") 使用Pytorch和OpenCV實現(xiàn)視頻人臉替換
使用Pytorch和OpenCV實現(xiàn)視頻人臉替換
本文將分成3個部分,第一部分從兩個視頻中提取人臉并構(gòu)建標準人臉數(shù)據(jù)集。第二部分使用數(shù)據(jù)集與神經(jīng)網(wǎng)絡一起學習如何在潛在空間中表示人臉,并從該表示中重建人臉圖像。最后部分使用神經(jīng)網(wǎng)絡在視頻的每一幀中創(chuàng)建與源視頻中相同但具有目標視頻中人物表情的人臉。然后將原人臉替換為假人臉,并將新幀保存為新的假視頻。
項目的基本結(jié)構(gòu)(在第一次運行之前)如下所示
├── face_masking.py ├── main.py ├── face_extraction_tools.py ├── quick96.py ├── merge_frame_to_fake_video.py ├── data │ ├── data_dst.mp4 │ ├── data_src.mp4
main.py是主腳本,data文件夾包含程序需要的的data_dst.mp4和data_src.mp4文件。
提取和對齊-構(gòu)建數(shù)據(jù)集
在第一部分中,我們主要介紹face_extraction_tools.py文件中的代碼。
因為第一步是從視頻中提取幀,所以需要構(gòu)建一個將幀保存為JPEG圖像的函數(shù)。這個函數(shù)接受一個視頻的路徑和另一個輸出文件夾的路徑。
def extract_frames_from_video(video_path: Union[str, Path], output_folder: Union[str, Path], frames_to_skip: int=0) -> None: """ Extract frame from video as a JPG images. Args: video_path (str | Path): the path to the input video from it the frame will be extracted output_folder (str | Path): the folder where the frames will be saved frames_to_skip (int): how many frames to skip after a frame which is saved. 0 will save all the frames. If, for example, this value is 2, the first frame will be saved, then frame 2 and 3 will be skipped, the 4th frame will be saved, and so on. Returns: """ video_path = Path(video_path) output_folder = Path(output_folder) if not video_path.exists(): raise ValueError(f'The path to the video file {video_path.absolute()} is not exist') if not output_folder.exists(): output_folder.mkdir(parents=True) video_capture = cv2.VideoCapture(str(video_path)) extract_frame_counter = 0 saved_frame_counter = 0 while True: ret, frame = video_capture.read() if not ret: break if extract_frame_counter % (frames_to_skip + 1) == 0: cv2.imwrite(str(output_folder / f'{saved_frame_counter:05d}.jpg'), frame, [cv2.IMWRITE_JPEG_QUALITY, 90]) saved_frame_counter += 1 extract_frame_counter += 1 print(f'{saved_frame_counter} of {extract_frame_counter} frames saved')
函數(shù)首先檢查視頻文件是否存在,以及輸出文件夾是否存在,如果不存在則自動創(chuàng)建。然后使用OpenCV 的videoccapture類來創(chuàng)建一個對象來讀取視頻,然后逐幀保存為輸出文件夾中的JPEG文件。也可以根據(jù)frames_to_skip參數(shù)跳過幀。
然后就是需要構(gòu)建人臉提取器。該工具應該能夠檢測圖像中的人臉,提取并對齊它。構(gòu)建這樣一個工具的最佳方法是創(chuàng)建一個FaceExtractor類,其中包含檢測、提取和對齊的方法。
對于檢測部分,我們將使用帶有OpenCV的YuNet。YuNet是一個快速準確的基于cnn的人臉檢測器,可以由OpenCV中的FaceDetectorYN類使用。要創(chuàng)建這樣一個FaceDetectorYN對象,我們需要一個帶有權(quán)重的ONNX文件。該文件可以在OpenCV Zoo中找到,當前版本名為“face_detection_yunet_2023mar.onnx”。
我們的init()方法如下:
def __init__(self, image_size):
"""
Create a YuNet face detector to get face from image of size 'image_size'. The YuNet model
will be downloaded from opencv zoo, if it's not already exist.
