") MS-COCO數(shù)據(jù)集的可靠嗎?
MS-COCO數(shù)據(jù)集的可靠嗎?
ICCV2023 基準測試:MS-COCO數(shù)據(jù)集的可靠嗎?
摘要
數(shù)據(jù)集是用于分析和比較各種任務(wù)的算法的基礎(chǔ),從圖像分類到分割,它們也在圖像預(yù)訓練算法中起著重要作用。然而,人們往往只關(guān)注結(jié)果,而忽略了數(shù)據(jù)集中實際的內(nèi)容。因此,質(zhì)疑數(shù)據(jù)集中所包含的信息類型以及其中的微妙差異和偏見是非常必要的。在本文中,我們利用形狀分析流程來發(fā)現(xiàn)Sama-COCO(MS-COCO的重新標注版本)的潛在問題。我們在兩個數(shù)據(jù)集上訓練和評估了模型,以檢查不同標注條件對結(jié)果的影響。我們的實驗表明,標注方式對性能有顯著影響,因此標注過程應(yīng)該根據(jù)目標任務(wù)進行設(shè)計。
引言
數(shù)據(jù)集基準和評估標準對于塑造計算機視覺研究的方向和動力具有關(guān)鍵作用。它們是衡量社區(qū)進步和算法創(chuàng)新的標尺。這些組件通常被認為是單一的工作,它們被收集和分析以確保所有算法的可靠性和質(zhì)量。然而,當基準本身存在缺陷時,研究人員和從業(yè)者花費大量時間調(diào)整他們的實驗以在基準上取得最佳性能,會產(chǎn)生什么后果呢?
視覺數(shù)據(jù)集通常用于分類、檢測和分割等任務(wù)的算法基準測試或大型神經(jīng)網(wǎng)絡(luò)的預(yù)訓練。然而,這存在一個問題,那就是實際的目標并不總是與數(shù)據(jù)集中提供的數(shù)據(jù)相一致。這種不一致可能源于自動標注協(xié)議的缺陷或眾包努力的不協(xié)調(diào)。因此,有必要建立一個嚴格的端到端流程,其中注釋過程由實際任務(wù)的明確定義所指導。
目標檢測數(shù)據(jù)集(MS-COCO)是一個用于評估和比較檢測和實例分割算法的標準數(shù)據(jù)集,包括YOLO,R-CNN和DETR等方法。它由自然圖像組成,具有自動駕駛行業(yè)的應(yīng)用價值,因此為在其上開發(fā)的神經(jīng)網(wǎng)絡(luò)提供了質(zhì)量標準。由于MS-COCO在計算機視覺中作為基準的重要性,理解其數(shù)據(jù)集中的邊界框和分割掩模的可靠性和質(zhì)量是非常必要的,因為它們反映了數(shù)據(jù)的趨勢和特征。為了評估數(shù)據(jù)集的質(zhì)量,可以創(chuàng)建數(shù)據(jù)集的重新標注版本,以便與原始版本進行比較和發(fā)現(xiàn)潛在的差異,這些差異可能會影響算法的性能和泛化能力。

圖2 除了聚集的實例外,其他對象的大小分布
數(shù)據(jù)集
Sama-COCO數(shù)據(jù)集是對現(xiàn)有MS-COCO數(shù)據(jù)集的重新標注工作,由一組專業(yè)的標注員完成。該項目最初是作為一個內(nèi)部工作,旨在生成高質(zhì)量的地面真實數(shù)據(jù),后來發(fā)展成為一種提供了解機器學習數(shù)據(jù)集質(zhì)量復(fù)雜因素的新方法。
該數(shù)據(jù)集是在數(shù)月內(nèi)生成的,使用了不固定的人力資源:有時有多達500名標注員同時工作。關(guān)鍵點是有對標注員的進行詳細指導。與MS-COCO數(shù)據(jù)集一樣,標注以矢量多邊形的形式提供。
