 更深層的理解視覺Transformer, 對視覺Transformer的剖析
更深層的理解視覺Transformer, 對視覺Transformer的剖析
寫在前面&&筆者的個人理解
目前基于Transformer結構的算法模型已經在計算機視覺(CV)領域展現出了巨大的影響力。他們在很多基礎的計算機視覺任務上都超過了之前的卷積神經網絡(CNN)算法模型,下面是筆者找到的最新的在不同基礎計算機視覺任務上的LeaderBoard榜單排名,通過LeaderBoard可以看到,基于Transformer算法模型在各類計算機視覺任務上的統治地位。
圖像分類任務
首先是在ImageNet上的LeaderBoard,通過榜單可以看出,前五名當中,每個模型都使用了Transformer結構,而CNN結構只有部分使用,或者采用和Transformer相結合的方式。
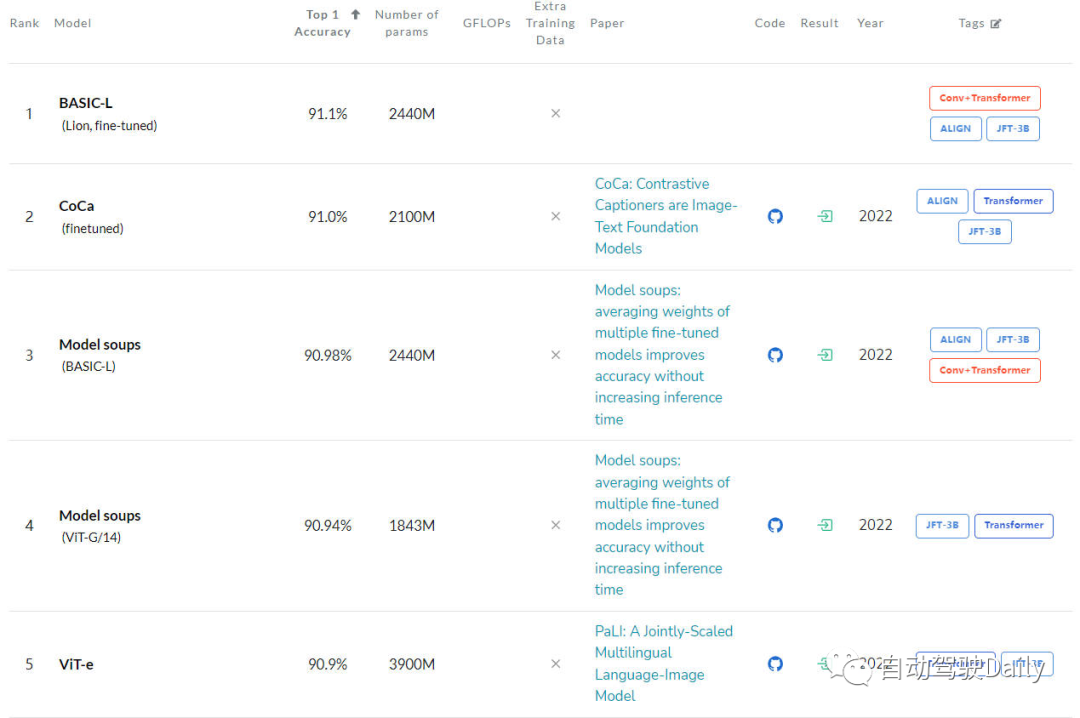
圖像分類任務的LeaderBoard
目標檢測任務
接下來是在COCO test-dev上的LeaderBoard,通過榜單可以看出,前五名當中,一半以上都是基于DETR這類算法結構進行延伸的。
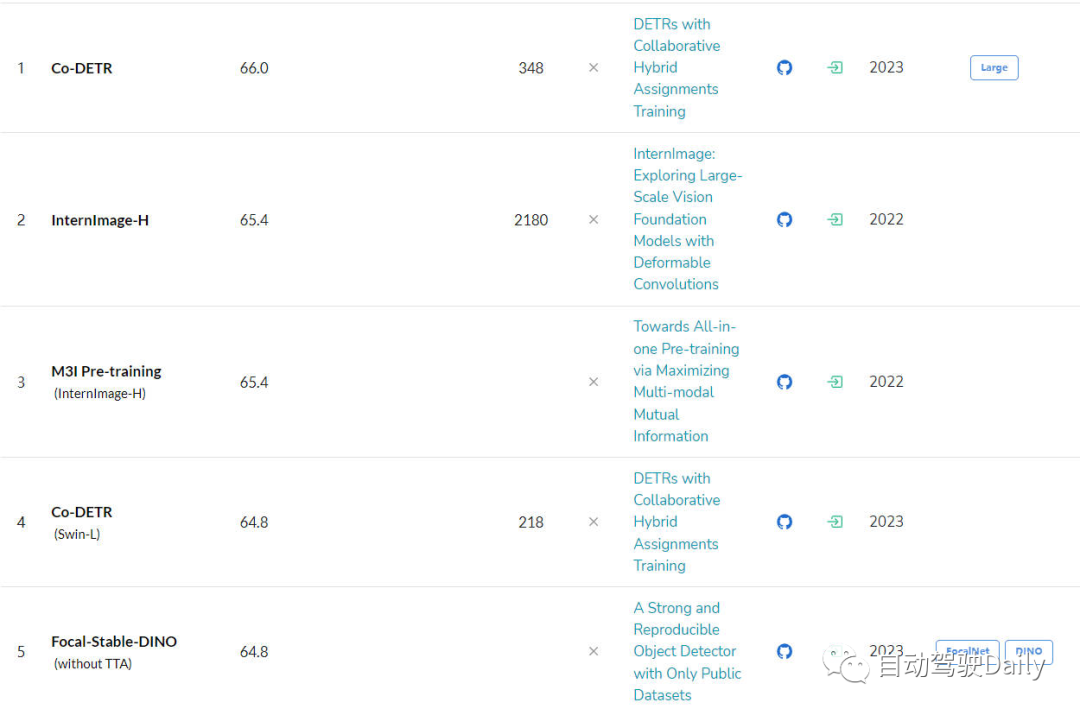
目標檢測任務的LeaderBoard
語義分割任務
最后是在ADE20K val上的LeaderBoard,通過榜單也可以看出,在榜單的前幾名中,Transformer結構依舊占據是當前的主力軍。
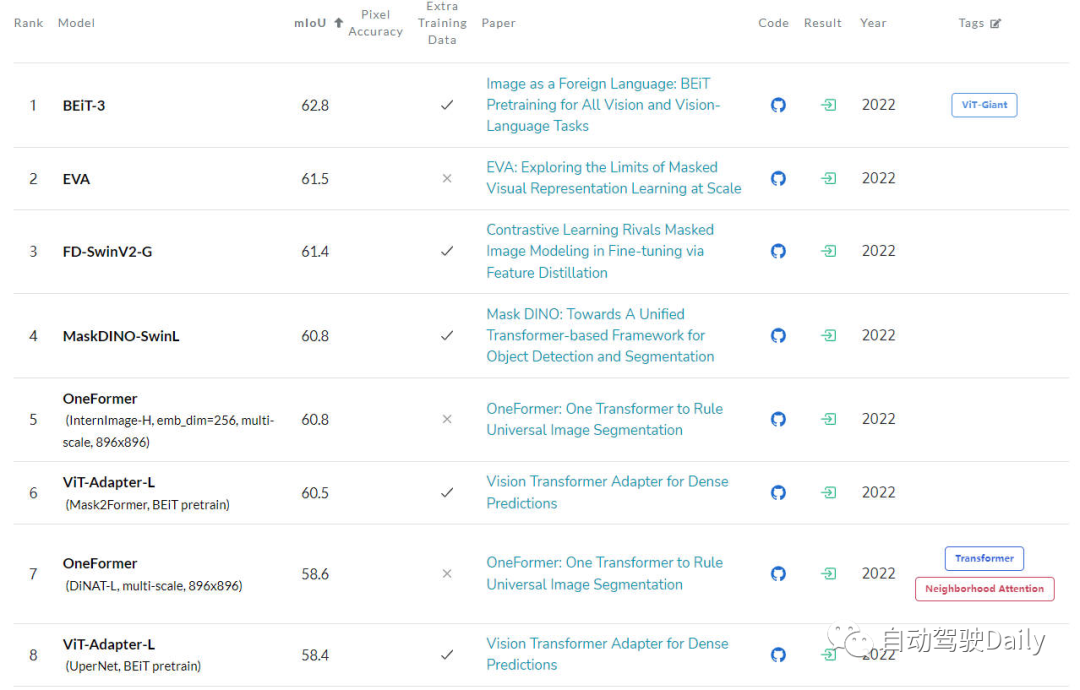
語義分割任務的LeaderBoard
雖然目前Transformer展現出了巨大的發展前景,但是現在的計算機視覺社區還并沒有完全掌握Vision Transformer的內部工作原理,也沒有掌握其決策(輸出的預測結果)的基礎,那對其可解釋性的需求就逐漸凸顯了出來。因為只有了解了這類模型是如何做出決策的,才不僅可以提高它們的性能,還可以建立對人工智能系統的信任。
所以本文的主要動機就是探索Vision Transformer的不同可解釋性方法,并根據不同算法的研究動機、結構類型以及應用場景進行分類,從而形成了一篇綜述文章。
