 HTAP在快遞行業助力時效分析的落地實踐
HTAP在快遞行業助力時效分析的落地實踐
當前,網購已經成為千家萬戶主要的購物方式,隨著快遞體 量的飛速膨脹,分析時效成了擺在快遞公司面前的重要課題,有 沒有辦法既能降低成本又能提升時效呢?
整個快遞的生命周期可以用“收發到派簽”五個字概括。“收” 是指用戶下單,快遞小哥來收件,網點建包;“發”是指快遞在轉 運過程中發往運轉中心,發往目的地;“到”是指末端中心到件,分揀到網點;“派”是指派件網點分揀,快遞小哥開始派件;“簽” 是指快遞小哥派件以后,客戶簽收。
中通快遞有一套完善的自研的大數據平臺(見圖 2-3-1 ), ETL(Extract Transformation Load,抽取、轉換、裝載)數據建模 支持到半小時的級別。中通快遞大數據平臺支持多種數據源的接入,如關系數據庫 MySQL 、Oracle,文檔數據庫 MongoDB 以及 Elasticsearch(ES)。基本上,所有實時任務都是通過大數據平臺 來管理的,支持 Kafka、消息隊列(MQ)等的接入。不論是離線 ETL 還是 Spark/Flink 的實時任務,都通過大數據平臺接入整個大 數據的計算集群,最終進行計算。計算分析的結果再通過大數據 平臺提供給使用方:一是將數據推送到數據應用端,用于分析和報表;二是提供給 OLAP 的查詢引擎,供用戶或其他系統查詢。
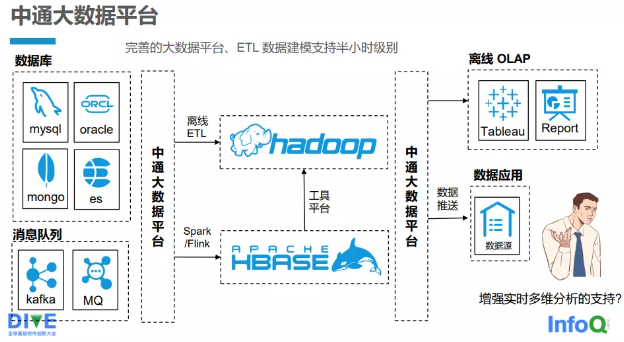
圖 2-3-1 中通快遞自研大數據平臺
2.3.1 1.0 時代:滿足業務和技術需求 1. 業務與技術需求分析
大數據平臺首先要滿足業務的需求。中通快遞的業務具有如下特點:
1)體量很大:業務發展很快,數據量很大,而且每筆訂單會 有 5~6 次更新,甚至更多次更新。
2)分析周期長:業務方要求的數據分析所覆蓋的周期越來越長。
3)時效要求高:對分析時效的要求也越來越高,已經不滿足于 T+1 離線計算,或者半小時級別的分析。
4)多維度:技術方案支撐多維的靈活分析。
5 )可用性要求高:要突破單機性能瓶頸、單點故障,縮短甚至消除故障恢復時間。
6)并發高:QPS(Queries Per Second,每秒查詢率)高,應用要求達到毫秒級的響應。
以技術為出發點,需要實現:
1)打通多個業務場景,設置多個業務指標。
2)實現強一致的分布式事務,實現原有業務模式切換代價小。
3)分析計算的工程化,以及離線存儲過程。
4)支持高并發寫、高并發更新。
5)支持二級索引與高并發查詢。
6 )支持在線維護,單點故障對業務無影響。
7 )支持熱點自動調度。
8)與現有技術生態緊密結合,做到分鐘級的統計分析。
9)支持 100 以上列的大寬表,支持多維度的查詢分析。
2. 重構時效系統
基于上述業務需求和技術需求,中通快遞引入了 TiDB,將多條業務線接到 TiDB 上,包括數據中臺、實時寬表、時效分析、 大促看板等。