Args:
image_size (tuple): a tuple of (width: int, height: int) of the image to be analyzed
"""
detection_model_path = Path('models/face_detection_yunet_2023mar.onnx')
if not detection_model_path.exists():
detection_model_path.parent.mkdir(parents=True, exist_ok=True)
url = "https://github.com/opencv/opencv_zoo/blob/main/models/face_detection_yunet/face_detection_yunet_2023mar.onnx"
print('Downloading face detection model...')
filename, headers = urlretrieve(url, filename=str(detection_model_path))
print('Download finish!')
self.detector = cv2.FaceDetectorYN.create(str(detection_model_path), "", image_size)
函數(shù)首先檢查權(quán)重文件是否存在,如果不存在,則從web下載。然后使用權(quán)重文件和要分析的圖像大小創(chuàng)建FaceDetectorYN對象。檢測方法采用YuNet檢測方法在圖像中尋找人臉
def detect(self, image): ret, faces = self.detector.detect(image) return ret, faces
YuNet的輸出是一個大小為[num_faces, 15]的2D數(shù)組,包含以下信息:
0-1:邊界框左上角的x, y
2-3:邊框的寬度、高度
4-5:右眼的x, y(樣圖中藍點)
6-7:左眼x, y(樣圖中紅點)
8-9:鼻尖x, y(示例圖中綠色點)
10-11:嘴巴右角的x, y(樣例圖像中的粉色點)
12-13:嘴角左角x, y(樣例圖中黃色點)
14:面部評分
現(xiàn)在已經(jīng)有了臉部位置數(shù)據(jù),我們可以用它來獲得臉部的對齊圖像。這里主要利用眼睛位置的信息。我們希望眼睛在對齊后的圖像中處于相同的水平(相同的y坐標)。
@staticmethod def align(image, face, desired_face_width=256, left_eye_desired_coordinate=np.array((0.37, 0.37))): """ Align the face so the eyes will be at the same level Args: image (np.ndarray): image with face face (np.ndarray): face coordinates from the detection step desired_face_width (int): the final width of the aligned face image left_eye_desired_coordinate (np.ndarray): a length 2 array of values between 0 and 1 where the left eye should be in the aligned image Returns: (np.ndarray): aligned face image """ desired_face_height = desired_face_width right_eye_desired_coordinate = np.array((1 - left_eye_desired_coordinate[0], left_eye_desired_coordinate[1])) # get coordinate of the center of the eyes in the image right_eye = face[4:6] left_eye = face[6:8] # compute the angle of the right eye relative to the left eye dist_eyes_x = right_eye[0] - left_eye[0] dist_eyes_y = right_eye[1] - left_eye[1] dist_between_eyes = np.sqrt(dist_eyes_x ** 2 + dist_eyes_y ** 2) angles_between_eyes = np.rad2deg(np.arctan2(dist_eyes_y, dist_eyes_x) - np.pi) eyes_center = (left_eye + right_eye) // 2 desired_dist_between_eyes = desired_face_width * ( right_eye_desired_coordinate[0] - left_eye_desired_coordinate[0]) scale = desired_dist_between_eyes / dist_between_eyes M = cv2.getRotationMatrix2D(eyes_center, angles_between_eyes, scale) M[0, 2] += 0.5 * desired_face_width - eyes_center[0] M[1, 2] += left_eye_desired_coordinate[1] * desired_face_height - eyes_center[1] face_aligned = cv2.warpAffine(image, M, (desired_face_width, desired_face_height), flags=cv2.INTER_CUBIC)
這個方法獲取單張人臉的圖像和信息,輸出圖像的寬度和期望的左眼相對位置。我們假設輸出圖像是平方的,并且右眼的期望位置具有相同的y位置和x位置的1 - left_eye_x。計算兩眼之間的距離和角度,以及兩眼之間的中心點。
最后一個方法是extract方法,它類似于align方法,但沒有轉(zhuǎn)換,它也返回圖像中人臉的邊界框。
