 AI網絡未來十年以太網交換機市場的增長動力嗎?
AI網絡未來十年以太網交換機市場的增長動力嗎?
根據 IDC 的數據,2022 年,AI 網絡市場已達到 20億美元,其中 InfiniBand 貢獻了 75% 的收入。2023 年AI 基礎設施建設投資將達到 1540億美元,到 2026 年將增長到 3000億美元。展望 2027 年,AI 網絡的收入將飆升至超過 100億美元,其中以太網將超過 60億美元。以太網和 InfiniBand 都將在此期間強勁增長。與此同時,AI 工作負載的帶寬每年增長將超過 100%,遠高于數據中心每年 30-40% 的帶寬增長。此外,AI 將成為未來十年以太網交換機市場最重要的增長動力。
隨著AI 的持續火熱,其工作負載也呈指數級增長,網絡基礎設施正面臨極限。AI 基礎設施建設需要支持運行在單個計算和存儲節點上的大型復雜工作負載,這些節點作為邏輯集群一起工作。AI 網絡通過大容量互聯結構連接這些大型工作負載。
01
AI 工作負載
AI 工作負載與傳統數據中心網絡有著根本的不同,雖然超大規模數據中心和 AI /HPC集群之間有很多相似之處,但超大規模數據中心使用的解決方案不足以解決AI /HPC工作負載帶來的額外復雜性。AI網絡有著以下特征:
并行計算:AI 工作負載是運行相同應用程序、相同計算任務的多臺機器之間統一的基礎設施;
規模:此類任務的規模可以達到數千個計算引擎(例如GPU、CPU、FPGA 等);
作業類型:不同的任務在大小、運行時間、數據集大小和數量、生成答案的類型、用于編碼應用程序的不同語言和運行它的硬件類型等方面有所不同,都會導致為運行AI 工作負載而構建的網絡流量模式不斷變化;
延遲:延遲是影響作業完成時間(JCT)的重要因素之一。然而,由于此類并行工作負載在多臺機器上運行,因此延遲取決于響應最慢的機器;
無損:遲到的響應會延遲整個應用程序。在傳統數據中心中,消息丟失將導致重新傳輸,而在AI 工作負載中,消息丟失意味著整個計算要么錯誤,要么卡住。正是由于這個原因,AI 網絡需要無損行為;
帶寬:AI 應用的數據集很大。高帶寬流量需要在服務器之間運行,以便應用程序能夠獲取數據。在現代部署中,AI /HPC計算功能的每個計算引擎的接口速度都達到 400Gbps。
02
AI 集群網絡
AI 集群通常有兩個不同的網絡。第一種網絡,也是比較傳統的,是所有服務器的外部或面向外部的“前端”網絡,當它們面向公共互聯網時,需要基于以太網和IP協議。AI 的主要區別在于需要將大量數據輸入集群,因此管道比傳統的網絡服務器大得多。未來的 AI 設計將驅動每臺服務器多個 112G SERDES 通道,表現為 100 G 或 400 G 端口。
第二種是“后端”網絡,這是一個將AI 集群資源連接在一起的獨特網絡。對于AI 集群來說,跨計算資源連接到其共享存儲和內存,并快速且沒有延遲偏差地執行這些任務,對于最大化集群性能至關重要。未來這種新網絡的AI 設計將是每個計算服務器有多個 400 G、800 G 或更高端口。
