 NeurIPS 2023 | 全新的自監督視覺預訓練代理任務:DropPos
NeurIPS 2023 | 全新的自監督視覺預訓練代理任務:DropPos

論文標題:
DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions
論文鏈接:https://arxiv.org/pdf/2309.03576
代碼鏈接:https://github.com/Haochen-Wang409/DropPos
今天介紹我們在自監督視覺預訓練領域的一篇原創工作,目前 DropPos 已被 NeurIPS 2023 接收,相關代碼已開源,有任何問題歡迎在 GitHub 提出。

TL;DR
我們提出了一種全新的自監督代理任務 DropPos,首先在 ViT 前向過程中屏蔽掉大量的 position embeddings(PE),然后利用簡單的 cross-entropy loss 訓練模型,讓模型重建那些無 PE token 的位置信息。這個及其簡單的代理任務就能在多種下游任務上取得有競爭力的性能。

Motivation
在 MoCo v3 的論文中有一個很有趣的現象:ViT 帶與不帶 position embedding,在 ImageNet 上的分類精度相差無幾。

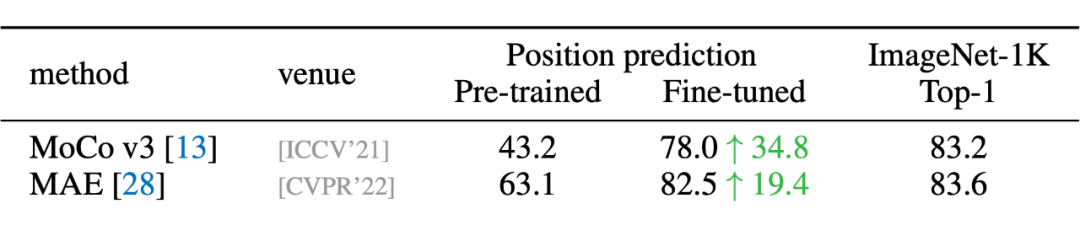
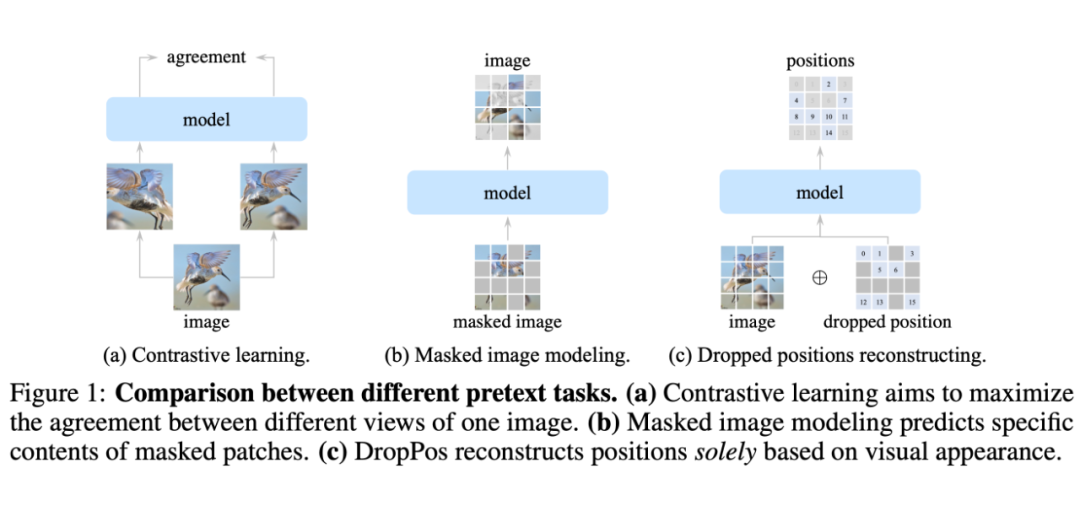
- 對比 CL,DropPos 不需要精心設計的數據增強(例如 multi-crop)。
- 對比 MIM,DropPos 不需要精心設計的掩碼策略和重建目標。

