") 從原理到代碼理解語(yǔ)言模型訓(xùn)練和推理,通俗易懂,快速修煉LLM
從原理到代碼理解語(yǔ)言模型訓(xùn)練和推理,通俗易懂,快速修煉LLM
今天分享一篇博客,介紹語(yǔ)言模型的訓(xùn)練和推理,通俗易懂且抓住本質(zhì)核心,強(qiáng)烈推薦閱讀。
標(biāo)題:Language Model Training and Inference: From Concept to Code
作者:CAMERON R. WOLFE
原文:
https://cameronrwolfe.substack.com/p/language-model-training-and-inference
要理解大語(yǔ)言模型(LLM),首先要理解它的本質(zhì),無(wú)論預(yù)訓(xùn)練、微調(diào)還是在推理階段,核心都是next token prediction,也就是以自回歸的方式從左到右逐步生成文本。
什么是token?
token是指文本中的一個(gè)詞或者子詞,給定一句文本,送入語(yǔ)言模型前首先要做的是對(duì)原始文本進(jìn)行tokenize,也就是把一個(gè)文本序列拆分為離散的token序列
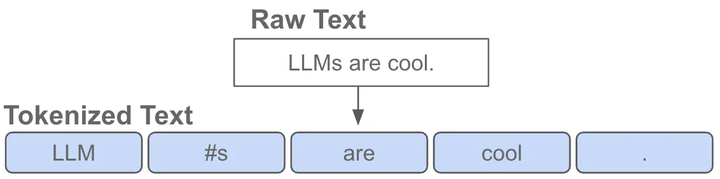
其中,tokenizer是在無(wú)標(biāo)簽的語(yǔ)料上訓(xùn)練得到的一個(gè)token數(shù)量固定且唯一的分詞器,這里的token數(shù)量就是大家常說(shuō)的詞表,也就是語(yǔ)言模型知道的所有tokens。
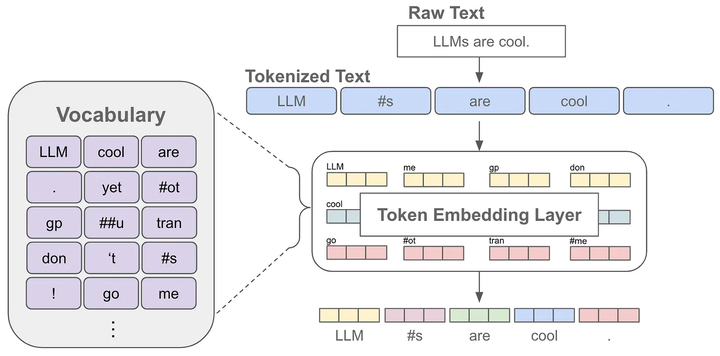
當(dāng)我們對(duì)文本進(jìn)行分詞后,每個(gè)token可以對(duì)應(yīng)一個(gè)embedding,這也就是語(yǔ)言模型中的embedding層,獲得某個(gè)token的embedding就類(lèi)似一個(gè)查表的過(guò)程
