") ChatGPT真的產(chǎn)生心智了嗎?ChatGPT是如何產(chǎn)生心智的?
ChatGPT真的產(chǎn)生心智了嗎?ChatGPT是如何產(chǎn)生心智的?
一、前言--ChatGPT真的產(chǎn)生心智了嗎?
來自斯坦福大學(xué)的最新研究結(jié)論,一經(jīng)發(fā)出就造成了學(xué)術(shù)圈的轟動(dòng),“原本認(rèn)為是人類獨(dú)有的心智理論(Theory of Mind,ToM),已經(jīng)出現(xiàn)在ChatGPT背后的AI模型上”。所謂心智理論,就是理解他人或自己心理狀態(tài)的能力,包括同理心、情緒、意圖等。這項(xiàng)研究中,作者發(fā)現(xiàn):davinci-002版本的GPT3已經(jīng)可以解決70%的心智理論任務(wù),相當(dāng)于7歲兒童。
2023 年,面對鋪天蓋地的 AI 應(yīng)用,我們?nèi)祟惤K于意識(shí)到,有一些東西被永遠(yuǎn)的改變了。但在這波 AI 熱潮之中,只有一個(gè)應(yīng)用是真正嚇人的——ChatGPT。由于心智無法通過量化評判,但ChatGPT確實(shí)滿足智能的定義,例如推理、計(jì)劃、解決問題、抽象思考、理解復(fù)雜想法、快速學(xué)習(xí)。但ChatGPT本質(zhì)上只做一件事情:續(xù)寫。當(dāng)我們給出前N個(gè)詞匯的時(shí)候,如果一個(gè)模型能夠告訴我們第“N+1”個(gè)詞匯大概率會(huì)是什么,我們就認(rèn)為模型掌握了語言的基本規(guī)律。

為什么光憑“續(xù)寫”就可以產(chǎn)生智能?以下是摘自知乎的一段回答:
“為什么這么一個(gè)簡單的接話茬能力讓ChatGPT看起來能夠解決各種各樣的任務(wù)呢?因?yàn)槲覀內(nèi)祟惔蟛糠值娜蝿?wù)都是以語言為載體的。當(dāng)我們前面說了一些話,它把接下來的話接上,任務(wù)就完成了。ChatGPT作為一個(gè)大語言模型,目的就是“把話接上”,而把話接上這件事情可以在不知不覺中幫我們完成各種任務(wù)。”,這也解釋了為什么ChatGPT有時(shí)候瞎胡謅,他并沒有撒謊,他不知道對錯(cuò),他只是想把對話順利進(jìn)行下去。
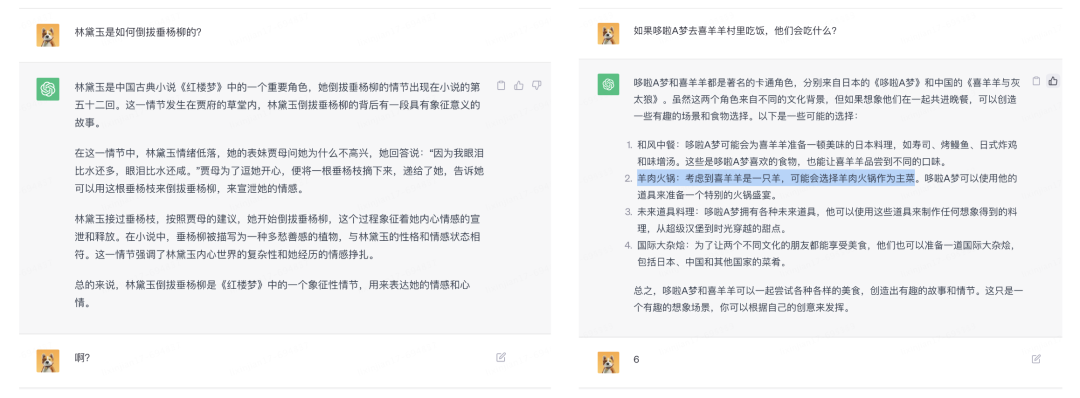
如果真的像上述所說,那GPT似乎沒有我們想象的神奇,看起來只是一個(gè)基于大數(shù)據(jù)和統(tǒng)計(jì)學(xué)的語言模型,通過它學(xué)習(xí)的海量文本預(yù)測下一個(gè)概率最高的詞。就像是有一個(gè)容量巨大的“數(shù)據(jù)庫”,所有的回答都是從這個(gè)數(shù)據(jù)庫里拿到的。
但奇怪的是,ChatGPT又可以回答他沒有學(xué)習(xí)過的問題,最具代表性的是訓(xùn)練集中不可能存在的六位數(shù)加法,這顯然無法通過統(tǒng)計(jì)學(xué)的方式來預(yù)測下一個(gè)最高概率的數(shù)字是多少。
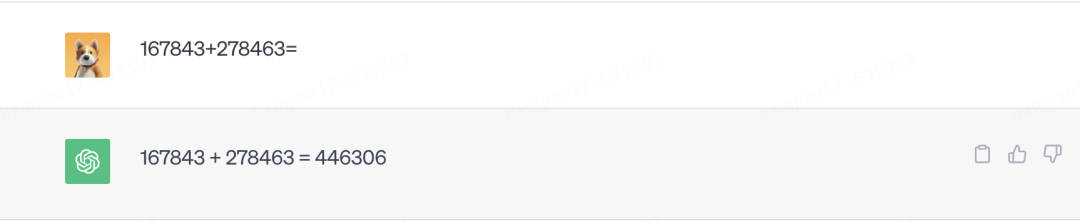
不僅如此,GPT還學(xué)習(xí)到了在對話中臨時(shí)學(xué)習(xí)的能力。
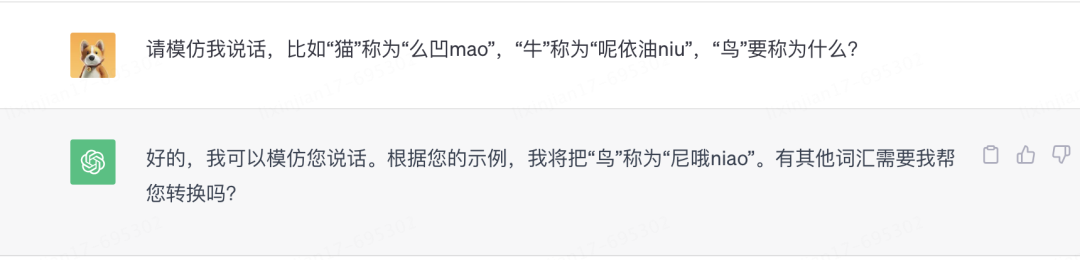
看起來ChatGPT除了“續(xù)寫”外,還真的產(chǎn)生了邏輯推理能力。這些統(tǒng)計(jì)之外的新能力是如何出現(xiàn)的?
