 何愷明新作RCG:無自條件圖像生成新SOTA!與MIT首次合作!
何愷明新作RCG:無自條件圖像生成新SOTA!與MIT首次合作!
大佬何愷明還未正式入職MIT,但和MIT的第一篇合作研究已經出來了:
他和MIT師生一起開發了一個自條件圖像生成框架,名叫RCG(代碼已開源)。
這個框架結構非常簡單但效果拔群,直接在ImageNet-1K數據集上實現了無條件圖像生成的新SOTA。
它生成的圖像不需要任何人類注釋(也就是提示詞、類標簽什么的),就能做到既保真又具有多樣性。

這樣的它不僅顯著提高了無條件圖像生成的水平,還能跟當前最好的條件生成方法一較高下。
用何愷明團隊自己的話來說:
有條件和無條件生成任務之間長期存在的性能差距,終于在這一刻被彌補了。
那么,它究竟是如何做到的呢?
類似自監督學習的自條件生成
首先,所謂無條件生成,就是模型在沒有輸入信號幫助的情況下直接捕獲數據分布生成內容。
這種方式比較難以訓練,所以一直和條件生成有很大性能差距——就像無監督學習比不過監督學習一樣。
但就像自監督學習的出現,扭轉了這一局面一樣。
在無條件圖像生成領域,也有一個類似于自監督學習概念的自條件生成方法。
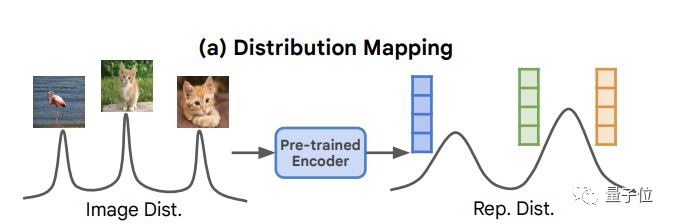
相比傳統的無條件生成簡單地將噪聲分布映射到圖像分布,這種方法主要將像素生成過程設置在從數據分布本身導出的表示分布上。
它有望超越條件圖像生成,并推動諸如分子設計或藥物發現這種不需要人類給注釋的應用往前發展(這也是為什么條件生成圖像發展得這么好,我們還要重視無條件生成)。
現在,基于這個自條件生成概念,何愷明團隊首先開發了一個表示擴散模型RDM。
它主要用于生成低維自監督圖像表示,方法是通過自監督圖像編碼器從圖像中截取:
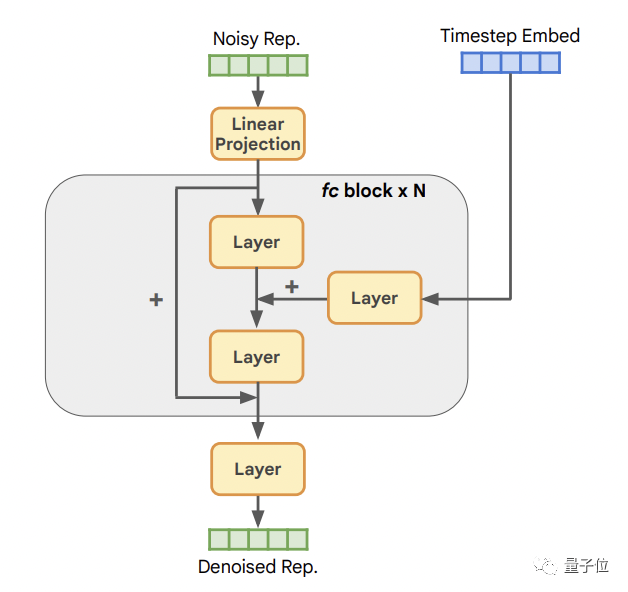
