 如何實現一個高性能內存池
如何實現一個高性能內存池
寫在前面
本文的內存池代碼是改編自Nginx的內存池源碼,思路幾乎一樣。由于Nginx源碼的變量命名我不喜歡,又沒有注釋,看得我很難受。想自己寫一版容易理解的代碼。
應用場景
寫內存池的原理之前,按照慣例先說內存池的應用場景。
為什么我們需要內存池?
- 因為malloc等分配內存的方式,需要涉及到系統調用sbrk,頻繁的malloc和free會消耗系統資源。
既然如此,我們就預先在用戶態創建一個緩存空間,作為內存池。
每次malloc的時候,從用戶態的內存池中獲得分配的內存,不走系統調用,就能像賽車加氮氣一樣超級加速內存管理。
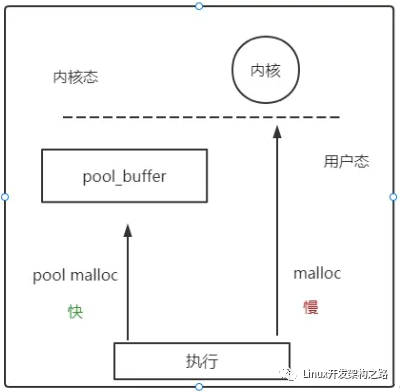
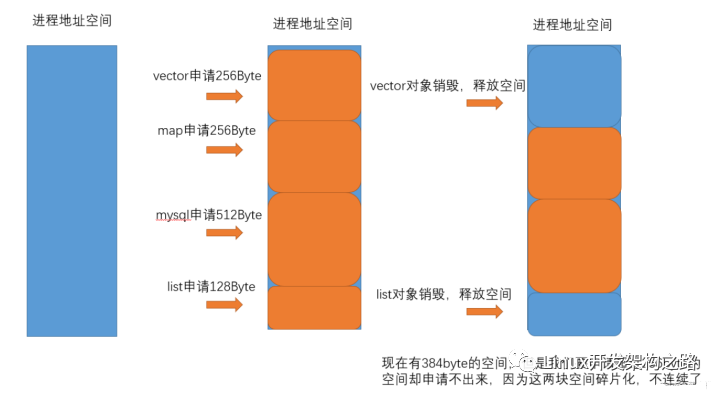
2.如果頻繁地malloc和free,由于malloc的地址是不確定的,因為每次malloc的時候,會先在freelist中找一個適合其大小的塊,如果找不到,才會調用sbrk直接拓展堆的內存邊界。(freelist是之前free掉的內存,內核會將其組織成一個鏈表,留待下次malloc的時候查找使用。)
因為不確定,所以容易產生內存碎片。

如果我們需要4個字節的空間,卻因為malloc的位置隨機分配在這個滑稽的位置,就導致雖然我們有2+2的空間但是只能望洋興嘆的尷尬處境。
Nginx內存池的特點
nginx中線程池與內存池都是池,核心思想都是對系統的資源調度起一個緩沖的作用,但是多少還是有點區別。
對于線程池來說,兩隊列+中樞的架構,在不同公司的框架實現都大同小異。
但是內存池卻是在不同的框架中,實現不盡相同。
為什么會有區別,根本原因是面向的實際業務不同,從而導致不同公司的內存池會靈活變通,有各自鮮明的特點。
在Nginx的服務器中,每當有一個客戶端connect進來后,就會為其單獨創建一個內存池,用于recv和send的緩沖區buffer。
所以Nginx的內存池的特點是,其包含了兩種內存分配方式,大內存和小內存使用不同的數據結構來存儲。從而適應客戶端不同的請求,如果只是一些簡單的表單,就用小內存,如果是上傳下載大文件,就用大內存。
同時Nginx的內存池還有一個重要的特點:不像線程池會回收利用所有線程,Nginx的內存池不回收小內存的buffer,只回收大內存的buffer。
同樣是出于實際業務的考慮,每個內存池都對應一個客戶,那么一個客戶端產生的小內存碎片自然不會太多,即使不回收,也不會有太大代價。
同時tcp本身就有keep-alive機制,超過一定時間就斷開,Nginx是典型的將不同客戶端分發到多進程的網絡模型,連接斷開,進程結束,從而對應的內存池會釋放,相當于一次性回收所有的大小內存。
但是在連接中大內存因為占用空間大,Nginx覺得還是有必要回收,所以只做了回收大內存這個接口。
數據結構
我們先講核心的,小內存的實現。
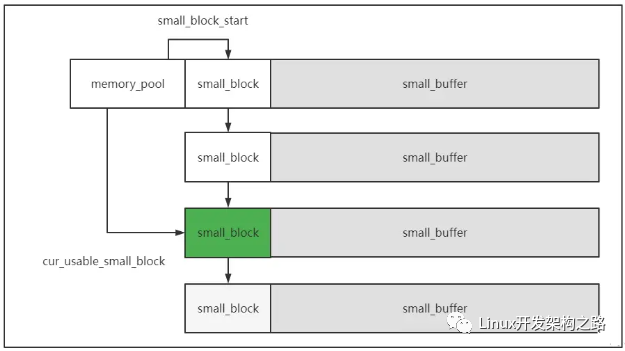
首先整個內存池pool中有兩條鏈,一條是big block鏈,一條是small block鏈。
一個small block我們可以看做是一個小緩沖區,而整條鏈的小緩沖區串起來組成一個大緩沖區,就是內存池了。
small block數據結構如下:
public:
char * cur_usable_buffer;
char * buffer_end;
small_block * next_block;
int no_enough_times;
};
- cur_usable_buffer:指向該block的可用buffer的首地址
- buffer_end:指向該block的buffer的結尾地址
- next_block: 指向block鏈的下一個small block
- no_enough_times:每次分配內存,都要順著small block鏈,找鏈中的每個小緩沖區看是否有足夠分配的內存,如果在該block沒找到,就會將該值+1,代表沒有足夠空間命中的次數。
對于small block,我們看它的格局要更上層一點,達到看山不是山,看水不是水的境界,因為它不僅僅是單獨的block對象,還代表了后面跟著的buffer,當鏈中所有小緩沖區都不夠位置分配新的空間時,就會創建新的small block,而創建的時候,會一次性創建small_block+buffer_capacity大小的空間。
為什么要這么設置,而不是先malloc一個small_block,再malloc一個small_buffer,別問,問就是不優雅,像這樣分配內存,相當于兩個連在一起形成一個整塊,很舒適,適合強迫癥,而不是東一塊隨機地址,西一塊隨機地址,那還叫池嗎?干脆叫地下水管道吧,一堆支流。
我們不需要在small_block的數據結構中存buffer的首地址指針,因為很自然的是,我們拿到small_block的指針后自然也就拿到了buffer的首地址指針
即 buffer_head_ptr = (char*)small_block + sizeof(small_block);
small_block中各指針的指向:

然后是整個內存池pool的數據結構
public:
size_t small_buffer_capacity;
small_block * cur_usable_small_block;
big_block * big_block_start;
small_block small_block_start[0];
//-----------------------------上面是成員,下面是api--------------------------------------------
static memory_pool * createPool(size_t capacity);
static void destroyPool(memory_pool * pool);
static char* createNewSmallBlock(memory_pool * pool,size_t size);
static char* mallocBigBlock(memory_pool * pool,size_t size);
static void* poolMalloc(memory_pool * pool,size_t size);
static void freeBigBlock(memory_pool * pool, char *buffer_ptr);
};
- small_buffer_capacity:對于Nginx的內存池,每個small buffer的大小都是一樣的,所以該值代表了small buffer的容量,在創建內存池的時候作為參數確定。