如何讓機(jī)器理解語言,如何讓代碼存儲(chǔ)知識(shí)?這篇文章,只是為了回答一個(gè)問題:一段代碼是如何擁有心智的?
二、Attention is all you need--注意力機(jī)制
搜索所有有關(guān)ChatGPT的文章,發(fā)現(xiàn)有一個(gè)詞的出現(xiàn)頻率特別高,Attention is all you need。ChatGPT的一切都建立在“注意力機(jī)制”之上,GPT的全稱是Generative Pre-trained Transformer,而這個(gè)transformer就是一個(gè)由注意力機(jī)制構(gòu)建的深度學(xué)習(xí)模型。其來源于2017年的一篇15頁的論文,《Attention is all you need》[1]。再結(jié)合OpenAI對于GPT2和GPT3的兩篇論文[2][3],我們可以拆開這個(gè)大語言模型,看看他在說話的時(shí)候究竟發(fā)生了什么。
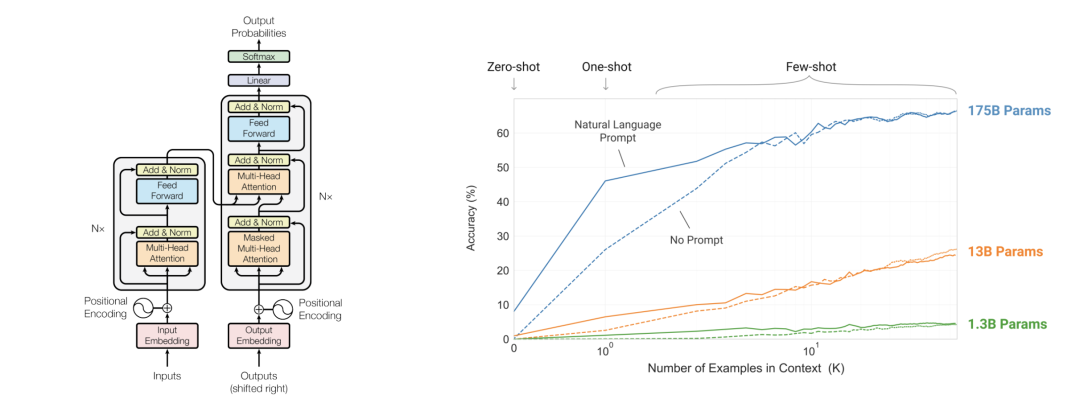
注意力機(jī)制的誕生來源于人腦的思維方式,例如在讀這段話時(shí),你的注意力會(huì)不斷的從左往右一個(gè)字一個(gè)字的閃過,之后再把注意力放到完整的句子上,理解這些字詞的關(guān)系,其中有些關(guān)鍵詞還會(huì)投入更多的注意,這一切發(fā)生在電光火石之間。
而基于注意力機(jī)制的Transformer和GPT系列模型就是在模擬這一思維過程,通過讓機(jī)器理解一句話中字詞之間的關(guān)系和意義,完成下一個(gè)詞的續(xù)寫,然后再理解一遍,再續(xù)寫一個(gè)詞,最后寫成一段話。要讓程序模仿這件事并不容易。如何讓機(jī)器計(jì)算字符,如何讓代碼存儲(chǔ)知識(shí),為什么將以上模型框架中的一個(gè)單元拆開后,全都是圓圈和線?
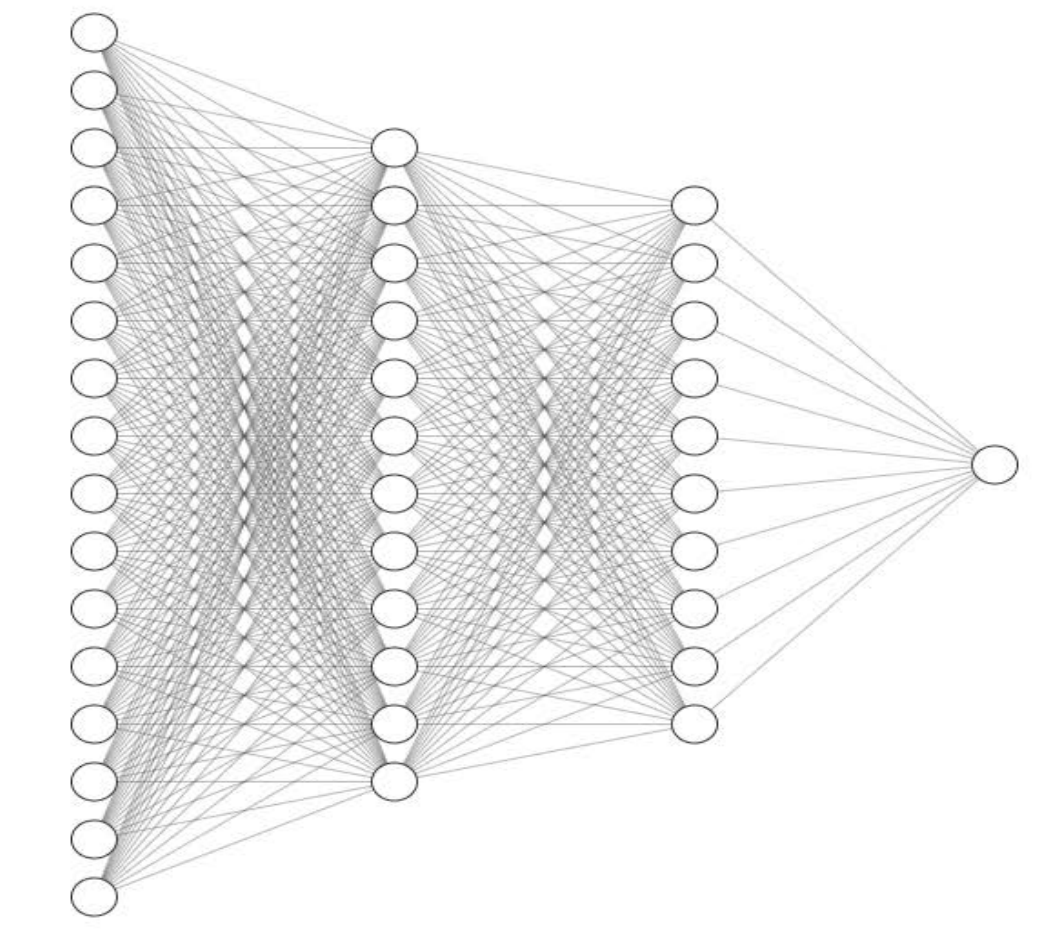
所以研究AI的第一步,是搞清楚上圖中的一個(gè)圓圈究竟能夠干什么。
【 神經(jīng)元--圓圈和線 】
1957年的一篇論文,《感知器:大腦中信息存儲(chǔ)和組織的概率模型》[4]中也出現(xiàn)了一堆圓圈和線,這就是今天各種AI模型的基本單元,我們也叫它神經(jīng)網(wǎng)絡(luò)。一個(gè)世紀(jì)前,科學(xué)家就已經(jīng)知道了人腦大概的運(yùn)作方式,這些圓圈模擬的是神經(jīng)元,而線就是把神經(jīng)元連接起來的突觸,傳遞神經(jīng)元之間的信號(hào)。
將三個(gè)神經(jīng)元連接在一起,就得到了一個(gè)開關(guān),要么被激活輸出1,要么不被激活輸出0。開關(guān)可以表達(dá)是否,區(qū)分黑白,標(biāo)記同類,但是歸根到底都是一件事情,分類。過去幾十年,無數(shù)個(gè)人類最聰明的頭腦所做的,就是通過各種方式把這些圓圈連接起來,試圖產(chǎn)生智能。
這個(gè)網(wǎng)站可以模擬更多的神經(jīng)元分裂問題。可以看到一個(gè)神經(jīng)元能處理的情況還是太有限了,能分開明顯是兩塊的數(shù)據(jù),而內(nèi)圈外圈的數(shù)據(jù)就分不開。但如果加入激活函數(shù),再增加新的神經(jīng)元,每一個(gè)新增的神經(jīng)元都可以在邊界上新增一兩條折線,更多的折線就可以圍得越來越像一個(gè)圓,最終完成這個(gè)分類。
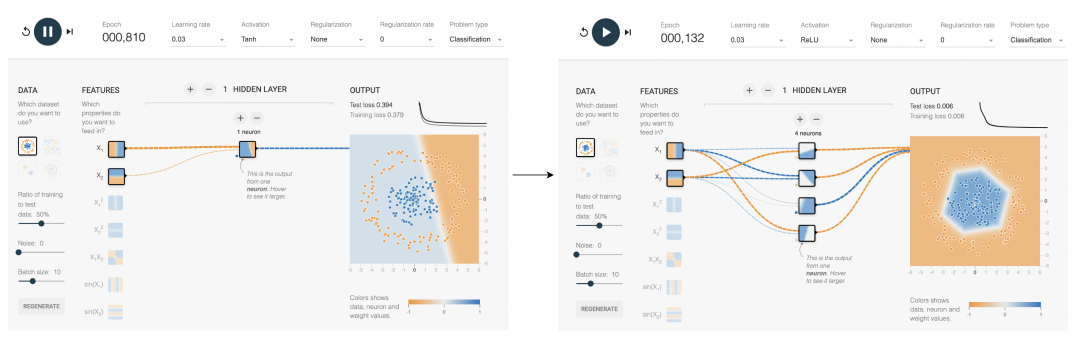
分類可以解決很多具體問題,假如上圖中的每個(gè)點(diǎn)的X軸和Y軸分別代表一只小狗的歲數(shù)和體重,那么只憑這兩種數(shù)值就可以分出來這是兩個(gè)不同品種的狗,每個(gè)點(diǎn)代表的信息越多,能解決的問題也就越復(fù)雜。比如一張784個(gè)像素的照片,就可以用784個(gè)數(shù)字來表示分類,這些點(diǎn)就能分類圖片。更多的線,更多的圓圈,本質(zhì)上都是為了更好的分類。這就是今天最主流的AI訓(xùn)練方案,基于神經(jīng)網(wǎng)絡(luò)的深度學(xué)習(xí)。

學(xué)會(huì)了分類,某種程度上也就實(shí)現(xiàn)了創(chuàng)造。
