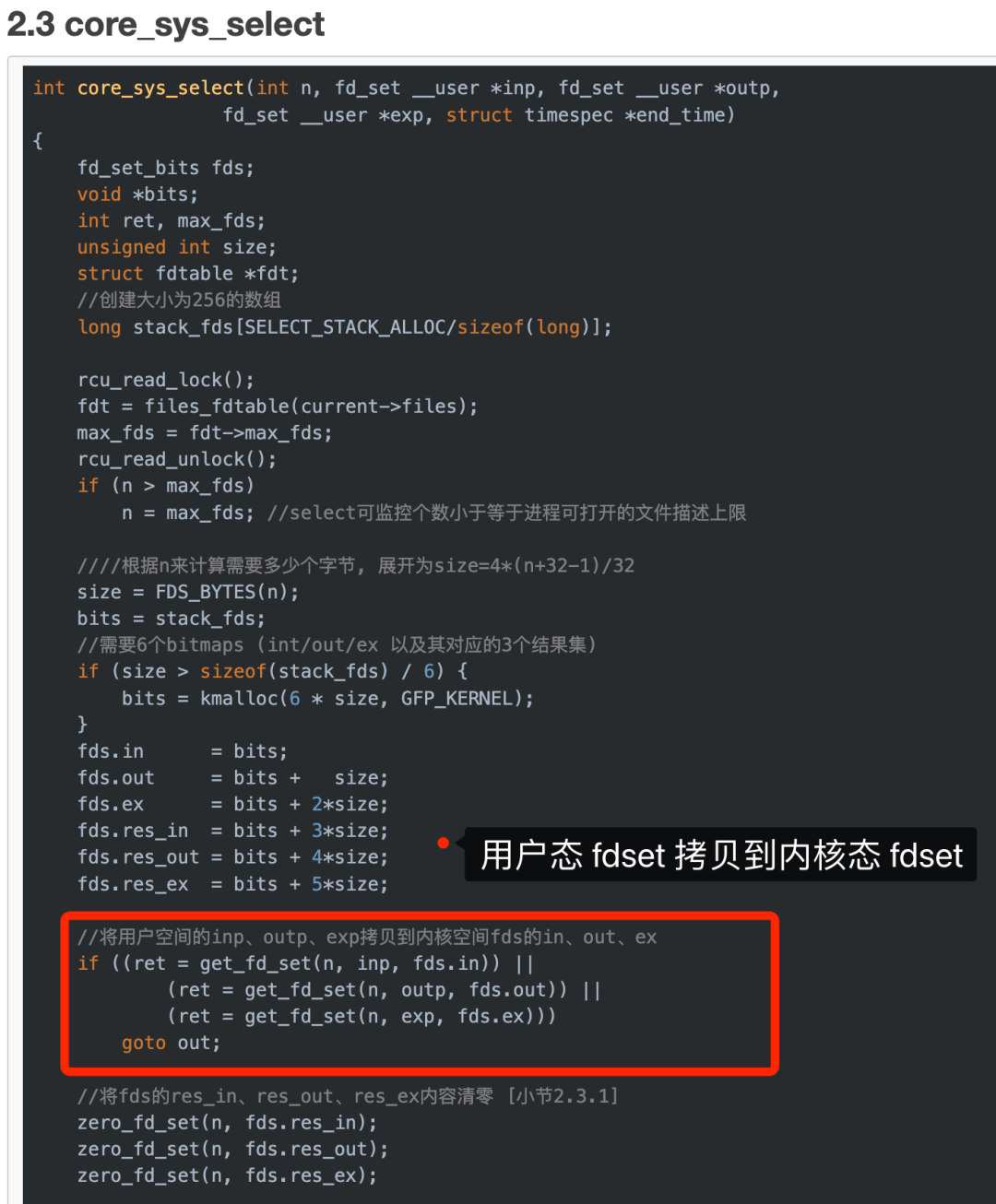 image-20230829160943074
image-20230829160943074操作系統
進程、線程、協程的概念
-
進程(Process):進程是操作系統中的一個執行實例,它擁有獨立的內存空間和資源。每個進程都是獨立運行的,擁有自己的地址空間、文件句柄、環境變量等。進程間通信需要通過特定的機制,如管道、消息隊列、共享內存等。
-
線程(Thread):線程是進程的一部分,是在同一進程內并發執行的執行單元。不同線程共享同一進程的內存空間和資源,包括全局變量、堆、文件描述符等。線程可以更輕量級地創建、切換和銷毀,相對于進程而言,線程間的切換開銷較小。線程之間可以通過共享內存等機制進行通信。
-
協程(Coroutine):協程是一種用戶級的輕量級線程。協程由用戶控制,而不是由操作系統內核控制。在協程中,執行流可以在不同協程之間進行切換,切換由程序員手動控制,而不需要內核介入。協程可以在一個線程內實現并發,但無法利用多核心處理器。協程通常用于實現高效的異步編程和協作任務。
系統創建進程的時候,會給進程分配哪些資源?
