 JDK中java.lang.String 類的源碼解析
JDK中java.lang.String 類的源碼解析
1、String 類的定義
public final class String
implements java.io.Serializable, Comparable, CharSequence {}
和上一篇博客所講的 Integer 類一樣,這也是一個用 final 聲明的常量類,不能被任何類所繼承,而且一旦一個String對象被創建, 包含在這個對象中的字符序列是不可改變的, 包括該類后續的所有方法都是不能修改該對象的,直至該對象被銷毀,這是我們需要特別注意的(該類的一些方法看似改變了字符串,其實內部都是創建一個新的字符串,下面講解方法時會介紹)。接著實現了 Serializable接口,這是一個序列化標志接口,還實現了 Comparable 接口,用于比較兩個字符串的大小(按順序比較單個字符的ASCII碼),后面會有具體方法實現;最后實現了 CharSequence 接口,表示是一個有序字符的集合,相應的方法后面也會介紹。
2、字段屬性
/**用來存儲字符串 */
private final char value[];
/** 緩存字符串的哈希碼 */
private int hash; // Default to 0
/** 實現序列化的標識 */
private static final long serialVersionUID = -6849794470754667710L;
一個 String 字符串實際上是一個 char 數組。
3、構造方法
String 類的構造方法很多。可以通過初始化一個字符串,或者字符數組,或者字節數組等等來創建一個 String 對象。
String str1 = "abc";//注意這種字面量聲明的區別,文末會詳細介紹
String str2 = new String("abc");
String str3 = new String(new char[]{'a','b','c'});
4、equals(Object anObject) 方法
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
String 類重寫了 equals 方法,比較的是組成字符串的每一個字符是否相同,如果都相同則返回true,否則返回false。
5、hashCode() 方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
String 類的 hashCode 算法很簡單,主要就是中間的 for 循環,計算公式如下:
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
s 數組即源碼中的 val 數組,也就是構成字符串的字符數組。這里有個數字 31 ,為什么選擇31作為乘積因子,而且沒有用一個常量來聲明?主要原因有兩個:
①、31是一個不大不小的質數,是作為 hashCode 乘子的優選質數之一。
②、31可以被 JVM 優化,31 * i = (i << 5) - i。因為移位運算比乘法運行更快更省性能。
6、charAt(int index) 方法
public char charAt(int index) {
//如果傳入的索引大于字符串的長度或者小于0,直接拋出索引越界異常
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];//返回指定索引的單個字符
}
我們知道一個字符串是由一個字符數組組成,這個方法是通過傳入的索引(數組下標),返回指定索引的單個字符。
7、compareTo(String anotherString) 和 compareToIgnoreCase(String str) 方法
我們先看看 compareTo 方法:
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
源碼也很好理解,該方法是按字母順序比較兩個字符串,是基于字符串中每個字符的 Unicode 值。當兩個字符串某個位置的字符不同時,返回的是這一位置的字符 Unicode 值之差,當兩個字符串都相同時,返回兩個字符串長度之差。
compareToIgnoreCase() 方法在 compareTo 方法的基礎上忽略大小寫,我們知道大寫字母是比小寫字母的Unicode值小32的,底層實現是先都轉換成大寫比較,然后都轉換成小寫進行比較。
8、concat(String str) 方法
該方法是將指定的字符串連接到此字符串的末尾。
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
首先判斷要拼接的字符串長度是否為0,如果為0,則直接返回原字符串。如果不為0,則通過 Arrays 工具類(后面會詳細介紹這個工具類)的copyOf方法創建一個新的字符數組,長度為原字符串和要拼接的字符串之和,前面填充原字符串,后面為空。接著在通過 getChars 方法將要拼接的字符串放入新字符串后面為空的位置。
注意:返回值是 new String(buf, true),也就是重新通過 new 關鍵字創建了一個新的字符串,原字符串是不變的。這也是前面我們說的一旦一個String對象被創建, 包含在這個對象中的字符序列是不可改變的。
