") 基于Transformer的可泛化人體表征設(shè)計方案
基于Transformer的可泛化人體表征設(shè)計方案
作者:潘嘯,論文第一作者
0. 筆者前言
可泛化人體重建旨在在多個人體視頻上進行預(yù)訓(xùn)練,學(xué)習(xí)可泛化的重建先驗。在測試階段,給定新人物的稀疏視角參考圖,在無需微調(diào)或者訓(xùn)練的情況下,可直接輸出新視角。以往方法大部分使用基于稀疏卷積(SparseConvNet)的人體表征方式,然而,一方面,稀疏卷積有限的感受野導(dǎo)致其對人體的自遮擋十分敏感,另一方面,其輸入為不斷變化的觀察空間姿勢下的人體,導(dǎo)致訓(xùn)練和推理階段的姿勢不匹配問題,降低了泛化能力。
不同于此,本文工作TransHuman使用Transformer圍繞SMPL表面構(gòu)建了人體部位之間的全局聯(lián)系,并且將輸入統(tǒng)一在標(biāo)準(zhǔn)姿勢下,顯著的提升了該表征的泛化能力。在多個數(shù)據(jù)集上達到了新SOTA的同時,具有很高的推理效率。
本文專注于可泛化人體重建任務(wù)。為了處理動態(tài)人體的運動和遮擋,之前方法主要采用了基于稀疏卷積的人體表征。然而,該表征方式1)在多變的觀察姿勢空間進行優(yōu)化,導(dǎo)致訓(xùn)練與測試階段輸入姿勢不一致,從而降低泛化性; 2)缺少人體部位之間的全局聯(lián)系,從而導(dǎo)致對人體的遮擋敏感。為了解決這兩個問題,我們提出了一個新的框架TransHuman。TransHuman在標(biāo)準(zhǔn)姿勢空間進行優(yōu)化, 并且使用Transformer構(gòu)建了人體部位之間的聯(lián)系。具體來講,TransHuman由三個部分組成:基于Transformer的人體編碼(TransHE), 可形變局部輻射場(DPaRF), 以及細粒度整合模塊 (FDI). 首先,TransHE在標(biāo)準(zhǔn)空間使用Transformer處理SMPL;然后,DPaRF將TransHE輸出的每個Token視為一個可形變的局部輻射場來獲得觀察空間下某一查詢點的特征。最后,F(xiàn)DI進一步從參考圖中直接收集細粒度的信息。本文在ZJU-MoCap及H36M上進行大量實驗,證明了TransHuman的泛化性顯著優(yōu)于之前方法,并具有較高的推理效率。
4. 算法解析