會分配虛擬內存空間、文件描述符、信號資源。
線程的資源怎么回收?
linux 線程退出有多種方式,如return,pthread_exit,pthread_cancel等;線程分為可結合的(joinable)和 分離的(detached)兩種。
- 如果沒有在創建線程時設置線程的屬性為PTHREAD_CREATE_DETACHED,則線程默認是可結合的。可結合的線程在線程退出后不會立即釋放資源,必須要調用pthread_join來顯式的結束線程。
- 分離的線程在線程退出時系統會自動回收資源。
怎么看進程當中有哪些線程?
使用ps命令:通過在終端中運行ps -eLf命令,可以列出所有進程及其對應的線程信息。每個線程都會顯示線程ID(TID)、進程ID(PID)、線程優先級(PRI)、CPU占用率(%CPU)、內存占用(%MEM)等信息。
 image-20230829163916659
image-20230829163916659怎么查看網絡的狀態?
可以通過 netstat 命令。
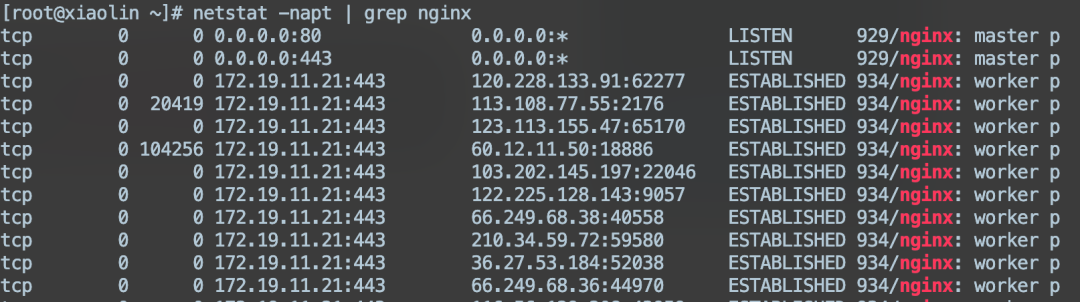 image-20230829164022018
image-20230829164022018如果只想看close_wait狀態的連接,怎么看?
netstat-napt|grepclose_wait
計網
HTTP協議狀態碼 500 501 502 503 504分別代表什么?可以舉出具體場景嘛?
狀態碼500:
-
服務器內部錯誤(Internal Server Error):表示服務器在處理請求時遇到了意外的錯誤,無法完成請求。
-
場景:當服務器上的應用程序發生未處理的異常或錯誤時,可能會返回500狀態碼。例如,如果網站的后端代碼出現了錯誤,導致無法正確處理請求,服務器可能會返回500狀態碼。
狀態碼501:
-
未實現(Not Implemented):表示服務器不支持客戶端請求的功能或方法。
-
場景:當客戶端發送了一個服務器不支持的請求方法或功能時,服務器可以返回501狀態碼。例如,如果客戶端發送了一個不被服務器支持的HTTP方法,如PROPFIND,服務器可能會返回501狀態碼。
狀態碼502:
-
錯誤網關(Bad Gateway):表示服務器作為網關或代理,從上游服務器接收到的響應無效。
-
場景:當服務器作為網關或代理時,如果服務器從上游服務器接收到的響應無效,可能會返回502狀態碼。例如,當反向代理服務器無法訪問后端服務器或后端服務器返回了無效的響應時,可能會返回502狀態碼。
狀態碼503 :
-