它的核心架構如下:
首先是輸入層,它負責將表征投射到隱藏維度C,接著是N個全連接塊,最后是一個輸出層,負責把隱藏層的潛在特征重新投射(轉換)到原始表征維度。
其中每一層都包含一個LayerNorm層、一個SiLU層以及一個線性層。
這樣的RDM具有兩個優點:
一是多樣性強,二是計算開銷小。
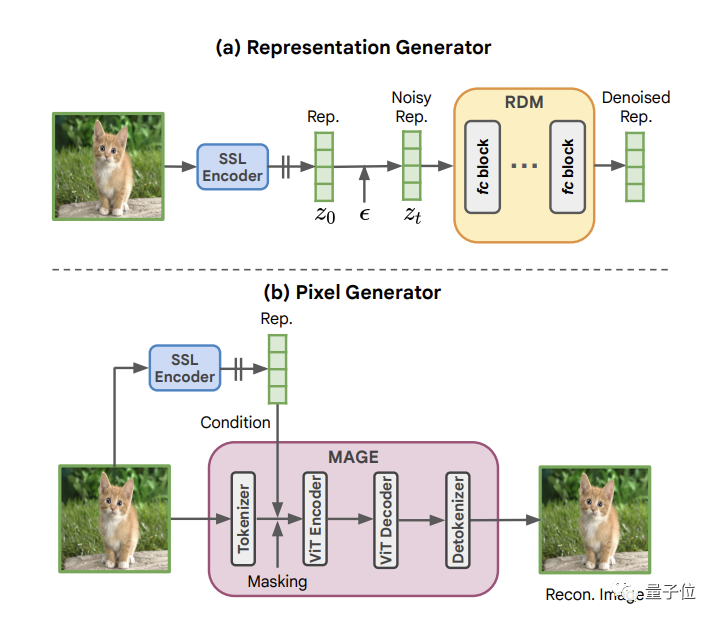
接著,利用RDM,團隊就提出了今天的主角:表示條件圖像生成架構RCG。
它是一個簡單的自條件生成框架,由三個組件組成:
一個是SSL圖像編碼器,用于將圖像分布轉換為緊湊的表示分布。
一個是RDM,用于對該分布進行建模和采樣。
最后是一個像素生成器MAGE,用于根據表示來處理圖像像。
MAGE的工作方式主要是向token化的圖像中添加隨機掩碼,并要求網絡以從同一圖像中提取的表示為條件來重建丟失的token。
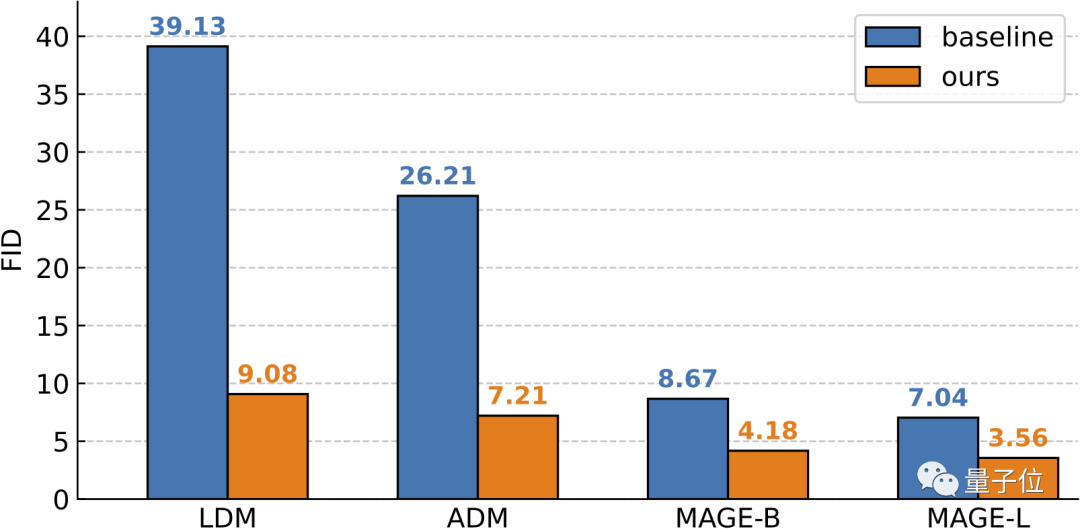
最終,測試表明,這個自條件生成框架雖結構簡單但效果非凡:
在ImageNet 256×256上,RCG實現了3.56的FID和186.9的IS(Inception Score)得分。
相比之下,在它之前最厲害的無條件生成方法FID分數為7.04,IS得分為123.5。
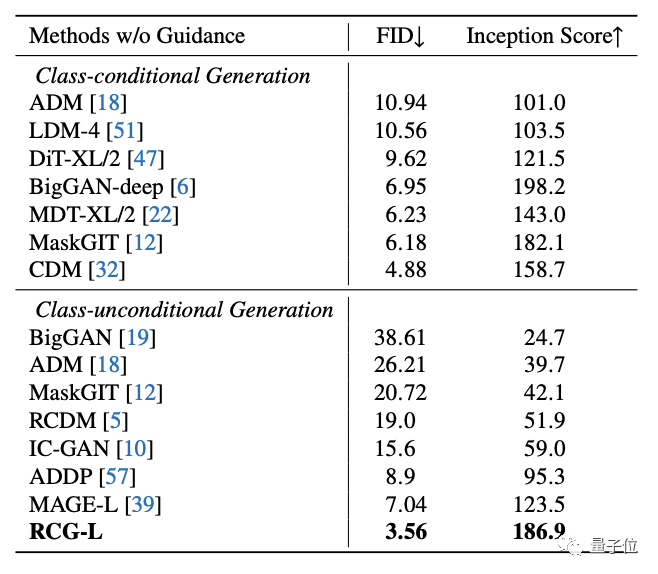
以及,相比條件生成,RCG也絲毫不遜色,可以達到相當甚至超過該領域基準模型的水平。
最后,在無分類器引導的情況下,RCG的成績還能進一步提高到3.31(FID)和253.4(IS)。
團隊表示:
這些結果表明,自條件圖像生成模型擁有巨大潛力,可能預示這一領域新時代的到來。
團隊介紹
本文一共三位作者:

代碼:https://github.com/LTH14/rcg