9、indexOf(int ch) 和 indexOf(int ch, int fromIndex) 方法
indexOf(int ch),參數 ch 其實是字符的 Unicode 值,這里也可以放單個字符(默認轉成int),作用是返回指定字符第一次出現的此字符串中的索引。其內部是調用 indexOf(int ch, int fromIndex),只不過這里的 fromIndex =0 ,因為是從 0 開始搜索;而 indexOf(int ch, int fromIndex) 作用也是返回首次出現的此字符串內的索引,但是從指定索引處開始搜索。
public int indexOf(int ch) {
return indexOf(ch, 0);//從第一個字符開始搜索
}
public int indexOf(int ch, int fromIndex) {
final int max = value.length;//max等于字符的長度
if (fromIndex < 0) {//指定索引的位置如果小于0,默認從 0 開始搜索
fromIndex = 0;
} else if (fromIndex >= max) {
//如果指定索引值大于等于字符的長度(因為是數組,下標最多只能是max-1),直接返回-1
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {//一個char占用兩個字節,如果ch小于2的16次方(65536),絕大多數字符都在此范圍內
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {//for循環依次判斷字符串每個字符是否和指定字符相等
if (value[i] == ch) {
return i;//存在相等的字符,返回第一次出現該字符的索引位置,并終止循環
}
}
return -1;//不存在相等的字符,則返回 -1
} else {//當字符大于 65536時,處理的少數情況,該方法會首先判斷是否是有效字符,然后依次進行比較
return indexOfSupplementary(ch, fromIndex);
}
}
10、split(String regex) 和 split(String regex, int limit) 方法
split(String regex) 將該字符串拆分為給定正則表達式的匹配。split(String regex , int limit) 也是一樣,不過對于 limit 的取值有三種情況:
①、limit > 0 ,則pattern(模式)應用n - 1 次
String str = "a,b,c";
String[] c1 = str.split(",", 2);
System.out.println(c1.length);//2
System.out.println(Arrays.toString(c1));//{"a","b,c"}
②、limit = 0 ,則pattern(模式)應用無限次并且省略末尾的空字串
String str2 = "a,b,c,,";
String[] c2 = str2.split(",", 0);
System.out.println(c2.length);//3
System.out.println(Arrays.toString(c2));//{"a","b","c"}
③、limit < 0 ,則pattern(模式)應用無限次
String str2 = "a,b,c,,";
String[] c2 = str2.split(",", -1);
System.out.println(c2.length);//5
System.out.println(Arrays.toString(c2));//{"a","b","c","",""}
下面我們看看底層的源碼實現。對于 split(String regex) 沒什么好說的,內部調用 split(regex, 0) 方法:
public String[] split(String regex) {
return split(regex, 0);
}
重點看 split(String regex, int limit) 的方法實現:
public String[] split(String regex, int limit) {
/* 1、單個字符,且不是".$|()[{^?*+"其中一個
* 2、兩個字符,第一個是"",第二個大小寫字母或者數字
*/
char ch = 0;
if (((regex.value.length == 1 &&
".$|()[{^?*+".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
{
int off = 0;
int next = 0;
boolean limited = limit > 0;//大于0,limited==true,反之limited==false
ArrayList< String > list = new ArrayList< >();
while ((next = indexOf(ch, off)) != -1) {
//當參數limit<=0 或者 集合list的長度小于 limit-1