服務不可用(Service Unavailable):表示服務器暫時無法處理請求,通常是由于服務器過載或維護。
-
場景:當服務器暫時無法處理請求時,可能會返回503狀態碼。例如,當網站正在進行維護或升級時,服務器可以返回503狀態碼來告知客戶端服務不可用。
狀態碼504 :
-
網關超時(Gateway Timeout):表示服務器作為網關或代理,在等待上游服務器的響應時超時。
-
場景:當服務器作為網關或代理時,在等待上游服務器的響應時超時,可能會返回504狀態碼。例如,如果反向代理服務器在規定的超時時間內無法從后端服務器獲取響應,可能會返回504狀態碼。
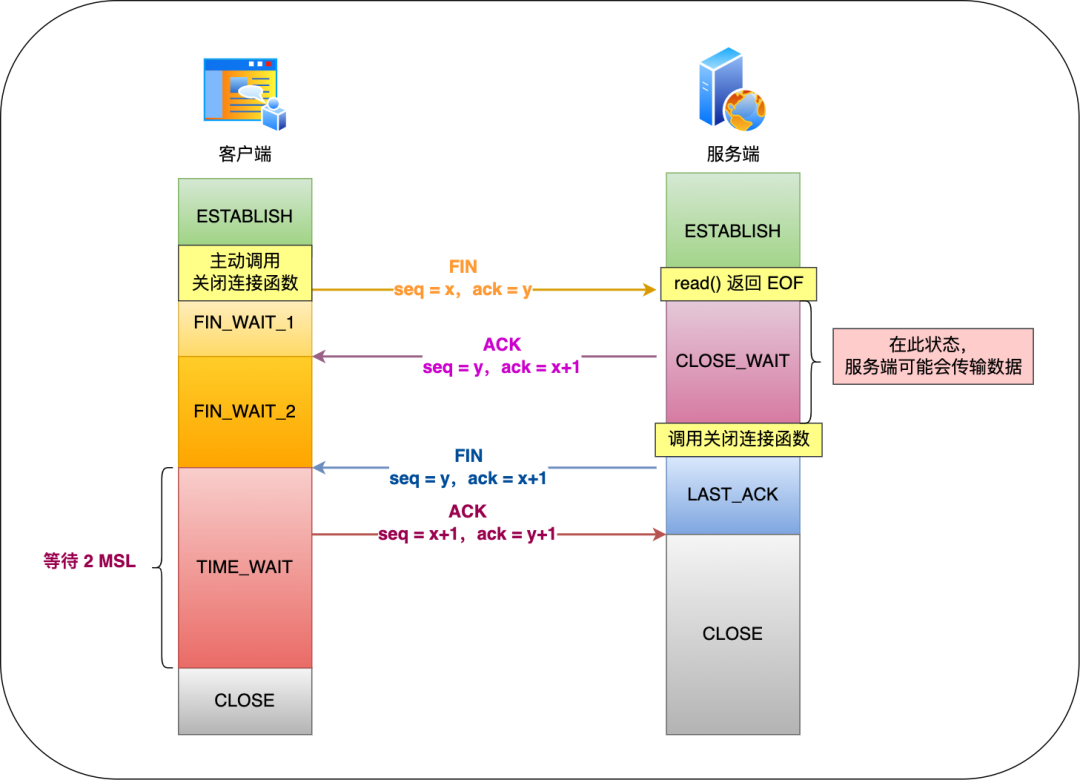
說一說四次揮手的整個過程?
TCP 四次揮手的過程如下:
 在這里插入圖片描述
在這里插入圖片描述具體過程:
- 客戶端主動調用關閉連接的函數,于是就會發送 FIN 報文,這個 FIN 報文代表客戶端不會再發送數據了,進入 FIN_WAIT_1 狀態;
- 服務端收到了 FIN 報文,然后馬上回復一個 ACK 確認報文,此時服務端進入 CLOSE_WAIT 狀態。在收到 FIN 報文的時候,TCP 協議棧會為 FIN 包插入一個文件結束符 EOF 到接收緩沖區中,服務端應用程序可以通過 read 調用來感知這個 FIN 包,這個 EOF 會被放在已排隊等候的其他已接收的數據之后,所以必須要得繼續 read 接收緩沖區已接收的數據;
- 接著,當服務端在 read 數據的時候,最后自然就會讀到 EOF,接著 read() 就會返回 0,這時服務端應用程序如果有數據要發送的話,就發完數據后才調用關閉連接的函數,如果服務端應用程序沒有數據要發送的話,可以直接調用關閉連接的函數,這時服務端就會發一個 FIN 包,這個 FIN 報文代表服務端不會再發送數據了,之后處于 LAST_ACK 狀態;
- 客戶端接收到服務端的 FIN 包,并發送 ACK 確認包給服務端,此時客戶端將進入 TIME_WAIT 狀態;
- 服務端收到 ACK 確認包后,就進入了最后的 CLOSE 狀態;
- 客戶端經過 2MSL 時間之后,也進入 CLOSE 狀態;
你可以看到,每個方向都需要一個 FIN 和一個 ACK,因此通常被稱為四次揮手。
Time_wait 為什么2MSL ?
主要是兩個原因:
- 防止歷史連接中的數據,被后面相同四元組的連接錯誤的接收;
- 保證「被動關閉連接」的一方,能被正確的關閉;
原因一:防止歷史連接中的數據,被后面相同四元組的連接錯誤的接收
假設 TIME-WAIT 沒有等待時間或時間過短,被延遲的數據包抵達后會發生什么呢?
