 10億數據如何快速插入MySQL?
10億數據如何快速插入MySQL?
首先考慮10億數據寫到MySQL單表可行嗎?
數據庫單表能支持10億嗎?
答案是不能,單表推薦的值是2000W以下。這個值怎么計算出來的呢?
MySQL索引數據結構是B+樹,全量數據存儲在主鍵索引,也就是聚簇索引的葉子結點上。B+樹插入和查詢的性能和B+樹層數直接相關,2000W以下是3層索引,而2000w以上則可能為四層索引。
Mysql b+索引的葉子節點每頁大小16K。當前每條數據正好1K,所以簡單理解為每個葉子節點存儲16條數據。b+索引每個非葉子節點大小也是16K,但是其只需要存儲主鍵和指向葉子節點的指針,我們假設主鍵的類型是 BigInt,長度為 8 字節,而指針大小在 InnoDB 中設置為 6 字節,這樣一共 14 字節,這樣一個非葉子節點可以存儲 16 * 1024/14=1170。
也就是每個非葉子節點可關聯1170個葉子節點,每個葉子節點存儲16條數據。由此可得到B+樹索引層數和存儲數量的表格。2KW 以上 索引層數為 4 層,性能更差。
| 層數 | 最大數據量 |
|---|---|
| 2 | 1170 * 16 = 18720 |
| 3 | 1170 * 1170 * 16= 21902400 = 2000w |
| 4 | 1170 * 1170 * 1170 * 16 = 25625808000 = 256億 |
為了便于計算,我們可以設計單表容量在1KW,10億條數據共100個表。
如何高效的寫入數據庫
單條寫入數據庫性能比較差,可以考慮批量寫入數據庫,批量數值動態可調整。每條1K,默認可先調整為100條批量寫入。
批量數據如何保證數據同時寫成功?MySQL Innodb存儲引擎保證批量寫入事務同時成功或失敗。
寫庫時要支持重試,寫庫失敗重試寫入,如果重試N次后依然失敗,可考慮單條寫入100條到數據庫,失敗數據打印記錄,丟棄即可。
此外寫入時按照主鍵id順序順序寫入可以達到最快的性能,而非主鍵索引的插入則不一定是順序的,頻繁地索引結構調整會導致插入性能下降。最好不創建非主鍵索引,或者在表創建完成后再創建索引,以保證最快的插入性能。
是否需要并發寫同一個表
不能
并發寫同一個表無法保證數據寫入時是有序的。
提高批量插入的閾值,在一定程度上增加了插入并發度。無需再并發寫入單表
MySQL存儲引擎的選擇
Myisam 比innodb有更好的插入性能,但失去了事務支持,批量插入時無法保證同時成功或失敗,所以當批量插入超時或失敗時,如果重試,勢必對導致一些重復數據的發生。但是為了保證更快的導入速度,可以把myisam存儲引擎列為計劃之一。
現階段我引用一下別人的性能測試結果:MyISAM與InnoDB對比分析
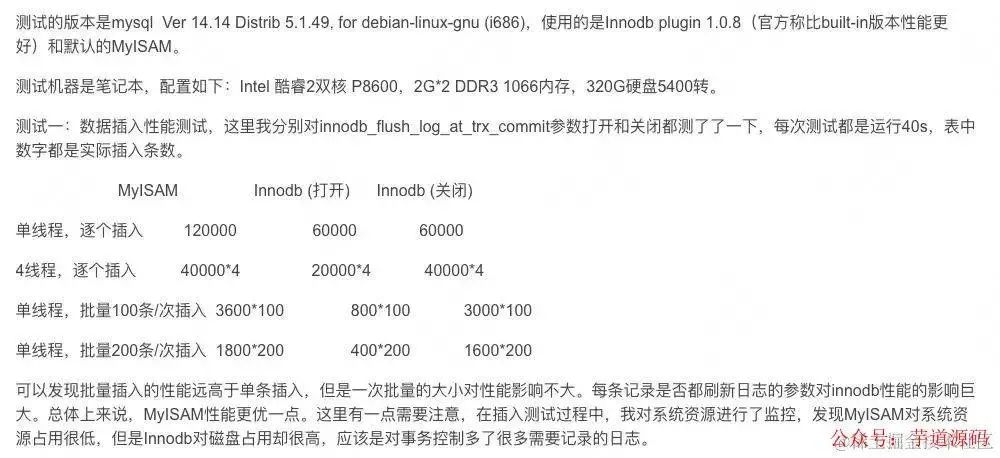
從數據可以看到批量寫入明顯優于單條寫入。并且在innodb關閉即時刷新磁盤策略后,innodb插入性能沒有比myisam差太多。
innodb_flush_log_at_trx_commit: 控制MySQL刷新數據到磁盤的策略。
默認=1,即每次事務提交都會刷新數據到磁盤,安全性最高不會丟失數據。
當配置為0、2 會每隔1s刷新數據到磁盤, 在系統宕機、mysql crash時可能丟失1s的數據。
考慮到Innodb在關閉即時刷新磁盤策略時,批量性能也不錯,所以暫定先使用innodb(如果公司MySQL集群不允許改變這個策略值,可能要使用MyIsam了。)。線上環境測試時可以重點對比兩者的插入性能。
要不要進行分庫
mysql 單庫的并發寫入是有性能瓶頸的,一般情況5K TPS寫入就很高了。