我們指導標注員在繪制COCO對象輪廓的多邊形時要盡可能精確,盡量避免包含背景。我們還指導標注員優(yōu)先標注對象的單個實例,而不是聚集在一起的對象。如果圖像中某個對象類別的實例數(shù)量超過了給定的閾值,我們就指示標注員只標注前幾個實例,然后將剩余的實例標記為聚集。整個項目中的閾值根據(jù)不同的情況進行調(diào)整,以平衡預(yù)算、時間和數(shù)據(jù)質(zhì)量之間的關(guān)系。此外,我們還指示標注員忽略尺寸小于10×10像素的對象。
重新標注過程涵蓋了MS-COCO數(shù)據(jù)集中的所有123,287張訓練和驗證圖像。這些圖像預(yù)先加載了MS-COCO的原始標注,這使得標注員可以根據(jù)需要修改、保留或刪除這些標注。在標注階段之后,還有一個質(zhì)量保證(QA)階段,QA專家會檢查每個提交的標注。不符合質(zhì)量要求的標注會被退回,要求標注員進行修正,直到達到滿意的水平。需要注意的是,一些標注員誤解了忽略小對象的要求,認為是要刪除MS-COCO的預(yù)標注,而另一些標注員則沒有改變它們。
與原始MS-COCO數(shù)據(jù)集相比,Sama-COCO數(shù)據(jù)集有幾個顯著的差異。首先,Sama-COCO數(shù)據(jù)集中標記為聚集的實例明顯更多。這部分是因為標注員被指示將大型的單一聚集分解為較小的部分和單個實體。盡管兩個數(shù)據(jù)集有相同的基礎(chǔ),但Sama-COCO在80個類別中的47個類別中擁有更多的實例。其中一些類別,如person,增加的數(shù)量非常顯著。其次,Sama-COCO的頂點數(shù)幾乎是MS-COCO的兩倍,這是因為標注員被指示在繪制多邊形時要盡可能精確,盡量不包含背景。此外,如圖2所示,大型對象的數(shù)量顯著減少,因為大型的聚集或?qū)ο笕褐械膯蝹€元素被重新標注為不同的實體。在Sama-COCO數(shù)據(jù)集中還可以觀察到一個關(guān)鍵的變化是非常小的對象(尺寸小于或等于10×10像素)的數(shù)量明顯減少。最后,Sama-COCO數(shù)據(jù)集中還有更多的小型(從10×10到32×32像素)和中等大小(從32×32到96×96像素)的對象。
形狀分析
由于Sama-COCO是重新注釋而非最初數(shù)據(jù)集的更正,所以樣本之間沒有對應(yīng)關(guān)系。為了確定地分析注釋形狀的差異,必須首先匹配多邊形。放寬分析要求為單個多邊形形狀,并利用邊界框形狀一致性的概念。形狀一致性假設(shè)輪廓錯誤不意味著盒子錯誤。使用基于交集與并集(IoU)度量的重疊標準確定匹配。對于任何一對封閉形狀,IoU定義為:
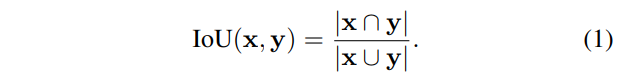
數(shù)據(jù)集之間注釋實例的匹配由所有形狀中IoU大于置信度閾值T的形狀對定義。每個注釋最多只有一個匹配,且不能保證一定找到匹配。經(jīng)驗選擇匹配閾值為0.90。這種策略可找到受輪廓噪聲影響的匹配,而不是與全局框錯誤相關(guān)的匹配。對形狀和形狀集,匹配定義為:
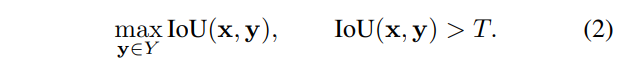
一旦找到匹配,則使用輪廓分析量化成對形狀之間的差異。設(shè)()表示成對形狀()的輪廓,長度為()。設(shè)為空間域上輪廓的精確距離變換(EDT),其中定義了中的空間位置。用于量化形狀之間平均差異的平均表面距離定義為:
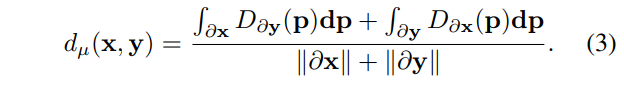
某些成對形狀可能存在大型區(qū)域分歧。在這種情況下,平均表面距離無法捕獲這種現(xiàn)象。為了緩解這個問題,引入最大距離,定義為:
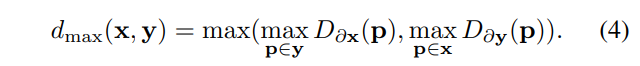
匹配流程應(yīng)用于訓練分割,找到310504個確定匹配。每個形狀使用pycoco標準柵格化為掩模,并通過將掩模與自身的二值腐蝕相減生成輪廓。生成EDT,并通過用成對形狀的輪廓索引距離圖來計算路徑積分。該流程對兩個形狀雙向完成,如圖3所示。平均和最大表面距離的分布如圖4所示。
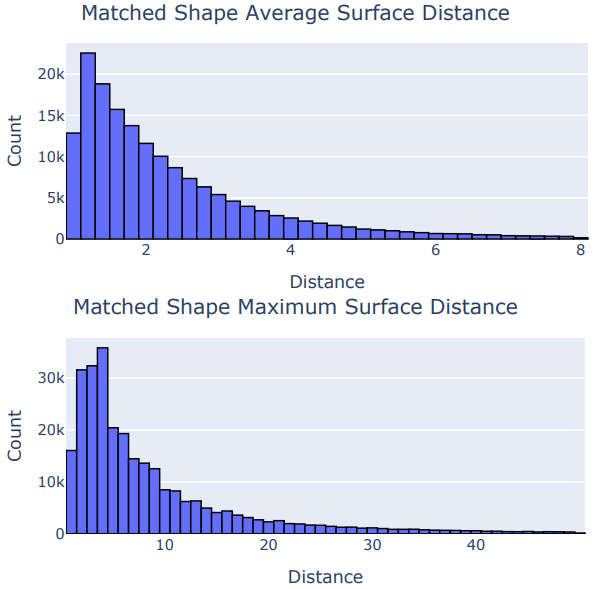
圖4:平均和最大表面距離的長尾分布
實驗
為了研究重新標注過程對神經(jīng)網(wǎng)絡(luò)預(yù)測質(zhì)量的影響,我們使用檢測和實例分割任務(wù)來訓練和評估神經(jīng)網(wǎng)絡(luò)。重新標注過程包括更精確的多邊形、更細化的聚集和更多的標注實例。我們使用Detectron2框架在MS-COCO和Sama-COCO上訓練了一個基于ResNet-50和FPN的Faster R-CNN模型,并使用MS-COCO的標準評估指標對其進行評估,將每個數(shù)據(jù)集的驗證分割作為地面真實數(shù)據(jù)。我們使用8個Nvidia V100 GPU,在批量大小為16的情況下,總共進行了270k次迭代的訓練。我們在所有的實驗中保持了相同的超參數(shù)。我們使用平均精度均值(mAP)作為評估指標,結(jié)果如表1所示。
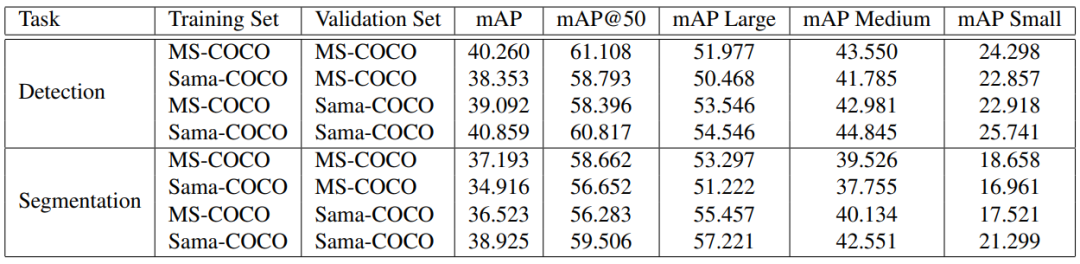
表1:檢測和分割結(jié)果
我們還評估了學習與驗證集完全匹配的理想表示的意義。在這種情況下,我們將源標注與目標標注進行比較,將源視為模型預(yù)測,目標視為地面真實數(shù)據(jù)。我們交替使用MS-COCO和Sama-COCO作為源和目標,以確保評估的公平性。結(jié)果如表2所示。

表2: 當將源數(shù)據(jù)集視為針對目標數(shù)據(jù)集的預(yù)測時,檢測和分割結(jié)果
討論
我們要先說明,沒有任何數(shù)據(jù)集是完美的,Sama-COCO也不比MS-COCO更好或更差。每個數(shù)據(jù)集都會不可避免地存在一些偏差,但是不同形式的偏差會對神經(jīng)網(wǎng)絡(luò)的性能產(chǎn)生不同的影響。這可以通過比較不同數(shù)據(jù)集的基準測試結(jié)果來觀察。
當我們比較兩個數(shù)據(jù)集中的匹配實例時,可以發(fā)現(xiàn)MS-COCO數(shù)據(jù)集中存在一些系統(tǒng)性的偏差。這些偏差有兩種不同的形式。第一種形式的偏差與多邊形的緊密程度有關(guān)。我們發(fā)現(xiàn),平均表面距離較低的成對多邊形在輪廓上有輕微的差異。平均來說,Sama-COCO的多邊形比原始標注更貼合對象,但是過分割和欠分割實例的組合可能對真實的預(yù)測質(zhì)量沒有影響,如果噪聲的期望值為零。也有可能,隨著網(wǎng)絡(luò)規(guī)模的增大,它們會適應(yīng)這些輪廓中的偏差,從而誤導評估指標。在這種情況下,很難判斷神經(jīng)網(wǎng)絡(luò)學習的表示的真實質(zhì)量,因為評估它們的唯一方式也包含了偏差。
第二種形式的偏差與遮擋物和標注風格指南的處理和規(guī)定有關(guān)。Sama-COCO強調(diào)多邊形貼近可觀察到的像素,而原始數(shù)據(jù)集包含繞過遮擋物的多邊形。考慮遮擋物更適合像素級的實例分割任務(wù),而忽略遮擋物更類似于定位任務(wù)。在這種隱性的偏差上訓練的神經(jīng)網(wǎng)絡(luò)會以不同的方式學習解決這些任務(wù)。因此,任何機器學習從業(yè)者都必須了解他們的數(shù)據(jù)集與他們想要解決的下游任務(wù)之間的關(guān)聯(lián)性,并應(yīng)該在數(shù)據(jù)收集階段注意標注標準和指南,以盡量減少頂層問題。合并具有沖突標注風格的數(shù)據(jù)集可能是不明智的,因為神經(jīng)網(wǎng)絡(luò)的下游行為可能難以預(yù)測。
