 NVIDIA AI Foundation Models:使用生產就緒型 LLM 構建自定義企業聊天機器人和智能副駕
NVIDIA AI Foundation Models:使用生產就緒型 LLM 構建自定義企業聊天機器人和智能副駕

大語言模型(LLM)正在徹底變革數據科學,帶來自然語言理解、AI 和機器學習的高級功能。為洞悉特定領域而定制的自定義 LLM 在企業應用中越來越受到青睞。
NVIDIA Nemotron-3 8B系列基礎模型是一套功能強大的全新工具,可用于為企業構建生產就緒生成式 AI 應用,從而推動從客服 AI 聊天機器人到尖端 AI 產品的各種創新。
這些新的基礎模型現已加入NVIDIA NeMo。這個端到端框架用于構建、自定義和部署專為企業定制的 LLM。企業現在可以使用這些工具快速且經濟高效地大規模開發 AI 應用。這些應用可在云端、數據中心以及 Windows PC 和筆記本電腦上運行。
Nemotron-3 8B 系列現已在 Azure AI Model 目錄、HuggingFace 和NVIDIA NGC 目錄上的NVIDIA AI Foundation Model中心提供。該系列包含基本模型、聊天模型和問答(Q&A)模型,可解決各種下游任務。表 1 列出了該系列的所有模型。
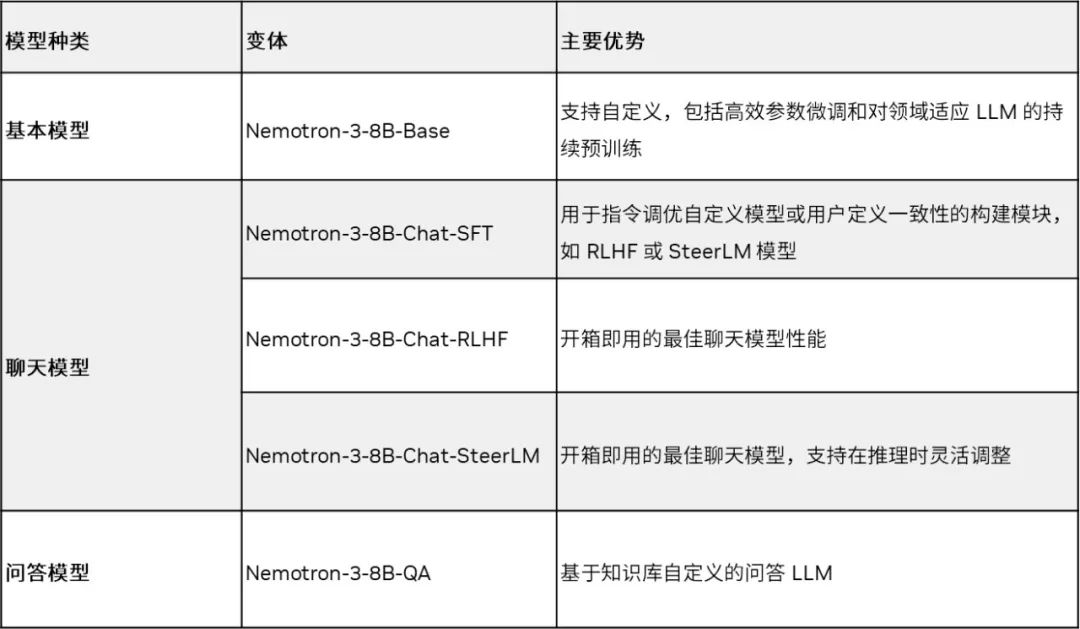
表 1. Nemotron-3 8B 系列基礎模型支持多種 LLM 用例
設計用于生產的基礎模型
基礎模型是強大的構建模塊,它減少了構建實用的自定義應用所需的時間和資源。然而,企業機構必須確保這些模型符合其具體需求。
NVIDIA AI Foundation Models 基于來源可靠的數據集訓練而成,集合了無數聲音和體驗。嚴格監控確保了數據的真實性,并符合不斷變化發展的法律規定。任何出現的數據問題都會迅速得到解決,確保企業的 AI 應用既符合法律規范,又能保護用戶隱私。這些模型既能吸收公開數據集,也能兼容專有數據集。
Nemotron-3-8B 基本模型
Nemotron-3-8B 基本模型是一種用于生成類人文本或代碼的緊湊型高性能模型。該模型的 MMLU 5 樣本平均值為 54.4。該基本模型還精通 53 種語言,包括英語、德語、俄語、西班牙語、法語、日語、中文、意大利語和荷蘭語,因此能滿足跨國企業對多語言能力的需求。該基本模型還經過 37 種不同編碼語言的訓練。
Nemotron-3-8B 聊天模型
該套件還添加了 Nemotron-3-8B 聊天模型,用于 LLM 驅動的聊天機器人交互。Nemotron-3-8B 聊天模型有三個版本,每個版本均針對特定用戶的獨特調整而設計:
-
監督微調(SFT)
-
人類反饋強化學習(RLHF)
-
NVIDIA SteerLM(https://blogs.nvidia.com/blog/2023/10/11/customize-ai-models-steerlm/)
Nemotron-3-8B-SFT 模型是指令微調的第一步,我們在此基礎上建立了 RLHF 模型,該模型是 8B 類別中 MT-Bench 分數最高的模型(MT-Bench 是最常用的聊天質量指標)。用戶可以從使用 8B-chat-RLHF 開始,以獲得最佳的即時聊天互動效果。但對于希望與最終用戶的偏好保持一致的企業,可以在使用 SFT 模型的同時,應用自己的 RLHF。
最后,最新的對齊方法 SteerLM 為訓練和自定義推理 LLM 提供了新的靈活性。借助 SteerLM,用戶可以定義其所需的所有屬性,并將其嵌入單個模型中,然后就可以在該模型運行時為特定用例選擇其所需的組合。