def extract_and_align_face_from_image(input_dir: Union[str, Path], desired_face_width: int=256) -> None: """ Extract the face from an image, align it and save to a directory inside in the input directory Args: input_dir (str|Path): path to the directory contains the images extracted from a video desired_face_width (int): the width of the aligned imaged in pixels Returns: """ input_dir = Path(input_dir) output_dir = input_dir / 'aligned' if output_dir.exists(): rmtree(output_dir) output_dir.mkdir() image = cv2.imread(str(input_dir / '00000.jpg')) image_height = image.shape[0] image_width = image.shape[1] detector = FaceExtractor((image_width, image_height)) for image_path in tqdm(list(input_dir.glob('*.jpg'))): image = cv2.imread(str(image_path)) ret, faces = detector.detect(image) if faces is None: continue face_aligned = detector.align(image, faces[0, :], desired_face_width) cv2.imwrite(str(output_dir / f'{image_path.name}'), face_aligned, [cv2.IMWRITE_JPEG_QUALITY, 90])訓練
對于網(wǎng)絡,我們將使用AutoEncoder。在AutoEncoder中,有兩個主要組件——編碼器和解碼器。編碼器獲取原始圖像并找到它的潛在表示,解碼器利用潛在表示重構(gòu)原始圖像。
對于我們的任務,要訓練一個編碼器來找到一個潛在的人臉表示和兩個解碼器——一個可以重建源人臉,另一個可以重建目標人臉。
在這三個組件被訓練之后,我們回到最初的目標:創(chuàng)建一個源面部但具有目標表情的圖像。也就是說使用解碼器A和人臉B的圖像。
面孔的潛在空間保留了面部的主要特征,如位置、方向和表情。解碼器獲取這些編碼信息并學習如何構(gòu)建全臉圖像。由于解碼器A只知道如何構(gòu)造A類型的臉,因此它從編碼器中獲取圖像B的特征并從中構(gòu)造A類型的圖像。
在本文中,我們將使用來自原始DeepFaceLab項目的Quick96架構(gòu)的一個小修改版本。
模型的全部細節(jié)可以在quick96.py文件中。
在我們訓練模型之前,還需要處理數(shù)據(jù)。為了使模型具有魯棒性并避免過擬合,我們還需要在原始人臉圖像上應用兩種類型的增強。第一個是一般的轉(zhuǎn)換,包括旋轉(zhuǎn),縮放,在x和y方向上的平移,以及水平翻轉(zhuǎn)。對于每個轉(zhuǎn)換,我們?yōu)閰?shù)或概率定義一個范圍(例如,我們可以用來旋轉(zhuǎn)的角度范圍),然后從范圍中選擇一個隨機值來應用于圖像。
random_transform_args = {
'rotation_range': 10,
'zoom_range': 0.05,
'shift_range': 0.05,
'random_flip': 0.5,
}
def random_transform(image, rotation_range, zoom_range, shift_range, random_flip):
"""
Make a random transformation for an image, including rotation, zoom, shift and flip.
Args:
image (np.array): an image to be transformed
rotation_range (float): the range of possible angles to rotate - [-rotation_range, rotation_range]
zoom_range (float): range of possible scales - [1 - zoom_range, 1 + zoom_range]
shift_range (float): the percent of translation for x and y
random_flip (float): the probability of horizontal flip
Returns:
(np.array): transformed image
"""
h, w = image.shape[0:2]
rotation = np.random.uniform(-rotation_range, rotation_range)
scale = np.random.uniform(1 - zoom_range, 1 + zoom_range)
tx = np.random.uniform(-shift_range, shift_range) * w
ty = np.random.uniform(-shift_range, shift_range) * h
mat = cv2.getRotationMatrix2D((w // 2, h // 2), rotation, scale)
mat[:, 2] += (tx, ty)
result = cv2.warpAffine(image, mat, (w, h), borderMode=cv2.BORDER_REPLICATE)
if np.random.random() < random_flip:
result = result[:, ::-1]
return result
第2個是通過使用帶噪聲的插值圖產(chǎn)生的失真。這種扭曲將迫使模型理解人臉的關(guān)鍵特征,并使其更加一般化。
def random_warp(image): """ Create a distorted face image and a target undistorted image Args: image (np.array): image to warp Returns: (np.array): warped version of the image (np.array): target image to construct from the warped version """ h, w = image.shape[:2] # build coordinate map to wrap the image according to range_ = np.linspace(h / 2 - h * 0.4, h / 2 + h * 0.4, 5) mapx = np.broadcast_to(range_, (5, 5)) mapy = mapx.T # add noise to get a distortion of the face while warp the image mapx = mapx + np.random.normal(size=(5, 