Pipeline概覽 / 研究背景
TransHuman的pipeline如圖4所示。整個pipeline可以抽象為:給定空間中一個查詢點(Query Point),我們需要從多視角參考圖中提取一個對應(yīng)的 條件特征(Condition Feature) 輸入NeRF,從而實現(xiàn)泛化能力(詳細可參考PixelNeRF)。而條件特征主要由兩部分組成:表面特征(Appearance Feature)及人體表征(Human Representation)。
表面特征:該特征可由將查詢點通過相機參數(shù)進行反向投影后在參考圖中進行插值得到,其直接反應(yīng)參考圖中的原始RGB信息,因此屬于細粒度信息。但由于其缺少人體幾何先驗信息,僅使用此特征會導(dǎo)致人體幾何的崩塌(詳見Paper原文實驗部分);
人體表征:為獲得人體表征,首先通過現(xiàn)有的SMPL估計方法,從視頻中擬合出一個SMPL模版(Fitted SMPL,數(shù)據(jù)集一般自帶)。然后對于SMPL的每一個頂點,將其反向投影到參考圖得到該頂點對應(yīng)的CNN Feature,就得到了著色之后的SMPL(Painted SMPL)。從著色之后的SMPL提取出來的特征便是人體表征。人體表征包含了人的幾何先驗,因此在pipeline中起著關(guān)鍵作用,也是本文的研究重點。
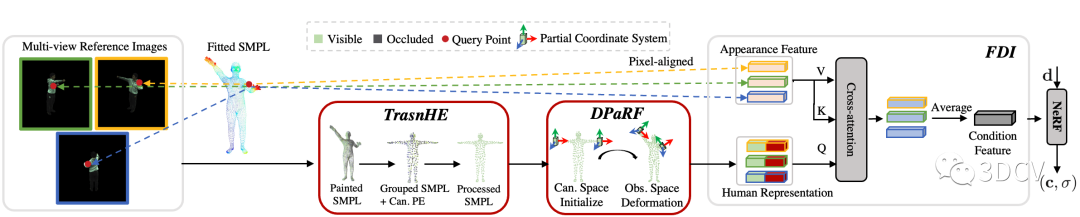
圖4:Pipeline概覽圖
研究動機
之前的方法主要利用稀疏卷積(SparseConvNet) 來得到人體表征 ,如圖5上半部分所示。該方法主要有兩個問題:
多變的輸入姿勢問題。 稀疏卷積的輸入為觀察姿勢下的SMPL,也就是說其輸入的姿勢會隨著幀數(shù)的變化而變化。這導(dǎo)致了訓(xùn)練和推理階段的輸入姿勢不一致問題(推理階段的人的姿勢可能是各種各樣的),從而極大的增加了泛化的難度。
局部感受野問題。 由于我們所能獲取的參考圖往往是十分稀疏的(本文默認采用3個視角),所以著色之后的SMPL通常包含大量的被遮擋部分。而另一方面,稀疏卷積本質(zhì)是3D卷積,其感受野比較有限,從而導(dǎo)致無法進行人體部位之間的全局的推理。具體舉例來說,假設(shè)人的左手是可見的而右手是被遮擋的,如果有全局之間的關(guān)系,那么網(wǎng)絡(luò)理論上可以推斷出右手被遮擋的部分大概是什么樣。基于此直覺,我們認為在人體不同部位之間構(gòu)建全局關(guān)系是很重要的。