AI 工作負載嚴重依賴于后端網絡。由于一個工作負載在多臺服務器上運行,因此需要高帶寬、無抖動和無數據包丟失,以確保最高的 GPI 利用率。網絡性能的任何下降都會影響JCT。這就需要一個可預測的、無損的后端網絡解決方案,這對任何網絡技術來說都是一個重大挑戰。
隨著AI 工作負載的快速增長,AI 集群結構中使用的網絡解決方案需要不斷發展,以最大限度地利用昂貴的AI 資源。
03
AI網絡行業解決方案
如何設計高效的AI 集群組網方案,滿足低時延、高吞吐的機間通信,從而降低多機多卡間數據同步的通信耗時,提升 GPU 有效計算時間占比(GPU 計算時間/整體訓練時間),對于 AI 網絡互聯至關重要。下文展示了部分AI高性能網絡行業解決方案。
騰訊星脈網絡
6月,騰訊云首次完整披露自研星脈高性能計算網絡。據稱,星脈網絡具備3.2T通信帶寬,能提升40%的GPU利用率,節省30%~60%的模型訓練成本,為AI大模型帶來10倍通信性能提升。基于騰訊云新一代算力集群HCC,可支持10萬卡的超大計算規模。
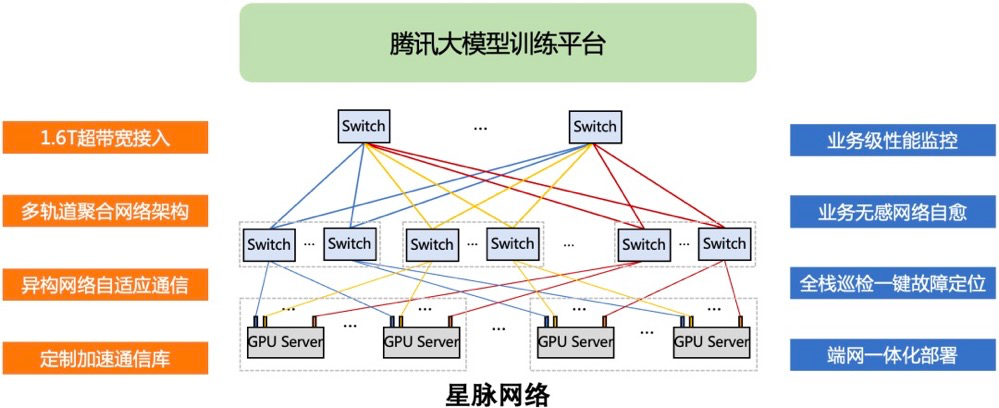
在硬件方面,星脈網絡基于騰訊的網絡研發平臺,采用全自研設備構建互聯底座,實現自動化部署和配置。在軟件方面,騰訊云自研的TiTa網絡協議,采用先進的擁塞控制和管理技術,能夠實時監測并調整網絡擁塞,滿足大量服務器節點之間的通信需求,確保數據交換流暢、延時低,使集群通信效率達90%以上。
華為星河AI網絡
華為新一代星河AI網絡解決方案,旨在提供一種高效、可靠、安全的數據中心網絡解決方案,以支持大規模數據中心的數字化轉型。華為星河AI網絡解決方案整體技術棧,圍繞超高吞吐、長穩可靠和彈性高并發等核心目標來構建關鍵技術:
超高吞吐:基于華為獨創的全局負載均衡NSLB算法、自動化開局和全棧可視運維技術實現算網實時協同調度,將網絡有效吞吐從業界的50%提升到98%,大模型訓練效率提升20%。
長穩可靠:利用全棧可視運維黑科技,實現大模型訓練網絡路徑、流負載實時可視;結合Packet Event數據面異常感知技術和DPFR故障無感自愈技術,實現亞毫秒級故障快速收斂。
彈性高并發:基于華為獨創的多路徑智能調度、流感知均衡調優和自適應抗丟包技術,實現 “T級數據小時達”,轉發運力提升8倍。
阿里可預期高性能網絡
阿里云基礎設施事業部推出的可預期網絡(Predictable Network)可滿足計算任務中的過程數據高效交換需求,是大規模RDMA網絡部署實踐中不斷總結并創新而來的網絡技術體系。相比于傳統網絡的“盡力而為”,可預期網絡的概念代表了應用場景對網絡服務質量更高的要求,讓吞吐率、時延等關鍵性能指標“可預期”,具備質量保證(QoS)。