我們知道文本序列是有順序的,而常見(jiàn)的語(yǔ)言模型都是基于注意力機(jī)制的transformer結(jié)構(gòu),無(wú)法自動(dòng)考慮文本的前后順序,因此需要手動(dòng)加上位置編碼,也就是每個(gè)位置有一個(gè)位置embedding,然后和對(duì)應(yīng)位置的token embedding進(jìn)行相加
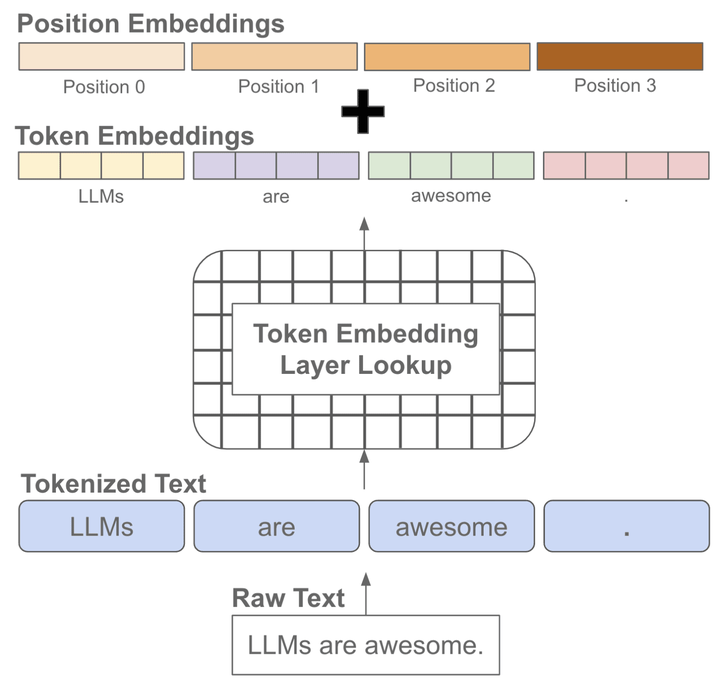
在模型訓(xùn)練或推理階段大家經(jīng)常會(huì)聽(tīng)到上下文長(zhǎng)度這個(gè)詞,它指的是模型訓(xùn)練時(shí)接收的token訓(xùn)練的最大長(zhǎng)度,如果在訓(xùn)練階段只學(xué)習(xí)了一個(gè)較短長(zhǎng)度的位置embedding,那模型在推理階段就不能夠適用于較長(zhǎng)文本(因?yàn)樗鼪](méi)見(jiàn)過(guò)長(zhǎng)文本的位置編碼)
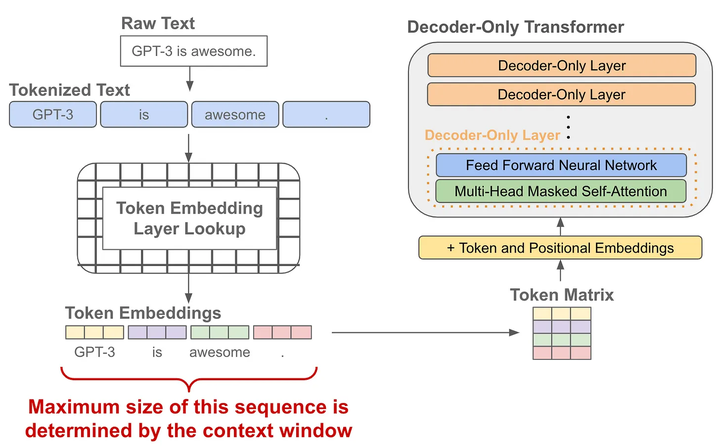
語(yǔ)言模型的預(yù)訓(xùn)練
當(dāng)我們有了token embedding和位置embedding后,將它們送入一個(gè)decoder-only的transofrmer模型,它會(huì)在每個(gè)token的位置輸出一個(gè)對(duì)應(yīng)的embedding(可以理解為就像是做了個(gè)特征加工)
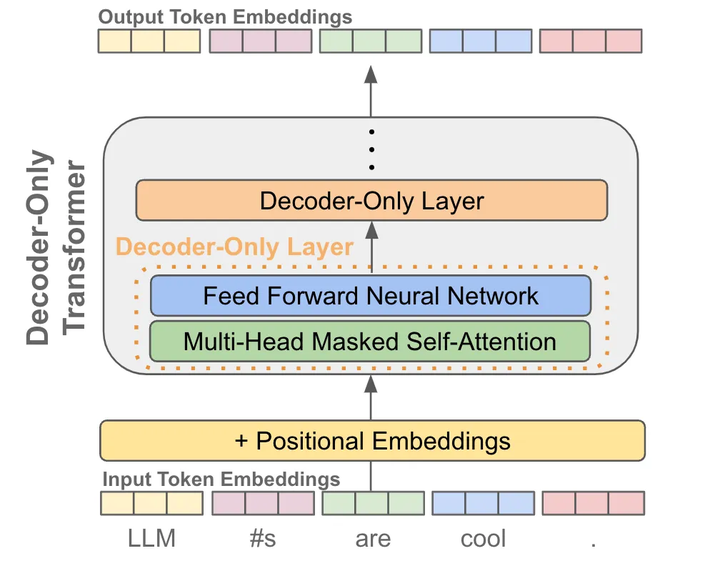
有了每個(gè)token的一個(gè)輸出embedding后,我們就可以拿它來(lái)做next token prediction了,其實(shí)就是當(dāng)作一個(gè)分類(lèi)問(wèn)題來(lái)看待:
首先我們把輸出embedding送入一個(gè)線性層,輸出的維度是詞表的大小,就是讓預(yù)測(cè)這個(gè)token的下一個(gè)token屬于詞表的“哪一類(lèi)”
為了將輸出概率歸一化,需要再進(jìn)行一個(gè)softmax變換
訓(xùn)練時(shí)就是最大化這個(gè)概率使得它能夠預(yù)測(cè)真實(shí)的下一個(gè)token
推理時(shí)就是從這個(gè)概率分布中采樣下一個(gè)token
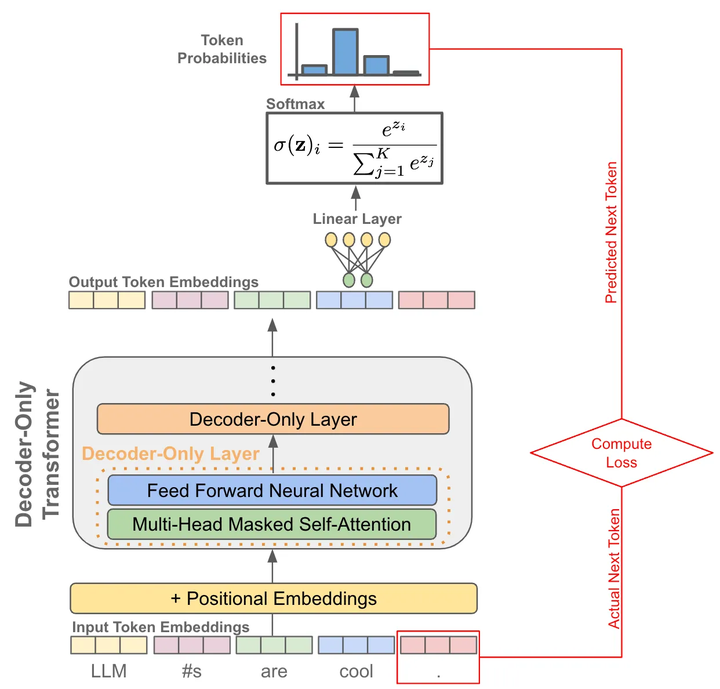
訓(xùn)練階段:因?yàn)橛衏ausal自注意力的存在,我們可以一次性對(duì)一整個(gè)句子每個(gè)token進(jìn)行下一個(gè)token的預(yù)測(cè),并計(jì)算所有位置token的loss,因此只需要一forward
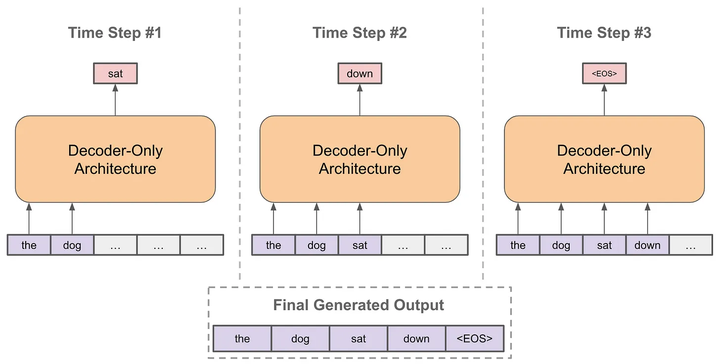
推理階段:以自回歸的方式進(jìn)行預(yù)測(cè)
每次預(yù)測(cè)下一個(gè)token
將預(yù)測(cè)的token拼接到當(dāng)前已經(jīng)生成的句子上
再基于拼接后的句子進(jìn)行預(yù)測(cè)下一個(gè)token
不斷重復(fù)直到結(jié)束
其中,在預(yù)測(cè)下一個(gè)token時(shí),每次我們都有一個(gè)概率分布用于采樣,根據(jù)不同場(chǎng)景選擇采樣策略會(huì)略有不同,不然有貪婪策略、核采樣、Top-k采樣等,另外經(jīng)常會(huì)看到Temperature這個(gè)概念,它是用來(lái)控制生成的隨機(jī)性的,溫度系數(shù)越小越穩(wěn)定。
代碼實(shí)現(xiàn)
