 NVIDIA Merlin 助力陌陌推薦業務實現高性能訓練優化
NVIDIA Merlin 助力陌陌推薦業務實現高性能訓練優化
通過 Merlin 大幅提升大規模深度多目標精排模型訓練性能
本案例中,NVIDIA 團隊與陌陌推薦系統團隊深度合作,共同使用 NVIDIA GPU 和 Merlin 軟件解決方案替代其原有解決方案。
通過使用 Merlin TensorFlow Plugin (即 Sparse Operation Kit,SOK) 和 HierarchicalKV(HKV),相較于原方案在相同規模模型和 GPU 下,顯著提高了陌陌大規模深度多目標精排模型的訓練性能。在不影響模型效果的前提下,模型整體吞吐提升了 5 倍以上,再結合通信和 IO 等進一步優化后,極限情況下可以提升 12 倍吞吐。
客戶簡介
摯文集團于 2011 年成立,2014 年 12 月 11 日在美國納斯達克交易所掛牌上市(NASDAQ: MOMO),擁有陌陌、探探等多款手機應用,以及電影制作發行、節目制作等多元業務。陌陌是摯文集團于 2011 年 8 月推出的一款基于地理位置的移動視頻社交應用,是中國領先的開放式社交平臺之一。
訓練速度面臨挑戰,
需有效提升算法迭代
陌陌的原始解決方案本質是基于 PS-Worker 的 CPU + GPU 混合訓練方案,可支持大規模稀疏參數的訓練。然而,隨著用戶規模的增加和業務的發展,對于推薦算法的準確度也有了更高的要求。這導致模型的復雜性和訓練樣本量顯著增加,對單次模型訓練速度和新模型算法探索效率都有更大的挑戰。盡管原方案在功能上支持了大規模稀疏參數的訓練,但在性能上難以滿足業務日益增長的需求。因此,陌陌亟需對訓練速度進行優化,加快算法迭代,以提高業務效果。
SOK 和 HKV
為推薦系統提升性能與靈活性
NVIDIA Merlin HugeCTR 是 NVIDIA 推出的可以高效利用 GPU 來進行推薦系統訓練的解決方案,為了使它能直接被其他 DL 用戶,比如 TensorFlow 所直接使用,NVIDIA 開發了 Merlin TensorFlow Plugin (以下簡稱 SOK),將 HugeCTR 中的高級特性封裝為 TensorFlow 可直接調用的形式,從而幫助用戶在 TensorFlow 中直接使用 HugeCTR 中的高級特性來加速他們的推薦系統。
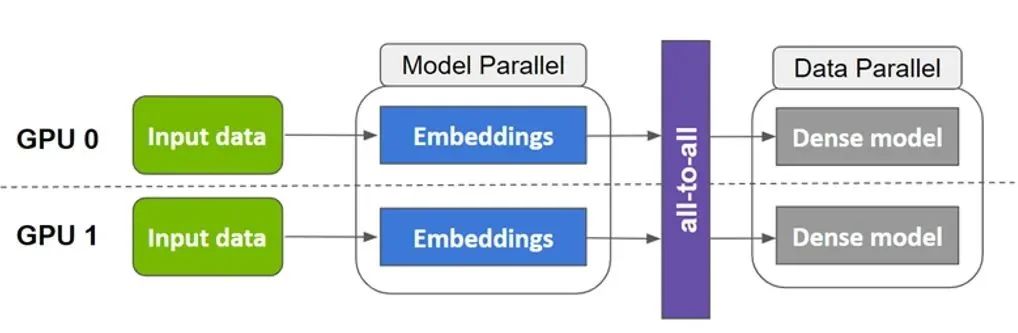
圖 1. Merlin TensorFlow Plugin(SOK)模型并行示意圖
Merlin TensorFlow Plugin 以數據并行的方式接收輸入數據,將稀疏參數以模型并行的方式分布在多個 GPU 上,將稠密參數以數據并行的方式分布在多個 GPU 上,內部實現“數據并行-模型并行-數據并行”的轉換流程。整個使用方式上盡可能的與原有 TensorFlow 算子對齊,減少對用戶已有的代碼的修改,以更方便、快捷地在多個 GPU 上進行擴展。此外,SOK 針對 embedding vector 的拷貝和 combiner 進行了高度優化和內核融合,使整個 lookup 的前后向過程擁有更好的性能。
Merlin HierarchicalKV (以下簡稱HKV)是 Merlin 下的針對于推薦系統訓練設計的 KV 加速庫。為兼容大模型訓練支持了層次化動態 Embedding 存儲(CPU+GPU),靈活的 eviction(淘汰) 機制和豐富的 API。目前已經集成入 SOK, 協同加速推薦系統 Embedding 的相關計算。
在應用了 SOK 和 HKV 后,相同規模模型和 GPU 下,陌陌精排模型的訓練性能相比于原方案,整體吞吐提升了 5 倍以上。除此之外,陌陌推薦團隊在當前 SOK + HKV 的架構基礎上,基于業務場景特點,進一步優化整體性能,包括梯度合并,減少梯度計算的通信開銷;并行特征數據讀取與轉換,以及特征數據預取到 GPU 等操作提速特征 IO;使用 XLA 進行編譯優化,融合 kernel 以減少 kernel launch 時間;設置 GPU 親和等操作,使得整體性能提升達到 12 倍。
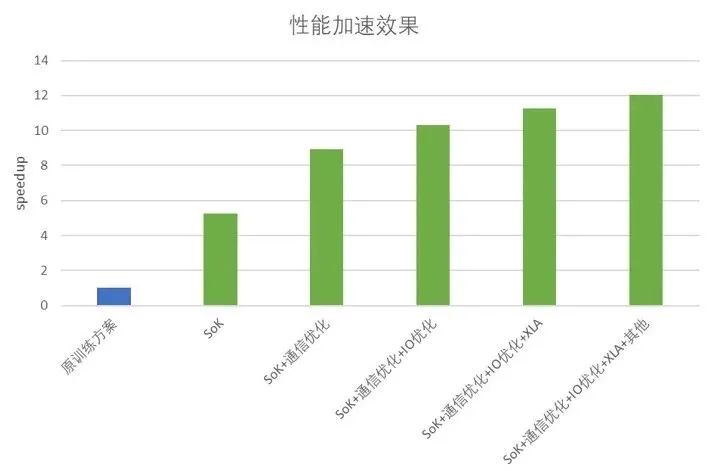
圖 2. 性能加速效果
在陌陌的實際應用中,動態 Embedding 的特性大大簡化了推薦系統中連續訓練需人工控制顯存中 embedding tab 大小的問題。而 SOK 與 HKV 為陌陌提供了完整的功能和性能支持。