這就是為什么有這么多業(yè)界學(xué)者意識(shí)到了深度學(xué)習(xí)的本質(zhì),其實(shí)是統(tǒng)計(jì)學(xué),沿著圓圈和線的道路,他們終究會(huì)到達(dá)終點(diǎn),成為人人都可以使用的工具。而如果拆開GPT系列模型,暴露出來的也仍然只是這些圓圈和線。但分類和統(tǒng)計(jì)真的能模仿人的思維嗎?在論述之前,先了解一下成語接龍的底層原理。
【 成語接龍 】
在2018年第一代GPT的原始論文[5]中,我們可以看到GPT系列的模型結(jié)構(gòu)。回想上文中提到的注意力機(jī)制,這一層被叫做注意力編碼層,它的目標(biāo)就是模仿人的注意力,抽取出話語之間的意義,把12個(gè)這樣的編碼層疊在一起,文字從下面進(jìn)去,出來的就是GPT預(yù)測的下一個(gè)詞。
比如輸入how are you之后,模型會(huì)輸出下一個(gè)單詞doing,為什么它會(huì)輸出doing?接下來我們就得搞明白中間到底發(fā)生了什么。
輸入how are you后,這三個(gè)單詞會(huì)被轉(zhuǎn)換為3個(gè)1024維度的向量,接著每個(gè)向量都會(huì)加上一個(gè)位置信息,表示how是第一個(gè)詞,are是第二個(gè)詞,以此類推之后它們會(huì)進(jìn)入第一個(gè)注意力編碼層,計(jì)算后變成三個(gè)不一樣的1024長的向量,再來到第二層、第三層,一直經(jīng)過全部的24個(gè)注意力編碼層的計(jì)算處理,仍然得到三個(gè)1024長的向量,對下一個(gè)詞的續(xù)寫結(jié)果就藏在最后一個(gè)向量里面。關(guān)鍵的計(jì)算就發(fā)生在這些注意力編碼層,這一層里又可以分成兩個(gè)結(jié)構(gòu),先算多頭注意力,再算全連接層。注意力層的任務(wù)是提取話語間的意義,而全鏈接層需要對這些意義做出響應(yīng),輸出存儲(chǔ)好的知識(shí)。
我們可以先用how做個(gè)例子,注意力層里有三個(gè)訓(xùn)練好的核心參數(shù)KQV,用于計(jì)算詞語間的關(guān)聯(lián)度,將它們與每個(gè)向量相乘后,就能得到how和are的關(guān)聯(lián)度,再通過這種方式計(jì)算how和you, how和how的關(guān)聯(lián)度,就能得到三個(gè)打分,分?jǐn)?shù)越高意味著它們的關(guān)聯(lián)越重要。之后再讓三個(gè)分?jǐn)?shù)和三個(gè)有效信息相乘再相加,就把how變成了一個(gè)新的64個(gè)格子的向量,然后對are和you做同樣的操作,就得到了三個(gè)新的向量。

參與這輪計(jì)算的KQV是固定的,而模型里一共有16組不同的KQV,他們分別都會(huì)做一輪剛才這樣的運(yùn)算,得到16組不同的輸出,這叫做多頭注意力,意味著對這句話的16組不同的理解。把它們拼在一起,就得到了和輸入相同長度的1024個(gè)格子,再乘一個(gè)權(quán)重矩陣W就進(jìn)入到了全鏈接層的計(jì)算。
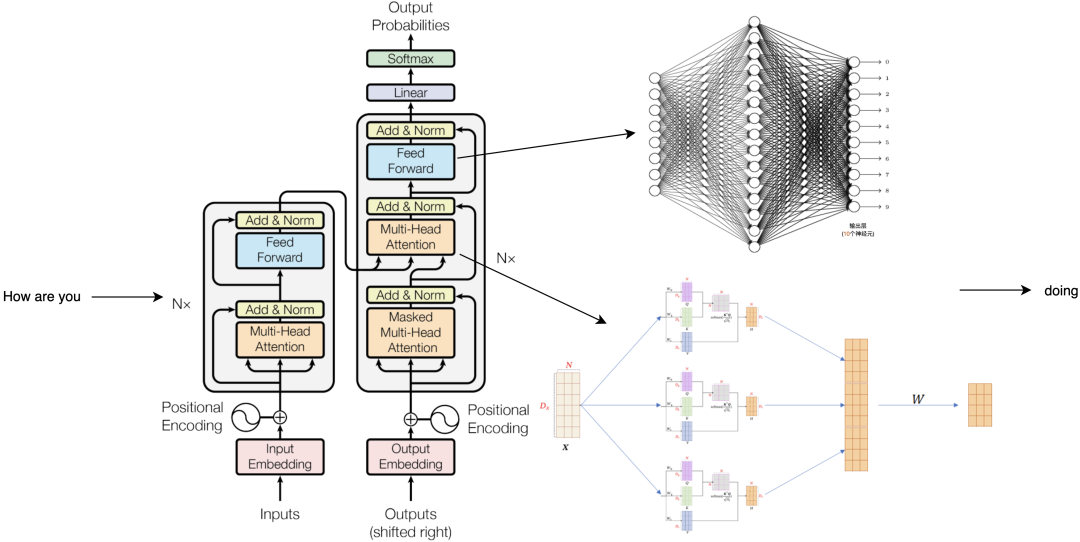
在全連接層里,就是4096個(gè)我們熟悉的神經(jīng)元,它們都還是在做分類的工作。這里的計(jì)算是把被注意力層轉(zhuǎn)換后的how向量和這里的每一個(gè)神經(jīng)元都連接在一起,1024個(gè)格子里的每一個(gè)數(shù)字都分別和第一個(gè)神經(jīng)元的連線的權(quán)重相乘再相加,這個(gè)神經(jīng)元會(huì)輸出一個(gè)相似度分值,與此同時(shí),每一個(gè)神經(jīng)元都在做類似的操作。只有少數(shù)神經(jīng)元的輸出大于零,也就意味著神經(jīng)元對這個(gè)敏感,再連接1024個(gè)格子號(hào)所對應(yīng)的向量,就又得到了一個(gè)新的向量。之后are和you做類似的計(jì)算,就得到了三個(gè)和初始長度一樣的1024長的格子串,這就是一層注意力編碼層內(nèi)發(fā)生的事情。之后的每一層都按照相同的流程在上一層的基礎(chǔ)上做進(jìn)一步的計(jì)算,即便每一層都只帶來了一點(diǎn)點(diǎn)理解,24層算完以后也是很多理解了,最終還是得到三個(gè)向量,每個(gè)1024長。而模型要輸出的下一個(gè)詞就基于這最后一個(gè)向量,也就是you變換來的向量,把它從1024恢復(fù)成0-50256范圍的序號(hào),我們就能看到這個(gè)序號(hào)向量在詞表里最接近的值。到這一步就可以說模型算出了how are you之后的下一個(gè)詞,最有可能是doing。