這種方法支持持續的改進周期。自定義模型響應可以作為未來訓練的數據,從而將模型的實用性提升到新的水平。
Nemotron-3-8B 問答模型
Nemotron-3-8B-QA 模型是一個問答(QA)模型,該模型在大量數據基礎上針對目標用例進行微調。
Nemotron-3-8B-QA 模型的性能一流,在 Natural Questions 數據集(https://ai.google.com/research/NaturalQuestions/)上實現了 41.99% 的零樣本 F1 分數。該指標用于衡量生成的答案與問答中真實答案的相似程度。
Nemotron-3-8B-QA 模型已與其他參數規模更大的先進語言模型進行了對比測試。測試是在 NVIDIA 創建的數據集以及 Natural Questions 和 Doc2Dial 數據集上進行的。結果表明,該模型具有良好的性能。
使用 NVIDIA NeMo 框架
構建自定義 LLM
NVIDIA NeMo 通過為多種模型架構提供端到端功能和容器化方案,簡化了構建自定義企業生成式 AI 模型的路徑。借助 Nemotron-3-8B 系列模型,開發者就可以使用 NVIDIA 提供的預訓練模型,這些模型可以輕松適應特定用例。
快速模型部署
使用 NeMo 框架時,無需收集數據或設置基礎架構。NeMo 精簡了這一過程。開發者可以自定義現有模型,并將其快速部署到生產中。
最佳模型性能
此外,它還與NVIDIA TensorRT-LLM開源庫和NVIDIA Triton 推理服務器無縫集成,前者可優化模型性能,后者可加速推理服務流程。這種工具組合實現了最先進的準確性、低延遲和高吞吐量。
數據隱私和安全
NeMo 可實現安全、高效的大規模部署,并符合相關安全法規規定。例如,如果數據隱私是業務的關鍵問題,就可以使用NeMo Guardrails在不影響性能或可靠性的情況下安全存儲客戶數據。
總之,使用 NeMo 框架構建自定義 LLM 是在不犧牲質量或安全標準的情況下、快速創建企業 AI 應用的有效方法。它為開發者提供了自定義靈活性,同時提供了大規模快速部署所需的強大工具。
開始使用 Nemotron-3-8B
您可以使用 NeMo 框架在 Nemotron-3-8B 模型上輕松運行推理,該框架充分利用 TensorRT-LLM 開源庫,可在NVIDIA GPU上為高效和輕松的 LLM 推理提供高級優化。它內置了對各種優化技術的支持,包括:
-
KV caching
-
Efficient Attention modules (including MQA, GQA, and Paged Attention)
-
In-flight (or continuous) batching
-
支持低精度(INT8/FP8)量化以及其他優化
NeMo 框架推理容器包含在 NeMo 模型(如 Nemotron-3-8B 系列)上應用 TensorRT-LLM 優化所需的所有腳本和依賴項,并將它們托管在 Triton 推理服務器上。部署完成后,它可以開放一個端點,供您發送推理查詢。
在 Azure ML 上的部署步驟
Nemotron-3-8B 系列模型可在 Azure ML 模型目錄中獲得,以便部署到 Azure ML 管理的端點中。AzureML 提供了易于使用的“無代碼部署”流程,使部署 Nemotron-3-8B 系列模型變得非常容易。該平臺已集成了作為 NeMo 框架推理容器的底層管道。
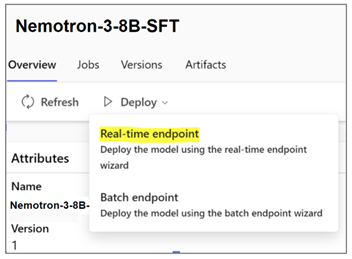
圖 1. 在 Azure ML 中選擇實時端點
如要在 Azure ML 上部署 NVIDIA 基礎模型并進行推理,請按照以下步驟操作:
-
登錄 Azure 賬戶:https://portal.azure.com/#home
-
導航至 Azure ML 機器學習工作室
-
選擇您的工作區,并導航至模型目錄
NVIDIA AI Foundation 模型可在 Azure 上進行微調、評估和部署,還可以在 Azure ML 中使用 NeMo 訓練框架對這些模型進行自定義。NeMo 框架由訓練和推理容器組成,已集成在 AzureML 中。
如要微調基本模型,請選擇您喜歡的模型變體,單擊“微調”,填寫任務類型、自定義訓練數據、訓練和驗證分割以及計算集群等參數。
如要部署該模型,請選擇您喜歡的模型變體,單擊“實時端點”,選擇實例、端點和其他用于自定義部署的參數。單擊“部署”,將推理模型部署到端點。
Azure CLI 和 SDK 支持也可用于在 Azure ML 上運行微調作業和部署。詳細信息請參見“Azure ML 中的 Foundation Models”文檔。
在本地或其他云上的部署步驟
Nemotron-3-8B 系列模型具有獨特的推理請求提示模板,建議將其作為最佳實踐。但由于它們共享相同的基本架構,因此其部署說明很相似。
有關使用 NeMo 框架推理容器的最新部署說明,參見:https://registry.ngc.nvidia.com/orgs/ea-bignlp/teams/ga-participants/containers/nemofw-inference。
為了演示,讓我們部署 Nemotron-3-8B-Base-4k。
1. 登錄 NGC 目錄,獲取推理容器。
# log in to your NGC organization
docker login nvcr.io
# Fetch the NeMo framework inference container
docker pull nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10
2. 下載 Nemotron-3-8B-Base-4k 模型。8B 系列模型可在 NGC 目錄和 Hugging Face 上獲得,您可以選擇其中一個下載模型。
NVIDIA NGC
從 NGC 下載模型最簡單的方法是使用 CLI。如果您沒有安裝 NGC CLI,請按照入門指南(https://docs.ngc.nvidia.com/cli/cmd.html#getting-started-with-the-ngc-cli)進行安裝和配置。
# Downloading using CLI. The model path can be obtained from it’s page on NGC
ngc registry model download-version "dztrnjtldi02/nemotron-3-8b-base-4k:1.0"
Hugging Face Hub
以下指令使用的是 git-lfs,您也可以使用 Hugging Face 支持的任何方法下載模型。
git lfs install
git clone https://huggingface.co/nvidia/nemotron-3-8b-base-4knemotron-3-8b-base-4k_v1.0
3.在交互模式下運行 NeMo 推理容器,安裝相關路徑
# Create a folder to cache the built TRT engines. This is recommended so they don’t have to be built on every deployment call.