- cur_usable_small_block:每次要分配小內存的時候,并不會從頭開始找合適的空間,而是從這個指針指向的small_block開始找。
- big_block_start:big block鏈的鏈頭
- small_block_start:small block的鏈頭。
這里要提一點的是,該類的最后一個成員small_block_start,其為一個長度為0的數組,這在C99中是一種柔性數組的寫法,所以比較吃編譯器,我是在linux環境下編譯,沒什么問題,但是vs環境可能會報錯,如果報錯就設置長度為1。
為什么要這么設置,后面講第一個api createPool 的時候會說。
還有全員使用靜態成員方法也是與此有關,因為Nginx是純C寫的,我使用靜態成員方法也是一種兼容C的面向過程函數的變種吧(笑~)。
最后是big block的數據結構
public:
char * big_buffer;
big_block * next_block;
};
- big_buffer:大內存buffer的首地址
- next_block:因為big block也是鏈式結構,指向下一個big block
big block最簡單,因為Nginx似乎不在乎big block優不優雅了,其big_block和big_buffer的地址就是分開的,不會連在一起。

接口實現
創建內存池 createPool:
這里需要再次提到剛剛的柔性數組,small_block_start
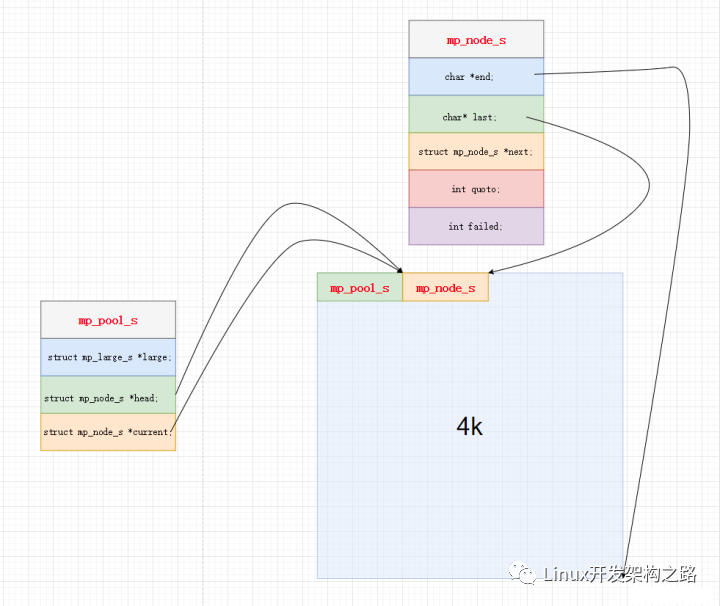
Nginx希望創建內存池pool的時候,不是單獨一個孤零零的pool對象,而是創建pool的同時,就創建第一個small_block,而創建一個新的small_block又需要同步建立一個small_buffer,而Nginx希望這三個對象的內存是連起來的,如圖所示,于是優雅再次出現。
柔性數組的意義在于,我們希望在memory_pool保留一個指針錨點來指向第一個small_block而不是通過剛剛的指針加法來找到small_block的首地址,那便使用一個0長度的數組作為這個錨點。
這樣malloc整段內存,small_block就會接在memory_pool的后面,且以small_block_start的形式成為pool的成員,實際上small_block_start長度為0是不占pool的內存空間的。
而為什么使用靜態成員函數也是這個原因,使用柔性數組必須保證其位置定義在整個類的內存空間的末尾,靜態函數雖然在類中聲明,但是實際會存放在靜態區中保存,不占用類的內存。
//-創建內存池并初始化,api以靜態成員(工廠)的方式模擬C風格函數實現
//-capacity是buffer的容量,在初始化的時候確定,后續所有小塊的buffer都是這個大小
memory_pool * memory_pool::createPool(size_t capacity){//-我們先分配一大段連續內存,該內存可以想象成這段內存由pool+small_block+small_block_buffers三個部分組成.
//-為什么要把三個部分(可以理解為三個對象)用連續內存來存,因為這樣整個池看起來比較優雅.各部分地址不會天女散花地落在內存的各個角落.