為了解決以上兩個問題,我們提出了本文關(guān)鍵的兩個創(chuàng)新點(如圖5下半部分所示),即:
用Transformer在SMPL表面之間構(gòu)建全局關(guān)系,即TransHE部分。
將網(wǎng)絡(luò)輸入先統(tǒng)一在標(biāo)準(zhǔn)空間(比如T-pose的SMPL),然后將輸出通過SMPL形變的方式轉(zhuǎn)化回觀察姿勢進行特征提取,即DPaRF部分。
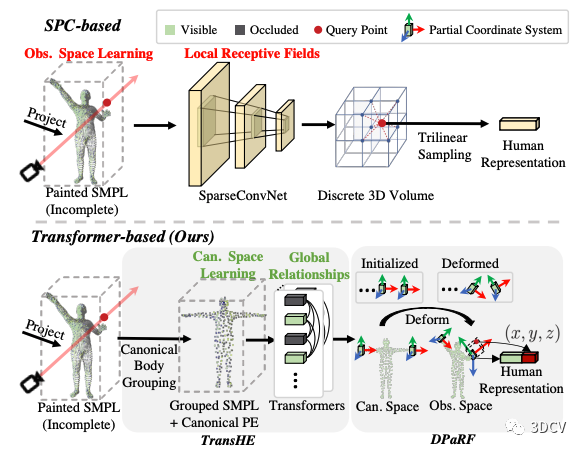
圖5:研究動機。SPC-base (Previous) vs. Transformer-based (Ours)。
基于Transformer的人體編碼 (TransHE)
接下來我們詳細介紹TransHE的細節(jié)。
如圖7左下角所示,TransHE模塊的輸入是Painted SMPL (6890 x d1,d1為CNN feature的維度)。一種直接的做法是將6890個Token輸入Transformer(本文使用ViT-Tiny),然而這種做法:
會帶來巨大的計算開銷。
會引入細粒度誤差(Fitted SMPL只是人體的粗略模版而不包含衣物等細節(jié),因此其著色本身也存在一定的誤差)。
基于這兩個問題,我們需要降低輸入Transformer的Token數(shù)量。
一種非常直接的想法是對Painted SMPL進行g(shù)rid voxelization,即,將空間均勻劃分為一個個小方塊,在同一個方塊內(nèi)的頂點取平均算做一個Token,同時把方塊中心作為Token對應(yīng)的PE。但由于Painted SMPL是在觀察姿勢下的,而觀察姿勢隨著輸入幀的變化而變化,這就導(dǎo)致每次輸入ViT的Token數(shù)量以及PE都在變化,使得優(yōu)化變得十分困難,而且會將不同語義部分劃分到同一個Token。圖6舉了一個人移動右手的例子,在這種情況下,grid voxelization對點的劃分會隨著姿勢的變化而變化,并且將左手和右手的頂點劃分在了同一個Token,這顯然不是我們所希望的。