當我們查看檢測和分割任務(wù)的評估指標差異時,可以明顯看到網(wǎng)絡(luò)從與訓練數(shù)據(jù)集相同風格的評估中受益,如表1所示。這意味著性能與主觀的質(zhì)量定義密切相關(guān)。如果我們使用額外的樣本來豐富數(shù)據(jù)集,但是樣本的風格分布發(fā)生了變化,那么網(wǎng)絡(luò)的性能可能會降低,這與我們的預(yù)期相反。這可以通過將一個數(shù)據(jù)集的驗證標注作為源,另一個數(shù)據(jù)集的驗證標注作為目標來理論上驗證。即使我們在另一個數(shù)據(jù)集上是完美的預(yù)測者,我們也會受到錯過的實例、邊界變形和細微差異的影響。還值得注意的是,一些最先進的檢測算法的性能優(yōu)于我們的結(jié)果。這很有趣,因為框標注應(yīng)該與多邊形的變化相對一致。這意味著網(wǎng)絡(luò)可能會過擬合訓練數(shù)據(jù)集中可能無法在另一個數(shù)據(jù)集中復(fù)現(xiàn)的特定信息類型。
結(jié)論
從討論中可以看出,數(shù)據(jù)集中的偏差可能導致一些不期望或意外的結(jié)果,這可能是有問題的。在實例分割中,標注方式的選擇會影響模型對遮擋對象的輸出。因此,在構(gòu)建標注數(shù)據(jù)集時必須仔細考慮,以確保它們能夠反映真實世界應(yīng)用中的需求。雖然Sama-COCO并不完全避免所有的標注錯誤,但它確實提供了一組高質(zhì)量的標注,可以用于更好地探索標簽噪聲領(lǐng)域和對精確多邊形很重要的應(yīng)用。
編輯:黃飛
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101169 -
圖像分類
+關(guān)注
關(guān)注
0文章
93瀏覽量
11956 -
計算機視覺
+關(guān)注
關(guān)注
8文章
1700瀏覽量
46127 -
機器學習
+關(guān)注
關(guān)注
66文章
8438瀏覽量
133084 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24833
原文標題:ICCV2023 基準測試:MS-COCO數(shù)據(jù)集的可靠嗎?
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
如何使用eIQ門戶訓練人臉檢測模型?
用于動作分類和定位的稀疏標記數(shù)據(jù)集
利用Attention模型為圖像生成字幕
在不使用任何額外數(shù)據(jù)的情況下,COCO數(shù)據(jù)集上物體檢測結(jié)果為50.9 AP的方法

微軟刪除 MS Celeb 名人數(shù)據(jù)集,撥開數(shù)據(jù)隱私的迷霧
「房間里的大象」:讓目標檢測器一臉懵逼
Tandy Coco視頻和音頻輸出(UVD克隆)

PCB Tandy CoCo EPROM墨盒設(shè)計
多模態(tài)上下文指令調(diào)優(yōu)數(shù)據(jù)集MIMIC-IT






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論