size_t total_size = sizeof(memory_pool)+sizeof(small_block)+capacity;
void *temp = malloc(total_size);
memset(temp,0,total_size);
memory_pool * pool = (memory_pool*)temp;
fprintf(stdout,"pool address:%pn",pool);
//-此時temp是pool的指針,先來初始化pool對象
pool ->small_buffer_capacity = capacity;
pool ->big_block_start = nullptr;
pool ->cur_usable_small_block = (small_block*)(pool->small_block_start);
//-pool+1的1是整個memory_pool的步長,別弄錯了。此時sbp是small_block的指針
small_block * sbp = (small_block*)(pool+1);
fprintf(stdout,"first small block address:%pn",sbp);
//-初始化small_block對象
sbp -> cur_usable_buffer = (char*)(sbp+1);
fprintf(stdout,"first small block buffer address:%pn",sbp->cur_usable_buffer);
sbp -> buffer_end = sbp->cur_usable_buffer+capacity;//-第一個可用的buffer就是開頭,所以end=開頭+capacity
sbp -> next_block = nullptr;
sbp -> no_enough_times = 0;
return pool;
};
代替malloc的分配內存的接口:poolMalloc
第一步,我們判斷poolMalloc的size是一個大內存還是小內存。
如果是大內存就走mallocBigBlock這個api。
如果是小內存,就從cur_usable_small_block這個small block開始找足夠的空間去分配內存,注意并不是從small block鏈的開頭開始尋找。因為大概率cur_usable_small_block之前的所有small block都已經分配完了,所以為了提高命中效率,需要這樣一個指針指向尋找的開始。
對于每個small block,我們直接用buffer_end 和 cur_usable_buffer相減就可以得到一個small buffer的剩余容量去判斷是否能分配。

如果空間足夠,就從cur_usable_buffer開始分配size大小的空間,并返回這段空間的首地址,同時更新cur_usable_buffer指向新的剩余空間。
如果直到鏈的末尾都沒有足夠的size大小的空間,那就需要創建新的small block,走createNewSmallBlock這個api。
void* memory_pool::poolMalloc(memory_pool * pool,size_t size){
//-先判斷要malloc的是大內存還是小內存
if(sizesmall_buffer_capacity){//-如果是小內存
//-從cur small block開始尋找
small_block * temp = pool -> cur_usable_small_block;
do{
//-判斷當前small block的buffer夠不夠分配
//-如果夠分配,直接返回
if(temp->buffer_end-temp->cur_usable_buffer>size){
char * res = temp->cur_usable_buffer;
temp -> cur_usable_buffer = temp->cur_usable_buffer+size;
return res;
}
temp = temp->next_block;
}while (temp);
//-如果最后一個small block都不夠分配,則創建新的small block;
//-該small block在創建后,直接預先分配size大小的空間,所以返回即可.
return createNewSmallBlock(pool,size);
}
//-分配大內存
return mallocBigBlock(pool,size);
}
創建新的小內存塊:createNewSmallBlock
首先創建一個smallblock和連帶的buffer,還是如這張圖所示:

因為我們創建的目的是為了分配size空間,所以初始化后,便預留size大小的buffer,對cur_usable_buffer進行更新。
值得提的是,每次到了創建新的small block的環節,就意味著目前鏈上的small buffer空間已經都分配得差不多了,可能需要更新cur_usable_small_block,這就需要用到small block的no_enough_times成員,將cur_usable_small_block開始的每個small block的該值++,Nginx設置的經驗值閾值是4,超過4,意味著該block不適合再成為尋找的開始了,需要往后繼續嘗試。
char* memory_pool::createNewSmallBlock(memory_pool * pool,size_t size){
//-先創建新的small block,注意還有buffer
size_t malloc_size = sizeof(small_block)+pool->small_buffer_capacity;
void * temp = malloc(malloc_size);
memset(temp,0,malloc_size);
//-初始化新的small block
small_block * sbp = (small_block *)temp;