5), scale=5*h/256) mapy = mapy + np.random.normal(size=(5, 5), scale=5*h/256) # get interpolation map for the center of the face with size of (96, 96) interp_mapx = cv2.resize(mapx, (int(w / 2 * (1 + 0.25)) , int(h / 2 * (1 + 0.25))))[int(w/2 * 0.25/2):int(w / 2 * (1 + 0.25) - w/2 * 0.25/2), int(w/2 * 0.25/2):int(w / 2 * (1 + 0.25) - w/2 * 0.25/2)].astype('float32') interp_mapy = cv2.resize(mapy, (int(w / 2 * (1 + 0.25)) , int(h / 2 * (1 + 0.25))))[int(w/2 * 0.25/2):int(w / 2 * (1 + 0.25) - w/2 * 0.25/2), int(w/2 * 0.25/2):int(w / 2 * (1 + 0.25) - w/2 * 0.25/2)].astype('float32') # remap the face image according to the interpolation map to get warp version warped_image = cv2.remap(image, interp_mapx, interp_mapy, cv2.INTER_LINEAR) # create the target (undistorted) image # find a transformation to go from the source coordinates to the destination coordinate src_points = np.stack([mapx.ravel(), mapy.ravel()], axis=-1) dst_points = np.mgrid[0:w//2+1:w//8, 0:h//2+1:h//8].T.reshape(-1, 2) # We want to find a similarity matrix (scale rotation and translation) between the # source and destination points. The matrix should have the structure # [[a, -b, c], # [b, a, d]] # so we can construct unknown vector [a, b, c, d] and solve for it using least # squares with the source and destination x and y points. A = np.zeros((2 * src_points.shape[0], 2)) A[0::2, :] = src_points # [x, y] A[0::2, 1] = -A[0::2, 1] # [x, -y] A[1::2, :] = src_points[:, ::-1] # [y, x] A = np.hstack((A, np.tile(np.eye(2), (src_points.shape[0], 1)))) # [x, -y, 1, 0] for x coordinate and [y, x, 0 ,1] for y coordinate b = dst_points.flatten() # arrange as [x0, y0, x1, y1, ..., xN, yN] similarity_mat = np.linalg.lstsq(A, b, rcond=None)[0] # get the similarity matrix elements as vector [a, b, c, d] # construct the similarity matrix from the result vector of the least squares similarity_mat = np.array([[similarity_mat[0], -similarity_mat[1], similarity_mat[2]], [similarity_mat[1], similarity_mat[0], similarity_mat[3]]]) # use the similarity matrix to construct the target image using affine transformation target_image = cv2.warpAffine(image, similarity_mat, (w // 2, h // 2)) return warped_image, target_image
這個函數(shù)有兩個部分,我們首先在面部周圍的區(qū)域創(chuàng)建圖像的坐標圖。有一個x坐標的映射和一個y坐標的映射。mapx和mapy變量中的值是以像素為單位的坐標。然后在圖像上添加一些噪聲,使坐標在隨機方向上移動。我們添加的噪聲,得到了一個扭曲的坐標(像素在隨機方向上移動一點)。然后裁剪了插值后的貼圖,使其包含臉部的中心,大小為96x96像素。現(xiàn)在我們可以使用扭曲的映射來重新映射圖像,得到一個新的扭曲的圖像。
在第二部分創(chuàng)建未扭曲的圖像,這是模型應該從扭曲的圖像中創(chuàng)建的目標圖像。使用噪聲作為源坐標,并為目標圖像定義一組目標坐標。然后我們使用最小二乘法找到一個相似變換矩陣(尺度旋轉(zhuǎn)和平移),將其從源坐標映射到目標坐標,并將其應用于圖像以獲得目標圖像。
然后就可以創(chuàng)建一個Dataset類來處理數(shù)據(jù)了。FaceData類非常簡單。它獲取包含src和dst文件夾的文件夾的路徑,其中包含我們在前一部分中創(chuàng)建的數(shù)據(jù),并返回大小為(2 * 96,2 * 96)歸一化為1的隨機源和目標圖像。我們的網(wǎng)絡將得到的是一個經(jīng)過變換和扭曲的圖像,以及源臉和目標臉的目標圖像。所以還需要實現(xiàn)了一個collate_fn