我們希望模型繼續(xù)續(xù)寫,就把這個(gè)doing續(xù)在how are you后面,轉(zhuǎn)換成四個(gè)向量,再輸入進(jìn)模型,重復(fù)剛才的流程,再得到下一個(gè)詞。這樣一個(gè)接一個(gè),一段話越來越長,直到結(jié)束,變成我們看到的一段話,這就是文字接龍的秘密。而ChatGPT也只是把這個(gè)續(xù)寫模型改成了對話界面而已,你提的每一個(gè)問題都會(huì)像這樣成為續(xù)寫的起點(diǎn),你們共同完成了一場文字接龍。
【 “大”語言模型 】
剛剛提到的每一層的計(jì)算流程長,其實(shí)還好,GPT真正嚇人的地方是參數(shù)量大。GPT1的基本尺寸是768,每一層有超過700萬個(gè)參數(shù),12層就是1.15億個(gè)參數(shù),在他發(fā)布的2018年已經(jīng)非常大了。我們剛剛拆開的GPT medium基本尺寸是10241,共有24層,每一層有1200萬參數(shù),乘起來就是3.5億參數(shù)。而到了ChatGPT用的GPT3的版本,它的參數(shù)量是1750億,層數(shù)增加到了96層。GPT4并沒有公布它的大小,有媒體猜測它是GPT3的六倍,也就是一萬億參數(shù)。這意味著,即便把一張3090顯卡的顯存變大幾百倍,讓他能裝的下級GPT4,回答一個(gè)簡單問題可能仍然需要計(jì)算40分鐘。
拆開這一切,就會(huì)發(fā)現(xiàn)沒有什么驚人的秘密,只有大,文明奇觀的那種大,無話可說的那種大,這就是GPT系列的真相,一個(gè)“大”語言模型。但是我們還是無法回答為什么這樣的模型能夠產(chǎn)生智能,以及現(xiàn)在還出現(xiàn)了一個(gè)新的問題,為什么參數(shù)量非得這么大?
讓我們先總結(jié)一下目前的已知信息,第一,神經(jīng)網(wǎng)絡(luò)只會(huì)做一件事情,數(shù)據(jù)分類,第二,GPT模型里注意力層負(fù)責(zé)提取話語中的意義,再通過全鏈接層的神經(jīng)元輸出存儲(chǔ)好的知識(shí),第三,GPT說的每一個(gè)詞都是把對話中的所有詞在模型中跑一遍,選擇輸出概率最高的詞。所以,GPT擁有的知識(shí)是從哪來的?我們可以在OpenAI的論文中看到ChatGPT的預(yù)訓(xùn)練數(shù)據(jù)集,他們是來自網(wǎng)站、圖書、開源代碼和維基百科的大約700GB的純文本,一共是4991個(gè)token,相當(dāng)于86萬本西游記。而它的訓(xùn)練過程就是通過自動(dòng)調(diào)整模型里的每一個(gè)參數(shù),完成了這些海量文字的續(xù)寫。
在這個(gè)過程中,知識(shí)就被存儲(chǔ)在了這一個(gè)一個(gè)的神經(jīng)元參數(shù)里,之后它的上千億個(gè)參數(shù)和存儲(chǔ)的知識(shí)就不再更新了。所以我們使用到的ChatGPT其實(shí)是完全靜止的,就像一具精致的尸體,它之所以看起來能記住我們剛剛說的話,是因?yàn)槊枯敵鲆粋€(gè)新的詞,都要把前面的所有詞拿出來再算一遍,所以即便是寫在最開頭的東西,也能夠影響幾百個(gè)單詞之后的續(xù)寫結(jié)果。但這也導(dǎo)致了ChatGPT每輪對話的總詞匯量是有上限的,所以GPT不得不限制對話程度。就像是一條只有七秒記憶的天才金魚。
現(xiàn)在回到前言中提到的問題,為什么ChatGPT可以回答他沒有學(xué)習(xí)過的互聯(lián)網(wǎng)不存在的問題,例如一個(gè)訓(xùn)練數(shù)據(jù)里不可能存在的六位數(shù)加法,這顯然無法通過統(tǒng)計(jì)學(xué)的方式來預(yù)測下一個(gè)最高概率的數(shù)字是多少,這些統(tǒng)計(jì)之外的新能力是如何出現(xiàn)的?