刨析Vision Transformer
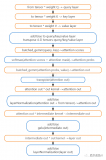
因為剛才提到,Vision Transformer的結構在各類基礎的計算機視覺任務中都取得了非常不錯的成績。所以之后計算機視覺社區涌現出了很多方法來增強它的可解釋性。本文我們主要以分類任務為主線,從Common Attribution Methods、Attention-based Methods、Pruning-based Methods、Inherently Explainable Methods、Other Tasks這五個方面中,挑選出最新以及經典的工作進行介紹。這里放一下論文中出現的思維導圖,大家可以根據自身感興趣的內容,進行更加細致的閱讀~
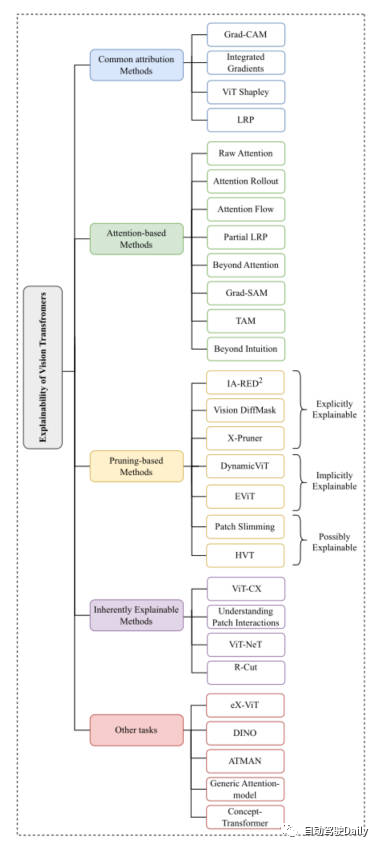
本文思維導圖
Common Attribution Methods
基于屬性方法的解釋通常的出發點是對模型的輸入特征如何一步一步得到最終輸出結果過程的解釋。這類方法主要用于衡量模型的預測結果和輸入特征之間的相關性。
在這些方法中,例如Grad-CAM以及Integrated Gradients算法是直接應用于了基于視覺Transformer的算法上。一些其他的方法像SHAP和Layer-Wise Relevance Propagation(LRP)已經被用來探索基于ViT的架構上了。但是由于SHAP這類方法到的計算成本非常大,所以最近的ViT Shapely算法被設計出來用于適配ViT的相關應用研究。
Attention-based Methods
Vision Transformer正是得益于其注意力機制使其擁有了強大的特征提取能力。而在基于注意力的可解釋性方法中,對注意力權重結果進行可視化則是一種非常有效的方法。本文對其中的幾種可視化技術進行介紹
Raw Attention:該方法顧名思義,就是對網絡模型中間層得到的注意力權重圖進行可視化,從而對模型的效果進行分析。
Attention Rollout:該技術通過對網絡的不同層中擴展注意力權重來跟蹤從輸入token到中間embedding之間的信息傳輸。