論文:https://arxiv.org/abs/2312.03701
一作是MIT博士生黎天鴻,本科畢業于清華姚班,研究方向為跨模態集成傳感技術。
他的主頁很有意思,還專門放了一個菜譜合集——做研究和做飯是他最熱愛的兩件事。
另一位作者是MIT電氣工程與計算機科學系(EECS)教授、MIT無線網絡和移動計算中心主任Dina Katabi,她是今年斯隆獎的獲得者,并已當選美國國家科學院院士。
最后,通訊作者為何愷明,他將在明年正式回歸學界、離開Meta加入MIT電氣工程和計算機科學系,與Dina Katabi成為同事。
-
圖像
+關注
關注
2文章
1089瀏覽量
40575 -
MIT
+關注
關注
3文章
253瀏覽量
23504 -
數據集
+關注
關注
4文章
1209瀏覽量
24836
原文標題:何愷明新作RCG:無自條件圖像生成新SOTA!與MIT首次合作!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
借助谷歌Gemini和Imagen模型生成高質量圖像

奧飛主題文化科技與洲明科技達成戰略合作
Mamba入局圖像復原,達成新SOTA
VCA810無輸入自激怎么解決?
Freepik攜手Magnific AI推出AI圖像生成器
fx3 UVC 32bit無圖像黑屏的原因?
旋變位置不變的情況下,當使能SOTA功能與關閉SOTA功能時,APP中DSADC采樣得到的旋變sin和cos兩者值不一樣,為什么?
IBM與SAP深化生成式AI領域合作
OpenAI發布圖像檢測分類器,可區分AI生成圖像與實拍照片
麻省理工與Adobe新技術DMD提升圖像生成速度
博世與微軟合作開發生成式AI產品
KOALA人工智能圖像生成模型問世
Stability AI試圖通過新的圖像生成人工智能模型保持領先地位






 工商網監
工商網監
評論