") 以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載案例(五)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載案例(五)
本文節(jié)選自《DetectingTroubleshooting, and PreventingCongestion in Storage Networks 存儲網(wǎng)絡(luò)中擁塞處理》
Troubleshooting Congestion in Lossless Ethernet Networks
解決無損以太網(wǎng)網(wǎng)絡(luò)擁塞問題的方法與光纖通道結(jié)構(gòu)相同。兩者都使用逐跳流量控制機(jī)制,只是實(shí)現(xiàn)方式不同而已。當(dāng)交換端口顯示出口擁塞時,擁塞的根源在于下游流量路徑。當(dāng)交換端口顯示入口擁塞時,一定是因?yàn)樵?a href="http://www.zgszdi.cn/v/tag/1392/" target="_blank">交換機(jī)上的一個或多個端口在出口方向擁塞。
Goals
正如第4 章詳細(xì)介紹的那樣,故障排除的目標(biāo)有兩個:
1. 確定擁塞的來源(元兇)和原因:調(diào)查和故障排除的主要目標(biāo)是確定是否存在擁塞、擁塞源和擁塞原因,擁塞原因可能是慢耗盡(通過高TxWait(如果可用)或快速遞增的暫停計(jì)數(shù)檢測到)或過度利用(通過高出口利用率或微爆發(fā)事件檢測到)。一旦知道了擁塞的來源和原因,就可以對造成擁塞的終端設(shè)備進(jìn)行詳細(xì)調(diào)查。
2. 確定受影響的設(shè)備(受害者):次要目標(biāo)是識別受到罪魁禍?zhǔn)自O(shè)備不利影響的設(shè)備。這些就是受害者。在調(diào)查完成之前,您可能不知道設(shè)備是罪魁禍?zhǔn)走€是受害者。請記住,有時識別不同的受害者類型(直接受害者、間接受害者和同路徑受害者)會有所幫助。有關(guān)詳細(xì)信息,請參閱第4 章"識別受影響設(shè)備(受害者)"一節(jié)。
重要的是要明白,受害設(shè)備可能會將性能下降報(bào)告為罪魁禍?zhǔn)自O(shè)備。但問題只能通過調(diào)查罪魁禍?zhǔn)锥皇鞘芎φ邅斫鉀Q。
Congestion Severities and Levels
第4 章定義了光纖通道結(jié)構(gòu)的擁塞嚴(yán)重程度和級別。但它們不能直接用于無損以太網(wǎng)網(wǎng)絡(luò),因?yàn)榕c光纖通道不同,無損以太網(wǎng)沒有鏈路(信用)重置的概念,而鏈路(信用)重置是光纖通道中嚴(yán)重(3 級)擁塞的癥狀。另一個原因是,如果環(huán)境中的設(shè)備沒有檢測這些情況的度量標(biāo)準(zhǔn),將它們分為不同等級的實(shí)際意義就很有限。值得注意的例子是TxWait 和RxWait 指標(biāo),在撰寫本文時,大多數(shù)以太網(wǎng)端口都沒有這些指標(biāo)。因此,與光纖通道不同,使用TxWait 無法檢測到1 級擁塞。
總之,對于無損以太網(wǎng),不同嚴(yán)重程度的擁塞癥狀可略作如下調(diào)整:
1. 輕度擁塞(1 級):延遲增加,但不丟幀。
a. 檢測暫停幀數(shù)或TxWait/RxWait (如果有)是否過多以及鏈路利用率是否過高。
2. 中度擁塞(2 級):延遲和丟幀增加。
a. 檢測無損級中的丟包情況
3. 嚴(yán)重?fù)砣? 級):延遲增加、丟幀和流量持續(xù)停頓。
a. 使用暫停超時或PFC 看門狗進(jìn)行檢測,稍后解釋
Methodology
我們建議按嚴(yán)重程度遞減的方式排除擁塞故障。請注意,這些擁塞嚴(yán)重程度并不是標(biāo)準(zhǔn)化的。它們的唯一目的是幫助用戶制定實(shí)用的工作流程,從而有助于快速準(zhǔn)確地檢測和排除擁塞故障。您可以根據(jù)自己的環(huán)境進(jìn)行定制。例如,如果沒有檢測3 級擁塞的簡便方法,可先調(diào)查2 級擁塞(數(shù)據(jù)包丟棄),然后再調(diào)查1 級擁塞(暫停幀計(jì)數(shù)或TxWait(如果有))。