當前數據都采用SSD 存儲,性能應該更好一些。但如果是HDD的話,雖然順序讀寫會有非常高的表現,但HDD無法應對并發寫入,例如每個庫10張表,假設10張表在并發寫入,每張表雖然是順序寫入,由于多個表的存儲位置不同,HDD只有1個磁頭,不支持并發寫,只能重新尋道,耗時將大大增加,失去順序讀寫的高性能。所以對于HDD而言,單庫并發寫多個表并不是好的方案。回到SSD的場景,不同SSD廠商的寫入能力不同,對于并發寫入的能力也不同,有的支持500M/s,有的支持1G/s讀寫,有的支持8個并發,有的支持4個并發。在線上實驗之前,我們并不知道實際的性能表現如何。
所以在設計上要更加靈活,需要支持以下能力
支持配置數據庫的數量
支持配置并發寫表的數量,(如果MySQL是HDD磁盤,只讓一張表順序寫入,其他任務等待)
通過以上配置,靈活調整線上數據庫的數量,以及寫表并發度,無論是HDD還是SSD,我們系統都能支持。不論是什么廠商型號的SSD,性能表現如何,都可調整配置,不斷獲得更高的性能。這也是后面設計的思路,不固定某一個閾值數量,都要動態可調整。
接下來聊一下文件讀取,10億條數據,每條1K,一共是931G。近1T大文件,一般不會生成如此大的文件。所以我們默認文件已經被大致切分為100個文件。每個文件數量大致相同即可。為什么切割為100個呢?切分為1000個,增大讀取并發,不是可以更快導入數據庫嗎?剛才提到數據庫的讀寫性能受限于磁盤,但任何磁盤相比寫操作,讀操作都要更快。尤其是讀取時只需要從文件讀取,但寫入時MySQL要執行建立索引,解析SQL、事務等等復雜的流程。所以寫的并發度最大是100,讀文件的并發度無需超過100。
更重要的是讀文件并發度等于分表數量,有利于簡化模型設計。即100個讀取任務,100個寫入任務,對應100張表。
如何保證寫入數據庫有序
既然文件被切分為100個10G的小文件,可以按照文件后綴+ 在文件行號 作為記錄的唯一鍵,同時保證同一個文件的內容被寫入同一個表。例如
index_90.txt 被寫入 數據庫database_9,table_0 ,
index_67.txt被寫入數據庫 database_6,table_7。
這樣每個表都是有序的。整體有序通過數據庫后綴+表名后綴實現。
如何更快地讀取文件
10G的文件顯然不能一次性讀取到內存中,場景的文件讀取包括
FileReader+ BufferedReader 逐行讀取
File+ BufferedReader
Scanner逐行讀取
Java NIO FileChannel緩沖區方式讀取
在MAC上,使用這幾種方式的讀取3.4G大小文件的性能對比
| 讀取方式 | |
|---|---|
| Files.readAllBytes | 內存爆了 OOM |
| FileReader+ BufferedReader 逐行讀取 | 11秒 |
| File+ BufferedReader | 10 秒 |
| Scanner | 57秒 |
| Java NIO FileChannel緩沖區方式讀取 | 3秒 |
詳細的評測內容請參考:讀取文件性能比較 :https://zhuanlan.zhihu.com/p/142029812
由此可見 使用JavaNIO FileChannnel明顯更優,但是FileChannel的方式是先讀取固定大小緩沖區,不支持按行讀取。也無法保證緩沖區正好包括整數行數據。如果緩沖區最后一個字節正好卡在一行數據中間,還需要額外配合讀取下一批數據。如何把緩沖區變為一行行數據,比較困難。
Filefile=newFile("/xxx.zip");
FileInputStreamfileInputStream=null;
longnow=System.currentTimeMillis();
try{