Method

- 如果簡單地把所有 PE 丟棄,讓模型直接重建每個 patch 的位置,會導致上下游的 discrepency。因為下游任務需要 PE,而上游預訓練的模型又完全沒見過 PE。
- ViT 對于 long-range 的建模能力很強,這個簡單的位置重建任務可能沒辦法讓模型學到非常 high-level 的語義特征。
-
看上去相似的不同 patch(例如純色的背景)的位置無需被精準重建,因此決定哪些 patch 的位置需要被重建非常關鍵。
- 針對問題一,我們采用了一個簡單的隨機丟棄策略。每次訓練過程中丟棄 75% 的 PE,保留 25% 的 PE。
- 針對問題二,我們采取了高比例的 patch mask,既能提高代理任務的難度,又能加快訓練的速度。
- 針對問題三,我們提出了 position smoothing 和 attentive reconstruction 的策略。
3.1 DropPos 前向過程

3.2 Objective
我們使用了一個最簡單的 cross-entropy loss 作為預訓練的目標函數:
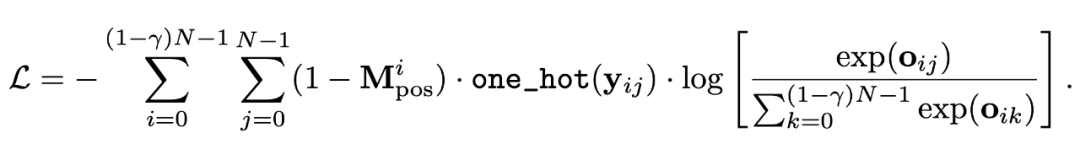
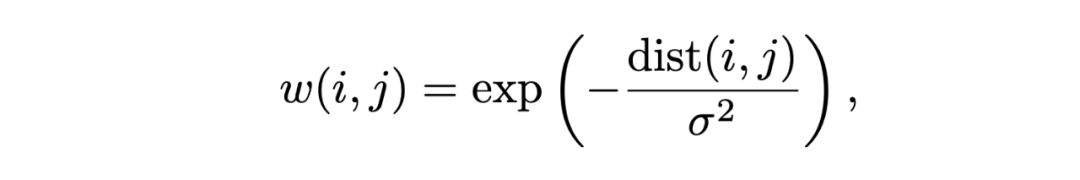
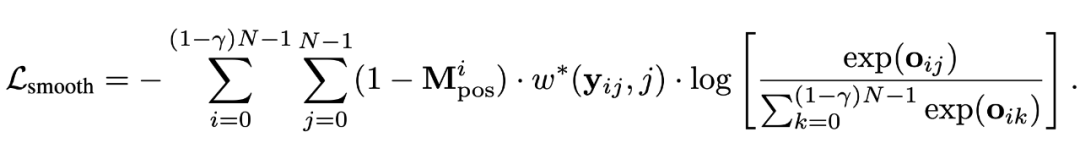 此處,w(i, j) 表示當真實位置為 i,而預測位置為 j 時,平滑后的 position target。
此外,我們還讓 sigma 自大變小,讓模型一開始不要過分關注精確的位置重建,而訓練后期則越來越關注于精準的位置重建。
3.2.2 Attentive Reconstruction
我們采用 [CLS] token 和其他 patch 的相似度作為親和力矩陣,作為目標函數的額外權重。
此處,w(i, j) 表示當真實位置為 i,而預測位置為 j 時,平滑后的 position target。
此外,我們還讓 sigma 自大變小,讓模型一開始不要過分關注精確的位置重建,而訓練后期則越來越關注于精準的位置重建。
3.2.2 Attentive Reconstruction
我們采用 [CLS] token 和其他 patch 的相似度作為親和力矩陣,作為目標函數的額外權重。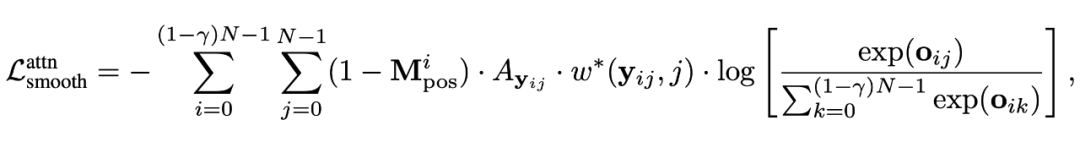
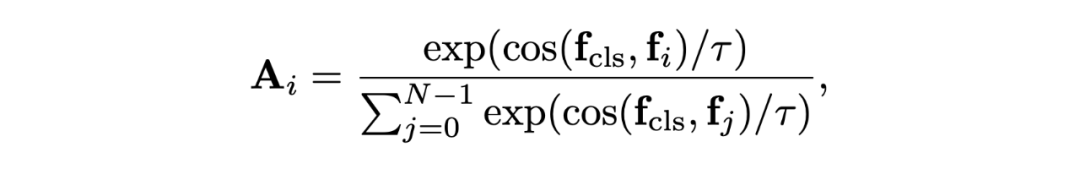 其中 f 為不同 token 的特征,tau 為超參數,控制了 affinity 的平滑程度。
其中 f 為不同 token 的特征,tau 為超參數,控制了 affinity 的平滑程度。