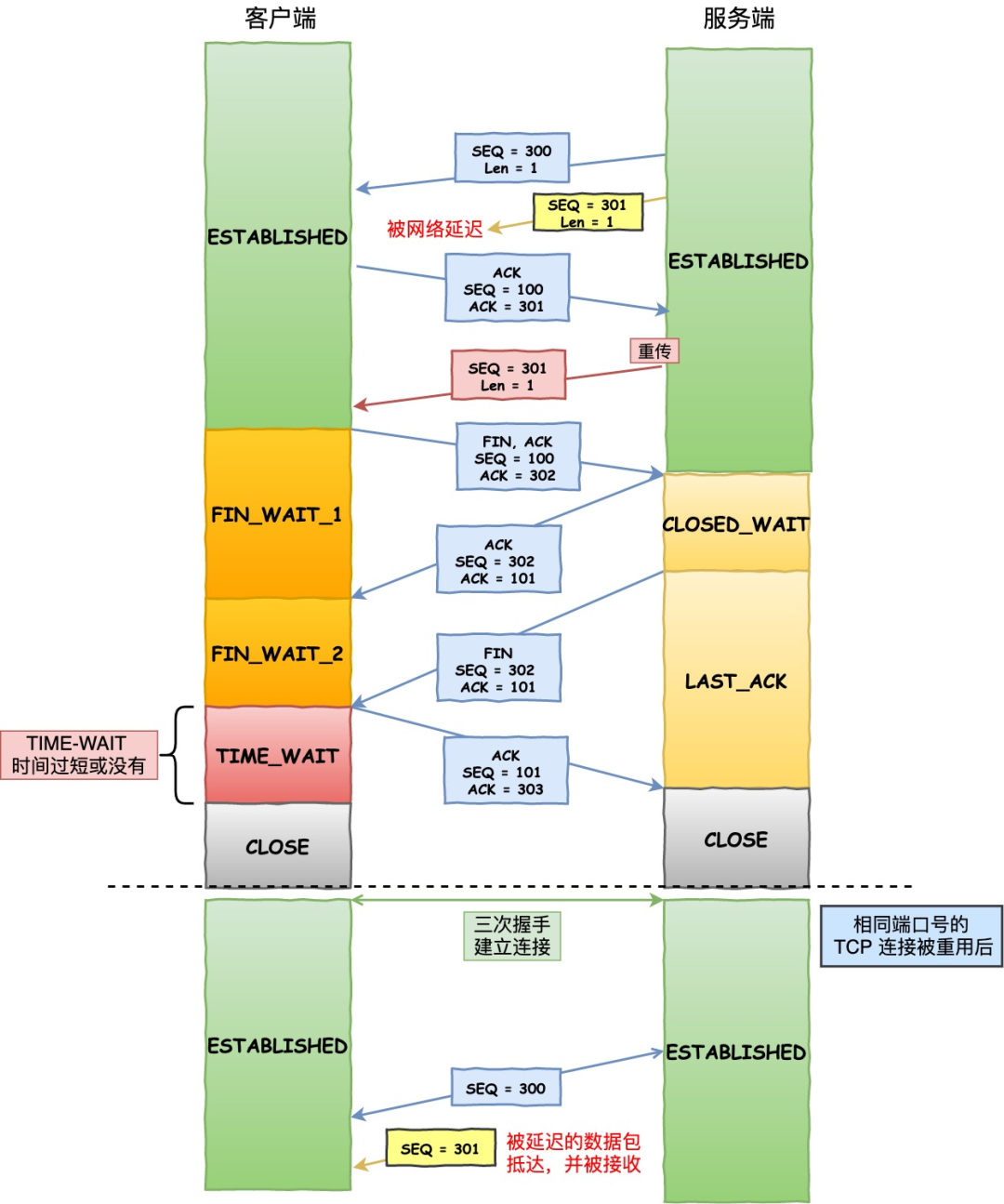 TIME-WAIT 時間過短,收到舊連接的數據報文
TIME-WAIT 時間過短,收到舊連接的數據報文如上圖:
-
服務端在關閉連接之前發送的
SEQ = 301報文,被網絡延遲了。 -
接著,服務端以相同的四元組重新打開了新連接,前面被延遲的
SEQ = 301這時抵達了客戶端,而且該數據報文的序列號剛好在客戶端接收窗口內,因此客戶端會正常接收這個數據報文,但是這個數據報文是上一個連接殘留下來的,這樣就產生數據錯亂等嚴重的問題。
為了防止歷史連接中的數據,被后面相同四元組的連接錯誤的接收,因此 TCP 設計了 TIME_WAIT 狀態,狀態會持續 2MSL 時長,這個時間足以讓兩個方向上的數據包都被丟棄,使得原來連接的數據包在網絡中都自然消失,再出現的數據包一定都是新建立連接所產生的。
原因二:保證「被動關閉連接」的一方,能被正確的關閉
在 RFC 793 指出 TIME-WAIT 另一個重要的作用是:
TIME-WAIT - represents waiting for enough time to pass to be sure the remote TCP received the acknowledgment of its connection termination request.