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;
} else {//判斷最后一個list.size() == limit - 1
list.add(substring(off, value.length));
off = value.length;
break;
}
}
//如果沒有一個能匹配的,返回一個新的字符串,內容和原來的一樣
if (off == 0)
return new String[]{this};
// 當 limit<=0 時,limited==false,或者集合的長度 小于 limit是,截取添加剩下的字符串
if (!limited || list.size() < limit)
list.add(substring(off, value.length));
// 當 limit == 0 時,如果末尾添加的元素為空(長度為0),則集合長度不斷減1,直到末尾不為空
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).length() == 0) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
return Pattern.compile(regex).split(this, limit);
}
11、replace(char oldChar, char newChar) 和 String replaceAll(String regex, String replacement) 方法
①、replace(char oldChar, char newChar) :將原字符串中所有的oldChar字符都替換成newChar字符,返回一個新的字符串。
②、String replaceAll(String regex, String replacement):將匹配正則表達式regex的匹配項都替換成replacement字符串,返回一個新的字符串。
12、substring(int beginIndex) 和 substring(int beginIndex, int endIndex) 方法
①、substring(int beginIndex):返回一個從索引 beginIndex 開始一直到結尾的子字符串。
public String substring(int beginIndex) {
if (beginIndex < 0) {//如果索引小于0,直接拋出異常
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;//subLen等于字符串長度減去索引
if (subLen < 0) {//如果subLen小于0,也是直接拋出異常
throw new StringIndexOutOfBoundsException(subLen);
}
//1、如果索引值beginIdex == 0,直接返回原字符串
//2、如果不等于0,則返回從beginIndex開始,一直到結尾
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
②、 substring(int beginIndex, int endIndex):返回一個從索引 beginIndex 開始,到 endIndex 結尾的子字符串。
13、常量池
在前面講解構造函數的時候,我們知道最常見的兩種聲明一個字符串對象的形式有兩種:
①、通過“字面量”的形式直接賦值
String str = "hello";
②、通過 new 關鍵字調用構造函數創建對象
String str = new String("hello");
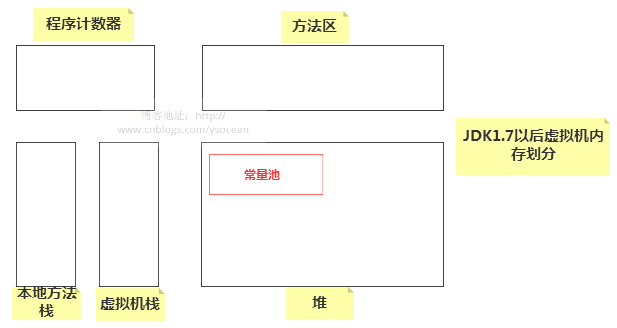
那么這兩種聲明方式有什么區別呢?在講解之前,我們先介紹 JDK1.7(不包括1.7)以前的 JVM 的內存分布:

①、程序計數器:也稱為 PC 寄存器,保存的是程序當前執行的指令的地址(也可以說保存下一條指令的所在存儲單元的地址),當CPU需要執行指令時,需要從程序計數器中得到當前需要執行的指令所在存儲單元的地址,然后根據得到的地址獲取到指令,在得到指令之后,程序計數器便自動加1或者根據轉移指針得到下一條指令的地址,如此循環,直至執行完所有的指令。線程私有。
②、虛擬機棧:基本數據類型、對象的引用都存放在這。線程私有。
③、本地方法棧:虛擬機棧是為執行Java方法服務的,而本地方法棧則是為執行本地方法(Native Method)服務的。在JVM規范中,并沒有對本地方法棧的具體實現方法以及數據結構作強制規定,虛擬機可以自由實現它。在HotSopt虛擬機中直接就把本地方法棧和虛擬機棧合二為一。
④、方法區:存儲了每個類的信息(包括類的名稱、方法信息、字段信息)、靜態變量、常量以及編譯器編譯后的代碼等。注意:在Class文件中除了類的字段、方法、接口等描述信息外,還有一項信息是常量池,用來存儲編譯期間生成的字面量和符號引用。
⑤、堆:用來存儲對象本身的以及數組(當然,數組引用是存放在Java棧中的)。
在 JDK1.7 以后,方法區的常量池被移除放到堆中了,如下:
常量池:Java運行時會維護一個String Pool(String池), 也叫“字符串緩沖區”。String池用來存放運行時中產生的各種字符串,并且池中的字符串的內容不重復。