中通快遞的時效系統是對原有時效系統的重構。原來的時效 系統整體架構(見圖 2-3-2)比較簡單,消費隊列通過消息程序把 所有數據寫入到數據庫,最終在數據庫上建立很多存儲過程,來 對數據進行統計分析,最終將統計分析的結果提供給應用程序用于查詢。
圖 2-3-3 是升級后的時效系統架構。
在原有的架構上,升級后的時效系統引入了 TiDB 和 TiSpark,消息接入 Spark/Flink,最終的數據寫入 TiDB。把原來 的存儲過程全部下線,替換成 TiSpark。數據會寫入兩端:輕量 級的匯總數據直接寫入 Hive(Hadloop 的一個數據倉庫工具),通過 OLAP 對外提供查詢服務;中途匯總的數據,直接寫入關系數據庫,如 MySQL。另外,每日使用 DataX 將 T+1 的數據從 TiDB 的數據庫同步到 Hive,以便在第二天做離線的 ETL(提取、轉換、加載)操作。
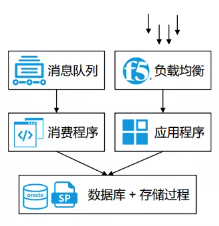
圖 2-3-2 中通快遞原來的時效系統整體架構
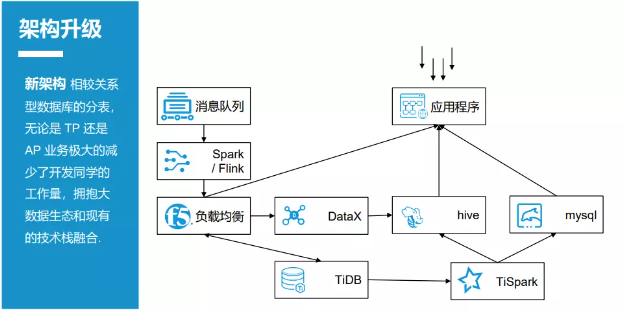
圖 2-3-3 升級后的時效系統架構
升級后的時效系統架構相較以前的關系數據庫的分表,無論是 TP 業務還是 AP 業務,都極大地減少了開發人員的工作量,并且把原來的消息接入切換成大數據的 Spark / Flink,擁抱了現有 的大數據生態,和現有的技術棧融合。
整個架構的升級帶來了很多收益。
1)已有系統的數據存儲周期從原來的 15 天增加到 45 天, 接下來會到 60 天,以后甚至會更長。在擴展性方面,升級后的架 構能支持在線的橫向擴展,隨時上下線存儲和計算節點,對此應 用基本上是無感知的。
2)在高并發方面,升級后的架構能滿足高性能的 OLTP 業務 需求,查詢性能略低于原系統,但是滿足需求。
3 )數據庫單點的壓力沒有了,實現了 TP 和 AP 的“分離”, 做到了資源隔離。
4)支持更多維度的業務分析,滿足了更多業務分析的需求。
整體架構清晰,可維護性增強,相比之前的存儲過程,升級 后整個架構體系非常清晰。
3. 大寬表建設
接下來給大家簡單地介紹中通快遞的大寬表建設情況,如 圖 2-3-4 所示。
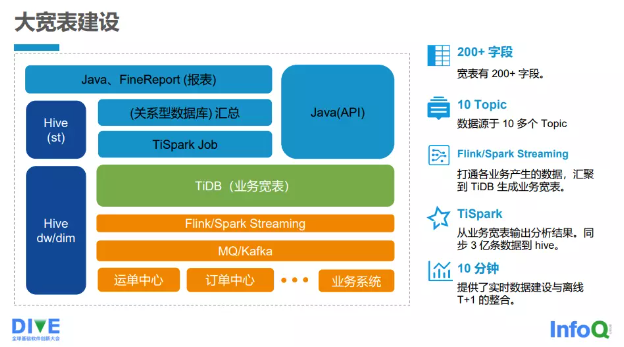
圖 2-3-4 大寬表建設情況
1)目前寬表有 200 多個字段,至今還在繼續增加。
2)接入了 10 多個主題(Topic)數據來源。
3)打通各業務產生的數據,并匯聚到 TiDB 生成業務寬表,借助流處理系統 Flink/Spark Streaming 把各個業務端的數據最終 寫入 TiDB 的寬表。
4)借助 TiSpark,從業務寬表輸出分析結果,同步 3 億余條數據到 Hive。
5)提供實時數據建設與離線數據 T+1 的整合,基本上可 在 10min 以內完成。
下邊是各個接入端,如運單中心、訂單中心等以及其他業務系統,接入端會把業務寫入 MQ/Kafka。Flink/Spark Streaming 會將 Kafka 里面的消息寫入 TiDB 的寬表 (TDB)。TiDB 的寬表上面是 TiSpark,它會通過 TiSpark 的批處 理最終將數據寫入 DW 或者 DIM 層,也會將一些匯總數據寫入 ST 層,而逐步匯總的數據會寫入關系數據庫。最終 Java 應用或者 FineReport 報表,會讀取關系數據庫的匯總數據以及 ST 層的數據。