也就是說,TIME-WAIT 作用是等待足夠的時間以確保最后的 ACK 能讓被動關閉方接收,從而幫助其正常關閉。
如果客戶端(主動關閉方)最后一次 ACK 報文(第四次揮手)在網絡中丟失了,那么按照 TCP 可靠性原則,服務端(被動關閉方)會重發 FIN 報文。
假設客戶端沒有 TIME_WAIT 狀態,而是在發完最后一次回 ACK 報文就直接進入 CLOSE 狀態,如果該 ACK 報文丟失了,服務端則重傳的 FIN 報文,而這時客戶端已經進入到關閉狀態了,在收到服務端重傳的 FIN 報文后,就會回 RST 報文。
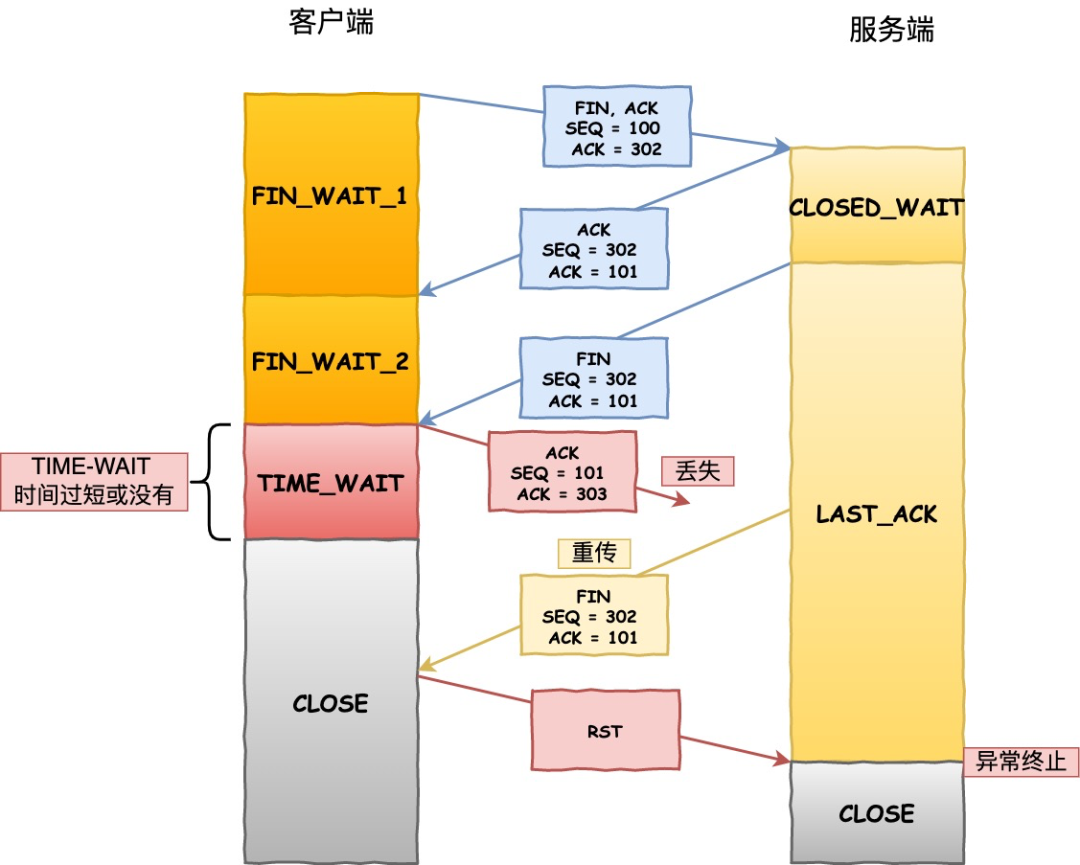 TIME-WAIT 時間過短,沒有確保連接正常關閉
TIME-WAIT 時間過短,沒有確保連接正常關閉服務端收到這個 RST 并將其解釋為一個錯誤(Connection reset by peer),這對于一個可靠的協議來說不是一個優雅的終止方式。
為了防止這種情況出現,客戶端必須等待足夠長的時間,確保服務端能夠收到 ACK,如果服務端沒有收到 ACK,那么就會觸發 TCP 重傳機制,服務端會重新發送一個 FIN,這樣一去一來剛好兩個 MSL 的時間。
 TIME-WAIT 時間正常,確保了連接正常關閉
TIME-WAIT 時間正常,確保了連接正常關閉客戶端在收到服務端重傳的 FIN 報文時,TIME_WAIT 狀態的等待時間,會重置回 2MSL。
當存在大量close_wait的連接時怎么處理?
