") FlashAttenion-V3: Flash Decoding詳解
FlashAttenion-V3: Flash Decoding詳解
Flash Attention V1和V2的作者又推出了Flash Decoding,真是太強(qiáng)了!
Flash-Decoding借鑒了FlashAttention的優(yōu)點(diǎn),將并行化維度擴(kuò)展到keys/values序列長(zhǎng)度。這種方法幾乎不收序列長(zhǎng)度影響(這對(duì)LLM模型能力很重要),可以充分利用GPU,即使在batch size較小時(shí)(inference特點(diǎn)),也可以極大提高了encoding速度。
相關(guān)背景知識(shí)先推薦閱讀:
FlashAttention圖解(如何加速Attention)
FlashAttention2詳解(性能比FlashAttention提升200%)
Motivation
最近,像ChatGPT或Llama這樣的LLM模型受到了空前的關(guān)注。然而,它們的運(yùn)行成本卻非常高昂。雖然單次回復(fù)的成本約為0.01美元(例如在AWS 8塊A100上運(yùn)行幾秒鐘),但是當(dāng)擴(kuò)展到數(shù)十億用戶的多次交互時(shí),成本會(huì)迅速上升。而且一些場(chǎng)景的成本更高,例如代碼自動(dòng)補(bǔ)全,因?yàn)橹灰脩糨斎胍粋€(gè)新字符就會(huì)執(zhí)行。由于LLM應(yīng)用非常廣泛且還在迅速增長(zhǎng),即使稍微提升其運(yùn)行效率也會(huì)產(chǎn)生巨大的收益。
LLM inference(或稱為decoding)是一個(gè)迭代的過程:預(yù)測(cè)的tokens是逐個(gè)生成的。如果生成的句子有N個(gè)單詞,那么模型需要進(jìn)行N次forward。一個(gè)常用的優(yōu)化技巧是KV Cache,該方法緩存了之前forward的一些中間結(jié)果,節(jié)約了大部分運(yùn)算(如MatMul),但是attention操作是個(gè)例外。隨著輸出tokens長(zhǎng)度增加,attention操作的復(fù)雜度也極具上升。
然而我們希望LLM能處理長(zhǎng)上下文。增加了上下文長(zhǎng)度,LLM可以輸出更長(zhǎng)的文檔、跟蹤更長(zhǎng)的對(duì)話,甚至在編寫代碼之前處理整個(gè)代碼庫(kù)。例如,2022年大多數(shù)LLM的上下文長(zhǎng)度最多為2k(如GPT-3),但現(xiàn)在LLM上下文長(zhǎng)度可以擴(kuò)展到32k(Llama-2-32k),甚至最近達(dá)到了100k(CodeLlama)。在這種情況下,attention操作在推理過程中占據(jù)了相當(dāng)大的時(shí)間比例。此外,當(dāng)batch size增加時(shí),即使在相對(duì)較小的上下文中,attention操作也可能成為瓶頸。這是因?yàn)樵摬僮餍枰獙?duì)內(nèi)存的訪問會(huì)隨著batch size增加而增加,而模型中其他操作只和模型大小相關(guān)。
因此,本文提出了Flash-Decoding,可以推理過程中顯著加速attention操作(例如長(zhǎng)序列生成速度提高8倍)。其主要思想是最大化并行加載keys和values的效率,通過重新縮放組合得到正確結(jié)果。
Multi-head attention for decoding
在decoding過程中,每個(gè)生成的新token需要與先前的tokens合并后,才能繼續(xù)執(zhí)行attention操作,即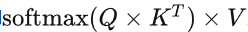 。Attention操作在訓(xùn)練過程的瓶頸主要卡在訪問內(nèi)存讀寫中間結(jié)果(例如
。Attention操作在訓(xùn)練過程的瓶頸主要卡在訪問內(nèi)存讀寫中間結(jié)果(例如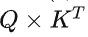 )的帶寬,相關(guān)加速方案可以參考FlashAttention和FlashAttention2。
)的帶寬,相關(guān)加速方案可以參考FlashAttention和FlashAttention2。
然而,上述優(yōu)化不適合直接應(yīng)用于推理過程。因?yàn)樵谟?xùn)練過程中,F(xiàn)lashAttention對(duì)batch size和query length進(jìn)行了并行化加速。而在推理過程中,query length通常為1,這意味著如果batch size小于GPU上的SM數(shù)量(例如A100上有108個(gè)SMs),那么整個(gè)計(jì)算過程只使用了GPU的一小部分!特別是當(dāng)上下文較長(zhǎng)時(shí),通常會(huì)減小batch size來適應(yīng)GPU內(nèi)存。例如batch size = 1時(shí),F(xiàn)lashAttention對(duì)GPU利用率小于1%!