有關(guān)詳細(xì)信息,請參閱第4 章"故障排除方法- 降低電平"部分。在將第4 章中的信息應(yīng)用于無損以太網(wǎng)時,請記住Rx 信用不可用與光纖通道中的入口擁塞相同,后者在以太網(wǎng)網(wǎng)絡(luò)中由Tx Pause 檢測到。同樣,Tx 信用不可用等同于光纖通道中的出口擁塞,而以太網(wǎng)網(wǎng)絡(luò)中的Rx 暫停可檢測到出口擁塞。
建議同時學(xué)習(xí)第4 章的案例研究。雖然這些案例是針對光纖通道描述的,但從中可以了解到無損以太網(wǎng)網(wǎng)絡(luò)的故障排除方法是如何類似的。
Troubleshooting Congestion in Spine-Leaf Topology
請參閱圖7-14,它是圖7-8 脊葉網(wǎng)絡(luò)網(wǎng)絡(luò)的一個子集。正如前面"無損脊葉網(wǎng)絡(luò)中的擁塞"一節(jié)所解釋的,一個罪魁禍?zhǔn)卓赡軙乖S多設(shè)備受害,而這些受害設(shè)備的用戶也可能會報(bào)告性能下降。因此,自然要從最先報(bào)告問題的地方開始排除故障,即受害設(shè)備或其連接的交換端口。無論從哪里開始,重要的是要追蹤擁塞的源頭,同時尋找嚴(yán)重性較高的事件,然后是嚴(yán)重性較低的事件(3 級2 級1 級)。
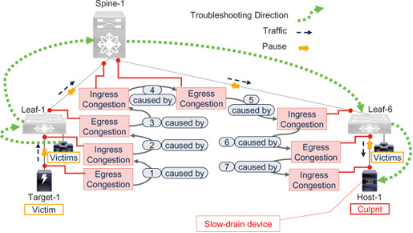
Figure 7-14Congestion troubleshooting direction in a lossless spine-leaf network
假設(shè)連接到Leaf-1 的受害主機(jī)上的應(yīng)用程序報(bào)告性能下降。這些是間接受害者,因?yàn)樗鼈兘邮諄碜阅繕?biāo)-1 的流量,而目標(biāo)-1 是罪魁禍?zhǔn)字鳈C(jī)-1 的直接受害者。但在故障排除結(jié)束之前,這一點(diǎn)還不得而知。故障排除工作流程如下:
1. 轉(zhuǎn)到受害主機(jī)直接連接的交換端口。如果發(fā)現(xiàn)出口擁塞癥狀(Rx 暫停或出口丟包),那么這臺主機(jī)就是罪魁禍?zhǔn)住?/p>
2. 如果沒有,請?jiān)谕唤粨Q機(jī)的任何其他邊緣端口上查找入口擁塞癥狀(Tx 暫停)。如果發(fā)現(xiàn)這樣的設(shè)備(Target-1),它一定在向罪魁禍?zhǔn)祝℉ost-1)發(fā)送流量(如果只有一個擁塞事件或罪魁禍?zhǔn)祝?/p>
3. 然后,在Leaf-1 的上游端口上查找出口擁塞癥狀。
4. 轉(zhuǎn)到其中一個上游設(shè)備(例如Spine-1)。Spine-1 發(fā)送的Tx 暫停應(yīng)與Leaf-1 上游端口上的Rx 暫停一致。如果它們的值不一致,請調(diào)查位錯誤或固件錯誤。
5. 在Spine-1,查找有出口擁塞癥狀(Rx 暫停)的端口。這些端口通常會傳輸從顯示入口擁塞的端口接收到的流量。
6. 轉(zhuǎn)到流量路徑中的下一個設(shè)備(Leaf-6)。Leaf-6 發(fā)送的Tx 暫停應(yīng)與Spine-1 上的Rx 暫停一致。如前所述,如果它們的值不同,則應(yīng)調(diào)查位錯誤或固件錯誤。
7. 在Leaf-6 上,查找有出口擁塞癥狀(Rx 暫停或出口丟包)的邊緣端口。這應(yīng)該是連接到罪魁禍?zhǔn)字鳈C(jī)(Host-1)的交換端口。如果未發(fā)現(xiàn)Rx 暫停或出口丟包,則調(diào)查端口是否過度使用。
在任何設(shè)備上,如果有更多端口出現(xiàn)出口擁塞癥狀,應(yīng)先處理較嚴(yán)重的癥狀。例如,先處理丟包后處理Rx 暫停。同樣,如果TxWait 不可用,應(yīng)先處理快速增加的暫停計(jì)數(shù),再處理緩慢增加的暫停計(jì)數(shù)。
Reality Check
圖7-14 所示的故障排除工作流程需要進(jìn)行實(shí)際檢查,原因如下。