def collate_fn(self, batch): """ Collate function to arrange the data returns from a batch. The batch returns a list of tuples contains pairs of source and destination images, which is the input of this function, and the function returns a tuple with 4 4D tensors of the warp and target images for the source and destination Args: batch (list): a list of tuples contains pairs of source and destination images as numpy array Returns: (torch.Tensor): a 4D tensor of the wrap version of the source images (torch.Tensor): a 4D tensor of the target source images (torch.Tensor): a 4D tensor of the wrap version of the destination images (torch.Tensor): a 4D tensor of the target destination images """ images_src, images_dst = list(zip(*batch)) # convert list of tuples with pairs of images into tuples of source and destination images warp_image_src, target_image_src = get_training_data(images_src, len(images_src)) warp_image_src = torch.tensor(warp_image_src, dtype=torch.float32).permute(0, 3, 1, 2).to(device) target_image_src = torch.tensor(target_image_src, dtype=torch.float32).permute(0, 3, 1, 2).to(device) warp_image_dst, target_image_dst = get_training_data(images_dst, len(images_dst)) warp_image_dst = torch.tensor(warp_image_dst, dtype=torch.float32).permute(0, 3, 1, 2).to(device) target_image_dst = torch.tensor(target_image_dst, dtype=torch.float32).permute(0, 3, 1, 2).to(device) return warp_image_src, target_image_src, warp_image_dst, target_image_dst
當我們從Dataloader對象獲取數(shù)據(jù)時,它將返回一個元組,其中包含來自FaceData對象的源圖像和目標圖像對。collate_fn接受這個結(jié)果,并對圖像進行變換和失真,得到目標圖像,并為扭曲的源圖像、目標源圖像、扭曲的目標圖像和目標目標圖像返回四個4D張量。
訓練使用的損失函數(shù)是MSE (L2)損失和DSSIM的組合
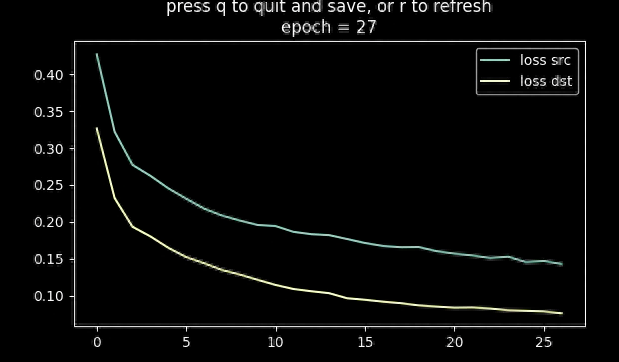 ? ??
? ??
訓練的指標和結(jié)果如上圖所示
生成視頻
在最后一步就是創(chuàng)建視頻。處理此任務的函數(shù)稱為
merge_frame_to_fake_video.py。我們使用MediaPipe創(chuàng)建了facemask類。
當初始化facemask對象時,初始化MediaPipe人臉檢測器。
class FaceMasking: def __init__(self): landmarks_model_path = Path('models/face_landmarker.task') if not landmarks_model_path.exists(): landmarks_model_path.parent.mkdir(parents=True, exist_ok=True) url = "https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/latest/face_landmarker.task" print('Downloading face landmarks model...') filename, headers = urlretrieve(url, filename=str(landmarks_model_path)) print('Download finish!') base_options = python_mp.BaseOptions(model_asset_path=str(landmarks_model_path)) options = vision.FaceLandmarkerOptions(base_options=base_options, output_face_blendshapes=False, output_facial_transformation_matrixes=False, num_faces=1) self.detector = vision.FaceLandmarker.create_from_options(options)
這個類也有一個從人臉圖像中獲取掩碼的方法:
def get_mask(self, image): """ return uint8 mask of the face in image Args: image (np.ndarray): RGB image with single face Returns: (np.ndarray): single channel uint8 mask of the face """ im_mp = mp.Image(image_format=mp.ImageFormat.SRGB, data=image.astype(np.uint8).copy()) detection_result = self.detector.detect(im_mp) x = np.array([landmark.x * image.shape[1] for landmark in detection_result.face_landmarks[0]], dtype=np.float32) y = np.array([landmark.y * image.shape[0] for landmark in detection_result.face_landmarks[0]], dtype=np.float32) hull = np.round(np.squeeze(cv2.convexHull(np.column_stack((x, y))))).astype(np.int32) mask = np.zeros(image.shape[:2], dtype=np.uint8) mask = cv2.fillConvexPoly(mask, hull, 255) kernel = np.ones((7, 7), np.uint8) mask = cv2.erode(mask, kernel) return mask
