 基于機器翻譯增加的跨語言機器閱讀理解算法
基于機器翻譯增加的跨語言機器閱讀理解算法
作者:阿里云云棲號
鏈接:https://my.oschina.net/yunqi/blog/10319964
近日,阿里云人工智能平臺 PAI 與華南理工大學朱金輝教授團隊、達摩院自然語言處理團隊合作在自然語言處理頂級會議 EMNLP2023 上發表基于機器翻譯增加的跨語言機器閱讀理解算法 X-STA。通過利用一個注意力機制的教師來將源語言的答案轉移到目標語言的答案輸出空間,從而進行深度級別的輔助以增強跨語言傳輸能力。同時,提出了一種改進的交叉注意力塊,稱為梯度解纏知識共享技術。此外,通過多個層次學習語義對齊,并利用教師指導來校準模型輸出,增強跨語言傳輸性能。實驗結果顯示,我們的方法在三個多語言 MRC 數據集上表現出色,優于現有的最先進方法。
背景
大規模預訓練語言模型的廣泛應用,促進了 NLP 各個下游任務準確度大幅提升,然而,傳統的自然語言理解任務通常需要大量的標注數據來微調預訓練語言模型。但低資源語言缺乏標注數據集,難以獲取。大部分現有的 MRC 數據集都是英文的,這對于其他語言來說是一個困難。其次,不同語言之間存在語言和文化的差異,表現為不同的句子結構、詞序和形態特征。例如,日語、中文、印地語和阿拉伯語等語言具有不同的文字系統和更復雜的語法系統,這使得 MRC 模型難以理解這些語言的文本。
為了解決這些挑戰,現有文獻中通常采用基于機器翻譯的數據增強方法,將源語言的數據集翻譯成目標語言進行模型訓練。然而,在 MRC 任務中,由于翻譯導致的答案跨度偏移,無法直接使用源語言的輸出分布來教導目標語言。
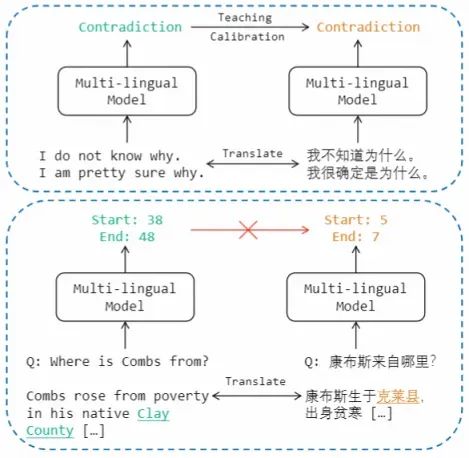
因此,本文提出了一種名為 X-STA 的跨語言 MRC 方法,遵循三個原則:共享、教導和對齊。共享方面,提出了梯度分解的知識共享技術,通過使用平行語言對作為模型輸入,從源語言中提取知識,增強對目標語言的理解,同時避免源語言表示的退化。教導方面,本方法利用注意機制,在目標語言的上下文中尋找與源語言輸出答案語義相似的答案跨度,用于校準輸出答案。對齊方面,多層次的對齊被利用來進一步增強 MRC 模型的跨語言傳遞能力。通過知識共享、教導和多層次對齊,本方法可以增強模型對不同語言的語言理解能力。
算法概述
X-STA 模型框架圖如下所示:
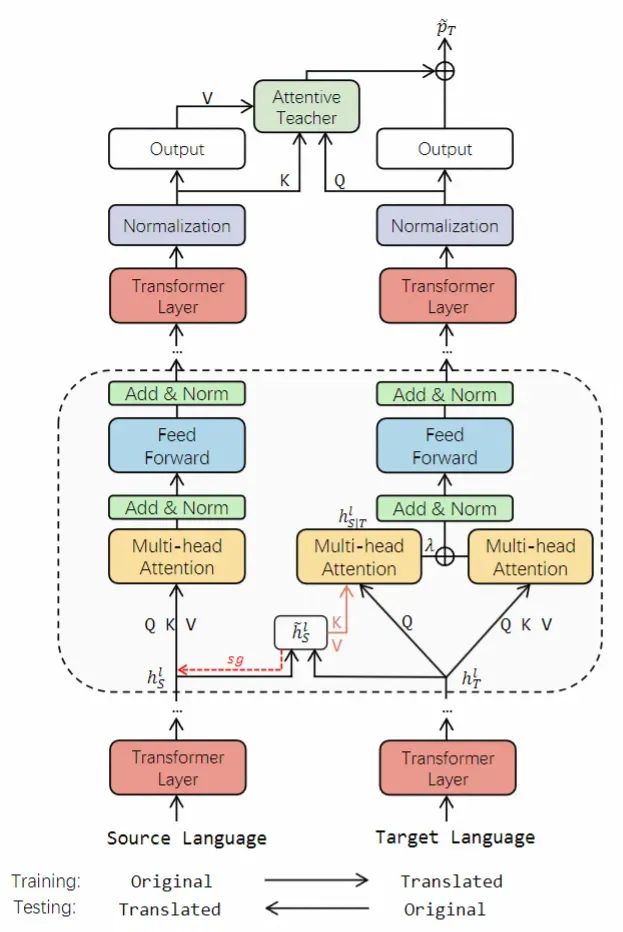