下面代碼來(lái)自項(xiàng)目https://github.com/karpathy/nanoGPT/tree/master,同樣是一個(gè)很好的項(xiàng)目,推薦初學(xué)者可以看看。
對(duì)于各種基于Transformer的模型,它們都是由很多個(gè)Block堆起來(lái)的,每個(gè)Block主要有兩個(gè)部分組成:
Multi-headed Causal Self-Attention
Feed-forward Neural Network結(jié)構(gòu)的示意圖如下:
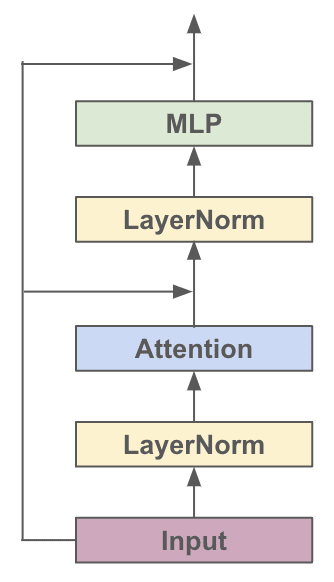
看圖搭一下單個(gè)Block
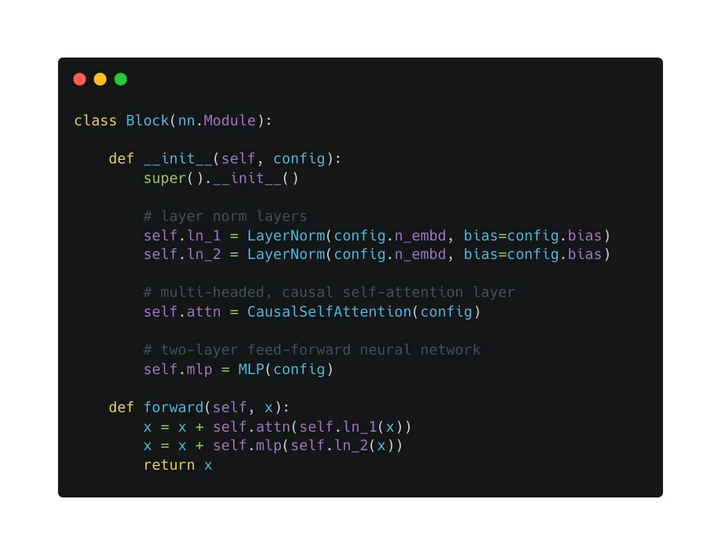
然后看下一整個(gè)GPT的結(jié)構(gòu)
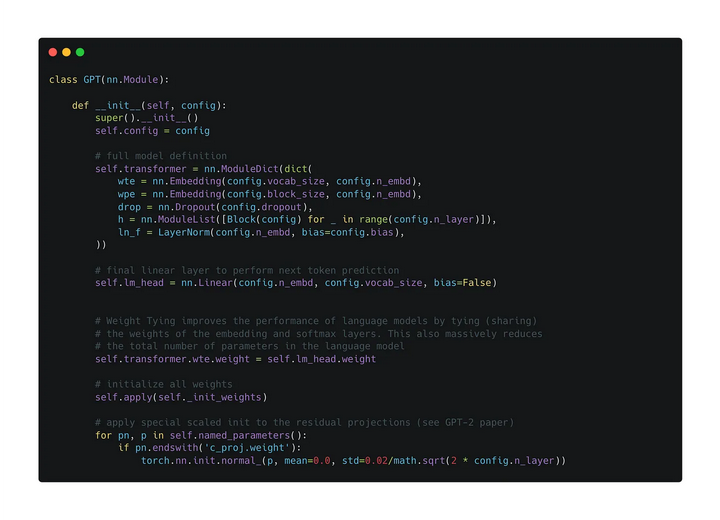
主要就是兩個(gè)embedding層(token、位置)、多個(gè)block、一些額外的dropout和LayerNorm層,以及最后用來(lái)預(yù)測(cè)下一個(gè)token的線性層。說(shuō)破了就是這么簡(jiǎn)單。
這邊還用到了weight tying的技巧,就是最后一層用來(lái)分類(lèi)的線性層的權(quán)重和token embedding層的權(quán)重共享。
接下來(lái)重點(diǎn)來(lái)關(guān)注一下訓(xùn)練和推理的forward是如何進(jìn)行的,這能幫助大家更好的理解原理。
首先需要構(gòu)建token embedding和位置embedding,把它們疊加起來(lái)后過(guò)一個(gè)dropout,然后就可以送入transformer的block中了。
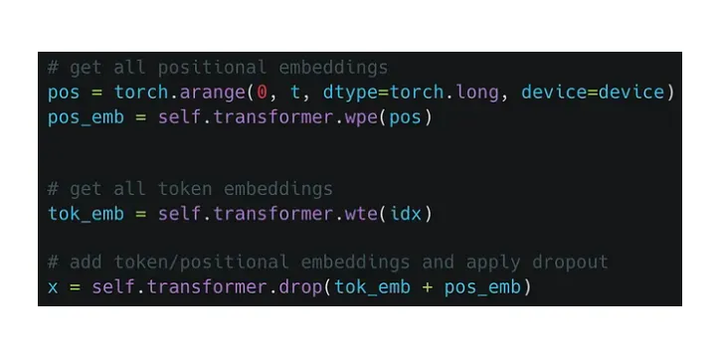