CLOSE_WAIT 狀態是「被動關閉方」才會有的狀態,而且如果「被動關閉方」沒有調用 close 函數關閉連接,那么就無法發出 FIN 報文,從而無法使得 CLOSE_WAIT 狀態的連接轉變為 LAST_ACK 狀態。
所以,當服務端出現大量 CLOSE_WAIT 狀態的連接的時候,說明服務端的程序沒有調用 close 函數關閉連接。
那什么情況會導致服務端的程序沒有調用 close 函數關閉連接?這時候通常需要排查代碼。
我們先來分析一個普通的 TCP 服務端的流程:
- 創建服務端 socket,bind 綁定端口、listen 監聽端口
- 將服務端 socket 注冊到 epoll
- epoll_wait 等待連接到來,連接到來時,調用 accpet 獲取已連接的 socket
- 將已連接的 socket 注冊到 epoll
- epoll_wait 等待事件發生
- 對方連接關閉時,我方調用 close
可能導致服務端沒有調用 close 函數的原因,如下。
第一個原因:第 2 步沒有做,沒有將服務端 socket 注冊到 epoll,這樣有新連接到來時,服務端沒辦法感知這個事件,也就無法獲取到已連接的 socket,那服務端自然就沒機會對 socket 調用 close 函數了。
不過這種原因發生的概率比較小,這種屬于明顯的代碼邏輯 bug,在前期 read view 階段就能發現的了。
第二個原因:第 3 步沒有做,有新連接到來時沒有調用 accpet 獲取該連接的 socket,導致當有大量的客戶端主動斷開了連接,而服務端沒機會對這些 socket 調用 close 函數,從而導致服務端出現大量 CLOSE_WAIT 狀態的連接。
發生這種情況可能是因為服務端在執行 accpet 函數之前,代碼卡在某一個邏輯或者提前拋出了異常。
第三個原因:第 4 步沒有做,通過 accpet 獲取已連接的 socket 后,沒有將其注冊到 epoll,導致后續收到 FIN 報文的時候,服務端沒辦法感知這個事件,那服務端就沒機會調用 close 函數了。
第四個原因:第 6 步沒有做,當發現客戶端關閉連接后,服務端沒有執行 close 函數,可能是因為代碼漏處理,或者是在執行 close 函數之前,代碼卡在某一個邏輯,比如發生死鎖等等。
可以發現,當服務端出現大量 CLOSE_WAIT 狀態的連接的時候,通常都是代碼的問題,這時候我們需要針對具體的代碼一步一步的進行排查和定位,主要分析的方向就是服務端為什么沒有調用 close。
mysql
什么是聚簇索引和非聚簇索引?
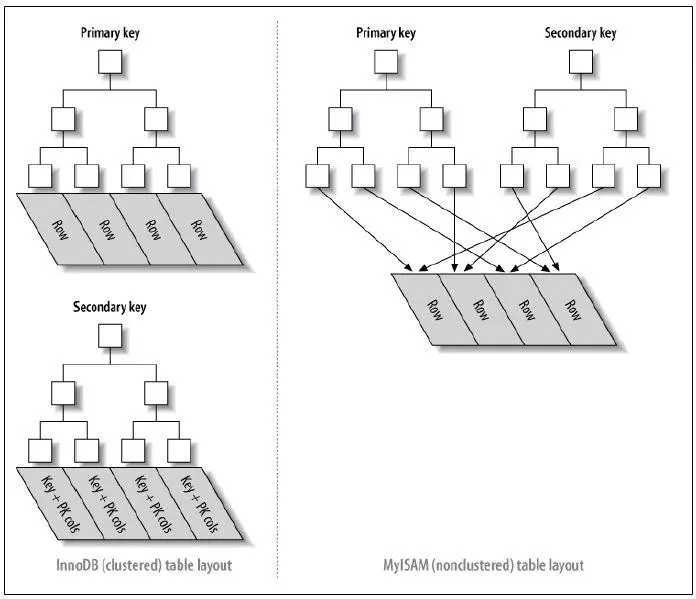
- 對于聚簇索引表來說(左圖),表數據是和主鍵一起存儲的,主鍵索引的葉結點存儲行數據(包含了主鍵值),二級索引的葉結點存儲行的主鍵值。使用的是B+樹作為索引的存儲結構,非葉子節點都是索引關鍵字,但非葉子節點中的關鍵字中不存儲對應記錄的具體內容或內容地址。葉子節點上的數據是主鍵與具體記錄(數據內容)。
- 對于非聚簇索引表來說(右圖),表數據和索引是分成兩部分存儲的,主鍵索引和二級索引存儲上沒有任何區別。使用的是B+樹作為索引的存儲結構,所有的節點都是索引,葉子節點存儲的是索引+索引對應的記錄的數據。
InooDB 為什么要使用聚簇索引?