Attention Flow:該方法將注意力圖視為一個流量網絡,并使用最大流量算法計算從中間embedding到輸入token的最大流量值。
partialLRP:該方法是用于可視化Vision Transformer中的多頭注意力機制提出來的,同時還考慮了每個注意力頭的重要性。
Grad-SAM:該方法用于緩解僅依靠原始注意力矩陣來解釋模型預測的局限性,促使研究人員將梯度以用于原始的注意力權重中。
Beyond Intuition:該方法也是一種用于解釋注意力的方法,包括注意力感知和推理反饋兩個階段。
最后放一張不同可解釋性方法的注意力可視化圖,大家可以自行感受一下不同可視化方法的區別。

不同可視化方法的注意力圖對比
Pruning-based Methods
剪枝是一種非常有效的方法,被廣泛應用于優化transformer結構的效率和復雜性。剪枝方法通過對冗余或者沒用的信息進行刪減,從而降低模型的參數量和計算復雜度。雖然剪枝算法側重于提高模型的計算效率,但是該類算法依舊可以實現對模型的可解釋性。
本文中針對基于Vision-Transformer的剪枝方法,大體可以分成三大類:explicitly explainable(顯式可解釋)、implicitly explainable(隱式可解釋)、possibly explainable(可能可解釋)。
Explicitly Explainable
在基于剪枝的方法當中,有幾類方法可以提供簡單而且更可解釋的模型。
IA-RED^2:該方法的目標是在算法模型的計算效率以及可解釋性之間實現一個最優的平衡。并且在這個過程當中,保持原有ViT算法模型的靈活性。
X-Pruner:該方法是一種用于剪枝顯著性單元的方法,通過創建一個可解釋性的感知掩碼來衡量每個可預測單元在預測特定類中的貢獻。
Vision DiffMask:該剪枝方法包括在每個ViT層上加入門控機制,通過門控機制,可以實現在屏蔽輸入的同時保持模型的輸出。除此之外,該算法模型可以清晰地觸發剩余圖像中的子集,從而實現更好地對模型預測的理解。
Implicitly Explainable