fprintf(stdout,"new small block address:%pn",sbp);
sbp -> cur_usable_buffer = (char*)(sbp+1);//-跨越一個small_block的步長
fprintf(stdout,"new small block buffer address:%pn",sbp->cur_usable_buffer);
sbp -> buffer_end = (char*)temp+malloc_size;
sbp -> next_block = nullptr;
sbp -> no_enough_times = 0;
//-預留size空間給新分配的內存
char* res = sbp -> cur_usable_buffer;//-存個副本作為返回值
sbp -> cur_usable_buffer = res+size;
//-因為目前的所有small_block都沒有足夠的空間了。
//-意味著可能需要更新線程池的cur_usable_small_block,也就是尋找的起點
small_block * p = pool -> cur_usable_small_block;
while(p->next_block){
if(p->no_enough_times>4){
pool -> cur_usable_small_block = p->next_block;
}
++(p->no_enough_times);
p = p->next_block;
}
//-此時p正好指向當前pool中最后一個small_block,將新節點接上去。
p->next_block = sbp;
//-因為最后一個block有可能no_enough_times>4導致cur_usable_small_block更新成nullptr
//-所以還要判斷一下
if(pool -> cur_usable_small_block == nullptr){
pool -> cur_usable_small_block = sbp;
}
return res;//-返回新分配內存的首地址
}
分配大內存空間:mallocBigBlock
如果size超過了預設的capacity,那就會走這個api。
其同樣也是一個鏈式查找的過程,只不過比查找small block更快更粗暴。
big block鏈沒有類似cur_usable_small_block這樣的節點,只要從頭開始遍歷,如果有空buffer就返回該block,如果超過3個還沒找到(同樣是Nginx的經驗值)就直接不找了,創建新的big block。
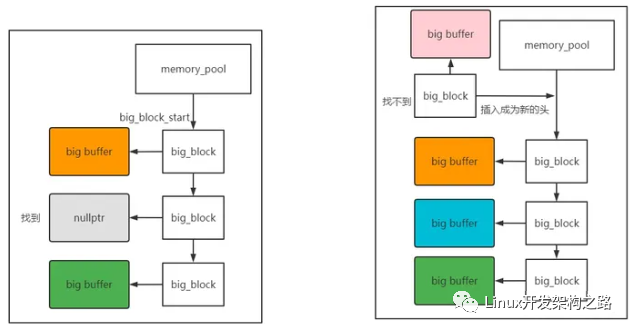
還有一點值得注意的是,big_buffer是個大內存,所以其是個malloc的隨機地址,
但是big_block本身是一個小內存,那就不應該還是用隨機地址,應該保存在內存池內部的空間。
所以這里有個套娃的內存池poolMalloc操作,用來分配big_block的空間。
char* memory_pool::mallocBigBlock(memory_pool * pool,size_t size){
//-先分配size大小的空間
void*temp = malloc(size);
memset(temp, 0, size);
//-從big_block_start開始尋找,注意big block是一個棧式鏈,插入新元素是插入到頭結點的位置。
big_block * bbp = pool->big_block_start;
int i = 0;
while(bbp){
if(bbp->big_buffer == nullptr){
bbp->big_buffer = (char*)temp;
return bbp->big_buffer;
}
if(i>3){
break;//-為了保證效率,如果找三輪還沒找到有空buffer的big_block,就直接建立新的big_block
}
bbp = bbp->next_block;
++i;
}
//-創建新的big_block,這里比較難懂的點,就是Nginx覺得big_block的buffer雖然是一個隨機地址的大內存
//-但是big_block本身算一個小內存,那就不應該還是用隨機地址,應該保存在內存池內部的空間。
//-所以這里有個套娃的內存池malloc操作
big_block* new_bbp = (big_block*)memory_pool::poolMalloc(pool,sizeof(big_block));
//-初始化
new_bbp -> big_buffer = (char*)temp;
new_bbp ->next_block = pool->big_block_start;
pool -> big_block_start = new_bbp;
//-返回分配內存的首地址
return new_bbp->big_buffer;
}
釋放大內存:freeBigBlock:
由于big block是一個鏈式結構,所以要找到對應的buffer并free掉,就需要從這個鏈的開頭開始遍歷,一直到找到位置。
void memory_pool::freeBigBlock(memory_pool * pool, char *buffer_ptr){
big_block* bbp = pool -> big_block_start;
while(bbp){
if(bbp->big_buffer == buffer_ptr){
free(bbp->big_buffer);
bbp->big_buffer = nullptr;
return;
}
bbp = bbp->next_block;
}
}
銷毀線程池:destroyPool:
這個思路也很簡單,pool中有兩條鏈分別指向大內存和小內存,那么分別沿著這兩條鏈去free掉內存即可,由于大內存的buffer和big block不是一起malloc的,所以只需要free掉buffer,而big block是分配在小內存池中的,所以,之后free掉小內存的時候會順帶一起free掉。