1.此故障排除工作流程只能在擁塞狀況持續(xù)期間使用,因?yàn)榕cCisco MDS 交換機(jī)和Nexus 7000/7700 交換機(jī)不同,大多數(shù)以太網(wǎng)交換機(jī)(包括Cisco Nexus 9000 交換機(jī))不保留帶有時間和日期戳的擁塞事件歷史記錄。
2. 由于大多數(shù)以太網(wǎng)交換機(jī)不報(bào)告TxWait 和RxWait 的百分比,因此即使實(shí)時排除故障也很繁瑣。在Cisco Nexus 9000 交換機(jī)和Cisco UCS 服務(wù)器上,命令輸出中只有累計(jì)暫停計(jì)數(shù)。用戶必須多次執(zhí)行這些命令并手動計(jì)算差值,如例7-7 所示。為數(shù)百個端口執(zhí)行這些步驟既困難又耗時,而且容易出錯。試想一下,在圖7-8 中可能有數(shù)百個端口的脊柱交換機(jī)上手動計(jì)算這一結(jié)果。
3. 正如前面有關(guān)暫停幀數(shù)的章節(jié)所述,暫停幀數(shù)的名義增長并不一定表示擁塞。
4. 請注意,造成擁塞的原因可能不止一個。如果造成擁塞的原因在不同的交換機(jī)上,那么可能會有不止一條路徑。
5. 最后,在手動解釋暫停幀數(shù)時,如果擁塞條件停止,由于事件沒有時間和日期標(biāo)記,因此無法知道其計(jì)數(shù)何時增加。
由于這些原因,使用命令行界面很難排除無損以太網(wǎng)網(wǎng)絡(luò)擁塞的故障。
Troubleshooting Congestion using a Remote Monitoring Platform
通過使用遠(yuǎn)程監(jiān)控平臺,可以改變在無損以太網(wǎng)網(wǎng)絡(luò)中排除擁塞故障時令人不快的現(xiàn)實(shí),該平臺可持續(xù)輪詢暫停幀的數(shù)量,以保存帶有時間和日期戳的歷史記錄。
UCS 流量監(jiān)控(UTM) 應(yīng)用程序就是此類應(yīng)用程序的一個示例。有關(guān)詳細(xì)信息,請參閱第9 章。UTM 應(yīng)用程序可以使用比較分析、踩點(diǎn)和季節(jié)性等方法近乎實(shí)時地檢測擁堵情況并排除故障。
Comparative Analysis
比較網(wǎng)絡(luò)端口(主機(jī)端口和交換機(jī)端口)的暫停幀速率,檢測是否有幾個端口的暫停幀數(shù)比其他端口高得多。
在圖7-8 中,有數(shù)千臺主機(jī)、
1. 每60 秒從邊緣交換端口或主機(jī)輪詢一次Tx 和Rx 暫停。
2. 計(jì)算累計(jì)暫停幀數(shù)的delta 值,了解60 秒內(nèi)的變化情況。
3. 按"Tx 暫停"降序排列主機(jī),或按"Rx 暫停"降序排列邊緣交換端口。
4. 調(diào)查該列表中排名前10 位的主機(jī)。通常情況下,這些主機(jī)的慢排空嚴(yán)重程度較高。
應(yīng)在所有類似實(shí)體中使用相同的比較分析。例如,將所有骨干端口相互比較,檢測是否有幾個端口報(bào)告了過多的暫停幀。
Trends and Seasonality
暫停幀對無損以太網(wǎng)網(wǎng)絡(luò)的運(yùn)行非常重要,因此其正常活動是沒有問題的。但要仔細(xì)分析任何峰值和谷值。此外,還要查找暫停幀計(jì)數(shù)在過去幾天或幾周內(nèi)是否一直在上升,盡管可能不會出現(xiàn)任何突然的峰值。此外,還要查找是否存在季節(jié)性,即暫停幀數(shù)的峰值是否出現(xiàn)在一天中的特定時段或一周中的特定日子,甚至一年中的特定月份。
從圖表上看,低計(jì)數(shù)的直線就可以了。注意峰值,尤其是持續(xù)時間較長的大峰值。
Monitoring a Slow-drain Suspect
可疑設(shè)備是發(fā)送暫停幀的終端設(shè)備。但它不一定是罪魁禍?zhǔn)住?梢钥隙ǖ氖牵覀冃枰嗟男畔ⅲ驗(yàn)槿缜八觯瑑H僅計(jì)算暫停幀的數(shù)量并不能說明傳輸?shù)降淄V沽硕嚅L時間。
根據(jù)我們的經(jīng)驗(yàn),以下幾種方法有助于判斷嫌疑人是否也是罪魁禍?zhǔn)住?/p>