基于剪枝的方法當中,也有一些經典的方法可以被劃分為隱式的可解釋性模型類別中。
Dynamic ViT:該方法采用輕量級預測模塊,根據當前的特征去估計每個token的重要性程度。然后將該輕量級的模塊加入到ViT的不同層中,以分層的方式來修剪冗余的token。最重要的是,該方法通過逐步定位對分類貢獻最大的關鍵圖像部分來增強可解釋性。
Efficient Vision Transformer(EViT):該方法的核心思想是通過重組token的方式來加速EViT。通過計算注意力得分,EViT保留最相關的token,同時將不太相關的token融合到另外的token中。同時論文的作者為了評估EViT的可解釋性,對多個輸入圖像可視化了token的識別過程。
Possibly Explainable
雖然這類方法最初并不是為了提高ViT的可解釋性,但是這類方法為進一步研究模型的可解釋性提供了很大的潛力。
Patch Slimming:通過自上而下的方法來專注圖像中的冗余patch來加速ViT。該算法選擇性的保留了關鍵補丁的能力來突出重要的視覺特征,從而增強可解釋性。
Hierarchical Visual Transformer(HVT):該方法的引入用于去增強ViT的可擴展性和性能。隨著模型深度的增加,序列長度逐漸減小。此外,通過將ViT塊劃分為多個階段,并在每個階段應用池化操作,顯著提高了計算效率。考慮到對模型最重要組成部分的逐漸集中,有機會探索其對增強可解釋性和可解釋性的潛在影響。
Inherently Explainable Methods
在不同的可解釋方法中,有一類方法主要是開發能夠內在地解釋算法模型,然而,這些模型通常難以達到與更復雜的黑盒模型相同的精度水平。因此,必須在可解釋性和性能之間考慮謹慎的平衡。接下來對一些經典的工作進行簡要的介紹。
ViT-CX:該方法針對ViT模型定制的基于掩碼的解釋方法。這種方法依賴patch embedding以及其對模型輸出的影響,而不是聚焦對它們的關注。該方法包括掩碼生成和掩碼聚合兩個階段,從而提供更有意義的顯著性圖。
ViT-NeT:該方法是一種新的神經樹解碼器,通過樹形結構和原型來描述決策過程。同時,該算法還可以對結果進行可視化解釋。