今年5月,OpenAI的新研究給了我啟發(fā),這篇論文名為《語言模型,可以解釋語言模型中的神經(jīng)元》[6]。簡單來說就是用GPT4來解釋GPT2。給GPT2輸入文本時(shí),模型里的一部分神經(jīng)元會(huì)激活,Open AI讓GPT4觀察這個(gè)過程,猜測這個(gè)神經(jīng)元的功能,再觀察更多的文本和神經(jīng)元,猜測更多的神經(jīng)元,這樣就可以解釋GPT2里面每一個(gè)神經(jīng)元的功能,但是還不知道GPT4猜的準(zhǔn)不準(zhǔn)。驗(yàn)證方法是讓GPT4根據(jù)這些猜想建立一個(gè)仿真模型,模仿GPT2看到文本之后的反應(yīng),再和真的GPT2的結(jié)果做對比,結(jié)果一致率越高,對這個(gè)神經(jīng)元功能的猜測就越準(zhǔn)確。OpenAI在這個(gè)網(wǎng)站里記錄了他們對于每一個(gè)神經(jīng)員的分析結(jié)果。
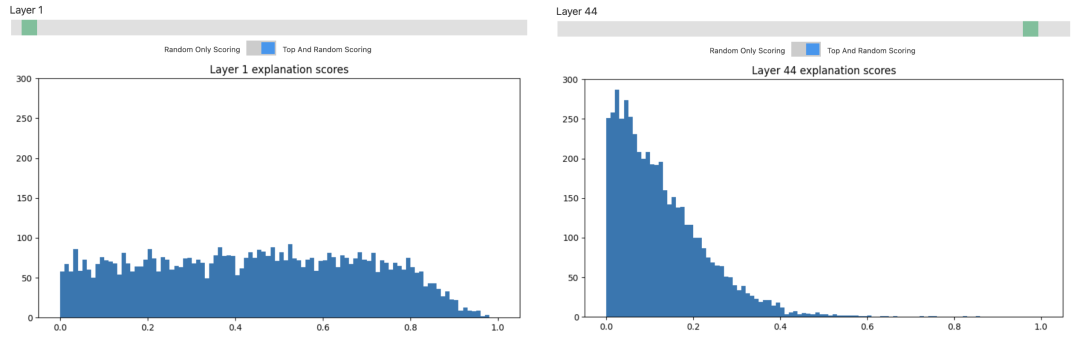
比如我們輸入30, 28,就可以看到第30層的第28個(gè)神經(jīng)元的情況。GPT4認(rèn)為這個(gè)神經(jīng)元關(guān)注的是具體時(shí)間。下面是各種測試?yán)洌G色就表示神經(jīng)元對這個(gè)詞有反應(yīng),綠色越深,反應(yīng)就越大。可以發(fā)現(xiàn),即便拼寫完全不同,但這些模型中間層的神經(jīng)元也已經(jīng)可以根據(jù)詞語和上下文來理解它們的意義了。

但OpenAI也發(fā)現(xiàn),只有那些層數(shù)較低的神經(jīng)元才是容易理解的。這個(gè)柱狀圖里的橫坐標(biāo)是對神經(jīng)元解釋的準(zhǔn)確程度,縱坐標(biāo)是神經(jīng)元的數(shù)量。可以看到,對于前幾層的神經(jīng)元,差不多一半都能做到0.4以上的準(zhǔn)確度。但是層數(shù)越高,得分低的神經(jīng)元就越來越多了,大多數(shù)神經(jīng)元還是處在一片迷霧之中。
因?yàn)閷τ谡Z言的理解本來就是難以解釋的,比如這樣一段對話。對于中文母語的我們來說,很快就能理解這段話的意思,但是對于一個(gè)神經(jīng)網(wǎng)絡(luò),只靠幾個(gè)對“意思”有反應(yīng)的神經(jīng)元顯然是不夠意思。
A:“你這是什么意思?”
B:“沒什么意思,意思意思。”
A:“你這人真有意思。”
B:“其實(shí)也沒有別的意思。”
A:“那我就不好意思了。”
B:“是我不好意思。”
而GPT似乎理解了這些意思,它是如何做到的?
【 Emergence--涌現(xiàn) 】
“將萬事萬物還原為簡單基本定律的能力,并不蘊(yùn)含從這些定律出發(fā),重建整個(gè)宇宙的能力。” —— Philip Anderson.