Experiments
4.1 與其他方法的對比

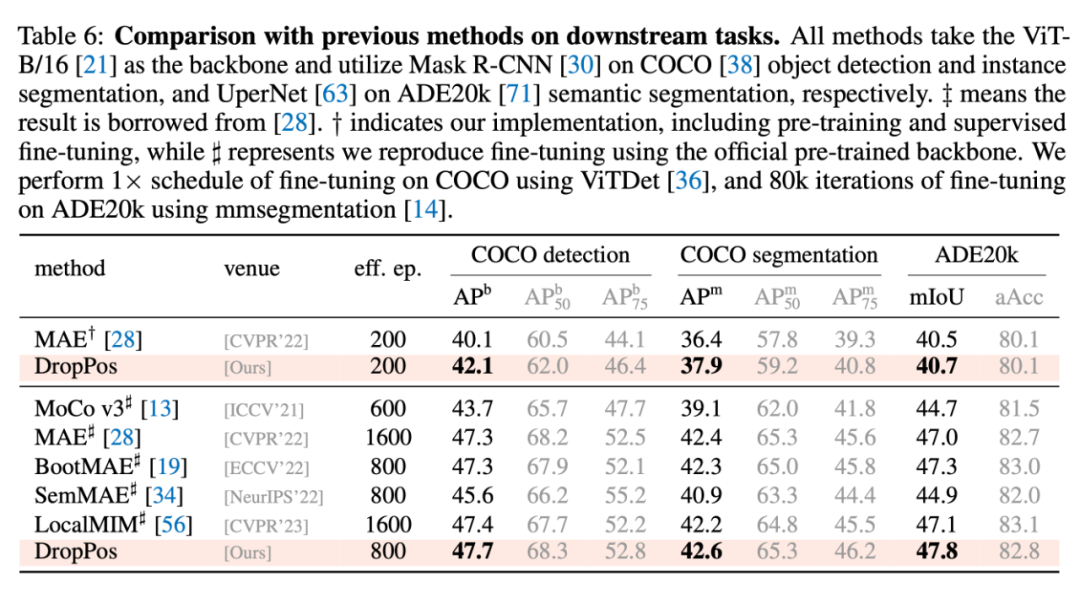
4.2 消融實驗
本文主要有四個超參:patch mask ratio(gamma),position mask ratio(gamma_pos),sigma,和 tau。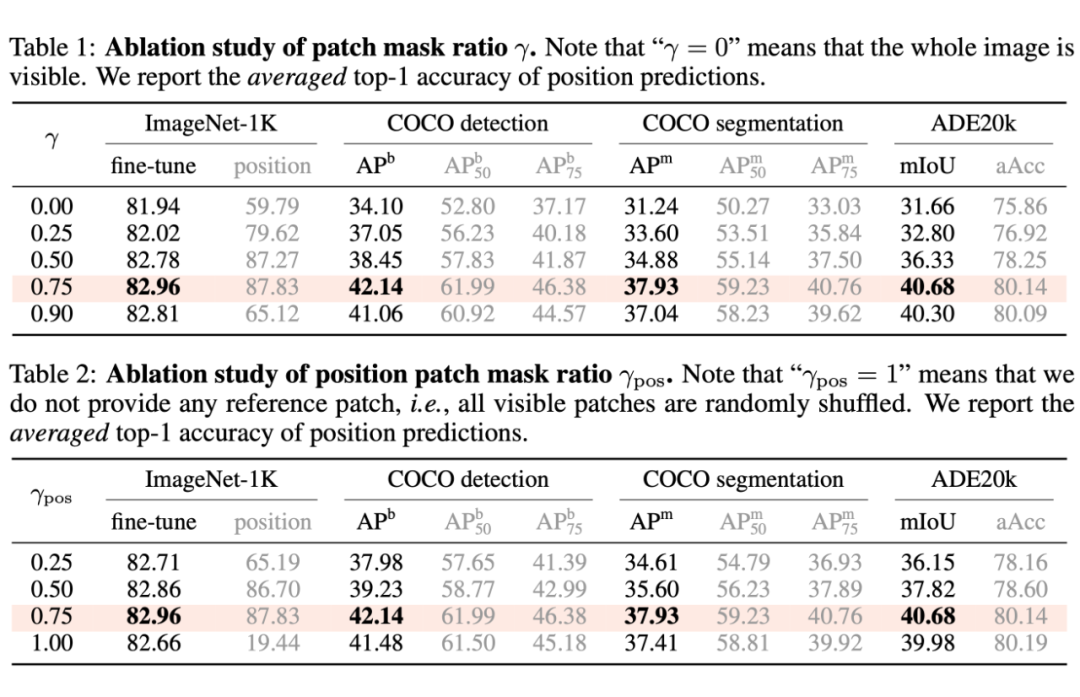
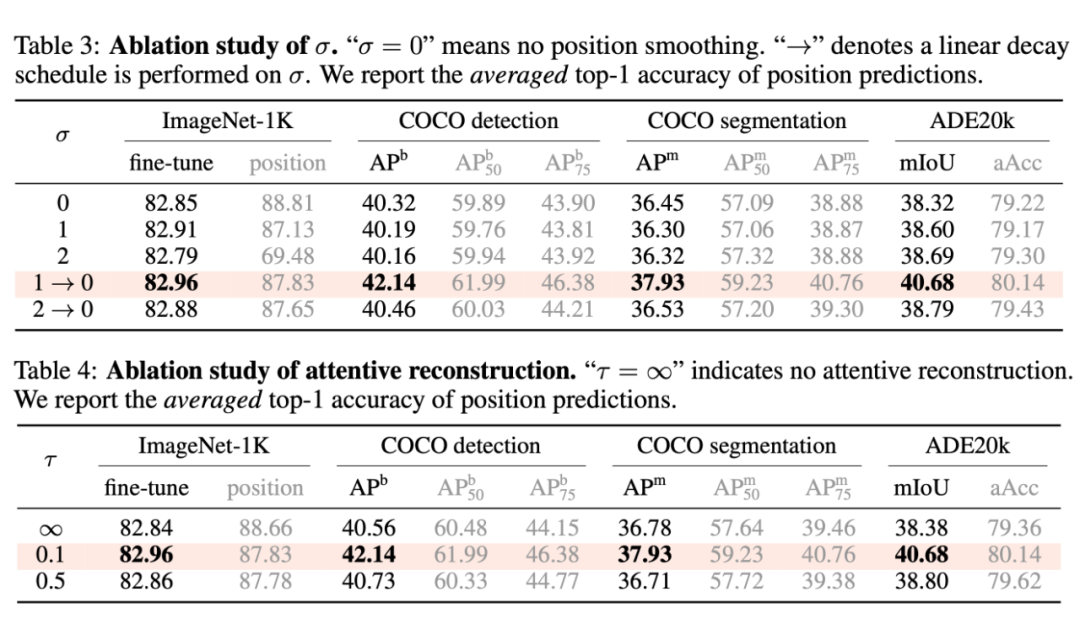 由表,我們可以得出一些比較有趣的結論:
由表,我們可以得出一些比較有趣的結論:
- 一般來說,更高的 position 重建精度會帶來更高的下游任務性能。
- 上述結論存在例外:當 sigma = 0 時,即不做位置平滑時,位置預測精度高,而下游任務表現反而低;當 tau = inf 時,即不做 attentive reconstruction 時,位置預測精度高,而下游表現反而低。
-
因此,過分關注于預測每一個 patch 的精確的位置,會導致局部最優,對于下游任務不利。

聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
物聯網
+關注
關注
2913文章
44928瀏覽量
377055
原文標題:NeurIPS 2023 | 全新的自監督視覺預訓練代理任務:DropPos
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
知行科技大模型研發體系初見效果
11月,知行科技作為共同第一作者提出的Strong Vision Transformers Could BeExcellent Teachers(ScaleKD),以預訓練ViT(視覺
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
模型展示了強大的泛化能力,能夠將在模擬環境學到的技能遷移到真實場景。RT-2的改進版本更是引入了視覺-語言預訓練技術,使模型能夠理解更抽象的任務描述。
第8章通過具體應用案例展現了具身
發表于 12-24 15:03
KerasHub統一、全面的預訓練模型庫
深度學習領域正在迅速發展,在處理各種類型的任務中,預訓練模型變得越來越重要。Keras 以其用戶友好型 API 和對易用性的重視而聞名,始終處于這一動向的前沿。Keras 擁有專用的內容庫,如用
時空引導下的時間序列自監督學習框架
【導讀】最近,香港科技大學、上海AI Lab等多個組織聯合發布了一篇時間序列無監督預訓練的文章,相比原來的TS2Vec等時間序列表示學習工作,核心在于提出了將空間信息融入到預

直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習
神經網絡,特別是預訓練的基礎模型研究得到了廣泛的應用,但其仍然主要依賴于在大量樣本上的批量式訓練。本報告將探討實現模型的增量式訓練,針對深度神經網絡在增量式學習新

蘋果揭示AI新動向:Apple Intelligence模型在谷歌云端芯片上預訓練
蘋果公司在最新的技術論文中披露了一項重要信息,其全新的人工智能系統Apple Intelligence所依賴的模型并非傳統上大型科技公司首選的NVIDIA GPU,而是選擇了在谷歌設計的云端芯片上進行預訓練。這一決定不僅打破了行
預訓練和遷移學習的區別和聯系
預訓練和遷移學習是深度學習和機器學習領域中的兩個重要概念,它們在提高模型性能、減少訓練時間和降低對數據量的需求方面發揮著關鍵作用。本文將從定義、原理、應用、區別和聯系等方面詳細探討預
大語言模型的預訓練
能力,逐漸成為NLP領域的研究熱點。大語言模型的預訓練是這一技術發展的關鍵步驟,它通過在海量無標簽數據上進行訓練,使模型學習到語言的通用知識,為后續的任務微調奠定基礎。本文將深入探討大
LLM預訓練的基本概念、基本原理和主要優勢
理解和生成自然語言的能力,為各種NLP任務提供了強大的支持。本文將詳細介紹LLM預訓練的基本概念、基本原理以及主要優勢,并附上相關的代碼示例。
神經網絡如何用無監督算法訓練
神經網絡作為深度學習的重要組成部分,其訓練方式多樣,其中無監督學習是一種重要的訓練策略。無監督學習旨在從未標記的數據中發現數據內在的結構、模式或規律,從而提取有用的特征表示。這種
預訓練模型的基本原理和應用
預訓練模型(Pre-trained Model)是深度學習和機器學習領域中的一個重要概念,尤其是在自然語言處理(NLP)和計算機視覺(CV)等領域中得到了廣泛應用。預
【大語言模型:原理與工程實踐】大語言模型的預訓練
大語言模型的核心特點在于其龐大的參數量,這賦予了模型強大的學習容量,使其無需依賴微調即可適應各種下游任務,而更傾向于培養通用的處理能力。然而,隨著學習容量的增加,對預訓練數據的需求也相應
發表于 05-07 17:10
【大語言模型:原理與工程實踐】大語言模型的基礎技術
就無法修改,因此難以靈活應用于下游文本的挖掘中。
詞嵌入表示:將每個詞映射為一個低維稠密的實值向量。不同的是,基于預訓練的詞嵌入表示先在語料庫中利用某種語言模型進行預訓練,然后將其應
發表于 05-05 12:17
【大語言模型:原理與工程實踐】核心技術綜述
其預訓練和微調,直到模型的部署和性能評估。以下是對這些技術的綜述:
模型架構:
LLMs通常采用深層的神經網絡架構,最常見的是Transformer網絡,它包含多個自注意力層,能夠捕捉輸入數據中
發表于 05-05 10:56
名單公布!【書籍評測活動NO.30】大規模語言模型:從理論到實踐
榜銷售TOP1的桂冠,可想大家對本書的認可和支持!
這本書為什么如此受歡迎?它究竟講了什么?下面就給大家詳細~~
本書主要內容
本書圍繞大語言模型構建的四個主要階段——預訓練、有監督微調、獎勵建模
發表于 03-11 15:16





 工商網監
工商網監
評論