 計算機視覺中的立體視覺和深度感知Python示例實現
計算機視覺中的立體視覺和深度感知Python示例實現
在人工智能和圖像處理的迷人世界中,這些概念在使機器能夠像我們的眼睛一樣感知我們周圍的三維世界中起著關鍵作用。和我們一起探索立體視覺和深度感知背后的技術,揭示計算機如何從二維圖像中獲得深度、距離和空間理解的秘密。
計算機視覺中的立體視覺和深度感知是什么?
立體視覺和深度感知是計算機視覺中的重要概念,旨在模仿人類從視覺信息中感知深度和三維結構的能力。它們通常用于機器人技術、自動駕駛汽車和增強現實等應用中。
立體視覺
立體視覺,也稱為立體視或雙目視覺,是一種通過捕獲和分析稍微分開放置的兩個或多個攝像頭的圖像來感知場景深度的技術,模仿了人眼的工作方式。
立體視覺背后的基本原理是三角測量。當兩個攝像頭(或“立體攝像頭”)從稍微不同的視點捕獲相同場景的圖像時,生成的圖像對稱為立體對,其中包含兩個圖像中相應點的位置差異或差異。
通過分析這些差異,計算機視覺系統可以計算場景中物體的深度信息。靠近攝像頭的物體將具有較大的差異,而遠離攝像頭的物體將具有較小的差異。
立體視覺算法通常涉及諸如特征匹配、差異映射和極線幾何等技術,以計算深度圖或場景的3D表示。
深度感知
計算機視覺中的深度感知是指系統能夠從單個或多個2D圖像或視頻幀中理解和估計3D場景中物體的距離能力。
除了立體視覺外,深度感知可以使用其他方法實現,包括:
單眼線索:這些是可以在單個攝像頭或圖像中感知的深度線索。例如,透視、紋理梯度、陰影和遮擋等示例。即使在沒有立體視覺的情況下,這些線索也可以幫助估算深度。
LiDAR(光探測與測距):LiDAR傳感器使用激光束來測量場景中物體的距離,提供點云形式的精確深度信息。這些信息可以與視覺數據融合,以獲得更準確的深度感知。
結構光:結構光涉及將已知圖案投射到場景上,并分析該圖案在場景中的物體上的變形。這種變形可用于計算深度信息。
飛行時間(ToF)攝像頭:ToF攝像頭測量光線從物體反射并返回到攝像頭所需的時間。這些信息用于估算深度。
在計算機視覺應用中,深度感知對于障礙物避免、物體識別、3D重建和場景理解等任務至關重要。
計算機視覺中的立體視覺和深度感知組件
立體攝像頭:立體視覺依賴于兩個或多個相機(立體攝像頭),這些相機相距已知的距離放置。這些相機從稍微不同的視點捕獲相同場景的圖像,模擬人眼感知深度的方式。
圖像捕獲:相機捕獲場景的圖像或視頻幀。這些圖像通常被稱為左圖像(來自左相機)和右圖像(來自右相機)。
校準:為了準確計算深度信息,必須對立體攝像頭進行校準。這個過程涉及確定攝像頭參數,如內在矩陣、畸變系數和外在參數(攝像頭之間的旋轉和平移)。校準確保來自兩個相機的圖像能夠正確進行校正和匹配。
校正:校正是應用于捕獲的圖像的幾何變換,以對齊極線上的相應特征。這通過使差異更可預測來簡化立體匹配過程。
立體匹配:立體匹配是在左圖像和右圖像之間找到對應點或匹配點的過程。用于計算每個像素的差異的像素值被稱為差異,表示圖像中特征的水平偏移。有各種立
體匹配算法可供選擇,包括塊匹配、半全局匹配和圖割,用于找到這些對應點。
差異圖:差異圖是一幅灰度圖像,其中每個像素的強度值對應于場景中該點的差異或深度。靠近相機的物體具有較大的差異,而遠離相機的物體具有較小的差異。
深度圖:深度圖是通過使用已知的基線(相機之間的距離)和相機的焦距來從差異圖中導出的。它計算每個像素的實際世界單位(例如米)的深度,而不是差異。
可視化:深度和差異圖通常可視化,以提供場景的3D結構的可讀人類表示。這些圖可以顯示為灰度圖像,也可以轉換為點云以進行3D可視化。
一些硬件:除了攝像頭外,還可以使用深度感知攝像頭(例如Microsoft Kinect、Intel RealSense)或LiDAR(光探測與測距)傳感器等專用硬件來獲取深度信息。這些傳感器直接提供深度,無需立體匹配。
計算機視覺中的立體視覺和深度感知Python示例實現
import cv2 import numpy as np # Create two video capture objects for left and right cameras (adjust device IDs as needed) left_camera = cv2.VideoCapture(0) right_camera = cv2.VideoCapture(1) # Set camera resolution (adjust as needed) width = 640 height = 480 