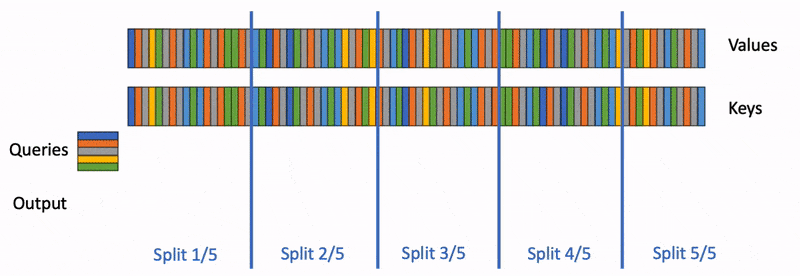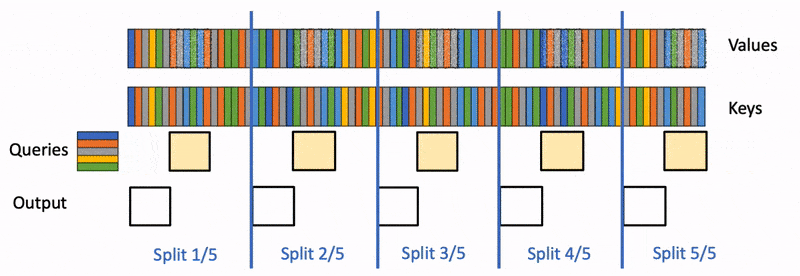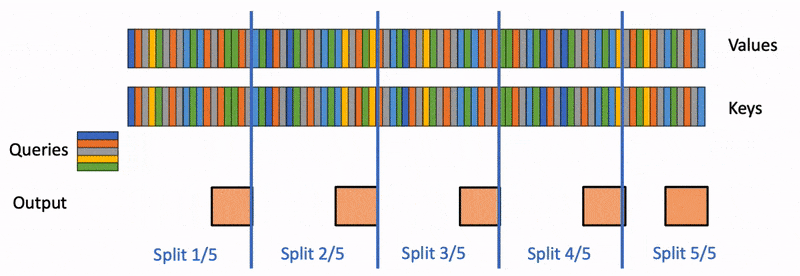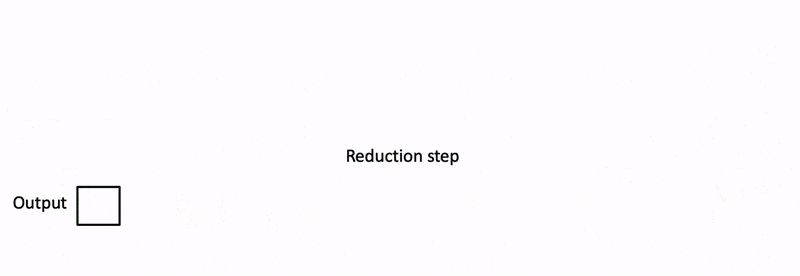
下面展示了FlashAttention的計(jì)算示意圖,該示例將keys和values分為了2個(gè)block:
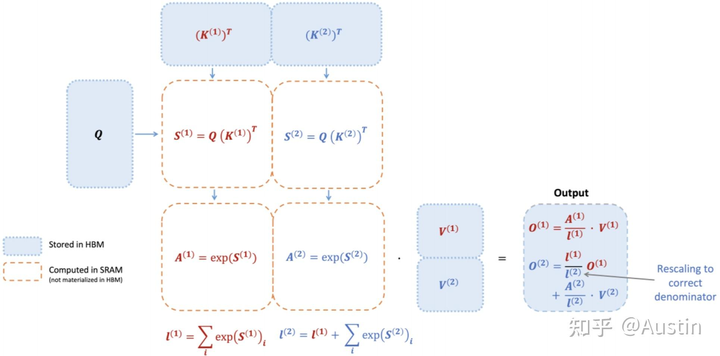
FlashAttention示意圖
對(duì)應(yīng)的計(jì)算公式:
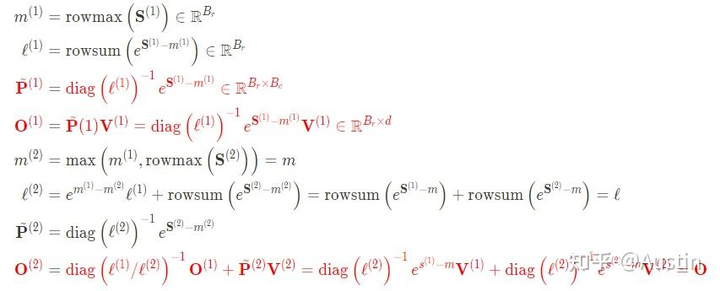
FlashAttention示意圖對(duì)應(yīng)的計(jì)算公式
注意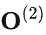 的計(jì)算過程依賴
的計(jì)算過程依賴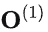 ,從下圖也可以看出,F(xiàn)lashAttention是按順序更新output的,其實(shí)當(dāng)時(shí)我在看FlashAttention這篇文章時(shí)就覺得這個(gè)順序操作可以優(yōu)化的,因?yàn)榉凑家猺escale,不如最后統(tǒng)一rescale,沒必要等之前block計(jì)算完(為了獲取上一個(gè)block的max值)
,從下圖也可以看出,F(xiàn)lashAttention是按順序更新output的,其實(shí)當(dāng)時(shí)我在看FlashAttention這篇文章時(shí)就覺得這個(gè)順序操作可以優(yōu)化的,因?yàn)榉凑家猺escale,不如最后統(tǒng)一rescale,沒必要等之前block計(jì)算完(為了獲取上一個(gè)block的max值)

flashattention計(jì)算過程
A faster attention for decoding: Flash-Decoding
上面提到FlashAttention對(duì)batch size和query length進(jìn)行了并行化加速,F(xiàn)lash-Decoding在此基礎(chǔ)上增加了一個(gè)新的并行化維度:keys/values的序列長(zhǎng)度。即使batch size很小,但只要上下文足夠長(zhǎng),它就可以充分利用GPU。與FlashAttention類似,F(xiàn)lash-Decoding幾乎不用額外存儲(chǔ)大量數(shù)據(jù)到全局內(nèi)存中,從而減少了內(nèi)存開銷。