使用聚簇索引的一些好處:
-
數據行的物理存儲順序:使用聚集索引可以將數據行按照索引鍵的順序存儲在磁盤上,這樣相鄰的數據行在物理上也是相鄰的。這種物理存儲順序可以提高基于范圍查詢的性能,因為相關的數據行在物理上是連續的,減少了磁盤I/O的次數。
-
覆蓋索引查詢:由于聚集索引包含了實際的數據行,當查詢只需要使用聚集索引的鍵列時,可以避免訪問數據行,提高查詢性能。這種情況下也稱為覆蓋索引查詢。
什么是 InooDB里面的聯合索引?
通過將多個字段組合成一個索引,該索引就被稱為聯合索引。
比如,將商品表中的 product_no 和 name 字段組合成聯合索引(product_no, name),創建聯合索引的方式如下:
CREATEINDEXindex_product_no_nameONproduct(product_no,name);
聯合索引(product_no, name) 的 B+Tree 示意圖如下(圖中葉子節點之間我畫了單向鏈表,但是實際上是雙向鏈表,原圖我找不到了,修改不了,偷個懶我不重畫了,大家腦補成雙向鏈表就行)。
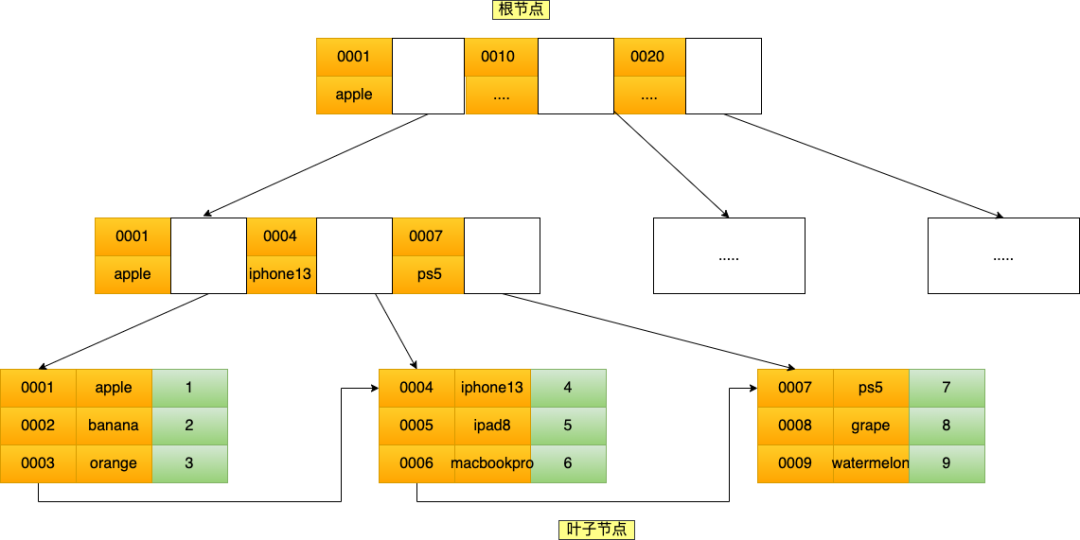 聯合索引
聯合索引可以看到,聯合索引的非葉子節點用兩個字段的值作為 B+Tree 的 key 值。當在聯合索引查詢數據時,先按 product_no 字段比較,在 product_no 相同的情況下再按 name 字段比較。
也就是說,聯合索引查詢的 B+Tree 是先按 product_no 進行排序,然后再 product_no 相同的情況再按 name 字段排序。
因此,使用聯合索引時,存在最左匹配原則,也就是按照最左優先的方式進行索引的匹配。在使用聯合索引進行查詢的時候,如果不遵循「最左匹配原則」,聯合索引會失效,這樣就無法利用到索引快速查詢的特性了。
比如,如果創建了一個 (a, b, c) 聯合索引,如果查詢條件是以下這幾種,就可以匹配上聯合索引:
- where a=1;
- where a=1 and b=2 and c=3;
- where a=1 and b=2;
需要注意的是,因為有查詢優化器,所以 a 字段在 where 子句的順序并不重要。
但是,如果查詢條件是以下這幾種,因為不符合最左匹配原則,所以就無法匹配上聯合索引,聯合索引就會失效:
- where b=2;
- where c=3;