該函數(shù)首先將輸入圖像轉(zhuǎn)換為MediaPipe圖像結(jié)構(gòu),然后使用人臉檢測器查找人臉。然后使用OpenCV找到點的凸包,并使用OpenCV的fillConvexPoly函數(shù)填充凸包的區(qū)域,從而得到一個二進制掩碼。最后,我們應用侵蝕操作來縮小遮蔽。
def get_mask(self, image): """ return uint8 mask of the face in image Args: image (np.ndarray): RGB image with single face Returns: (np.ndarray): single channel uint8 mask of the face """ im_mp = mp.Image(image_format=mp.ImageFormat.SRGB, data=image.astype(np.uint8).copy()) detection_result = self.detector.detect(im_mp) x = np.array([landmark.x * image.shape[1] for landmark in detection_result.face_landmarks[0]], dtype=np.float32) y = np.array([landmark.y * image.shape[0] for landmark in detection_result.face_landmarks[0]], dtype=np.float32) hull = np.round(np.squeeze(cv2.convexHull(np.column_stack((x, y))))).astype(np.int32) mask = np.zeros(image.shape[:2], dtype=np.uint8) mask = cv2.fillConvexPoly(mask, hull, 255) kernel = np.ones((7, 7), np.uint8) mask = cv2.erode(mask, kernel) return mask
merge_frame_to_fake_video函數(shù)就是將上面所有的步驟整合,創(chuàng)建一個新的視頻對象,一個FaceExtracot對象,一個facemask對象,創(chuàng)建神經(jīng)網(wǎng)絡組件,并加載它們的權(quán)重。
def merge_frames_to_fake_video(dst_frames_path, model_name='Quick96', saved_models_dir='saved_model'):
model_path = Path(saved_models_dir) / f'{model_name}.pth'
dst_frames_path = Path(dst_frames_path)
image = Image.open(next(dst_frames_path.glob('*.jpg')))
image_size = image.size
result_video = cv2.VideoWriter(str(dst_frames_path.parent / 'fake.mp4'), cv2.VideoWriter_fourcc(*'MJPG'), 30, image.size)
face_extractor = FaceExtractor(image_size)
face_masker = FaceMasking()
encoder = Encoder().to(device)
inter = Inter().to(device)
decoder = Decoder().to(device)
saved_model = torch.load(model_path)
encoder.load_state_dict(saved_model['encoder'])
inter.load_state_dict(saved_model['inter'])
decoder.load_state_dict(saved_model['decoder_src'])
model = torch.nn.Sequential(encoder, inter, decoder)
然后針對目標視頻中的所有幀,找到臉。如果沒有人臉就把畫面寫入視頻。如果有人臉,將其提取出來,轉(zhuǎn)換為網(wǎng)絡的適當輸入,并生成新的人臉。
對原人臉和新人臉進行遮蔽,利用遮蔽圖像上的矩量找到原人臉的中心。使用無縫克隆,以逼真的方式將新臉代替原來的臉(例如,改變假臉的膚色,以適應原來的臉皮膚)。最后將結(jié)果作為一個新的幀放回原始幀,并將其寫入視頻文件。
frames_list = sorted(dst_frames_path.glob('*.jpg'))
for ii, frame_path in enumerate(frames_list, 1):
print(f'Working om {ii}/{len(frames_list)}')
frame = cv2.imread(str(frame_path))
retval, face = face_extractor.detect(frame)
if face is None:
result_video.write(frame)
continue
face_image, face = face_extractor.extract(frame, face[0])
face_image = face_image[..., ::-1].copy()
face_image_cropped = cv2.resize(face_image, (96, 96)) #face_image_resized[96//2:96+96//2, 96//2:96+96//2]
face_image_cropped_torch = torch.tensor(face_image_cropped / 255., dtype=torch.float32).permute(2, 0, 1).unsqueeze(0).to(device)
generated_face_torch = model(face_image_cropped_torch)
generated_face = (generated_face_torch.squeeze().permute(1,2,0).detach().cpu().numpy() * 255).astype(np.uint8)
mask_origin = face_masker.get_mask(face_image_cropped)
mask_fake = face_masker.get_mask(generated_face)
origin_moments = cv2.moments(mask_origin)
cx = np.round(origin_moments['m10'] / origin_moments['m00']).astype(int)
cy = np.round(origin_moments['m01'] / origin_moments['m00']).astype(int)