①、字面量創建字符串或者純字符串(常量)拼接字符串會先在字符串池中找,看是否有相等的對象,沒有的話就在字符串池創建該對象;有的話則直接用池中的引用,避免重復創建對象。
②、new關鍵字創建時,直接在堆中創建一個新對象,變量所引用的都是這個新對象的地址,但是如果通過new關鍵字創建的字符串內容在常量池中存在了,那么會由堆在指向常量池的對應字符;但是反過來,如果通過new關鍵字創建的字符串對象在常量池中沒有,那么通過new關鍵詞創建的字符串對象是不會額外在常量池中維護的。
③、使用包含變量表達式來創建String對象,則不僅會檢查維護字符串池,還會在堆區創建這個對象,最后是指向堆內存的對象。
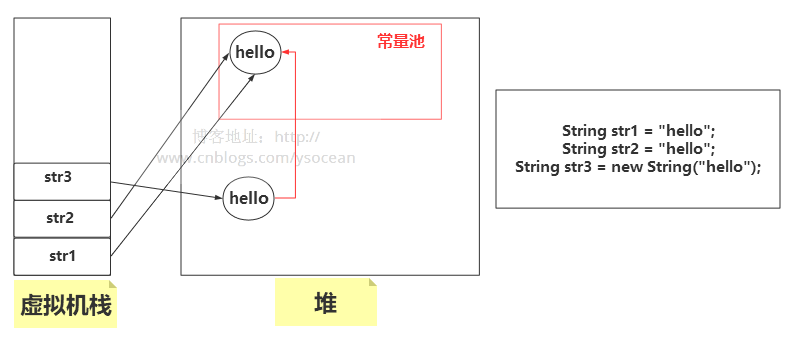
String str1 = "hello";
String str2 = "hello";
String str3 = new String("hello");
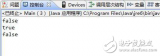
System.out.println(str1==str2);//true
System.out.println(str1==str3);//fasle
System.out.println(str2==str3);//fasle
System.out.println(str1.equals(str2));//true
System.out.println(str1.equals(str3));//true
System.out.println(str2.equals(str3));//true
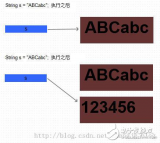
對于上面的情況,首先 String str1 = "hello",會先到常量池中檢查是否有“hello”的存在,發現是沒有的,于是在常量池中創建“hello”對象,并將常量池中的引用賦值給str1;第二個字面量 String str2 = "hello",在常量池中檢測到該對象了,直接將引用賦值給str2;第三個是通過new關鍵字創建的對象,常量池中有了該對象了,不用在常量池中創建,然后在堆中創建該對象后,將堆中對象的引用賦值給str3,再將該對象指向常量池。如下圖所示:
注意:看上圖紅色的箭頭,通過 new 關鍵字創建的字符串對象,如果常量池中存在了,會將堆中創建的對象指向常量池的引用。我們可以通過文章末尾介紹的intern()方法來驗證。
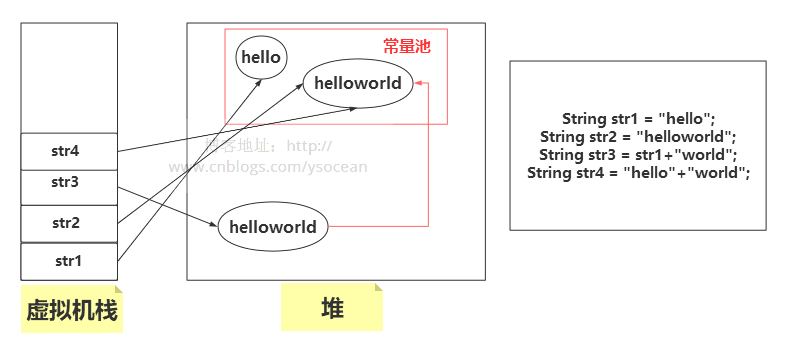
使用包含變量表達式創建對象:
String str1 = "hello";
String str2 = "helloworld";
String str3 = str1+"world";//編譯器不能確定為常量(會在堆區創建一個String對象)
String str4 = "hello"+"world";//編譯器確定為常量,直接到常量池中引用
System.out.println(str2==str3);//fasle
System.out.println(str2==str4);//true
System.out.println(str3==str4);//fasle
str3 由于含有變量str1,編譯器不能確定是常量,會在堆區中創建一個String對象。而str4是兩個常量相加,直接引用常量池中的對象即可。
14、intern() 方法
這是一個本地方法:
public native String intern();
當調用intern方法時,如果池中已經包含一個與該String確定的字符串相同equals(Object)的字符串,則返回該字符串。否則,將此String對象添加到池中,并返回此對象的引用。
這句話什么意思呢?就是說調用一個String對象的intern()方法,如果常量池中有該對象了,直接返回該字符串的引用(存在堆中就返回堆中,存在池中就返回池中),如果沒有,則將該對象添加到池中,并返回池中的引用。
String str1 = "hello";//字面量 只會在常量池中創建對象
String str2 = str1.intern();
System.out.println(str1==str2);//true
String str3 = new String("world");//new 關鍵字只會在堆中創建對象
String str4 = str3.intern();
System.out.println(str3 == str4);//false
String str5 = str1 + str2;//變量拼接的字符串,會在常量池中和堆中都創建對象
String str6 = str5.intern();//這里由于池中已經有對象了,直接返回的是對象本身,也就是堆中的對象
System.out.println(str5 == str6);//true
String str7 = "hello1" + "world1";//常量拼接的字符串,只會在常量池中創建對象
String str8 = str7.intern();
System.out.println(str7 == str8);//true
15、String 真的不可變嗎?