R-Cut:該方法是通過Relationship Weighted Out and Cut來增強ViT的可解釋性。該方法包括兩個模塊,分別是Relationship Weighted Out和Cut模塊。前者側重于從中間層提取特定類的信息,強調相關特征。后者執行細粒度的特征分解。通過對兩個模塊的集成,可以生成密集的特定于類的可解釋性映射。
Other Tasks
就如同在文章開頭提到的,除了分類之外,基于ViT的架構對其他CV任務的解釋性仍在探索中。有幾種專門針對其他任務提出的可解釋性方法,接下來就對相關領域的最新工作進行介紹~
eX-ViT:該算法是一種基于弱監督語義分割的新型可解釋視覺轉換器。此外,為了提高可解釋性,引入了屬性導向損失模塊,該模塊包含全局級屬性導向損失、局部級屬性可判別性損失和屬性多樣性損失三種損失。前者使用注意圖來創建可解釋的特征,后兩者則增強屬性學習。
DINO:該方法是一種簡單的自監督方法,并且是一種不帶標簽的自蒸餾方法。最終學習到的注意圖能夠有效地保留圖像的語義區域,從而實現可以解釋的目的。
Generic Attention-model:該方法是一種基于Transformer架構做預測的算法模型。該方法應用于三種最常用的架構,即純自注意、自注意與共同注意相結合和編碼器-解碼器注意。為了檢驗模型的解釋性,作者使用了視覺問答任務,然而,它也適用于其他CV任務,如目標檢測和圖像分割。
ATMAN:這是一種模態不可知的擾動方法,利用注意機制生成輸入相對于輸出預測的相關性圖。該方法試圖通過記憶效率注意操作來理解變形預測。
Concept-Transformer:該算法通過突出顯示用戶定義的高級概念的注意分數來生成模型輸出的解釋,從而確保可信性和可靠性。
未來展望
雖然目前基于Transformer架構的算法模型已經在各類計算機視覺任務上取得了非常出色的成績。但是目前來看,對于如何利用可解釋性方法的好處來促進模型調試和改進,以及提高模型的公平性和可靠性,特別是在ViT應用中,一直缺乏明顯的研究。
所以本文以圖像分類任務出發,對現有的基于Vision Transformer的可解釋性算法模型進行歸類整理,從而幫助人們更好的理解此類模型架構,希望可以對大家有所幫助。