1. 不發(fā)送暫停幀的終端設(shè)備不是慢排空的來源。可以將這些設(shè)備排除在可疑設(shè)備列表之外,從而只關(guān)注那些發(fā)送暫停幀的設(shè)備。
2. 終端設(shè)備每秒最多只有幾百個暫停幀(如少于300 個)并不會使其成為可疑設(shè)備。但是,當(dāng)暫停幀速率增加到每秒數(shù)百或數(shù)千的大倍數(shù)時,終端設(shè)備就會成為可疑設(shè)備。每秒數(shù)百萬個暫停幀無疑會使終端設(shè)備非常接近于罪魁禍?zhǔn)祝虼藨?yīng)積極監(jiān)控。
3. 檢查上游端口的擁塞擴(kuò)散癥狀。例如,在脊葉拓?fù)浣Y(jié)構(gòu)中,主機(jī)暫停幀速率的峰值是否與位于主機(jī)流量路徑上的骨干交換機(jī)端口的暫停幀速率峰值一致?如果是,則表明擁塞正在蔓延,因此主機(jī)是罪魁禍?zhǔn)住H绻皇牵瑒t表明主機(jī)只是瞬間暫停了流量,因此不會成為罪魁禍?zhǔn)住?/p>
4. 比較終端設(shè)備在兩個(或多個)端口上發(fā)送暫停幀的速率。通常情況下,它們的速率應(yīng)該是一致的。但如果一個端口每秒發(fā)送數(shù)百個暫停幀,而另一個端口每秒發(fā)送數(shù)百萬個暫停幀,或出現(xiàn)類似的非均勻暫停幀速率,則需要進(jìn)行調(diào)查。
5. 高暫停幀速率或暫停幀速率的增加必須與終端設(shè)備上層的事件相關(guān)聯(lián)。例如,終端設(shè)備上的I/O 錯誤、應(yīng)用性能下降、I/O 完成時間增加和IOPS 減少。這種關(guān)聯(lián)必須在網(wǎng)絡(luò)中的可疑終端設(shè)備(發(fā)送暫停幀)和其他終端設(shè)備(不發(fā)送暫停幀)上進(jìn)行。這是因?yàn)椋绻梢稍O(shè)備真的是罪魁禍?zhǔn)祝敲从善湓斐傻膿砣蜁U(kuò)散,使許多其他終端設(shè)備受害。
6.網(wǎng)絡(luò)端口的過多Tx 暫停幀應(yīng)導(dǎo)致該鏈路的Rx 流量降低。如果結(jié)果與此不同,則可能表明暫停幀沒有到達(dá)流量發(fā)送方,或者沒有被正確處理,或者是在沒有TxWait/RxWait 的情況下,僅使用暫停幀數(shù)量檢測擁塞的局限性,這在前面有關(guān)PFC 風(fēng)暴的章節(jié)中已有解釋。需要記住的要點(diǎn)是比較暫停幀和相反方向的流量。
Monitoring an Over-utilization Suspect
正如第1 章"定義完全使用率vs 高使用率vs 過度使用率"和"監(jiān)控完全使用率vs 高使用率vs 過度使用率"兩節(jié)所述,我們建議將任何高使用率(如超過80%)情況與過度使用率同等對待。這是因?yàn)椋鶕?jù)我們的經(jīng)驗(yàn),大多數(shù)高使用率情況也有一定的過度使用時間。要確定高使用率是否導(dǎo)致?lián)砣杀O(jiān)控上游端口的暫停幀。但在開始調(diào)查時,除非另有證明,否則應(yīng)將高使用率情況與過度使用情況同等對待。這種方法節(jié)省了檢測擁塞和尋找解決方案的時間。
FC and FCoE in the Same Network
有些交換機(jī),如Cisco Nexus 9000 交換機(jī)、Nexus 5000/6000 交換機(jī)和Cisco UCS Fabric Interconnect 可以有FC、FCoE(無損)和以太網(wǎng)(有損)端口。這些交換機(jī)以類似于前面解釋的方式將擁塞從流量控制出口端口擴(kuò)散到流量控制入口端口。唯一不同的是流量控制機(jī)制,因此檢測擁塞的指標(biāo)也不同。
請注意,F(xiàn)C 端口使用Rx B2B 信用不可用檢測入口擁塞,使用Tx B2B 信用不可用檢測出口擁塞。有關(guān)光纖通道指標(biāo)的詳細(xì)解釋,請參閱第3 章。
FCoE 端口(無損以太網(wǎng))使用"Tx 暫停"檢測入口擁塞,使用"Rx 暫停"檢測出口擁塞。前面關(guān)于擁塞檢測指標(biāo)的章節(jié)解釋了這些指標(biāo)。
ConsiderFigure 7-15with the following components.