1972年,理論物理學(xué)家Philip Anderson在Science發(fā)表了一篇名為《More is Different》[7]的論文,奠定了復(fù)雜科學(xué)的基礎(chǔ),安德森認(rèn)為:“大量基本粒子的復(fù)雜聚集體的行為并不能依據(jù)少數(shù)粒子的性質(zhì)作簡單外推就能得到理解。取而代之的是在每一復(fù)雜性的發(fā)展層次之中呈現(xiàn)了全新的性質(zhì),從而我認(rèn)為要理解這些新行為所需要作的研究,就其基礎(chǔ)性而言,與其它相比也毫不遜色”。
回顧語言模型的結(jié)構(gòu),信息是隨著注意力編碼層不斷往上流動(dòng)的,層數(shù)越高的神經(jīng)元越有能力關(guān)注那些復(fù)雜抽象的概念和難以言說的隱喻。這篇叫《在干草堆里找神經(jīng)元》[8]的論文也發(fā)現(xiàn)了類似的情況,他們找到了一個(gè)專門用來判斷語言是否為法語的神經(jīng)元。如果在小模型當(dāng)中屏蔽這個(gè)神經(jīng)元,他對法語的理解能力馬上會(huì)下降,而如果在一個(gè)大模型中屏蔽它,可能幾乎沒什么影響。這意味著在模型變大的過程中,一個(gè)單一功能的神經(jīng)元很可能會(huì)分裂出多個(gè)適應(yīng)不同情況的神經(jīng)元,它們不再那么直白的判斷單一問題,進(jìn)而變得更難。
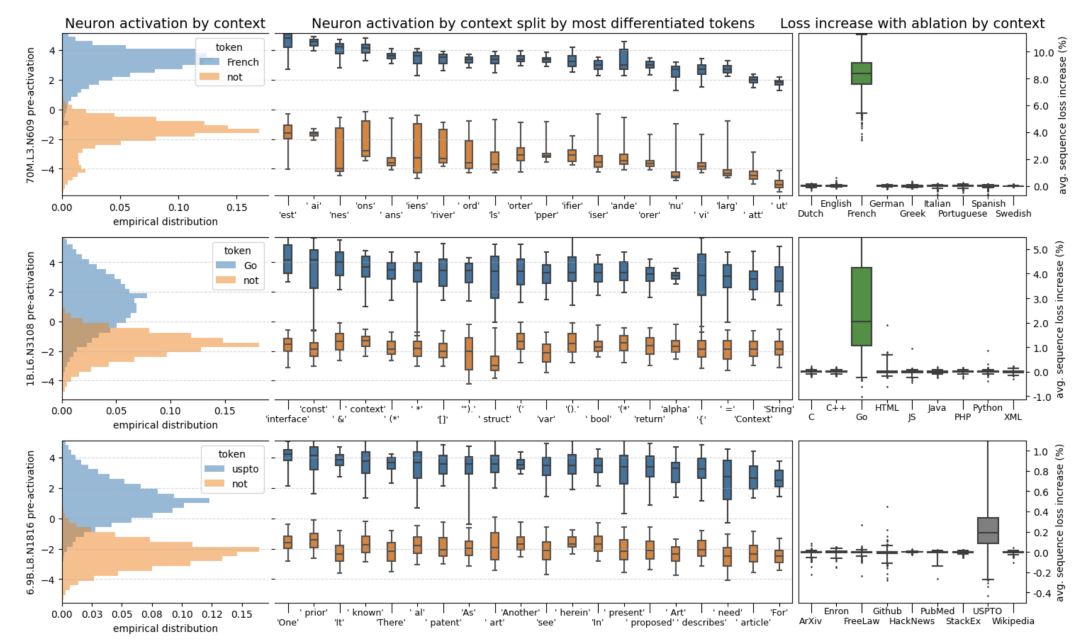
能理解這就是OpenAI為什么非得把模型搞得這么大的原因,只有足夠大才足夠抽象,而大到了一定程度,模型甚至?xí)_始出現(xiàn)從未出現(xiàn)過的全新能力。
在這篇名為《大語言模型的涌現(xiàn)能力》的論文中[9],研究人員對于這些大小不同的語言模型完成了八項(xiàng)新能力的測試。可以看到,他們在變大之前一直都不太行,而一旦大到某個(gè)臨界點(diǎn),它突然就行了,開始變成一條上竄的直線,就像是在一瞬間頓悟了一樣。
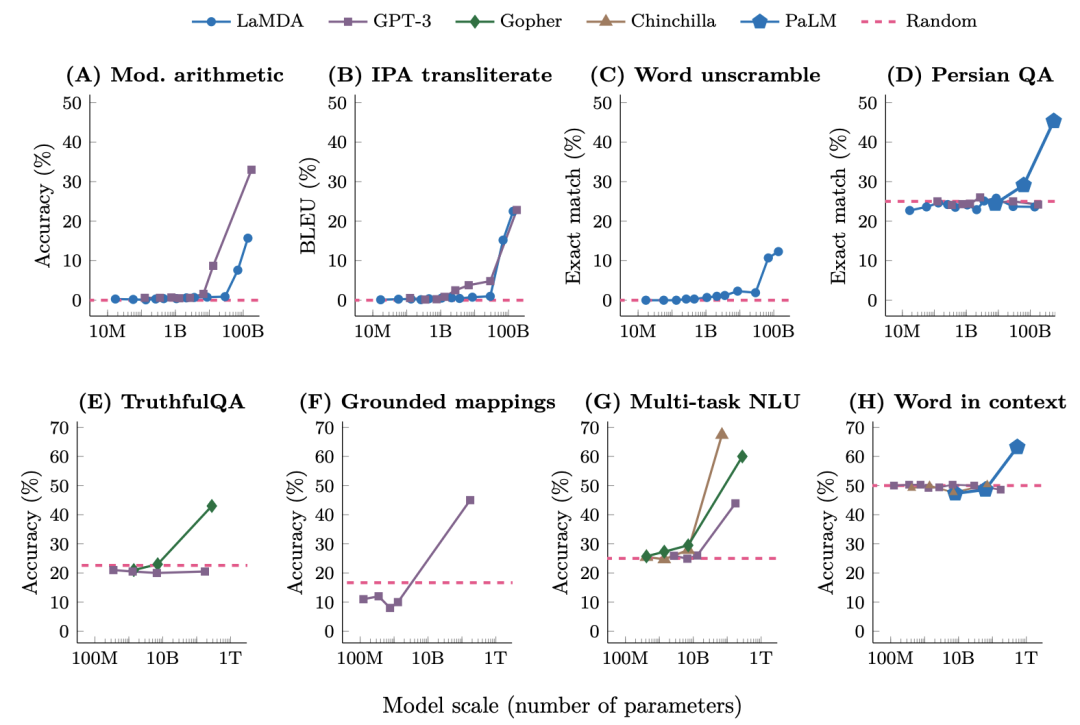
縱觀我們的自然和宇宙,一個(gè)復(fù)雜系統(tǒng)的誕生往往不是線性成長,而是在復(fù)雜度積累到某個(gè)閾值之后,突然的產(chǎn)生一種新的特質(zhì),一種此前從未有特的全新狀態(tài),這種現(xiàn)象被稱作涌現(xiàn),Emerge。而這個(gè)上千億參數(shù)的大語言模型,好像真的涌現(xiàn)出了一些數(shù)據(jù)分類之上的新東西。
最近讀了《失控》這本書,里面也提到了一個(gè)概念叫涌現(xiàn),可以理解為蜂群智慧。一只蜜蜂是很笨的,但是組成一個(gè)群體就可以完成很多超越個(gè)體智慧的決策。當(dāng)然我不覺得AI的單個(gè)神經(jīng)元是愚笨的,而是會(huì)不會(huì)這種“意識(shí)”,也會(huì)因?yàn)榇罅抗δ艿瑢W(xué)習(xí),突然涌現(xiàn)出來,就像人類的進(jìn)化,不知怎么的就有了意識(shí)。就像這個(gè)世界的一切都是由原子構(gòu)成,但如果只是計(jì)算原子之間的相互作用力,我們永遠(yuǎn)也無法理解化學(xué),也無法理解生命。所以,如果僅僅從還原論的角度把AI看作只做二元分裂的圓圈和線,我們就永遠(yuǎn)無法理解大語言模型今天涌現(xiàn)出的抽象邏輯和推理能力,為此,我們需要在一個(gè)新的層級重新理解這件事。
三、中文房間
1980年,美國哲學(xué)教授John Searle在這篇名為《心智大腦和程序》[10]的論文中提出了一個(gè)著名的思想實(shí)驗(yàn),中文房間。把一個(gè)只懂英文的人關(guān)在一個(gè)封閉的房間里,只能通過傳遞紙條的方式和外界對話。房間里有一本英文寫的中文對話手冊,每一句中文都能找到對應(yīng)的回復(fù)。這樣房間內(nèi)的人就可以通過手冊順暢的和外界進(jìn)行中文對話,看起來就像是會(huì)中文一樣,但實(shí)際上他既不理解外面提出的問題,也不理解他所返回的答案。
他試圖通過中文房間證明,不管一個(gè)程序有多聰明或者多像人,他都不可能讓計(jì)算機(jī)擁有思想、理解和意識(shí)。真的是這樣嗎?在這個(gè)名為互聯(lián)網(wǎng)哲學(xué)百科全書的網(wǎng)站中,可以看到圍繞中文房間的各種爭論,他們都沒能互相說服。