fileInputStream=newFileInputStream(file);
FileChannelfileChannel=fileInputStream.getChannel();
intcapacity=1*1024*1024;//1M
ByteBufferbyteBuffer=ByteBuffer.allocate(capacity);
StringBufferbuffer=newStringBuffer();
intsize=0;
while(fileChannel.read(byteBuffer)!=-1){
//讀取后,將位置置為0,將limit置為容量,以備下次讀入到字節緩沖中,從0開始存儲
byteBuffer.clear();
byte[]bytes=byteBuffer.array();
size+=bytes.length;
}
System.out.println("filesize:"+size);
}catch(FileNotFoundExceptione){
e.printStackTrace();
}catch(IOExceptione){
e.printStackTrace();
}finally{
//TODOclose資源.
}
System.out.println("Time:"+(System.currentTimeMillis()-now));
JavaNIO 是基于緩沖區的,ByteBuffer可轉為byte數組,需要轉為字符串,并且要處理按行截斷。
但是BufferedReader JavaIO方式讀取可以天然支持按行截斷,況且性能還不錯 ,10G文件,大致只需要讀取30s,由于導入的整體瓶頸在寫入部分,即便30s讀取完,也不會影響整體性能。所以文件讀取使用BufferedReader 逐行讀取。即方案3
如果協調讀文件任務和寫數據庫任務
這塊比較混亂,請耐心看完。
100個讀取任務,每個任務讀取一批數據,立即寫入數據庫是否可以呢?前面提到了由于數據庫并發寫入的瓶頸,無法滿足1個庫同時并發大批量寫入10個表,所以100個任務同時寫入數據庫,勢必導致每個庫同時有10個表同時在順序寫,這加劇了磁盤的并發寫壓力。為盡可能提高速度,減少磁盤并發寫入帶來的性能下降, 需要一部分寫入任務被暫停的。那么讀取任務需要限制并發度嗎?不需要。
假設寫入任務和讀取任務合并,會影響讀取任務并發度。初步計劃讀取任務和寫入任務各自處理,誰也不耽誤誰。但實際設計時發現這個方案較為困難。
最初的設想是引入Kafka,即100個讀取任務把數據投遞到Kafka,由寫入任務消費kafka寫入DB。100個讀取任務把消息投遞到Kafka,此時順序就被打亂了,如何保證有序寫入數據庫呢?我想到可以使用Kafka partition路由,即讀取任務id把同一任務的消息都路由到同一個partition,保證每個partition內有序消費。
要準備多少個分片呢?100個很明顯太多,如果partition小于100個,例如10個。那么勢必存在多個任務的消息混合在一起。如果同一個庫的多個表在一個Kafka partition,且這個數據庫只支持單表批量寫入,不支持并發寫多個表。這個庫多個表的消息混在一個分片中,由于并發度的限制,不支持寫入的表對應的消息只能被丟棄。所以這個方案既復雜,又難以實現。
所以最終放棄了Kafka方案,也暫時放棄了將讀取和寫入任務分離的方案。
最終方案簡化為 讀取任務讀一批數據,寫入一批。即任務既負責讀文件、又負責插入數據庫。
如何保證任務的可靠性
如果讀取任務進行到一半,宕機或者服務發布如何處理呢?或者數據庫故障,一直寫入失敗,任務被暫時終止,如何保證任務再次拉起時,再斷點處繼續處理,不會存在重復寫入呢?