有損以太網(wǎng):沒有逐跳流量控制(如PFC 或LLFC)的骨干網(wǎng)絡(luò)。這部分網(wǎng)絡(luò)的流量依靠其他機(jī)制(如OSI 模型第4 層的TCP)進(jìn)行擁塞控制。
無損光纖通道:具有B2B 流量控制功能的邊緣核心光纖通道Fabric。MDS-1 連接存儲陣列(Target-1 和Target-2)。
融合(有損+無損)以太網(wǎng):有損以太網(wǎng)網(wǎng)絡(luò)和光纖通道結(jié)構(gòu)共享葉子交換機(jī)(L-4 和L-6)。它們有專用的以太網(wǎng)上行鏈路(無流量控制)連接到骨干交換機(jī),光纖通道上行鏈路連接到MDS-1。下行鏈路連接到一個或多個FEX(FEX-4 和FEX-6),最終連接到主機(jī)。葉子到FEX 鏈路和FEX 到主機(jī)鏈路使用PFC。無損FC/FCoE 流量保持在無丟包類別中,而有損以太網(wǎng)流量保持在不受流控制的其他類別中。
FEX 代表思科Fabric Extender。從外形上看,它像一個交換機(jī),但實(shí)際上像一個遠(yuǎn)程模塊。它需要一個父交換機(jī)來實(shí)現(xiàn)控制功能(如路由協(xié)議)和管理功能(如配置端口)。父交換機(jī)和FEX 之間的鏈接使用SFP 和電纜,并運(yùn)行逐跳流量控制(如PFC)。這與ISL 類似。因此,在處理擁塞時,可將FEX 視為交換機(jī),盡管從一般意義上講,F(xiàn)EX 本身可能并不符合交換機(jī)的條件。
圖7-15 是思科UCS 架構(gòu)的近似表示。葉子交換機(jī)代表Fabric Interconnects,F(xiàn)EX 代表I/O 模塊(IOM),主機(jī)代表服務(wù)器。有關(guān)Cisco UCS 服務(wù)器的詳細(xì)信息,請參閱第9 章。
讓我們分析Host-1 和Host-2 造成的擁塞事件,并遵循故障排除方法。
Congestion Spreading due to Slow-Drain
在圖7-15 中,Host-1 是一個慢速排空設(shè)備,因?yàn)樗臒o損流量處理速率低于向其傳送幀的速率。因此,它會向FEX-4 發(fā)送PFC 暫停幀,以降低無損類別的流量速率。無損類之外的流量不受流量控制,因此在隊(duì)列滿時可能會被丟棄。
當(dāng)超過FEX-4 的暫停閾值時,它會向L-4 發(fā)送PFC 暫停幀,以降低不丟棄類的流量速率。但L-4 的上行鏈路(入口端口)運(yùn)行光纖通道。當(dāng)其緩沖區(qū)耗盡時,它會降低向上游鄰居(MDS-1)發(fā)送R_RDY 的速率。最后,MDS-1 降低向目標(biāo)發(fā)送R_RDY 的速率,以減少來自目標(biāo)的流量。
Congestion Spreading due to Over-Utilization
請看圖7-15 中的主機(jī)-2。它沒有造成慢排空,但在其交換端口的出口方向上造成了100% 的使用率,這可能會因過度使用而導(dǎo)致?lián)砣S们懊娼忉屵^的類似方法從MDS-1 追逐擁塞源時,在到達(dá)FEX-6 后,可能找不到任何有Rx 暫停增量的出口端口。在這種情況下,請查找正在以高出口利用率運(yùn)行的端口,這是過度利用導(dǎo)致?lián)砣嫩E象。這樣就能找到罪魁禍?zhǔn)譎ost-2。
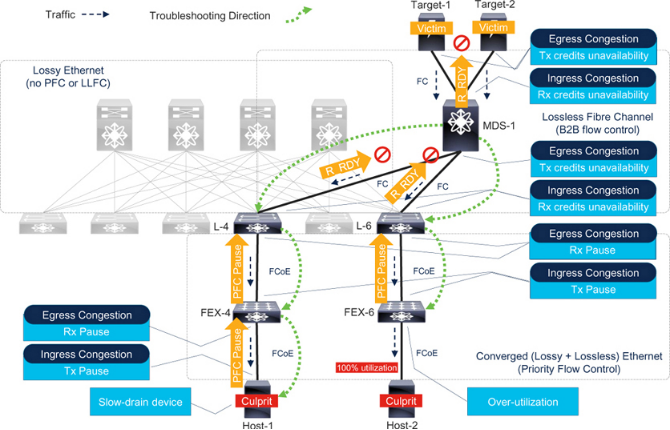
Figure 7-15Congestion troubleshooting workflow with FC and FCoE in the same network
請注意以下幾點(diǎn):
1. FC 和FCoE 混合網(wǎng)絡(luò)中擁塞的蔓延情況與僅有FC 或僅有FCoE 的網(wǎng)絡(luò)類似。
2. 在FEX-4 和FEX-6 的上行鏈路上,排空緩慢和過度使用也會導(dǎo)致類似的癥狀。即使在L-4、L-6 和MDS-1 上也無法找到擁塞原因。只有FEX-4 和FEX-6 上的邊緣鏈路能明確區(qū)分擁塞原因,因?yàn)樗鼈冎苯舆B接到擁塞源(罪魁禍?zhǔn)捉K端設(shè)備)。