具體流程如下:
先將源語言的目標數據翻譯到各個目標語言,目標語言的測試數據也翻譯回源語言。
每項數據包含問題 Q 和上下文段落 C。
構建并行語言對 ={源語言訓練數據,目標語言訓練數據} 送入模型并使用反向傳播進行模型訓練。
將并行語言對 ={源語言測試數據,目標語言測試數據} 送入模型獲取答案的預測。
算法精度評測
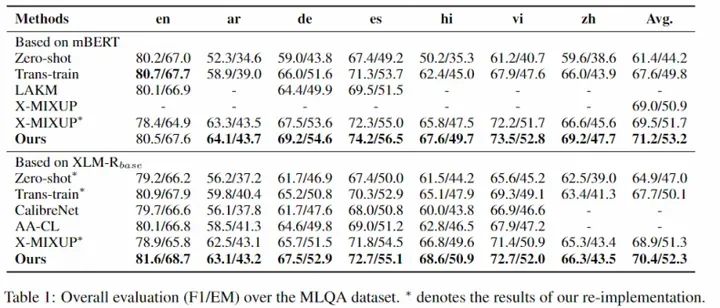
為了驗證 X-STA 算法的有效性,我們在三個跨語言 MRC 數據集上進行了測試,效果證明 X-STA 對精度提升明顯:
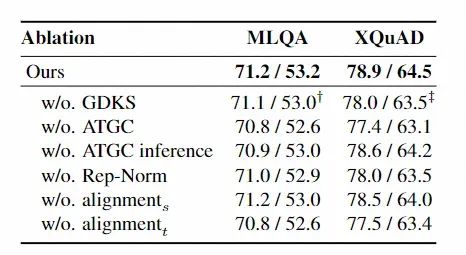
我們也對算法的模塊進行了詳細有效性分析,我們可以發現各模塊均對模型有一定貢獻。
為了更好地服務開源社區,這一算法的源代碼即將貢獻在自然語言處理算法框架 EasyNLP 中,歡迎 NLP 從業人員和研究者使用。
-
算法
+關注
關注
23文章
4630瀏覽量
93354 -
人工智能
+關注
關注
1796文章
47666瀏覽量
240282 -
數據集
+關注
關注
4文章
1209瀏覽量
24833 -
阿里云
+關注
關注
3文章
974瀏覽量
43230 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13646
原文標題:基于知識遷移的跨語言機器閱讀理解算法
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器翻譯三大核心技術原理 | AI知識科普
機器翻譯三大核心技術原理 | AI知識科普 2
神經機器翻譯的方法有哪些?
阿里巴巴機器翻譯在跨境電商場景下的應用和實踐
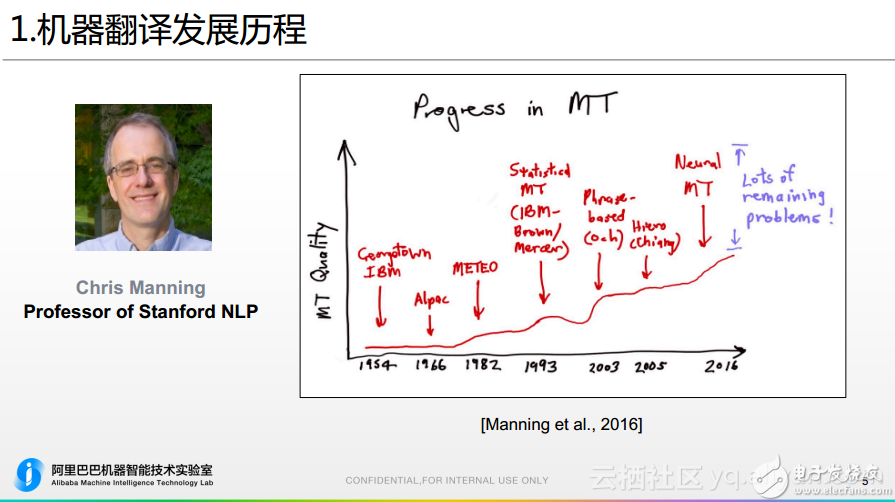
換個角度來聊機器翻譯

科大訊飛機器翻譯首次達到專業譯員水平 機器閱讀超越人類平均水平
多語言翻譯新范式的工作:機器翻譯界的BERT
基于短語的漢語維吾爾語機器翻譯系統
借助機器翻譯來生成偽視覺-目標語言對進行跨語言遷移
大語言模型的多語言機器翻譯能力分析

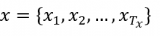





 工商網監
工商網監
評論