try:
output_face = cv2.seamlessClone(generated_face, face_image_cropped, mask_fake, (cx, cy), cv2.NORMAL_CLONE)
except:
print('Skip')
continue
fake_face_image = cv2.resize(output_face, (face_image.shape[1], face_image.shape[0]))
fake_face_image = fake_face_image[..., ::-1] # change to BGR
frame[face[1]:face[1]+face[3], face[0]:face[0]+face[2]] = fake_face_image
result_video.write(frame)
result_video.release()
一幀的結(jié)果是這樣的
模型并不完美,面部的某些角度,特別是側(cè)面視圖,會導致圖像不那么好,但總體效果不錯。
整合
為了運行整個過程,還需要創(chuàng)建一個主腳本。
from pathlib import Path import face_extraction_tools as fet import quick96 as q96 from merge_frame_to_fake_video import merge_frames_to_fake_video ##### user parameters ##### # True for executing the step extract_and_align_src = True extract_and_align_dst = True train = True eval = False model_name = 'Quick96' # use this name to save and load the model new_model = False # True for creating a new model even if a model with the same name already exists ##### end of user parameters ##### # the path for the videos to process data_root = Path('./data') src_video_path = data_root / 'data_src.mp4' dst_video_path = data_root / 'data_dst.mp4' # path to folders where the intermediate product will be saved src_processing_folder = data_root / 'src' dst_processing_folder = data_root / 'dst' # step 1: extract the frames from the videos if extract_and_align_src: fet.extract_frames_from_video(video_path=src_video_path, output_folder=src_processing_folder, frames_to_skip=0) if extract_and_align_dst: fet.extract_frames_from_video(video_path=dst_video_path, output_folder=dst_processing_folder, frames_to_skip=0) # step 2: extract and align face from frames if extract_and_align_src: fet.extract_and_align_face_from_image(input_dir=src_processing_folder, desired_face_width=256) if extract_and_align_dst: fet.extract_and_align_face_from_image(input_dir=dst_processing_folder, desired_face_width=256) # step 3: train the model if train: q96.train(str(data_root), model_name, new_model, saved_models_dir='saved_model') # step 4: create the fake video if eval: merge_frames_to_fake_video(dst_processing_folder, model_name, saved_models_dir='saved_model')
總結(jié)
在這篇文章中,我們介紹了DeepFaceLab的運行流程,并使用我們自己的方法實現(xiàn)了該過程。我們首先從視頻中提取幀,然后從幀中提取人臉并對齊它們以創(chuàng)建一個數(shù)據(jù)庫。使用神經(jīng)網(wǎng)絡來學習如何在潛在空間中表示人臉以及如何重建人臉。遍歷了目標視頻的幀,找到了人臉并替換,這就是這個項目的完整流程。
審核編輯:湯梓紅
-
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3846瀏覽量
64684 -
OpenCV
+關(guān)注
關(guān)注
31文章
635瀏覽量
41556 -
人臉圖像
+關(guān)注
關(guān)注
0文章
11瀏覽量
8993 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13359
原文標題:使用Pytorch和OpenCV實現(xiàn)視頻人臉替換
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
樹莓派上使用OpenCV和Python實現(xiàn)實時人臉檢測
如何用OpenCV的相機捕捉視頻進行人臉檢測--基于米爾NXP i.MX93開發(fā)板
基于openCV的人臉檢測系統(tǒng)的設計
【NanoPi2申請】基于opencv的人臉識別門禁系統(tǒng)
【AI技能解析】人臉識別是怎么做到的?
【飛凌RK3568開發(fā)板試用體驗】使用OpenCV進行人臉識別
【飛凌RK3588開發(fā)板試用】實現(xiàn)人臉檢測
如何往星光2板子里裝pytorch?
基于openCV的人臉檢測識別系統(tǒng)的設計

openCV人臉檢測系統(tǒng)的設計方案探究
基于SeetaFace2和OpenCV實現(xiàn)人臉識別
使用DFRobot LattePanda進行OpenCV人臉識別






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論