 大模型訓練loss突刺原因和解決辦法
大模型訓練loss突刺原因和解決辦法
最近閱讀了《A Theory on Adam Instability in Large-Scale Machine Learning 》這篇論文。比較全面的闡述了100B以上的大模型預訓練中出現loss spike的原因(loss 突然大幅度上漲),并介紹了一些可能的解決辦法。論文寫的非常精彩,但整體上有點散和深,我嘗試著站在工業立場上把它串一下
突刺是什么
首先介紹一下什么是loss spike:
loss spike指的是預訓練過程中,尤其容易在大模型(100B以上)預訓練過程中出現的loss突然暴漲的情況
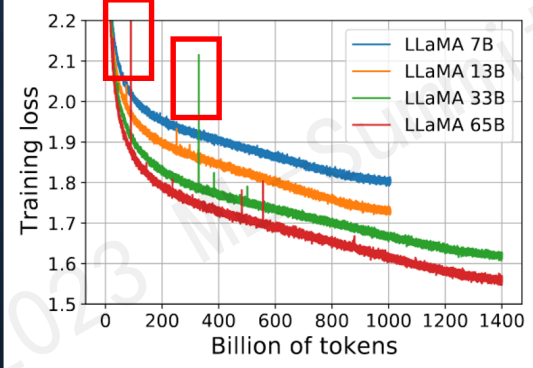
如圖所示模型訓練過程中紅框中突然上漲的loss尖峰loss spike的現象會導致一系列的問題發生,譬如模型需要很長時間才能再次回到spike之前的狀態(論文中稱為pre-explosion),或者更嚴重的就是loss再也無法drop back down,即模型再也無法收斂
PaLM和GLM130b之前的解決辦法是找到loss spike之前最近的checkpoint,更換之后的訓練樣本來避免loss spike的出現。
突刺成因分析
這篇論文(以下稱本文)對loss spike的出現原因做了十分詳細的分析,最后認為預訓練使用的Adam優化器是導致這個現象出現的重要原因之一
首先回顧一下Adam優化器的結構(這里介紹的是較為傳統的Adam優化器,現在nlp任務更偏向于使用帶有正則化項的Adamw變體):
其中均為超參數( ,防止除0),表示第t次更新的梯度, 的初始值 為0。
本文首先對Adam的有效性做了論述,其本質在于證明了Adam優化過程是對牛頓下降法(二階導)的一個有效逼近,因此在收斂速度上大幅度領先傳統SGD(一階導),證明過程不做贅述,可以參考本文和Adam系列相關論文
Adam算法是牛頓下降法的一個迭代逼近

一切顯得十分完美,但是理想很豐滿,現實很骨感,收斂過程并不是一帆風順的
首先我們想象一下這個更新參數的變化趨勢
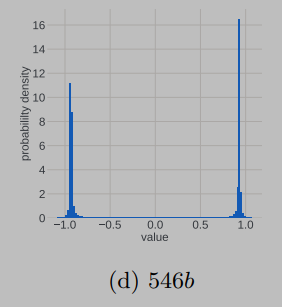
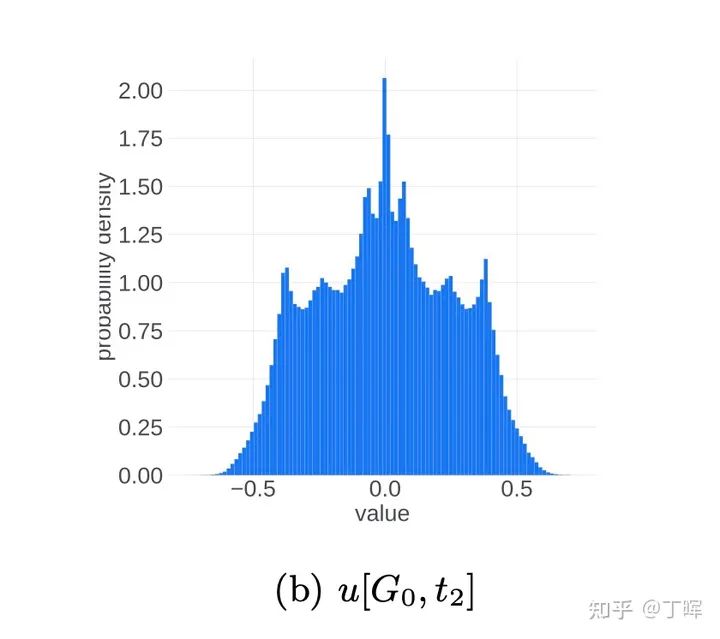
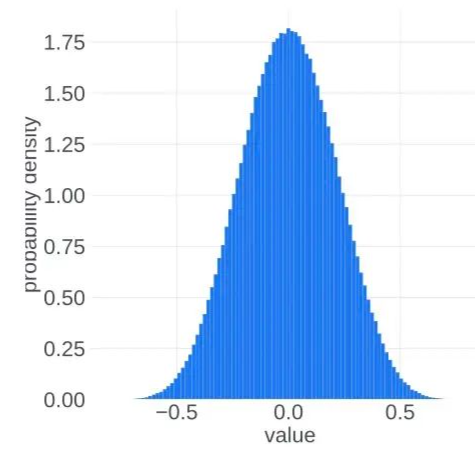
在 的時候, ,, 集中在 附近。而在訓練到最后,假設模型收斂到某個最優點,此時 應該集中在0附近。也就是說,我們似乎可以把更新參數的變化過程想象成為一個從兩端(非穩態)向中間(穩態)收攏的過程。實際的觀察現象也是如此:
非穩態
中間態
穩態
進入正態分布的穩態之后,理想的更新參數變化趨勢應該是方差越來越小,所有更新參數逐漸向0靠近。這應該是一個單向的過程,即穩定的單峰狀態(unimodal)不會再次進入非穩定的雙峰狀態(bimodal),但事實并非如此,更新參數會再次進入非穩定的雙峰狀態
本文在理論層面做了研究和解釋,從中心極限定理(可以結合道爾頓板實驗理解)出發,認為隨機事件的疊加進入單峰的正態分布的必要條件之一是各個隨機事件事件之間應該是相互獨立的,但是梯度變化以及更新參數的變化并不能特別好的滿足獨立性這一條件,而這一點恰恰是導致更新參數振蕩,loss spike出現以及loss 不收斂的重要原因之一