前面我們介紹了,String 類是用 final 關鍵字修飾的,所以我們認為其是不可變對象。但是真的不可變嗎?
每個字符串都是由許多單個字符組成的,我們知道其源碼是由 char[] value 字符數組構成。
public final class String
implements java.io.Serializable, Comparable< String >, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
value 被 final 修飾,只能保證引用不被改變,但是 value 所指向的堆中的數組,才是真實的數據,只要能夠操作堆中的數組,依舊能改變數據。而且 value 是基本類型構成,那么一定是可變的,即使被聲明為 private,我們也可以通過反射來改變。
String str = "vae";
//打印原字符串
System.out.println(str);//vae
//獲取String類中的value字段
Field fieldStr = String.class.getDeclaredField("value");
//因為value是private聲明的,這里修改其訪問權限
fieldStr.setAccessible(true);
//獲取str對象上的value屬性的值
char[] value = (char[]) fieldStr.get(str);
//將第一個字符修改為 V(小寫改大寫)
value[0] = 'V';
//打印修改之后的字符串
System.out.println(str);//Vae
通過前后兩次打印的結果,我們可以看到 String 被改變了,但是在代碼里,幾乎不會使用反射的機制去操作 String 字符串,所以,我們會認為 String 類型是不可變的。
那么,String 類為什么要這樣設計成不可變呢?我們可以從性能以及安全方面來考慮:
安全
引發安全問題,譬如,數據庫的用戶名、密碼都是以字符串的形式傳入來獲得數據庫的連接,或者在socket編程中,主機名和端口都是以字符串的形式傳入。因為字符串是不可變的,所以它的值是不可改變的,否則黑客們可以鉆到空子,改變字符串指向的對象的值,造成安全漏洞。
保證線程安全,在并發場景下,多個線程同時讀寫資源時,會引競態條件,由于 String 是不可變的,不會引發線程的問題而保證了線程。
HashCode,當 String 被創建出來的時候,hashcode也會隨之被緩存,hashcode的計算與value有關,若 String 可變,那么 hashcode 也會隨之變化,針對于 Map、Set 等容器,他們的鍵值需要保證唯一性和一致性,因此,String 的不可變性使其比其他對象更適合當容器的鍵值。
性能
當字符串是不可變時,字符串常量池才有意義。字符串常量池的出現,可以減少創建相同字面量的字符串,讓不同的引用指向池中同一個字符串,為運行時節約很多的堆內存。若字符串可變,字符串常量池失去意義,基于常量池的String.intern()方法也失效,每次創建新的 String 將在堆內開辟出新的空間,占據更多的內存
16、小結
好了,這就是JDK中java.lang.String 類的源碼解析。
-
JAVA
+關注
關注
19文章
2974瀏覽量
105135 -
源碼
+關注
關注
8文章
652瀏覽量
29450 -
JDK
+關注
關注
0文章
82瀏覽量
16636 -
string
+關注
關注
0文章
40瀏覽量
4746
發布評論請先 登錄
相關推薦
JDK 15安裝步驟及新特性
樹莓派如何安裝Java JDK?
java jdk6.0官方下載
探究面試最常見的String、StringBuffer、StringBuilder問題
深入理解java枚舉類型enum用法
java中string不可變的原因
基于java的負載均衡算法解析及源碼分享
java學習—探秘Java中的String、StringBuilder以及StringBuffer
java高級工程師的必備技能有哪些
如何使用Java獲取屬性和環境變量詳細方法說明
基于JDK 1.8來分析Thread類的源碼
JDK中java.lang.Arrays 類的源碼解析





 工商網監
工商網監
評論