3.無損以太網(wǎng)鏈路(L-4 和L-6 下行鏈路)和光纖通道鏈路(L-4 和L-6 上行鏈路)的擁塞故障排除方法與前面解釋的相同。不同之處在于,L-4 和L-6 交換機(jī)本身需要追尋擁塞源。在這些交換機(jī)上,入口(FC)端口使用光纖通道指標(biāo),出口(以太網(wǎng))端口使用PFC 指標(biāo)。它們的命令不同。執(zhí)行這兩種命令,檢查交換機(jī)上FC 和FCoE 流量的出口擁塞情況。
4. 在圖7-15 中,如果L-4 不在上行FC 端口(例如Cisco UCS Fabric Interconnects)上提供入口擁塞檢測指標(biāo),則可以使用MDS-1 上的出口擁塞檢測指標(biāo)。同樣,如果Host-1 不監(jiān)控Tx 暫停幀(或監(jiān)控起來不夠方便),則可選擇監(jiān)控FEX-4 上的Rx 暫停。
Bit Rate Differences between FC and FCoE
交換機(jī)在FC 和FCoE 端口之間傳輸流量時,必須仔細(xì)考慮比特率的差異。如第2 章"光纖通道比特率"、"光纖通道速度與比特率之間的差異"和表2-4 所述,某些光纖通道比特率與宣傳的速度有很大差異。例如,8GFC 端口的比特率為8.5 Gbps,但考慮到8b/10b 編碼,只能以6.8 Gbps 的速度傳輸數(shù)據(jù)。這使得10 GbE 的"速度"幾乎比8GFC 快50%。因此,當(dāng)FCoE 流量從10 Gbps 以太網(wǎng)端口切換到8GFC 端口時,可能會出現(xiàn)速度不匹配導(dǎo)致的擁塞。當(dāng)流量從16GFC 端口(比特率為14.025 Gbps)切換到工作速率為10 Gbps 的FCoE 端口時,會出現(xiàn)另一種常見的擁塞情況。正如本章所述,速度或容量不匹配程度越高,擁塞就越容易發(fā)生和蔓延。
雖然無法完全消除以太網(wǎng)和光纖通道在比特率上的差異,但必須盡可能地縮小它們之間的差距,例如32GFC 和25 GbE。除了端口速度外,還應(yīng)考慮共享FCoE 鏈路的最低帶寬保證,因?yàn)镕C/FCoE 流量可能不允許占用鏈路的全部容量。
對于帶有FC 和FCoE 端口的交換機(jī),如Cisco UCS Fabric Interconnect(參見第9 章),這應(yīng)該是一個設(shè)計(jì)層面的決策。初步設(shè)計(jì)完成后,應(yīng)持續(xù)監(jiān)控流量模式,并根據(jù)需要增加額外容量。
Multiple no-drop Classes on the Same Link
當(dāng)無損以太網(wǎng)網(wǎng)絡(luò)中啟用了多個無損類時,請按照每次一個類(CoS)的擁塞故障排除方法進(jìn)行操作。
圖7-15 中的融合拓?fù)渲粸镕CoE 流量設(shè)置了一個無損類。在同一拓?fù)渲校蔀镽oCEv2 流量啟用另一個無損類。
請參閱圖7-16。存儲陣列連接到葉子交換機(jī)(L-1),并為RoCEv2 進(jìn)行了配置。主機(jī)-1 和主機(jī)-2 通過FEX-4 連接到葉子L-4。這些主機(jī)以分配給CoS 5 流量的無損類訪問RoCEv2 存儲。脊葉拓?fù)洮F(xiàn)在可為CoS 5 流量提供PFC。RoCEv2 流量使用IP 標(biāo)頭中的DSCP 字段進(jìn)行分類,從而實(shí)現(xiàn)前面所述的第3 層PFC。不過,為簡單起見,本節(jié)假定RoCEv2 是表7-1 中CoS 到DSCP 映射的CoS 5 流量。
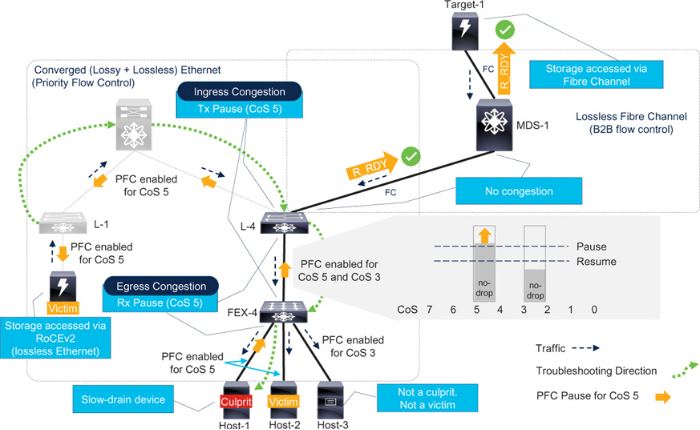
Figure 7-16Congestion troubleshooting with multiple no-drop classes
FCoE 主機(jī)(Host-3)連接到FEX-4,并將FCoE 流量分配到CoS 3。FEX-4 和L-4 將CoS 3 流量分配到專用的無損類。在L-4 上,CoS 3 流量通過光纖通道上行鏈路發(fā)送。