- where b=2 and c=3;
上面這些查詢條件之所以會失效,是因為(a, b, c) 聯合索引,是先按 a 排序,在 a 相同的情況再按 b 排序,在 b 相同的情況再按 c 排序。所以,b 和 c 是全局無序,局部相對有序的,這樣在沒有遵循最左匹配原則的情況下,是無法利用到索引的。
我這里舉聯合索引(a,b)的例子,該聯合索引的 B+ Tree 如下(圖中葉子節點之間我畫了單向鏈表,但是實際上是雙向鏈表,原圖我找不到了,修改不了,偷個懶我不重畫了,大家腦補成雙向鏈表就行)。
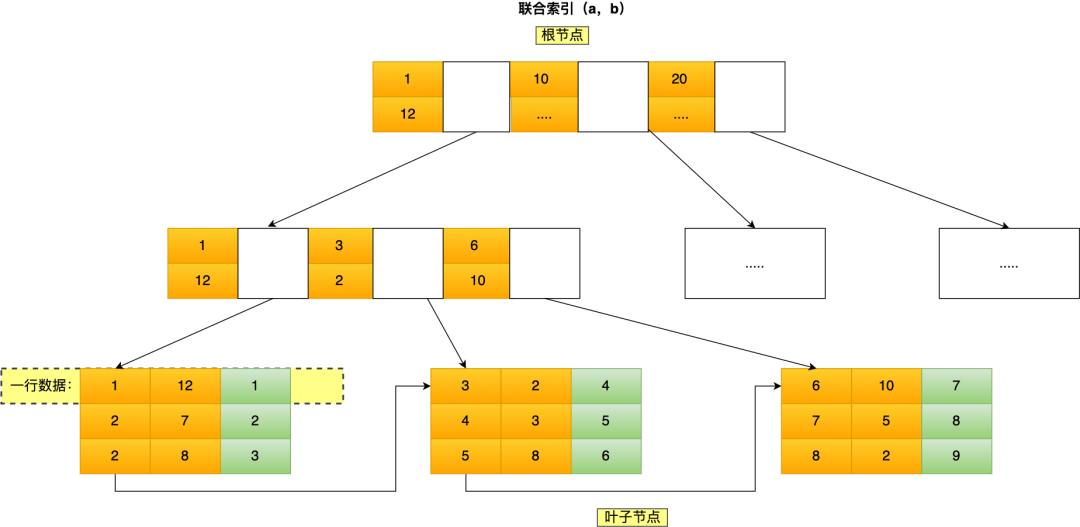 img
img
可以看到,a 是全局有序的(1, 2, 2, 3, 4, 5, 6, 7 ,8),而 b 是全局是無序的(12,7,8,2,3,8,10,5,2)。因此,直接執行where b = 2這種查詢條件沒有辦法利用聯合索引的,利用索引的前提是索引里的 key 是有序的。
只有在 a 相同的情況才,b 才是有序的,比如 a 等于 2 的時候,b 的值為(7,8),這時就是有序的,這個有序狀態是局部的,因此,執行where a = 2 and b = 7是 a 和 b 字段能用到聯合索引的,也就是聯合索引生效了。
給出一個表A 有a1~a5 個列,聯合索引(a2,a1)select a5 from A where a2=1 and a1=2 請問用到聯合索引了嘛?它的具體過程呢?
查詢符合最左匹配原則,可以a1 和 a2 都可以使用聯合索引。
具體的查詢過程,在二級索引 b+樹找到符合條件 a2 和 a1 的記錄,然后獲取這些記錄的 id 值,拿 id 值去主鍵索引查詢 a5 列的值,這里涉及了回表的查詢。
算法
滑動窗口 歷史好文: 我們又出成績了!! 還是銀行面試舒服些... 百度提前批,有點難度! 面試不會的問題,可以硬著頭皮亂答嗎.....
-
算法
+關注
關注
23文章
4630瀏覽量
93348 -
操作系統
+關注
關注
37文章
6892瀏覽量
123742 -
網絡協議
+關注
關注
3文章
269瀏覽量
21633
原文標題:終于字節約面,可惜沒把握住....
文章出處:【微信號:小林coding,微信公眾號:小林coding】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論