left_camera.set(cv2.CAP_PROP_FRAME_WIDTH, width) left_camera.set(cv2.CAP_PROP_FRAME_HEIGHT, height) right_camera.set(cv2.CAP_PROP_FRAME_WIDTH, width) right_camera.set(cv2.CAP_PROP_FRAME_HEIGHT, height) # Load stereo calibration data (you need to calibrate your stereo camera setup first) stereo_calibration_file = ‘stereo_calibration.yml’ calibration_data = cv2.FileStorage(stereo_calibration_file, cv2.FILE_STORAGE_READ) if not calibration_data.isOpened(): print(“Calibration file not found.”) exit() camera_matrix_left = calibration_data.getNode(‘cameraMatrixLeft’).mat() camera_matrix_right = calibration_data.getNode(‘cameraMatrixRight’).mat() distortion_coeff_left = calibration_data.getNode(‘distCoeffsLeft’).mat() distortion_coeff_right = calibration_data.getNode(‘distCoeffsRight’).mat() R = calibration_data.getNode(‘R’).mat() T = calibration_data.getNode(‘T’).mat() calibration_data.release() # Create stereo rectification maps R1, R2, P1, P2, Q, _, _ = cv2.stereoRectify( camera_matrix_left, distortion_coeff_left, camera_matrix_right, distortion_coeff_right, (width, height), R, T ) left_map1, left_map2 = cv2.initUndistortRectifyMap( camera_matrix_left, distortion_coeff_left, R1, P1, (width, height), cv2.CV_32FC1 ) right_map1, right_map2 = cv2.initUndistortRectifyMap( camera_matrix_right, distortion_coeff_right, R2, P2, (width, height), cv2.CV_32FC1 ) while True: # Capture frames from left and right cameras ret1, left_frame = left_camera.read() ret2, right_frame = right_camera.read() if not ret1 or not ret2: print(“Failed to capture frames.”) break # Undistort and rectify frames left_frame_rectified = cv2.remap(left_frame, left_map1, left_map2, interpolation=cv2.INTER_LINEAR) right_frame_rectified = cv2.remap(right_frame, right_map1, right_map2, interpolation=cv2.INTER_LINEAR) # Convert frames to grayscale left_gray = cv2.cvtColor(left_frame_rectified, cv2.COLOR_BGR2GRAY) right_gray = cv2.cvtColor(right_frame_rectified, cv2.COLOR_BGR2GRAY) # Perform stereo matching to calculate depth map (adjust parameters as needed) stereo = cv2.StereoBM_create(numDisparities=16, blockSize=15) disparity = stereo.compute(left_gray, right_gray) # Normalize the disparity map for visualization disparity_normalized = cv2.normalize(disparity, None, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U) # Display the disparity map cv2.imshow(‘Disparity Map’, disparity_normalized) if cv2.waitKey(1) & 0xFF == ord(‘q’): break # Release resources left_camera.release() right_camera.release() cv2.destroyAllWindows()
注意:對于立體攝像頭設置,需要進行攝像頭校準,并保存校準數據在.yml文件中,將路徑放入示例代碼中。
應用
通過立體視覺和深度感知獲得的深度信息可以用于各種計算機視覺應用,包括:
3D場景重建
物體檢測和跟蹤
機器人和車輛的自主導航
增強現實和虛擬現實
手勢識別
限制
以下是一些主要的限制:
依賴于相機校準:立體視覺系統需要對所使用的攝像機進行精確的校準。準確的校準對于確保深度信息的正確計算至關重要。校準中的任何錯誤都可能導致深度感知不準確。
有限的視場范圍:立體視覺系統的視場范圍有限,基于兩個攝像機之間的基線距離。這可能導致盲區或在兩個攝像機視場之外的對象的感知困難。
沒有紋理和特征的表面:立體匹配算法依賴于在左右圖像中找到對應的特征。缺乏紋理或獨特特征的表面,如光滑的墻壁或均勻的背景,可能難以準確匹配,導致深度估計錯誤。
遮擋:在場景中相互遮擋的對象可能會對立體視覺造成困難。當一個對象部分遮擋另一個對象時,確定被遮擋區域的深度可能會有問題。
有限的范圍和分辨率:隨著距離攝像機的增加,使用立體視覺感知深度的準確性會減小。此外,深度測量的分辨率隨著距離的增加而減小,使遠處物體的細節難以感知。
對光照條件敏感:光照條件的變化,如環境光的變化或陰影,可能會影響立體視覺的準確性。不一致的光照條件可能會使左右圖像之間的對應關系難以找到。
計算資源:立體匹配算法可能需要大量計算資源,特別是在處理高分辨率圖像或實時視頻流時。實時應用可能需要強大的硬件來進行高效處理。
成本和復雜性:設置帶有校準攝像機的立體視覺系統可能會昂貴且耗時。硬件要求,包括攝像機和校準設備,可能會成為某些應用的障礙。
透明或反光物體的不準確性:透明或高反射表面可能會導致立體視覺中的錯誤,因為這些材料可能不會以適合深度感知的方式反射光線。
動態場景:立體視覺假定在圖像捕捉期間場景是靜態的。在具有移動對象或攝像機運動的動態場景中,維護左右圖像之間的對應關系可能會很具挑戰性,導致深度估計不準確。
有限的戶外使用:立體視覺系統在明亮陽光下的戶外環境或缺乏紋理的場景中可能會遇到困難,如晴朗的天空。
總之,計算機視覺中的立體視覺和深度感知為機器與理解我們環境的三維豐富性互動打開了新的可能性。正如我們在本文中所探討的,這些技術是從機器人和自動駕駛車輛到增強現實和醫學成像等各種應用的核心。
編輯:黃飛
-
圖像處理
+關注
關注
27文章
1300瀏覽量
56894 -
人工智能
+關注
關注
1796文章
47668瀏覽量
240289 -
立體視覺
+關注
關注
0文章
37瀏覽量
9810 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46127 -
python
+關注
關注
56文章
4807瀏覽量
85038
原文標題:計算機視覺中的立體視覺和深度感知及示例
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何通過立體視覺構建小巧輕便的深度感知系統

雙目立體視覺原理大揭秘(二)
基于立體視覺的變形測量
雙目立體視覺的運用
匯總 |計算機視覺系統學習資料下載 精選資料分享
深度學習與傳統計算機視覺簡介
雙目立體視覺在嵌入式中有何應用
圖像處理基本算法-立體視覺
使用雙目立體視覺實現CCD測距系統設計的資料說明
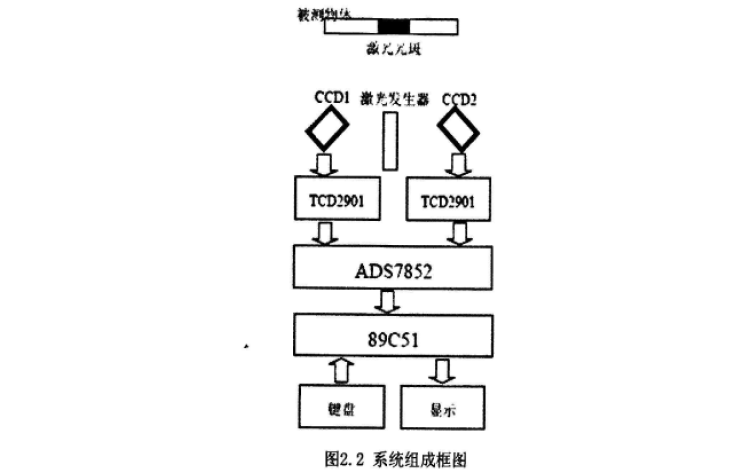
雙目立體計算機視覺的立體匹配研究綜述

雙目立體視覺深度測量步驟介紹

關于雙目立體視覺的三大基本算法及發展現狀





 工商網監
工商網監
評論