這些討論都停留在思想層面,因?yàn)槿绻豢恳槐敬蛴〕鰜淼氖謨裕形姆块g是不可能實(shí)現(xiàn)的。中文對話有著無窮無盡的可能,即便是同樣一句話,上下文不同,回答也不同。這意味著手冊需要記錄無限多的情況,要不然總有無法回答的時(shí)候。但詭異的是,ChatGPT真的實(shí)現(xiàn)了。作為一個(gè)只有330GB的程序,ChatGPT在有限的容量下實(shí)現(xiàn)了幾乎無限的中文對話,這意味著他完成了對中文的無損壓縮。
想象有一個(gè)這樣的復(fù)讀機(jī),空間只有100MB,只能放十首歌。要聽新的歌,就得刪掉舊的歌。但現(xiàn)在我們發(fā)現(xiàn)了一個(gè)神奇復(fù)讀機(jī)。現(xiàn)在只需要唱第一句,這個(gè)復(fù)讀機(jī)就可以通過續(xù)寫波形的方式把任何歌曲播放出來。我們應(yīng)該怎么理解這個(gè)復(fù)讀機(jī)?我們只能認(rèn)為他學(xué)會(huì)了唱歌。
四、Compression--壓縮即智慧
回想GPT的學(xué)習(xí)過程,它所做的,就是通過它的1750億個(gè)參數(shù),實(shí)現(xiàn)了它所學(xué)習(xí)的這4990億個(gè)token的壓縮。到這一步,逐漸意識(shí)到,是壓縮產(chǎn)生了智能。
Jack Ray, OpenAI大語言模型團(tuán)隊(duì)的核心成員,在視頻講座中提到,壓縮一直是我們的目標(biāo)。

接下來是我對于壓縮及智能這件事的理解,假設(shè)我要給你發(fā)送這句話,“壓縮即智慧”。
我們可以把GPT當(dāng)做一種壓縮工具,我用它壓縮這句話,你收到后再用GPT解壓,我們得先知道這句話的信息量有多大。在GBK這樣的編碼里,一個(gè)漢字需要兩個(gè)字節(jié),也就是16個(gè)0/1來表述,這可以表示2的16次方,也就是65536種可能。這句話一共5個(gè)字符,就需要一共80個(gè)0和1,也就是80比特。但實(shí)際上這句話的信息量是可以小于80比特的。它的真實(shí)信息量其實(shí)可以用一個(gè)公式計(jì)算。
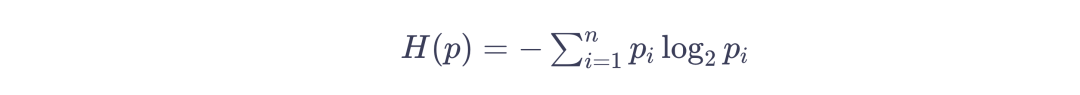
這是1948年香農(nóng)給出的信息熵的定義,它告訴我們信息的本質(zhì)是一種概率密度。我們可以把這里的P簡單理解為每個(gè)字出現(xiàn)的概率,它們出現(xiàn)的概率越低,整句話的信息量就越大。如果這句話里的每個(gè)字都是毫無規(guī)律的隨機(jī)出現(xiàn),那么P的概率就是1/65536,計(jì)算后的信息量就是原始的80比特。常見的傳統(tǒng)壓縮方法是找到重復(fù)的字,但幾乎不重復(fù)的句子就很難壓縮。更重要的是,正常的語言是有規(guī)律的,“壓”后面跟著“縮”的概率遠(yuǎn)大于1/65536,這就給了信息進(jìn)一步壓縮的空間。而語言模型所做的就是在壓縮的過程中找到語言的規(guī)律,提高每個(gè)字出現(xiàn)的概率。比如我們只發(fā)送“壓縮”,讓語言模型開始續(xù)寫,預(yù)測的概率表里就會(huì)出現(xiàn)接下來的詞,我們只需要選擇“即”和“智慧”所在的位置,例如(402,350)。那這兩這個(gè)數(shù)字就實(shí)現(xiàn)了信息的壓縮,接收方基于這些信息,從相同語言模型的概率去處理,選出數(shù)字對應(yīng)的選項(xiàng),就完成了解壓。2個(gè)最大不超過5000的數(shù)字,每個(gè)數(shù)字只要13位0/1就能表示,加上前2個(gè)字,一共也只需要發(fā)送52位0/1,信息壓縮到原來的52/80大約65%。
相反,如果語言模型的預(yù)測效果很差,后續(xù)文字的詞表還是會(huì)很長,無法實(shí)現(xiàn)很好的壓縮效果。所以可以發(fā)現(xiàn),壓縮效果越好意味著預(yù)測效果越好,也就反映了模型對于被壓縮信息的理解,而這種理解本身就是一種智能。為了把九九乘法表壓縮的足夠小,他需要理解數(shù)學(xué),而如果把行星坐標(biāo)壓縮的足夠小,他可能就理解了萬有引力。今天,大語言模型已經(jīng)成為了無損壓縮的最佳方案,可以實(shí)現(xiàn)14倍的壓縮率。壓縮這一視角最大的意義在于,相比于神秘莫測的涌現(xiàn),它給了我們一個(gè)清晰明確、可以量化機(jī)器智能的方案。即便面對中文房間這樣的思想實(shí)驗(yàn),我們也有辦法研究這個(gè)房間的智能程度。
但是,通過壓縮產(chǎn)生的智慧和人的心智真的是同一種東西嗎?