需要注意的是經(jīng)過(guò)transforemr block后出來(lái)的tensor的維度跟之前是一樣的。拿到每個(gè)token位置對(duì)應(yīng)的輸出embedding后,就可以通過(guò)最后的先行層進(jìn)行分類(lèi),然后用交叉熵?fù)p失來(lái)進(jìn)行優(yōu)化。

再看一下完整的過(guò)程,其中只需要將輸入左移一個(gè)位置就可以作為target了
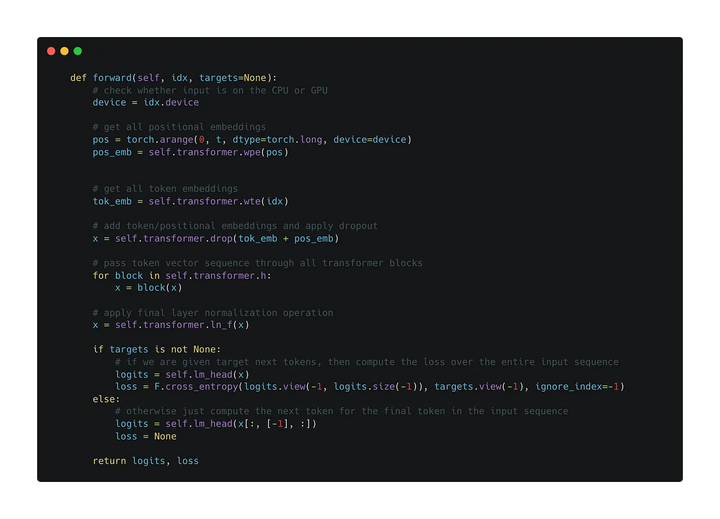
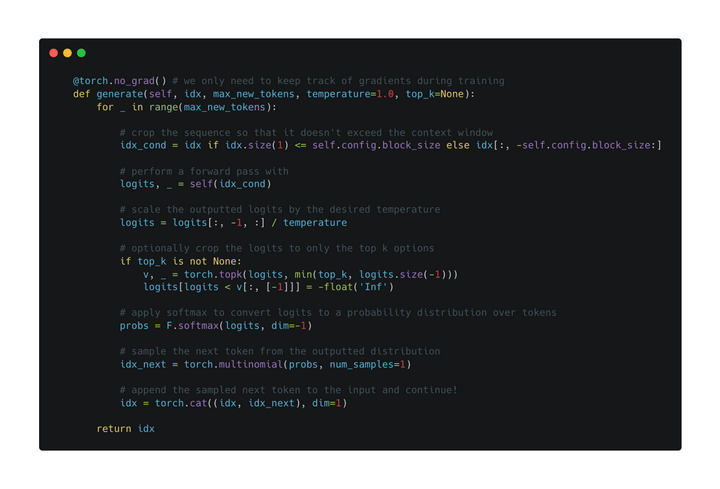
接下來(lái)看推理階段:
根據(jù)當(dāng)前輸入序列進(jìn)行一次前向傳播
利用溫度系數(shù)對(duì)輸出概率分布進(jìn)行調(diào)整
通過(guò)softmax進(jìn)行歸一化
從概率分布進(jìn)行采樣下一個(gè)token
拼接到當(dāng)前句子并再進(jìn)入下一輪循環(huán)
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
538瀏覽量
10341 -
LLM
+關(guān)注
關(guān)注
0文章
299瀏覽量
400
原文標(biāo)題:從原理到代碼理解語(yǔ)言模型訓(xùn)練和推理,通俗易懂,快速修煉LLM
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
通俗易懂的PID教程
通俗易懂系列整合—電源基礎(chǔ)知識(shí)講解
通俗易懂之電子稱開(kāi)發(fā)導(dǎo)航篇

通俗易懂的講解FFT的讓你快速了解FFT
大型語(yǔ)言模型(LLM)的自定義訓(xùn)練:包含代碼示例的詳細(xì)指南
大語(yǔ)言模型(LLM)快速理解






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論