造成梯度變化不獨立的原因(1、淺層參數長時間不更新2、batch太大,后期梯度更新趨于平穩)上述的理論有些晦澀,本文作者可能也了解這一點,之后開始直接點題,結合實驗觀察拋出了重要現象和結論
即訓練過程中loss spike的出現與:梯度更新幅度, 大小,batch大小這三個條件密切相關
本文作者對loss spike出現時模型的前后變化做了仔細拆解,發現下列一系列連續現象的出現導致了loss spike:

當前模型處在穩態(健康狀態),即單峰的正態分布狀態,并且梯度值 ,此時loss平穩,訓練過程正常

2.模型淺層(embedding層)梯度 ,這一般是由于訓練一段時間之后,淺層的語義知識表示此時一般已經學習的較好。但此時深層網絡(對應復雜任務)的梯度更新還是相對較大

3.一段時間淺層(embedding層)梯度 之后會導致 , 。此時趨于0。因此導致淺層參數得不到更新(也對應于上述參數更新事件不獨立的原因)

4.此時雖然淺層(embedding層)參數長時間不更新,但是深層的參數依然一直在更新。長時間這樣的狀態之后,batch之間的樣本分布變化可能就會直接導致淺層(embedding層)再次出現較大的梯度變化(可以想象成一個水壩蓄水太久終于被沖開了。至于小模型為什么不會出現這種情況,推測是小模型函數空間小,無法捕獲樣本的分布變化,越大規模的模型對樣本之間不同維度的特征分布變化越敏感),此時 , 再次集中在 附近(此時 , ),變成雙峰的非穩定狀態,本文提到了淺層(embedding層)這種突然的參數變化可能造成模型的連鎖反應進而出現loss spike的現象(這也對應了更換樣本重新訓練有可能會減少loss spike的出現頻率,實際上就是選擇分布變化較小的樣本,減小淺層梯度變換幅度)

5.這個階段模型處于非穩態,梯度變化幅度較大,每一次的梯度變化和更新參數變化事件之間又出現了一定的獨立性,因此經過一定的時間之后模型有可能再次進入穩態,loss再次drop back down(注意,本文著重提了這個再次drop back down并不是一定出現的,也很有可能loss長期處于flat狀態,再也無法收斂)
因此我們得出一些結論,loss spike的出現和淺層的梯度更新幅度, 大小密切相關(batch大小帶來的相關性問題倒是顯得沒那么大說服力),實際上就是淺層網絡參數突然進入到了之前長時間不在的狀態與模型深層參數當前的狀態形成了連鎖反應造成了模型進入非穩態。同時一般情況即使出現loss spike也會自動回復到正常狀態,但也有可能再也不會
突刺解法
本文最后提到了防止loss spike出現的一些方法:
1.如之前提到的PaLM和GLM130B提到的出現loss spike后更換batch樣本的方法(常規方法,但是成本比較高)
2.減小learning rate,這是個治標不治本的辦法,對更新參數的非穩態沒有做改進
3.減小 大小。或者直接把 設為0,重新定義
在等于0時候的值(這應該是個值得嘗試的辦法)
值得一提的是智譜華章在本文發表之前,在去年的GLM130B訓練時似乎也觀察到了淺層梯度變化和loss spike相關這一現象(GLM-130B: An Open Bilingual Pre-trained Model),他采取的是把淺層梯度直接乘以縮放系數 來減小淺層梯度更新值

出自130b

其實這塊我有個自己的想法,和是否也可以做衰減,隨著訓練過程逐漸減小,來避免loss spike的現象
另外假設我們能一次性加載所有樣本進行訓練(實際上不可能做到),是否還會出現loss spike的現象
最后目前流行的fp8,fp16混合訓練,如果upscale設置的過小,導致梯度在進入優化器之前就下溢,是不是會增加淺層梯度長時間不更新的可能性,進而增加loss spike的出現的頻率。(這么看來似乎提升upscale大小以及優化 大小是進一步提升模型效果的一個思路)
審核編輯:黃飛
-
Palm
+關注
關注
0文章
22瀏覽量
11292 -
人工智能
+關注
關注
1796文章
47666瀏覽量
240281 -
大模型
+關注
關注
2文章
2545瀏覽量
3164
原文標題:大模型訓練loss突刺原因和解決辦法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電腦開機啟動時提示(顯示)NTLDR文件丟失解決辦法及原因分
音箱沒聲音的原因和解決辦法
板式給料機鏈條磨損過快原因分析和解決辦法
空氣開關跳閘常見原因、解決辦法和卸下步驟
PCBA加工焊點拉尖產生的原因及解決辦法
電感嘯叫的原因和解決辦法





 工商網監
工商網監
評論