剛才我們提到可以 為每一個記錄設置一個主鍵Id,即 文件后綴index+文件所在行號。可以通過主鍵id的方式保證寫入的冪等。
文件所在的行號,最大值 大致為 10G/1k = 10M,即10000000。拼接最大的后綴99。最大的id為990000000。
所以也無需數據庫自增主鍵ID,可以在批量插入時指定主鍵ID。
如果另一個任務也需要導入數據庫呢?如何實現主鍵ID隔離,所以主鍵ID還是需要拼接taskId。例如{taskId}{fileIndex}{fileRowNumber} 轉化為Long類型。如果taskId較大,拼接后的數值過大,轉化為Long類型可能出錯。
最重要的是,如果有的任務寫入1kw,有的其他任務寫入100W,使用Long類型無法獲知每個占位符的長度,存在沖突的可能性。而如果拼接字符串{taskId}_{fileIndex}_{fileRowNumber} ,新增唯一索引,會導致插入性能更差,無法滿足最快導入數據的訴求。所以需要想另一個方案。
可以考慮使用Redis記錄當前任務的進度。例如Redis記錄task的進度,批量寫入數據庫成功后,更新 task進度。
INCRBYKEY_NAMEINCR_AMOUNT
指定當前進度增加100,例如 incrby task_offset_{taskId} 100。如果出現批量插入失敗的,則重試插入。多次失敗,則單個插入,單個更新redis。要確保Redis更新成功,可以在Redis更新時 也加上重試。
如果還不放心Redis進度和數據庫更新的一致性,可以考慮 消費 數據庫binlog,每一條記錄新增則redis +1 。
如果任務出現中斷,則首先查詢任務的offset。然后讀取文件到指定的offset繼續 處理。
如何協調讀取任務的并發度
前面提到了為了避免單個庫插入表的并發度過高,影響數據庫性能。可以考慮限制并發度。如何做到呢?
既然讀取任務和寫入任務合并一起。那么就需要同時限制讀取任務。即每次只挑選一批讀取寫入任務執行。
在此之前需要設計一下任務表的存儲模型。

bizId為了以后支持別的產品線,預設字段。默認為1,代表當前業務線。
datbaseIndex 代表被分配的數據庫后綴
tableIndex 代表被分配的表名后綴
parentTaskId,即總的任務id
offset可以用來記錄當前任務的進度
10億條數據導入數據庫,切分為100個任務后,會新增100個taskId,分別處理一部分數據,即一個10G文件。
status 狀態用來區分當前任務是否在執行,執行完成。
如何把任務分配給每一個節點,可以考慮搶占方式。每個任務節點都需要搶占任務,每個節點同時只能搶占1個任務。具體如何實現呢?可以考慮 每個節點都啟動一個定時任務,定期掃表,掃到待執行子任務,嘗試執行該任務。
如何控制并發呢?可以使用redission的信號量。key為數據庫id、
RedissonClientredissonClient=Redisson.create(config); RSemaphorerSemaphore=redissonClient.getSemaphore("semaphore"); //設置1個并發度 rSemaphore.trySetPermits(1); rSemaphore.tryAcquire();//申請加鎖,非阻塞。
由任務負責定期輪訓,搶到名額后,就開始執行任務。將該任務狀態置為Process,任務完成后或失敗后,釋放信號量。
TaskTassk任務表Redisalt爭搶信號量成功定時輪訓任務開始查詢待執行的任務循環爭搶信號量修改任務狀態執行中,設置開始時間時間查詢當前進度讀取文件到從當前進度讀取文件,批量導入數據庫更新進度執行完成,釋放信號量申請下一個任務的信號量TaskTassk任務表Redis
但是使用信號量限流有個問題,如果任務忘記釋放信號量,或者進程Crash無法釋放信號量,如何處理呢?可以考慮給信號量增加一個超時時間。那么如果任務執行過長,導致提前釋放信號量,另一個客戶單爭搶到信號量,導致 兩個客戶端同時寫一個任務如何處理呢?
what,明明是將10億數據導入數據庫,怎么變成分布式鎖超時的類似問題?