flashdecoding計(jì)算過程
Flash Decoding主要包含以下三個(gè)步驟(可以結(jié)合上圖來看):
將keys和values分成較小的block
使用FlashAttention并行計(jì)算query與每個(gè)block的注意力(這是和FlashAttention最大的區(qū)別)。對(duì)于每個(gè)block的每行(因?yàn)橐恍惺且粋€(gè)特征維度),F(xiàn)lash Decoding會(huì)額外記錄attention values的log-sum-exp(標(biāo)量值,用于第3步進(jìn)行rescale)
對(duì)所有output blocks進(jìn)行reduction得到最終的output,需要用log-sum-exp值來重新調(diào)整每個(gè)塊的貢獻(xiàn)
實(shí)際應(yīng)用中,第1步中的數(shù)據(jù)分塊不涉及GPU操作(因?yàn)椴恍枰谖锢砩戏珠_),只需要對(duì)第2步和第3步執(zhí)行單獨(dú)的kernels。雖然最終的reduction操作會(huì)引入一些額外的計(jì)算,但在總體上,F(xiàn)lash-Decoding通過增加并行化的方式取得了更高的效率。
Benchmarks on CodeLlama 34B
作者對(duì)CodeLLaMa-34b的decoding throughput進(jìn)行了基準(zhǔn)測(cè)試。該模型與Llama 2具有相同的架構(gòu)。作者在各種序列長(zhǎng)度(從512到64k)上測(cè)試了decoding速度,并比較了多種attention計(jì)算方法:
PyTorch:使用純PyTorch primitives運(yùn)行注意力計(jì)算(不使用FlashAttention)。
FlashAttention v2(v2.2之前的版本)。
FasterTransformer:使用FasterTransformer attention kernel
Flash-Decoding
將從內(nèi)存中讀取整個(gè)模型和KV Cache所需的時(shí)間作為上限
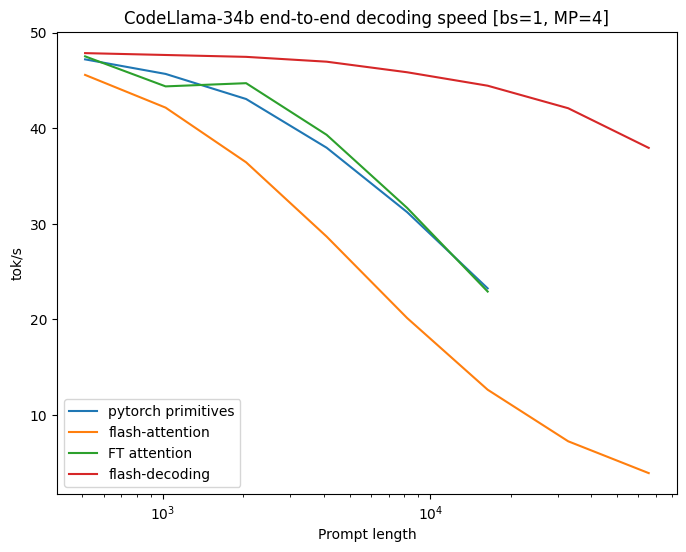