五、寫在最后
如果要問,現(xiàn)階段GPT和人類說話方式最大的不同是什么,我認(rèn)為,答案是他不會(huì)說謊。對于語言模型來說,說和想是一件事情,他只是一個(gè)字一個(gè)字的把他的思考過程和心理活動(dòng)說出來了而已。GPT從不回答我不知道,因?yàn)樗⒉恢雷约翰恢溃@就是AI的幻覺,看起來就像是一本正經(jīng)的胡說八道,他只是想讓對話繼續(xù)下去,是否正確反而沒那么重要。優(yōu)化這個(gè)問題的方法也很簡單,只需要在提問的時(shí)候多補(bǔ)充一句,Let's think step by step,請逐步分析,讓GPT像人一樣多想幾步,對他來說也就是把想的過程說出來。Step by step,這種能力也被稱為Chain of Thought,思維鏈。心理學(xué)家Daniel Kahneman把人的思維劃分成了兩種,系統(tǒng)一是直覺、快速的、沒有感覺的,系統(tǒng)二則需要主動(dòng)的運(yùn)用知識(shí)、邏輯和腦力來思考。前者是快思考,就像我們可以脫口而出八九七十二,九九八十一,而后者是慢思考。就比如要回答72乘81是多少,就必須列出過程,一步步計(jì)算。思維鏈的存在意味著大語言模型終于有了推理能力。而為了做到這件事,我們的大腦進(jìn)化了6億年。我們可以在6億年前的水母身上看到神經(jīng)網(wǎng)絡(luò)最古老的運(yùn)行方式。水母外圍的觸角區(qū)域和中心的嘴部區(qū)域都有神經(jīng)元。當(dāng)觸角感知到食物時(shí),這里的神經(jīng)元會(huì)激活,然后把信號(hào)傳給中心的神經(jīng)元,食物也會(huì)被這個(gè)觸角卷起來送到嘴里。漫長的歲月里,我們的大腦就在神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)上一層又一層的疊加生長出來。
首先進(jìn)化出來的是爬蟲類腦,這部分和青蛙的腦子有點(diǎn)像,它控制著我們的心跳、血壓、體溫這些讓我們不會(huì)死的東西。然后是古生物腦,它支配著我們的動(dòng)物本能,饑餓、恐懼和憤怒的情緒,繁衍后代的欲望都來自邊緣系統(tǒng)的控制。而最外側(cè)這兩毫米左右的薄薄的一層,是最近幾百萬年才進(jìn)化出來的新結(jié)構(gòu)、新皮質(zhì),我們?nèi)祟愐詾榘恋哪切┎糠郑Z言、文字、視覺、聽力、運(yùn)動(dòng)和思考都發(fā)生在這里,但我們對新皮質(zhì)還是知之甚少。目前已知的是,這里有大概200億個(gè)神經(jīng)元,每一平方厘米的新皮質(zhì)中都大約有一千萬個(gè)神經(jīng)元和500億個(gè)神經(jīng)元之間的連接。只需要從人類大腦外側(cè)取下一小片三平方厘米的新皮質(zhì),就已經(jīng)和ChatGPT大的嚇人的參數(shù)量類似了。而我們的大腦之所以需要這么多神經(jīng)元,是因?yàn)镚PT僅僅需要預(yù)測下一個(gè)詞,而我們的神經(jīng)元需要時(shí)刻預(yù)測這個(gè)世界下一秒會(huì)發(fā)生什么。
最近幾十年的神經(jīng)科學(xué)研究發(fā)現(xiàn)除了能激活神經(jīng)元的突觸信號(hào),還存在大量負(fù)責(zé)預(yù)測的樹突脈沖信號(hào)。一個(gè)處于預(yù)測狀態(tài)的神經(jīng)元如果得到足夠強(qiáng)的突出信號(hào),就可以比沒有預(yù)測狀態(tài)的神經(jīng)元更早的被激活,進(jìn)而抑制其他的神經(jīng)元。這意味著有一個(gè)事無巨細(xì)的世界模型就存儲(chǔ)在我們新皮質(zhì)的200億個(gè)神經(jīng)元里,而我們的大腦永遠(yuǎn)不會(huì)停止預(yù)測。所以,當(dāng)我們看到一個(gè)東西,其實(shí)看到的是大腦提前構(gòu)建的模型,如果它符合我們的預(yù)測,無事發(fā)生。而一旦預(yù)測錯(cuò)誤,大量的其他神經(jīng)元就會(huì)被激活,讓我們注意到這個(gè)錯(cuò)誤,并及時(shí)更新模型。所以每一次錯(cuò)誤都有它的價(jià)值。我們也正是在無數(shù)次的預(yù)測錯(cuò)誤和更新認(rèn)知中真正認(rèn)識(shí)了世界。
現(xiàn)在我可以試著回答最初的問題,GPT或許尚未涌現(xiàn)心智,但他已經(jīng)擁有了智能。它是一個(gè)“大”的語言模型,是幾百萬個(gè)圓圈和線互相連接的分類器,是通過預(yù)測下一個(gè)詞實(shí)現(xiàn)文字接龍的聊天大師,是不斷向上抽取意義的天才金魚,是對幾千億文字無損壓縮的復(fù)讀機(jī),是不論對錯(cuò)永遠(yuǎn)積極回應(yīng)人的助手。它可能又是一場快速退潮的科技熱點(diǎn),也可能是人類的最后一項(xiàng)重要的發(fā)明。從圍棋、繪畫、音樂到數(shù)學(xué)、語言、代碼,當(dāng)AI開始在那些象征人類智力和創(chuàng)造力的事情上逐漸超越的時(shí)候,給人類最大的沖擊不僅僅是工作被替代的恐懼,而是一種更深層的自我懷疑。人類的心智是不是要比我們想象的淺薄的多,我不這么認(rèn)為。
機(jī)器可以是一個(gè)精妙準(zhǔn)確的復(fù)讀機(jī),而人類是一個(gè)會(huì)出錯(cuò)的復(fù)讀機(jī)。缺陷和錯(cuò)誤定義了我們是誰。每一次不合規(guī)矩,每一次難以理解,每一次沉默、停頓和凝視,都比不假思索的回答更有價(jià)值。
審核編輯:劉清
-
編碼器
+關(guān)注
關(guān)注
45文章
3667瀏覽量
135237 -
GPT
+關(guān)注
關(guān)注
0文章
360瀏覽量
15505 -
機(jī)器語言
+關(guān)注
關(guān)注
0文章
35瀏覽量
10774 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1568瀏覽量
8057
原文標(biāo)題:ChatGPT是如何產(chǎn)生心智的?
文章出處:【微信號(hào):OSC開源社區(qū),微信公眾號(hào):OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
ChatGPT新增實(shí)時(shí)搜索與高級語音功能
心智理論測試:人工智能擊敗人類
OpenAI推出ChatGPT搜索功能
ChatGPT:怎樣打造智能客服體驗(yàn)的重要工具?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論