另外,寬表也會對外提供大量 API 的服務,數據中臺、時效系統、數據看板系統等產品,都會調用寬表提供的數據服務。在使用的過程中,我們也遇到了很多問題,我總結為量變引起質變。
1 )熱點問題:在業務高峰時,索引熱點較為突出,很多業務是基于時間來查詢的,在連續的時間段寫入或更新會導致索引的 熱點。在大促的時候尤為明顯,這樣會導致部分 TiKV 的壓力非常大。
2)內存碎片化的問題:在系統運行穩定一段時間之后,大量的更新和刪除會導致內存碎片化。這個問題已經在后續的版本中修復,系統升級之后沒有發現異常。
3)正確使用參數的問題:當讀取的數據量達到總體數據量的 1/10 以上時,建議關閉 tispark.plan.allow_index_read 參數。因為在這種情況下,這個參數的收益會變成很小,甚至會帶來一些負收益。
4. 運維監控
TiDB 已經有很豐富的監控指標,它使用的是現在主流的 Prometheus + Grafana,監控指標非常多、非常全。TiDB 支持用戶的線上業務,同時也支持開發人員查詢數據,因此可能會遇到一些異常的操作,甚至遇到一些 SQL 影響 Server 運行,對生產產生影響。基于 TiDB 提供的監控功能,并針對使用過程中遇到 的一些問題,我們自建了自動監管和告警系統,監控線上特殊賬 號的慢查詢,自動“殺掉”異常 SQL,并通知運維和應用負責人。我們還開發了查詢平臺讓用戶使用 Spark SQL 去查詢 TiDB 的數 據,兼顧了并發和安全。對一些很核心的指標,我們額外接入了自研的監控,將核心的告警信息電話告知到相關的值班人員。
2.3.2 2.0 時代:HTAP 提升
業務方的需求不斷升級,他們不再滿足于數據存得越來越多,還希望系統跑得更快,不僅希望系統要滿足分析數據周期的增長,還希望更快地感知業務的變化。下游系統需要更多的訂閱信息,希望信息不滿足需求時,能主動調取。在開展大促活動時,TiKV 的壓力非常大,我們需要真正地實現計算和存儲分離。集群太大,不容易管理,問題排查很困難。所以,我們對架構再次進行升級,再次升級后的架構如圖 2-3-5 所示。
2.0 時代我們引入了 TiFlash 和 TiCDC,為什么引入 TiFlash?因為 TiFlash 是一個列存數據庫,當在 TiDB 上建一條同步鏈時,整個架構包括 TiDB 都不需要改動。數據寫入的整個架構是不變 的,仍然可以通過 Flink/Spark 寫入 TiDB 寬表。我們雖然引入了 TiFlash,但是依然保留了部分 TiSpark 任務。由于業務特性,由一些數據匯總得到的結果數據可能會達到了幾百萬或者上千萬的 級別,全部通過 TiFlash 寫入 TiDB,時效性跟不上。TiDB 對此 需求提供了后續的解決方案,數據計算會部分切換到 TiFlash 上, TiSpark 和 TiFlash 是共存的。TiSpark 或者 TiSpark 的匯總數據還是會寫到 Hive,也有一部分會寫到 MySQL,它們都會對外提供數據服務。我們通過引入 TiCDC 把 TiDB 的 Biglog 同步到消息隊列里,供下游的業務方使用,進行地域式消費。