實際上 Redisson的信號量并沒有很好的辦法解決信號量超時問題,正常思維:如果任務執行過長,導致信號量被釋放,解決這個問題只需要續約就可以了,任務在執行中,只要發現快信號量過期了,就續約一段時間,始終保持信號量不過期。但是 Redission并沒有提供信號量續約的能力,怎么辦?
不妨換個思路,我們一直在嘗試讓多個節點爭搶信號量,進而限制并發度。可以試試選取一個主節點,通過主節點輪訓任務表。分三種情況,
情況1 當前執行中數量小于并發度。
則選取id最小的待執行任務,狀態置為進行中,通知發布消息。
消費到消息的進程,申請分布式鎖,開始處理任務。處理完成釋放鎖。借助于Redission分布式鎖續約,保證任務完成前,鎖不會超時。
情況2 當前執行中數量等于并發度。
主節點嘗試 get 進行中任務是否有鎖。
如果沒有鎖,說明有任務執行失敗,此時應該重新發布任務。如果有鎖,說明有任務正在執行中。
情況3 當前執行中數量大于并發度
上報異常情況,報警,人工介入
使用主節點輪訓任務,可以減少任務的爭搶,通過kafka發布消息,接收到消息的進程處理任務。為了保證更多的節點參與消費,可以考慮增加Kafka分片數。雖然每個節點可能同時處理多個任務,但是不會影響性能,因為性能瓶頸在數據庫。
那么主節點應該如何選取呢?可以通過Zookeeper+curator 選取主節點。可靠性比較高。
10億條數據插入數據庫的時間影響因素非常多。包括數據庫磁盤類型、性能。數據庫分庫數量如果能切分1000個庫當然性能更快,要根據線上實際情況決策分庫和分表數量,這極大程度決定了寫入的速率。最后數據庫批量插入的閾值也不是一成不變的,需要不斷測試調整,以求得最佳的性能。可以按照100,1000,10000等不斷嘗試批量插入的最佳閾值。
最后總結一下幾點重要的
總結
要首先確認約束條件,才能設計方案。確定面試官主要想問的方向,例如1T文件如何切割為小文件,雖是難點,然而可能不是面試官想考察的問題。
從數據規模看,需要分庫分表,大致確定分表的規模。
從單庫的寫入瓶頸分析,判斷需要進行分庫。
考慮到磁盤對并發寫的支持力度不同,同一個庫多個表寫入的并發需要限制。并且支持動態調整,方便在線上環境調試出最優值。
MySQL innodb、myisam 存儲引擎對寫入性能支持不同,也要在線上對比驗證
數據庫批量插入的最佳閾值需要反復測試得出。
由于存在并發度限制,所以基于Kafka分離讀取任務和寫入任務比較困難。所以合并讀取任務和寫入任務。
需要Redis記錄任務執行的進度。任務失敗后,重新導入時,記錄進度,可避免數據重復問題。
分布式任務的協調工作是難點,使用Redission信號量無法解決超時續約問題。可以由主節點分配任務+分布式鎖保證任務排他寫入。主節點使用Zookeeper+Curator選取。
審核編輯:劉清
-
緩沖器
+關注
關注
6文章
1930瀏覽量
45650 -
JAVA
+關注
關注
19文章
2975瀏覽量
105153 -
中斷
+關注
關注
5文章
900瀏覽量
41755 -
SSD
+關注
關注
21文章
2889瀏覽量
117862 -
MySQL
+關注
關注
1文章
829瀏覽量
26743
原文標題:阿里終面:10億數據如何快速插入MySQL?
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
利用JAVA向Mysql插入一億數量級數據—效率測評
labview無法將中文寫入mysql數據庫
源頭開始呈現labview連接MYSQL數據庫過程樣本
幾種數據庫的大數據批量插入解決方法
Mysql如何快速回滾被刪除的數據

MySQL數據庫:如何操作禁止重復插入數據







 工商網監
工商網監
評論