總之,在此拓?fù)渲校琇-4 和FEX-4 之間的鏈路為兩個無損類配置了PFC,分別分配給CoS 5 和CoS 3。因此,交換端口創(chuàng)建了兩個獨(dú)立的無損隊(duì)列,分別有自己的暫停閾值和恢復(fù)閾值。
當(dāng)Host-1(RoCEv2 主機(jī))成為慢排空設(shè)備時,它會發(fā)送CoS 5 的PFC 暫停幀。當(dāng)FEX-4 的暫停閾值超過CoS 5 隊(duì)列時,它只向L-4 發(fā)送CoS 5 的PFC 暫停幀。結(jié)果,Host-2(另一臺使用CoS 5 的RoCEv2 主機(jī))因L-4 和FEX-4 之間的共享鏈路擁塞而受害。
L-4 不會接收CoS 3 的PFC 暫停幀,因此不會減慢CoS 3 流量。因此,F(xiàn)CoE 主機(jī)(Host-3)不會受到影響。
在L-4 上,擁塞只擴(kuò)散到CoS 5 上行鏈路(骨干交換機(jī)),而不擴(kuò)散到光纖通道上行鏈路。
總之,啟用多個不丟包類別時,應(yīng)分別注意每個類別的擁塞癥狀。分析L-4 上每個端口的暫停計(jì)數(shù)器可能會導(dǎo)致錯誤的方向。只在CoS 5 中排除故障可以找到擁塞源(Host-1)。
Bandwidth Allocation Between Lossless and Lossy Traffic
回想一下,增強(qiáng)傳輸選擇(ETS,除PFC 外)是使融合(有損+無損)以太網(wǎng)取得成功的重要功能,因?yàn)樗鼮闊o損類提供帶寬保證,同時與其他類別的流量共享鏈路。
請注意以下有關(guān)使用ETS 分配帶寬的要點(diǎn):
1. 每個無損類別都預(yù)留了最少數(shù)量的緩沖區(qū)。
2. 無損類別會被分配一個最小帶寬,例如鏈路容量的50%。但這并不是"無損"類所能達(dá)到的最大帶寬。當(dāng)其他類沒有流量時,流量類最多可占用100% 的鏈路容量。
3. 但是,當(dāng)其他類別有流量時,無損類別的帶寬分配就會受到限制(假設(shè)為50%)。這可能會因過度使用而造成擁塞。
4. 端口在無損等級中的傳輸容量為50%,在其他等級中的傳輸容量為50%。
5.當(dāng)端口已按各流量等級的帶寬分配滿負(fù)荷傳輸時,例如無損等級的流量為50%,其他等級的流量為50%、
a. 如果交換機(jī)上的其他端口接收到的有損類流量超過了該端口的發(fā)送量,多余的流量就會像有損網(wǎng)絡(luò)一樣被丟棄。
b. 如果交換機(jī)上的其他端口接收到更多要從該端口發(fā)送出去的無損類流量,則接收到多余流量的端口會在暫停閾值處發(fā)送一個暫停幀。每個入口端口都維護(hù)有自己的暫停閾值、恢復(fù)閾值和凈空的無損隊(duì)列。這種情況就像過度使用造成的擁塞,并導(dǎo)致?lián)砣麛U(kuò)散。
Effect of Lossy Traffic on no-drop Class
一個常見的誤解是,有損類中的流量不會影響無損類。這取決于處理問題的方式。
無損類的流量可以消耗100% 的容量。但是,當(dāng)其他類有流量時,它就會被限制在保證帶寬內(nèi)。換句話說,以前不會造成擁塞的鏈路,在其他(有損耗)類別的流量增加后,可能會開始造成擁塞(由于過度使用)。例如,考慮一條10 GbE 鏈路,其中5 Gbps 分配給無損類,5 Gbps 分配給其他類。如果不存在其他流量,無損類中的無損流量可以消耗掉鏈路的全部容量。但是,如果其他流量需要2 Gbps,無損流量將被限制在8 Gbps。這臺交換機(jī)現(xiàn)在必須將其他端口的入口速率均衡為8 Gbps,而之前的速率為10 Gbps。為實(shí)現(xiàn)速率均衡,交換機(jī)會調(diào)用PFC,導(dǎo)致?lián)砣麛U(kuò)散。
如果只監(jiān)控I/O 吞吐量,這種情況就不容易理解了。早期,10 Gbps 的I/O 吞吐量不會造成擁塞。后來,僅8 Gbps 就會造成擁塞。
由于這些原因,在融合存儲網(wǎng)絡(luò)甚至共享存儲網(wǎng)絡(luò)中確定過度使用情況要比專用存儲網(wǎng)絡(luò)困難得多。再也不能通過出口百分比利用率來確定過度利用。在鏈路級別上分別監(jiān)控每類流量和每類擁塞情況,以及將兩者結(jié)合起來,有助于更好地理解和檢測此類問題。