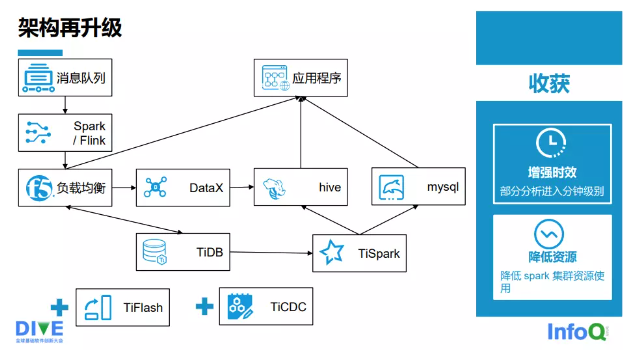
圖 2-3-5 再次升級后的架構
架構再升級的收獲共有兩點:
一 是增強時效,部分分析進入了分鐘級,運行間隔從 5~15min 降到了 1~2min。
二是降低了資源的使用,降低了 Spark 集群所需的資源量, 物理節點大概從 137 個降到了 77 個。
2.3.3 3.0 時代:展望未來
未來,仍然有很多問題等著我們處理,也有很多地方需要進 一步提升。
1)監控一直是我們比較頭疼的一個問題—我們的集群規模 比較大,指標很多,而且有的時候加載非常慢,排查問題的效率得不到保證。監控雖然很全,但是出了問題無法快速定位,這也 給我們線上排查問題帶來了一些困擾。
2 )執行計劃偶發不準,會影響集群的指標,導致業務相互 影響。這個情況可能與表的統計信息相關。過去數據清理還是比 較麻煩的,我們現在是通過自己寫腳本來支持舊數據的自動 TTL (Time to Live)功能。TiFlash 現在雖然已經支持很多函數知識下 推,但是我們希望可以更多地支持一些應用中遇到的函數。
3)提升集群穩定性。
4)實現 TiSpark 對 TiFlash Batch 的支持。
5)支持用戶、資源隔離,避免相互影響。
6)實現分區表支持、數據過濾,提高計算性能。
7)緩解計算抖動問題。
作者介紹
朱友志:中通快遞大數據架構師,負責中通大數據基礎架構工作。
審核編輯:劉清
-
ETL
+關注
關注
0文章
20瀏覽量
9421 -
MySQL
+關注
關注
1文章
829瀏覽量
26744 -
QPS
+關注
關注
0文章
24瀏覽量
8832 -
OLAP
+關注
關注
0文章
24瀏覽量
10126
原文標題:HTAP 在快遞行業助力時效分析的落地實踐
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
適合快遞驛站出庫儀一體機的安卓主板

龍智出席2024零跑智能汽車技術論壇,分享功能安全、需求管理、版本管理、代碼掃描等DevSecOps落地實踐

福田歐馬可智藍ES1快遞版有哪些亮點
海康威視助力快遞物流行業場景數字化升級
名單公布!【書籍評測活動NO.49】大模型啟示錄:一本AI應用百科全書

托寄物智能識別——大模型在京東快遞物流場景中的應用與落地

云天勵飛加速推動大模型行業落地
振弦采集儀的工程安全監測實踐與案例分析

海康威視助力快遞行業場景數字化
CET中電技術邀您參加第六屆綜合能源服務落地實踐峰會

嵌入式工業一體機在快遞柜設備上的應用

杭州掀起快遞物流創新浪潮,2024長三角快遞物流展7月共繪智慧物流新藍圖






 工商網監
工商網監
評論