除此之外,我們跟陌陌的合作過程中,也結合產品部署中的需求進一步對產品進行了性能優化和功能迭代,比如:
SOK 針對 embedding vector 的拷貝和 combiner 進行了高度優化和 kernel 融合,使整個 lookup 的前后向過程擁有更好的性能。
在陌陌 GPU 高水位線的實際業務中,基于陌陌的測試和反饋,SOK 通過優化了性能和功能的平衡點,使得其在保證性能的基礎上,穩定性也大大提升。
另外,在陌陌的實際應用中,面臨著模型實時訓練的挑戰,即需要減少對計算資源的占用,因此我們引入了 HKV,它支持了層次化動態嵌入存儲(包括 CPU 和 GPU),并提供了靈活的 eviction 機制以及豐富的 API。這種引入在降低資源占用的同時,也提高了系統的靈活性。
陌陌的實際業務場景和 GPU 使用方式對于 SOK 的開發和迭代提供了非常寶貴的經驗,同時陌陌的大量測試反饋也幫助 SOK 提升了應對復雜場景的能力,使得 SOK 的 feature 更加穩定和貼近客戶。
持續合作:
優化推薦模型性能,降低訓練成本
雙方團隊通過 SOK 和 HKV 對原方案進行深度優化后,成功幫助陌陌提升了 12 倍的訓練效率,極大的降低了模型訓練的成本和新模型算法嘗試的成本。目前,整體方案已上線,全面支持陌陌推薦系統模型訓練。
近期,NVIDIA 團隊還與陌陌進行了基于 Transformer 的推薦模型性能優化。NVIDIA JOC 團隊和 Merlin 團隊基于客戶的模型做了一系列性能分析,將 XLA+AMP+半精度 allreduce 應用到該模型上后,端到端性能實現了 50% 的加速。在此基礎上,團隊們進一步對性能熱點 multi-head-attention 部分進行優化,正在將 Flash-Attention 以 tf-plugin 形式進行集成,預計此項優化集成后,整體加速比可達到 3 倍,同時整體的優化方案使得顯存使用量下降約 70%,可以顯著地緩解顯存緊張的問題。
未來,陌陌與 NVIDIA 將繼續在推薦系統訓練和推理等方面持續合作,持續推進 GPU 和 AI 軟件加速計算在陌陌的全面落地,期待能夠為陌陌的業務及場景應用帶來更大的價值。
了解更多本案例中相關的 NVIDIA 產品信息,敬請查閱:
-
NVIDIA Merlin:
https://developer.nvidia.cn/merlin
-
Merlin TensorFlow Plugin (SOK) :
https://github.com/NVIDIA-Merlin/HugeCTR/tree/main/sparse_operation_kit
-
Merlin HierarchicalKV (HKV):
https://github.com/NVIDIA-Merlin/HierarchicalKV
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
原文標題:NVIDIA Merlin 助力陌陌推薦業務實現高性能訓練優化
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3848瀏覽量
91985
原文標題:NVIDIA Merlin 助力陌陌推薦業務實現高性能訓練優化
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區 助力打造高性能原生應用
怎么做電子元器件的銷售啊,不知道如何去地推陌拜,有沒有師哥能幫我解答一下,跪謝~
全新NVIDIA NIM微服務實現突破性進展
NVIDIA AI助力實現更好的癌癥檢測
2024CHINTERGEO武漢測繪展,帆陌科技攜創新無人機保險產品、技術首亮相

什么是協議分析儀和訓練器
NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案

NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

SOK在手機行業的應用案例
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
降本增效:NVIDIA路徑優化引擎創下多項世界紀錄!
基于NVIDIA Megatron Core的MOE LLM實現和訓練優化

NVIDIA 發布全新交換機,全面優化萬億參數級 GPU 計算和 AI 基礎設施






 工商網監
工商網監
評論