Untitled
從上圖可以看出,F(xiàn)lash-Decoding在處理非常大的序列時(shí)速度可以提高8倍,并且比其他方法具有更好的可擴(kuò)展性。所有方法在處理small prompts時(shí)表現(xiàn)相似,但隨著序列長(zhǎng)度從512增加到64k,其他方法的性能都變差了,而Flash-Decoding對(duì)序列長(zhǎng)度的增加并不敏感(下圖也是很好的證明)
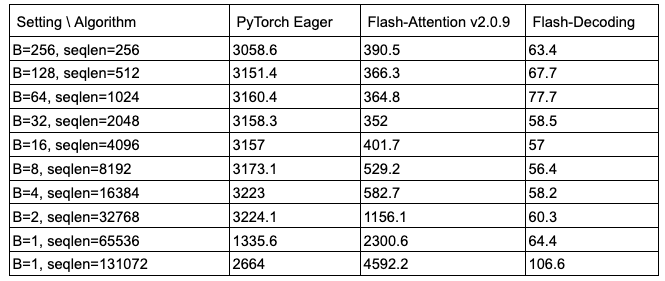
micro-benchmark on A100
Using Flash-Decoding
作者還通了Flash-Decoding使用方式:
基于FlashAttention package ,從版本2.2開始。
xFormers,在版本0.0.22中提供了xformers.ops.memory_efficient_attention模塊
作者也提供了LLaMa v2/CodeLLaMa的repo1和xFormers repo2。此外,作者還提供了一個(gè)針對(duì)LLaMa v1/v2的最小示例。
個(gè)人總結(jié)
Flash-Decoding對(duì)LLM在GPU上inference進(jìn)行了顯著加速(尤其是batch size較小時(shí)),并且在處理長(zhǎng)序列時(shí)具有更好的可擴(kuò)展性。
-
gpu
+關(guān)注
關(guān)注
28文章
4777瀏覽量
129362 -
模型
+關(guān)注
關(guān)注
1文章
3313瀏覽量
49233 -
LLM
+關(guān)注
關(guān)注
0文章
299瀏覽量
400
原文標(biāo)題:FlashAttenion-V3: Flash Decoding詳解
文章出處:【微信號(hào):GiantPandaCV,微信公眾號(hào):GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦


Necessary to disable "Above 4G Decoding" for View with vGPU?
MP3-FLASH-16P 使用說明書 V1.0
開源軟件-Morse_Encoding_Decoding摩斯密碼工具

瑞薩Flash程序員V3 發(fā)布說明





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論