比較值得注意的一點是,small鏈的free不是從第一個small block開始的,而是第二個small block。如圖所示,第一個small block的空間是和pool一起malloc出來的,不需要free,只要最后的時候free pool就會一起釋放掉。

void memory_pool::destroyPool(memory_pool * pool){
//-銷毀大內存
big_block * bbp = pool->big_block_start;while(bbp){
if(bbp->big_buffer){
free(bbp->big_buffer);
bbp->big_buffer = nullptr;
}
bbp = bbp->next_block;
}
//-為什么不刪除big_block節點?因為big_block在小內存池中,等會就和小內存池一起銷毀了
//-銷毀小內存
small_block * temp = pool -> small_block_start->next_block;
while(temp){
small_block * next = temp -> next_block;
free(temp);
temp = next;
}
free(pool);
}
測試代碼
測試一下用內存池分配的地址是否如我們所設計的那樣。
memory_pool * pool = memory_pool::createPool(1024);
//-分配小內存
char*p1 = (char*)memory_pool::poolMalloc(pool,2);
fprintf(stdout,"little malloc1:%pn",p1);
char*p2 = (char*)memory_pool::poolMalloc(pool,4);
fprintf(stdout,"little malloc2:%pn",p2);
char*p3 = (char*)memory_pool::poolMalloc(pool,8);
fprintf(stdout,"little malloc3:%pn",p3);
char*p4 = (char*)memory_pool::poolMalloc(pool,256);
fprintf(stdout,"little malloc4:%pn",p4);
char*p5 = (char*)memory_pool::poolMalloc(pool,512);
fprintf(stdout,"little malloc5:%pn",p5);
//-測試分配不足開辟新的small block
char*p6 = (char*)memory_pool::poolMalloc(pool,512);
fprintf(stdout,"little malloc6:%pn",p6);
//-測試分配大內存
char*p7 = (char*)memory_pool::poolMalloc(pool,2048);
fprintf(stdout,"big malloc1:%pn",p7);
char*p8 = (char*)memory_pool::poolMalloc(pool,4096);
fprintf(stdout,"big malloc2:%pn",p8);
//-測試free大內存
memory_pool::freeBigBlock(pool, p8);
//-測試再次分配大內存(我這里測試結果和p8一樣)
char*p9 = (char*)memory_pool::poolMalloc(pool,2048);
fprintf(stdout,"big malloc3:%pn",p9);
//-銷毀內存池
memory_pool::destroyPool(pool);
exit(EXIT_SUCCESS);
}
完整代碼
// * 修改了很多nginx中晦澀的變量名,比較容易理解
#include
#include
#include
using namespace std;
class small_block{
public:
char * cur_usable_buffer;
char * buffer_end;
small_block * next_block;
int no_enough_times;
};
class big_block{
public:
char * big_buffer;
big_block * next_block;
};
class memory_pool{
public:
size_t small_buffer_capacity;
small_block * cur_usable_small_block;
big_block * big_block_start;
small_block small_block_start[0];
static memory_pool * createPool(size_t capacity);
static void destroyPool(memory_pool * pool);
static char* createNewSmallBlock(memory_pool * pool,size_t size);
static char* mallocBigBlock(memory_pool * pool,size_t size);
static void* poolMalloc(memory_pool * pool,size_t size);
static void freeBigBlock(memory_pool * pool, char *buffer_ptr);
};
//-創建內存池并初始化,api以靜態成員(工廠)的方式模擬C風格函數實現
//-capacity是buffer的容量,在初始化的時候確定,后續所有小塊的buffer都是這個大小
memory_pool * memory_pool::createPool(size_t capacity){
//-我們先分配一大段連續內存,該內存可以想象成這段內存由pool+small_block+small_block_buffers三個部分組成.
