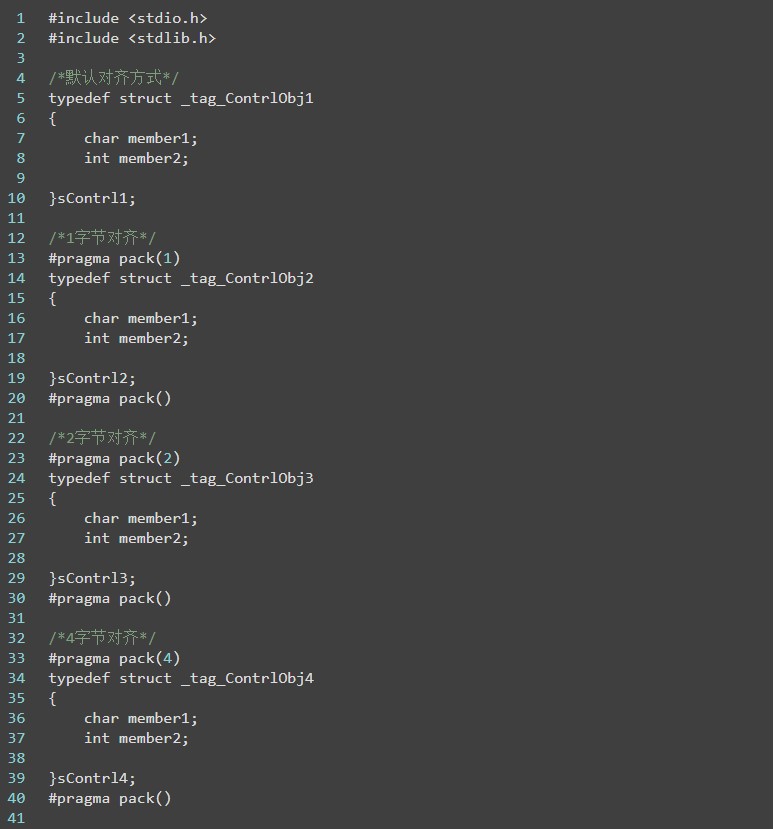
 什么是結構體的字節對齊現象
什么是結構體的字節對齊現象
什么是結構體的字節對齊現象
程序員,咱都用代碼說話,先上 code:
(說明:以下代碼均在 ARM 平臺上,使用 Keil 進行編譯測試)
//上面這個宏定義主要用于顯示結構體成員變量相對結構體起始地址的偏移
typedef structstu1{ int a; char b; int c;}stu1;
void main(){ LOG_INFO("rnrn====== Struct Test ======rnrn"); LOG_INFO("offset_of(stu1,a):t%dn",offset_of(stu1,a)); LOG_INFO("offset_of(stu1,b):t%dn",offset_of(stu1,b)); LOG_INFO("offset_of(stu1,c):t%dn",offset_of(stu1,c)); LOG_INFO("sizeof(stu1) :t%dn",sizeof(stu1)); return ;}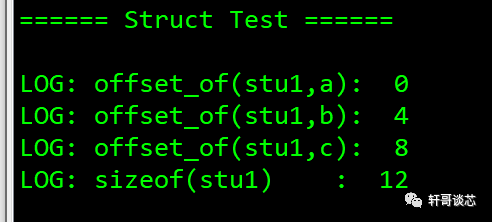
對于上面的運行結果,對字節對齊不了解的同學可能會疑惑,c的偏移量怎么會是8呢?不應該是 5 嗎?
結構體的大小怎么會是12呢?不應該是 9 嗎?
不了解的同學可能會這樣理解:
c的偏移量是sizeof(int)+sizeof(char) = 5
結構體stu1占用的內存大小應該是sizeof(int)+sizeof(char)+sizeof(int)=9。
通過下圖所示的stu1的內存結構可以知道,編譯器對變量存儲進行了一個特殊處理。

為了提高CPU的存儲速度,編譯器對一些變量的起始地址做了對齊處理。
在默認情況下,編譯器規定各成員變量存放的起始地址相對于結構體的起始地址的偏移量,必須為該變量的類型所占用的字節數和編譯器編譯過程中采用的字節對齊數兩者中最小值的整數倍。
有點繞,比如stu1 結構體中,變量 c 類型為 int,也就是占用 4 字節,編譯器采用 4 字節對齊,因此偏移量必須是 4 的整數倍。
typedef structstu2{ int a; char b; char c int d;}stu2;再比上面的 stu2中,如對于變量 c,其類型為 char ,占用 1 字節,編譯器采用 4 字節對齊,因此 它被分配的偏移量需要是 1 的整數倍,在上面的結構體 stu2 中,c 的偏移量為 5。
如圖:

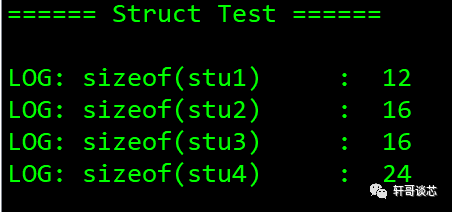
現在來分析前面的代碼
假定a的起始地址為0,它占用了4字節,接下來的空閑地址就是4,是1的倍數,滿足要求,所以b存放的起始地址是4,占用一個字節,接下來的空閑地址為5。c也是char變量,占用1字節, 因此可以放在地址 5 上面。
接下來看地址 6,對于 d,它占用了 4 個字節,同時需要注意的是,編譯器默認按照結構體中占有內存最大的類型所占用的字節數進行字節對齊。在此結構體中占用內存最大的為整型,占用4字節,所以在此取兩者的最小值4,6 并不是4的整數倍,所以向后移動,找到離6最近的8作為存放d的起始地址,d也占用4字節,最后結構體的大小為12。
需要注意的就是,變量b和 c后面2字節的存儲空間是由編譯器自動填充的,其中沒有存儲任何有用的信息。
-
ARM
+關注
關注
134文章
9169瀏覽量
369239 -
字節
+關注
關注
0文章
41瀏覽量
13806 -
代碼
+關注
關注
30文章
4828瀏覽量
69058 -
結構體
+關注
關注
1文章
130瀏覽量
10872
發布評論請先 登錄
相關推薦
C語言-結構體對齊詳解
RM48HDK平臺CCS結構體字節對齊總是咨詢
CCS3.3 結構體成員對齊
請問在ccs4.2 中怎么設置結構體的字節對齊?
請問cc2640r2 ccs7.4結構體字節能實現對齊嗎?


對結構體的對齊理解上有點偏差
結構體對齊為什么那么重要?

嵌套的結構體 字節是如何對齊的





 工商網監
工商網監
評論