為了進一步解決這個問題,我們提出先對標(biāo)準(zhǔn)姿勢SMPL(本文使用T-pose)進行K-Means聚類(本文默認聚300類)得到一個分組的字典。然后用該字典對Painted SMPL進行劃分,同一類的特征取均值作為Token,同時將標(biāo)準(zhǔn)姿勢SMPL下的聚類中心作為PE輸入ViT。這樣一來,Token數(shù)量和PE便不再受觀察姿勢的影響,極大的降低了學(xué)習(xí)的難度,如圖6右側(cè)所示。
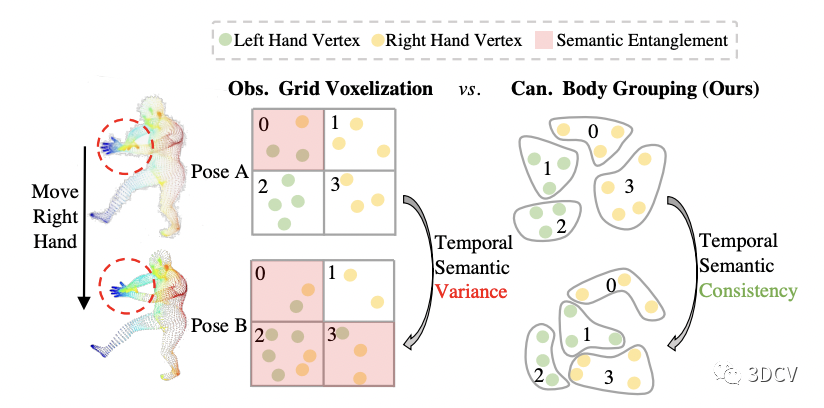
圖6:簡單的Grid Voxelization劃分方式(左) vs. 我們的劃分方式(右)。
可形變局部輻射場 (DPaRF)
由于我們在TransHE模塊將輸入統(tǒng)一在了標(biāo)準(zhǔn)姿勢,而我們最終需要的是觀察姿勢 下給定查詢點 對應(yīng)的特征,因此,我們需要將TransHE的輸出變回到觀察姿勢。這里我們的思路是,為每個Token(對應(yīng)一個身體部位)維護一個局部輻射場,且該輻射場的坐標(biāo)系隨著觀察姿勢 一起旋轉(zhuǎn),如圖7右下角所示。
然后對于每一個查詢點, 我們將其分配到距離最近的K個局部輻射場。對于每個局部輻射場,我們將Token與該場下的局部坐標(biāo)進行拼接得到該場下的人體表征。最終的人體表征 則是這K個場的所有人體表征的加權(quán)和(根據(jù)距離加權(quán))。
細粒度整合模塊 (FDI)
通過TransHE和DPaRF, 我們已經(jīng)得到了給定查詢點的人體表征,該表征包含了粗粒度的人體幾何先驗信息。接下來,和之前的工作類似,我們使用一個Cross-attention模塊,將粗粒度的人體表征 視作Q,細粒度的表面特征 視為K和V,得到最終的條件特征。
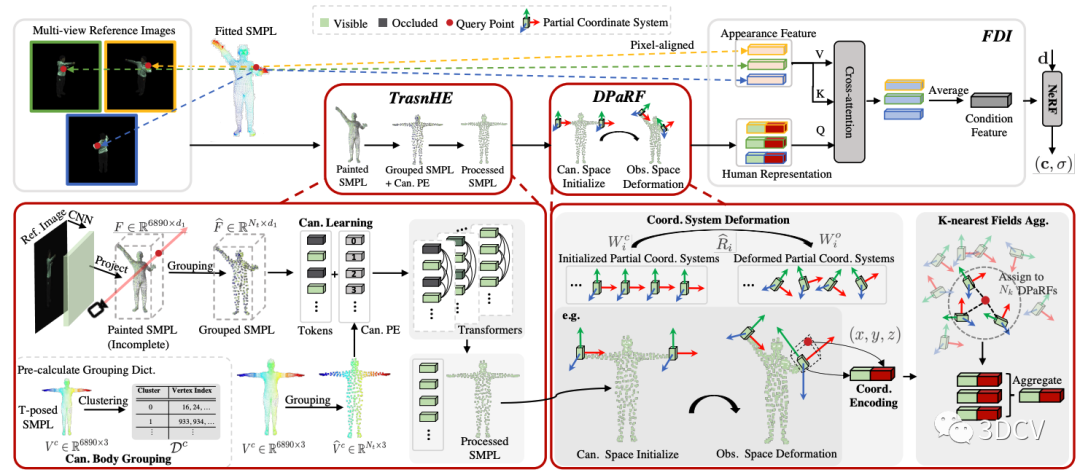
圖7:Pipeline細節(jié)圖。
5. 實驗結(jié)果
本文在ZJU-MoCap和H36M上進行了泛化性實驗,結(jié)果如下圖所示。主要分為四個setting: Pose的泛化,Identity的泛化,只給一張參考圖的泛化,以及跨數(shù)據(jù)集的泛化。在四個setting上均顯著高于之前方法,達到了新的SOTA。
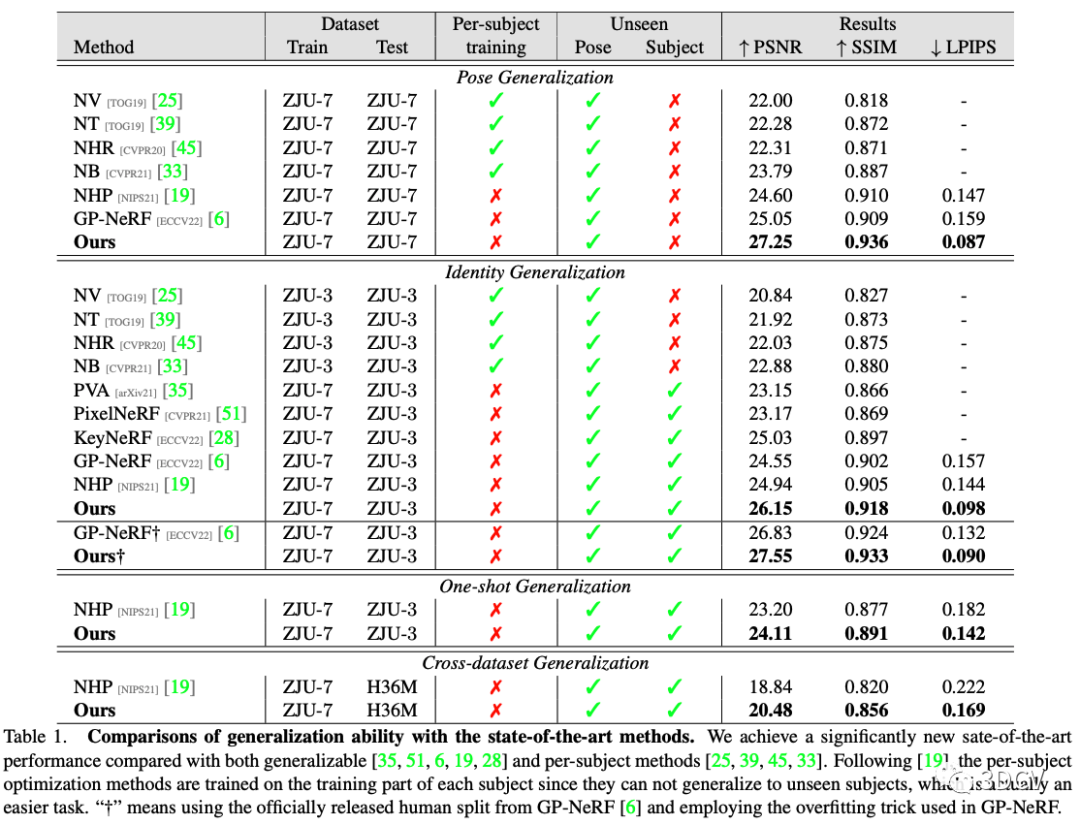
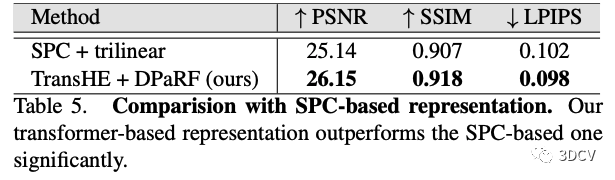
同時,作者還給出了在其代碼中直接將TransHE + DPaRF模塊替換成原來的SPC-based方法,以爭取盡量公平的對比。結(jié)果如下圖所示,本文方法仍明顯領(lǐng)先。