//-為什么要把三個部分(可以理解為三個對象)用連續內存來存,因為這樣整個池看起來比較優雅.各部分地址不會天女散花地落在內存的各個角落.
size_t total_size = sizeof(memory_pool)+sizeof(small_block)+capacity;
void *temp = malloc(total_size);
memset(temp,0,total_size);
memory_pool * pool = (memory_pool*)temp;
fprintf(stdout,"pool address:%pn",pool);
//-此時temp是pool的指針,先來初始化pool對象
pool ->small_buffer_capacity = capacity;
pool ->big_block_start = nullptr;
pool ->cur_usable_small_block = (small_block*)(pool->small_block_start);
//-pool+1的1是整個memory_pool的步長,別弄錯了。此時sbp是small_block的指針
small_block * sbp = (small_block*)(pool+1);
fprintf(stdout,"first small block address:%pn",sbp);
//-初始化small_block對象
sbp -> cur_usable_buffer = (char*)(sbp+1);
fprintf(stdout,"first small block buffer address:%pn",sbp->cur_usable_buffer);
sbp -> buffer_end = sbp->cur_usable_buffer+capacity;//-第一個可用的buffer就是開頭,所以end=開頭+capacity
sbp -> next_block = nullptr;
sbp -> no_enough_times = 0;
return pool;
};
//-銷毀內存池
void memory_pool::destroyPool(memory_pool * pool){
//-銷毀大內存
big_block * bbp = pool->big_block_start;
while(bbp){
if(bbp->big_buffer){
free(bbp->big_buffer);
bbp->big_buffer = nullptr;
}
bbp = bbp->next_block;
}
//-為什么不刪除big_block節點?因為big_block在小內存池中,等會就和小內存池一起銷毀了
//-銷毀小內存
small_block * temp = pool -> small_block_start->next_block;
while(temp){
small_block * next = temp -> next_block;
free(temp);
temp = next;
}
free(pool);
}
//-當所有small block都沒有足夠空間分配,則創建新的small block并分配size空間,返回分配空間的首指針
char* memory_pool::createNewSmallBlock(memory_pool * pool,size_t size){
//-先創建新的small block,注意還有buffer
size_t malloc_size = sizeof(small_block)+pool->small_buffer_capacity;
void * temp = malloc(malloc_size);
memset(temp,0,malloc_size);
//-初始化新的small block
small_block * sbp = (small_block *)temp;
fprintf(stdout,"new small block address:%pn",sbp);
sbp -> cur_usable_buffer = (char*)(sbp+1);//-跨越一個small_block的步長
fprintf(stdout,"new small block buffer address:%pn",sbp->cur_usable_buffer);
sbp -> buffer_end = (char*)temp+malloc_size;
sbp -> next_block = nullptr;
sbp -> no_enough_times = 0;
//-預留size空間給新分配的內存
char* res = sbp -> cur_usable_buffer;//-存個副本作為返回值
sbp -> cur_usable_buffer = res+size;
//-因為目前的所有small_block都沒有足夠的空間了。
//-意味著可能需要更新線程池的cur_usable_small_block,也就是尋找的起點
small_block * p = pool -> cur_usable_small_block;
while(p->next_block){
if(p->no_enough_times>4){
pool -> cur_usable_small_block = p->next_block;
}
++(p->no_enough_times);
p = p->next_block;
}
//-此時p正好指向當前pool中最后一個small_block,將新節點接上去。
p->next_block = sbp;
//-因為最后一個block有可能no_enough_times>4導致cur_usable_small_block更新成nullptr
//-所以還要判斷一下
if(pool -> cur_usable_small_block == nullptr){
pool -> cur_usable_small_block = sbp;
}
return res;//-返回新分配內存的首地址
}
//-分配大塊的內存
char* memory_pool::mallocBigBlock(memory_pool * pool,size_t size){
//-先分配size大小的空間
void*temp = malloc(size);
memset(temp, 0, size);
//-從big_block_start開始尋找,注意big block是一個棧式鏈,插入新元素是插入到頭結點的位置。
big_block * bbp = pool->big_block_start;