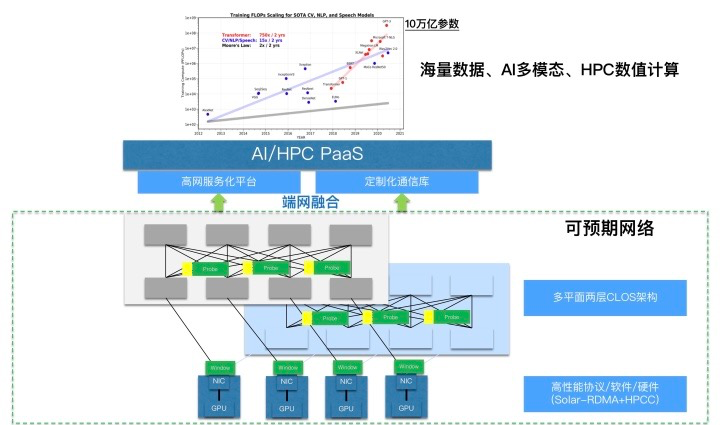
阿里云高性能可預期數據中心網絡的核心技術包括:
自研High Performance Network(HPN)高性能網絡架構;
基于自研交換機和智能網卡的端網融合核心技術體系;
統一的高性能網絡服務平臺,Network Unified Service Architecture (NUSA)。
阿里云可預期網絡技術體系在架構設計、傳輸協議、通信庫、網絡資源調度、網絡容器、服務化等維度展開,正在通過智能計算靈駿,為人工智能、大數據分析、高性能計算等高密度計算場景提供服務。
百度AIPod高性能網絡
百度認為 AI 高性能網絡有三大目標:超大規模、超高帶寬以及超長穩定,基于這樣的目標,百度有針對性地設計了 AI 大底座里面的 AI 高性能網絡—— AIPod。
百度AI 高性能網絡 AIPod有約 400 臺交換機、3000 張網卡、10000 根線纜和 20000 個光模塊。其中僅線纜的總長度就相當于北京到青島的距離。AIPod 網絡采用 3 層無收斂的 CLOS 組網結構。
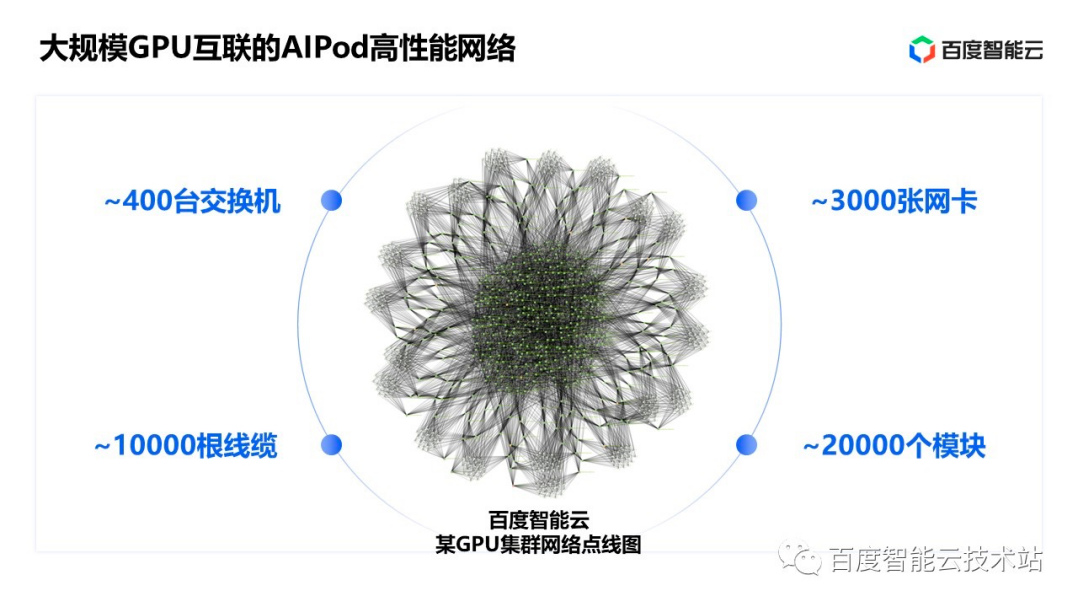
AIPod 高性能網絡也是百度智能云 AI 大底座中百度百舸的底層關鍵技術,決定了大模型訓練的能力和效率。大規模、高帶寬、長穩定的 AIPod 高性能網絡能夠幫助用戶更高效率、更低成本的訓練自己的大模型。
除此之外,像三大運營商、思科、英特爾、博通、谷歌、新華三、中興、銳捷、青云等公司都有針對AI的不同應用場景推出不同的行業解決方案,感興趣的朋友可以閱讀《盤點:AI 大模型背后不同玩家的網絡支撐》。
審核編輯:劉清
-
以太網
+關注
關注
40文章
5460瀏覽量
172743 -
gpu
+關注
關注
28文章
4777瀏覽量
129360 -
交換機
+關注
關注
21文章
2656瀏覽量
100181 -
HPC
+關注
關注
0文章
324瀏覽量
23853 -
SerDes
+關注
關注
6文章
201瀏覽量
35048
原文標題:AI網絡,未來十年以太網交換機市場的增長動力
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
交換機與以太網怎么連接
以太網交換機高穩定性時鐘系統應用方案
以太網交換機CTA進網許可認證有哪些申請條件?

虹科應用 增強型以太網交換機:如何實現同IP控制的高效網絡管理?
工業交換機與工業以太網的區別
如何使用以太網交換機最大限度地減少網絡延遲
如何使用托管型以太網交換機為 IIoT 實現安全的時間敏感網絡
工業以太網交換機節能的必要性與實施策略

工業以太網交換機 vs. 常規以太網交換機:全面詳細比較

2023年全球以太網交換機市場最新排名出爐!





 工商網監
工商網監
評論