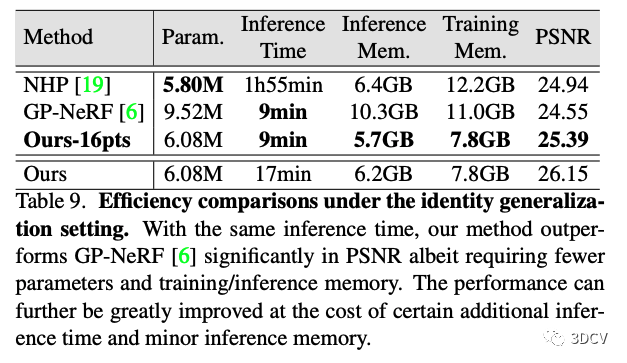
另外,作者對本文方法的效率也給出了分析。在使用相同推理時間的情況下,本文方法性能仍然明顯高于之前的方法,并且推理消耗的內(nèi)存更小。可見本文方法具有比較高的推理效率。
更多詳細的Ablation以及可視化推薦大家閱讀原文及觀看項目主頁的視頻DEMO。
6. 總結(jié)
本文為可泛化人體重建領(lǐng)域引入了一種新的基于Transformer的人體表征。該表征在人體部件之間構(gòu)建了全局關(guān)系,并將優(yōu)化統(tǒng)一在了標(biāo)準(zhǔn)姿勢下。其泛化性能明顯優(yōu)于先前的基于稀疏卷積的表征,而且具有比較高的推理效率,為后續(xù)可泛化人體重建的研究提供了一個新的更高效的模塊。
審核編輯:黃飛
-
Transformer
+關(guān)注
關(guān)注
0文章
146瀏覽量
6047
原文標(biāo)題:ICCV 2023開源 | 基于Transformer的可泛化人體表征來了!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
智能人體心率檢測裝置的設(shè)計方案
如何使用ads1298采集人體表面的表面肌電信號?
眼科超聲波診斷儀的設(shè)計方案
笨人的創(chuàng)意,創(chuàng)意智能插座設(shè)計方案,絕對可實現(xiàn)
品佳:適用于家庭智能照明的無線控制設(shè)計方案
大神求助tps333熱電堆傳感器為主的人體表面溫度檢測電路
ABBYY FineReader 和 ABBYY PDF Transformer+功能比對
如何更改ABBYY PDF Transformer+界面語言
AMEYA360設(shè)計方案丨人體感應(yīng)燈
泛在網(wǎng)是什么?
分享一款不錯的基于LM358的人體感應(yīng)燈電路設(shè)計方案
HarmonyOS的組件化設(shè)計方案
應(yīng)用案例 I 人體及醫(yī)用紅外熱像儀檢測校準(zhǔn)系統(tǒng)方案

SHERF:可泛化可驅(qū)動人體神經(jīng)輻射場的新方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論