int i = 0;
while(bbp){
if(bbp->big_buffer == nullptr){
bbp->big_buffer = (char*)temp;
return bbp->big_buffer;
}
if(i>3){
break;//-為了保證效率,如果找三輪還沒找到有空buffer的big_block,就直接建立新的big_block
}
bbp = bbp->next_block;
++i;
}
//-創建新的big_block,這里比較難懂的點,就是Nginx覺得big_block的buffer雖然是一個隨機地址的大內存
//-但是big_block本身算一個小內存,那就不應該還是用隨機地址,應該保存在內存池內部的空間。
//-所以這里有個套娃的內存池malloc操作
big_block* new_bbp = (big_block*)memory_pool::poolMalloc(pool,sizeof(big_block));
//-初始化
new_bbp -> big_buffer = (char*)temp;
new_bbp ->next_block = pool->big_block_start;
pool -> big_block_start = new_bbp;
//-返回分配內存的首地址
return new_bbp->big_buffer;
}
//-分配內存
void* memory_pool::poolMalloc(memory_pool * pool,size_t size){
//-先判斷要malloc的是大內存還是小內存
if(sizesmall_buffer_capacity){//-如果是小內存
//-從cur small block開始尋找
small_block * temp = pool -> cur_usable_small_block;
do{
//-判斷當前small block的buffer夠不夠分配
//-如果夠分配,直接返回
if(temp->buffer_end-temp->cur_usable_buffer>size){
char * res = temp->cur_usable_buffer;
temp -> cur_usable_buffer = temp->cur_usable_buffer+size;
return res;
}
temp = temp->next_block;
}while (temp);
//-如果最后一個small block都不夠分配,則創建新的small block;
//-該small block在創建后,直接預先分配size大小的空間,所以返回即可.
return createNewSmallBlock(pool,size);
}
//-分配大內存
return mallocBigBlock(pool,size);
}
//-釋放大內存的buffer,由于是一個鏈表,所以,確實,這是效率最低的一個api了
void memory_pool::freeBigBlock(memory_pool * pool, char *buffer_ptr){
big_block* bbp = pool -> big_block_start;
while(bbp){
if(bbp->big_buffer == buffer_ptr){
free(bbp->big_buffer);
bbp->big_buffer = nullptr;
return;
}
bbp = bbp->next_block;
}
}
int main(){
memory_pool * pool = memory_pool::createPool(1024);
//-分配小內存
char*p1 = (char*)memory_pool::poolMalloc(pool,2);
fprintf(stdout,"little malloc1:%pn",p1);
char*p2 = (char*)memory_pool::poolMalloc(pool,4);
fprintf(stdout,"little malloc2:%pn",p2);
char*p3 = (char*)memory_pool::poolMalloc(pool,8);
fprintf(stdout,"little malloc3:%pn",p3);
char*p4 = (char*)memory_pool::poolMalloc(pool,256);
fprintf(stdout,"little malloc4:%pn",p4);
char*p5 = (char*)memory_pool::poolMalloc(pool,512);
fprintf(stdout,"little malloc5:%pn",p5);
//-測試分配不足開辟新的small block
char*p6 = (char*)memory_pool::poolMalloc(pool,512);
fprintf(stdout,"little malloc6:%pn",p6);
//-測試分配大內存
char*p7 = (char*)memory_pool::poolMalloc(pool,2048);
fprintf(stdout,"big malloc1:%pn",p7);
char*p8 = (char*)memory_pool::poolMalloc(pool,4096);
fprintf(stdout,"big malloc2:%pn",p8);
//-測試free大內存
memory_pool::freeBigBlock(pool, p8);
//-測試再次分配大內存(我這里測試結果和p8一樣)
char*p9 = (char*)memory_pool::poolMalloc(pool,2048);
fprintf(stdout,"big malloc3:%pn",p9);
//-銷毀內存池
memory_pool::destroyPool(pool);
exit(EXIT_SUCCESS);
}
-
內存
+關注
關注
8文章
3055瀏覽量
74331 -
緩存
+關注
關注
1文章
241瀏覽量
26757 -
源碼
+關注
關注
8文章
652瀏覽量
29454 -
nginx
+關注
關注
0文章
154瀏覽量
12234
發布評論請先 登錄
相關推薦
詳解內存池技術的原理與實現
C++內存池的設計與實現
采用GDDR6的高性能內存解決方案
Linux下一種高性能定時器池的實現
突破性能瓶頸,實現CPU與內存高性能互連
什么是內存池

內存池主要解決的問題





 工商網監
工商網監
評論