-
算法
+關注
關注
23文章
4630瀏覽量
93352 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46127 -
Transformer
+關注
關注
0文章
145瀏覽量
6047
原文標題:更深層的理解視覺Transformer, 對視覺Transformer的剖析
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何更改ABBYY PDF Transformer+界面語言
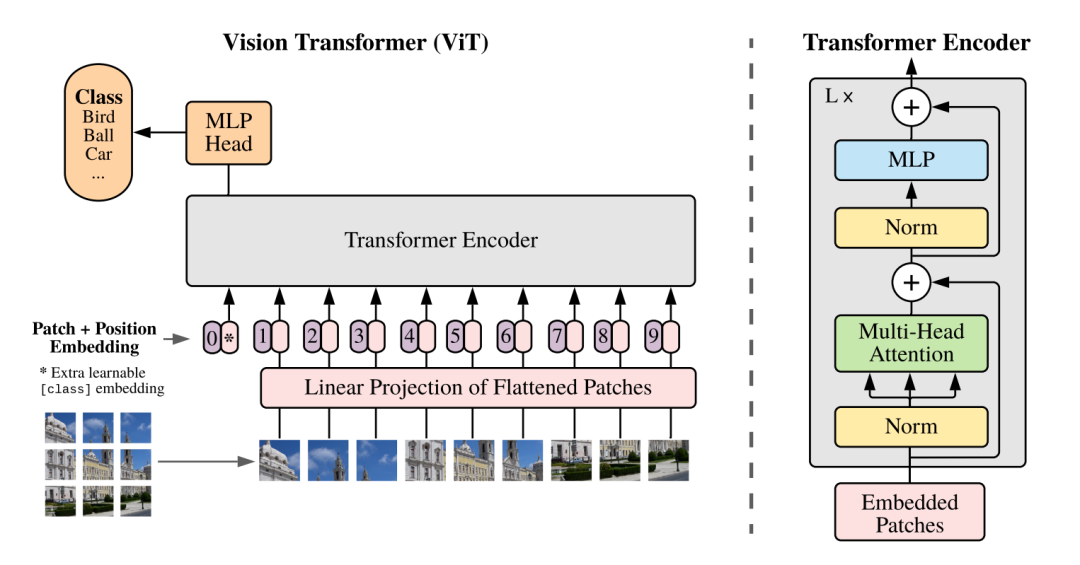
視覺新范式Transformer之ViT的成功
Transformer模型的多模態學習應用
用于語言和視覺處理的高效 Transformer能在多種語言和視覺任務中帶來優異效果
基于卷積的框架有效實現及視覺Transformer背后的關鍵成分
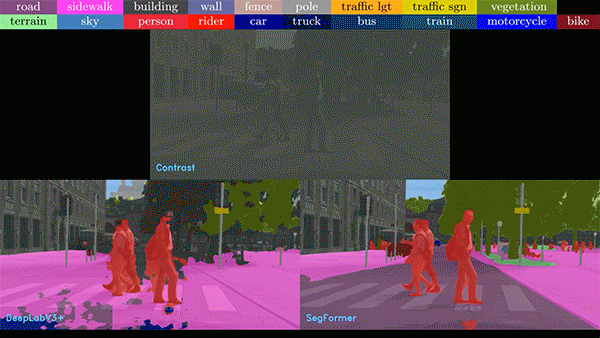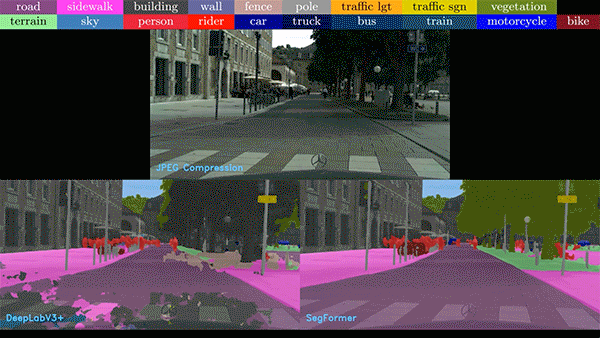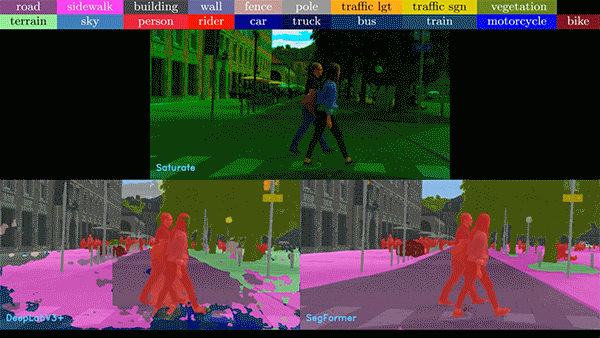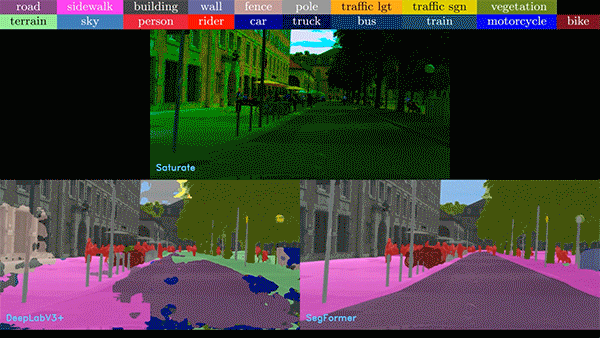
普通視覺Transformer(ViT)用于語義分割的能力
視覺Transformer在CV中的現狀、趨勢和未來方向
基于視覺transformer的高效時空特征學習算法
CVPR 2023 | 清華大學提出LiVT,用視覺Transformer學習長尾數據

如何入門面向自動駕駛領域的視覺Transformer?
使用 Vision Transformer 和 NVIDIA TAO,提高視覺 AI 應用的準確性和魯棒性
汽車領域擁抱Transformer需要多少AI算力?
Faster Transformer v1.0源碼詳解
LLM的Transformer是否可以直接處理視覺Token?

視覺Transformer基本原理及目標檢測應用





 工商網監
工商網監
評論