mkdir -p trt-cache
# Run the container, mounting the checkpoint and the cache directory
docker run --rm --net=host
--gpus=all
-v $(pwd)/nemotron-3-8b-base-4k_v1.0:/opt/checkpoints/
-v $(pwd)/trt-cache:/trt-cache
-w /opt/NeMo
-it nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10 bash
4. 在 Triton 推理服務器上使用 TensorRT-LLM 后端轉換并部署該模型。
python scripts/deploy/deploy_triton.py
--nemo_checkpoint /opt/checkpoints/Nemotron-3-8B-Base-4k.nemo
--model_type="gptnext"
--triton_model_name Nemotron-3-8B-4K
--triton_model_repository /trt-cache/
--max_input_len 3000
--max_output_len 1000
--max_batch_size 2
當該指令成功完成后,就會顯示一個可以查詢的端點。讓我們來看看如何做到這一點。
運行推理的步驟
有幾種運行推理的方法可供選擇,取決于您希望如何集成該服務:
1. 使用 NeMo 框架推理容器中的 NeMo 客戶端 API
2. 使用 PyTriton 在您的環境中創建一個客戶端應用
3. 鑒于所部署的服務會開放一個 HTTP 端點,使用任何可以發送 HTTP 請求的程序資源庫/工具。
選項 1(使用 NeMo 客戶端 API)的示例如下。您可以在同一臺設備上的 NeMo 框架推理容器中使用,也可以在能訪問服務 IP 和端口的不同設備上使用。
from nemo.deploy import NemoQuery
# In this case, we run inference on the same machine
nq = NemoQuery(url="localhost:8000", model_name="Nemotron-3-8B-4K")
output = nq.query_llm(prompts=["The meaning of life is"], max_output_token=200, top_k=1, top_p=0.0, temperature=0.1)
print(output)
其他選項示例可以在該推理容器的 README 中找到。
8B 系列模型指令
NVIDIA Nemotron-3-8B 系列中的模型:所有 NVIDIA Nemotron-3-8B 數據集共享預訓練基礎,但用于調優聊天(SFT、RLHF、SteerLM)和問答模型的數據集是根據其特定目的自定義的。此外,構建上述模型還采用了不同的訓練技術,因此這些模型在使用與訓練模板相似的定制指令時最為有效。
這些模型的推薦指令模板位于各自的模型卡上。
例如,以下是適用于 Nemotron-3-8B-Chat-SFT 和 Nemotron-3-8B-Chat-RLHF 模型的單輪和多輪格式:

指令和回復字段與輸入內容相對應。下面是一個使用單輪模板設置輸入格式的示例。
PROMPT_TEMPLATE = """System
{system}
User
{prompt}
Assistant
"""
system = ""
prompt = "Write a poem on NVIDIA in the style of Shakespeare"
prompt = PROMPT_TEMPLATE.format(prompt=prompt, system=system)
print(prompt)
注意:對于 Nemotron-3-8B-Chat-SFT 和 Nemotron-3-8B-Chat-RLHF 模型,我們建議保持系統提示為空。
進一步訓練和自定義
NVIDIA Nemotron-3-8B 模型系列適用于針對特定領域數據集的進一步定制。對此有幾種選擇,例如繼續從檢查點進行預訓練、SFT 或高效參數微調、使用 RLHF 校準人類演示或使用 NVIDIA 全新 SteerLM 技術。
NeMo 框架訓練容器提供了上述技術的易用腳本。我們還提供了各種工具,方便您進行數據整理、識別用于訓練和推理的最佳超參數,以及在您選擇的硬件(本地 DGX 云、支持 Kubernetes 的平臺或云服務提供商)上運行 NeMo 框架的工具。
更多信息,參見 NeMo 框架用戶指南(https://docs.nvidia.com/nemo-framework/user-guide/latest/index.html)或容器 README(https://registry.ngc.nvidia.com/orgs/ea-bignlp/containers/nemofw-training)。
Nemotron-3-8B 系列模型專為各種用例而設計,不僅在各種基準測試中表現出色,還支持多種語言。
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
原文標題:NVIDIA AI Foundation Models:使用生產就緒型 LLM 構建自定義企業聊天機器人和智能副駕
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3848瀏覽量
91977
原文標題:NVIDIA AI Foundation Models:使用生產就緒型 LLM 構建自定義企業聊天機器人和智能副駕
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英偉達推出基石世界模型Cosmos,解決智駕與機器人具身智能訓練數據問題
自然語言處理在聊天機器人中的應用
NLP技術在聊天機器人中的作用
ChatGPT 與傳統聊天機器人的比較
Meta將推出音頻版聊天機器人
Meta關閉明星AI聊天機器人,轉向用戶自創AI工具

NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型

AI聊天機器人Grok向歐洲X平臺Premium會員開放
使用Ryzen ? AI處理器構建聊天機器人






 工商網監
工商網監
評論