Case Study 1 — An Online Gaming Company
一家在線游戲公司將融合以太網(wǎng)網(wǎng)絡(luò)用于無損存儲I/O 流量和有損TCP/IP 流量。他們的服務(wù)器以10 GbE 連接網(wǎng)絡(luò),50% 的帶寬分配給無損類。他們的鏈路利用率很少超過90%。
他們報(bào)告了以下觀察結(jié)果:
許多應(yīng)用程序都報(bào)告了性能下降。
問題只在工作時間出現(xiàn)。
在同一時間段內(nèi),他們發(fā)現(xiàn)了一臺CPU 高的服務(wù)器,但這臺服務(wù)器的鏈接利用率從未超過70%。在這臺服務(wù)器上運(yùn)行的應(yīng)用程序的所有者懷疑存在存儲訪問問題。
CPU 高并不是有力的證據(jù),但應(yīng)用程序所有者懷疑是存儲問題。他們沒有在主機(jī)上看到任何I/O 錯誤。為了驗(yàn)證網(wǎng)絡(luò)擁塞情況,他們檢查了該服務(wù)器鏈接上的暫停幀計(jì)數(shù)。他們發(fā)現(xiàn),在問題持續(xù)期間,服務(wù)器發(fā)送了很多暫停幀。此外,連接該服務(wù)器的交換機(jī)也在其上行鏈路上進(jìn)一步發(fā)送暫停幀。這是擁塞的擴(kuò)散,可能會使許多其他服務(wù)器受害。
接下來,他們想找到在鏈路利用率保持在70% 以下的情況下,該服務(wù)器出現(xiàn)高Tx Pause 的原因。他們開始監(jiān)控每個類的流量利用率,并在問題持續(xù)期間發(fā)現(xiàn)了以下情況:
1. 服務(wù)器入口鏈路利用率從5 Gbps 提高到7 Gbps。
2.每級流量監(jiān)測顯示
a. 無損類的流量從2 Gbps 降至1.5 Gbps。
b. 其他(有損)類別的流量從3 Gbps 增加到5.5 Gbps。
根據(jù)這些觀察結(jié)果,我們懷疑其他(有損)流量的增加可能會導(dǎo)致CPU 使用率過高,從而沒有足夠的資源來處理存儲I/O。因此,服務(wù)器試圖減慢入口I/O 流量,這一點(diǎn)從暫停幀的數(shù)量和整個I/O 的減少可以看出。
為了驗(yàn)證這一理論,他們將該應(yīng)用程序移到了一臺CPU 數(shù)量更多的強(qiáng)大服務(wù)器上。這一改變之后,應(yīng)用程序不再遇到性能問題。有損類流量保持在3 Gbps 至5.5 Gbps 之間。無損類的平均流量為2 Gbps。暫停幀數(shù)保持在最低水平,沒有出現(xiàn)任何峰值或驟降。服務(wù)器的CPU 使用率也不高。
除了說明監(jiān)控每個端口和每個類流量利用率的重要性外,本案例研究還展示了全棧可觀測性如何幫助更快、更準(zhǔn)確地檢測擁塞問題。但全棧可觀察性并不是本案例研究的目的。真正的教訓(xùn)是,當(dāng)有損類的流量增加時,可能也會導(dǎo)致無損類的擁塞。在本案例中,真正的問題出在網(wǎng)絡(luò)之外,也就是服務(wù)器的CPU 容量,但其影響卻體現(xiàn)在網(wǎng)絡(luò)上,使許多其他服務(wù)器也深受其害。
不能一概而論地認(rèn)為CPU 高會導(dǎo)致I/O 性能問題。只有在本案例研究中,CPU 高才會導(dǎo)致問題。影響I/O 性能的原因還有很多。本案例研究的關(guān)鍵是了解有損耗類流量對無丟包類的影響。
Case Study 2 — Converged Versus Dedicated Storage Network
本案例研究與案例研究1 相似。不同之處在于服務(wù)器的CPU 利用率不再很高。此外,無損類的平均流量為6 Gbps(60%),有損類的平均流量為2 Gbps(20%)。當(dāng)報(bào)告應(yīng)用性能下降時,持續(xù)時間也與會聚鏈路的100% 利用率相吻合。對每類流量利用率進(jìn)行調(diào)查后發(fā)現(xiàn),有損類的流量從2 Gbps 激增到5 Gbps。同時,無損類的流量從6 Gbps 下降到5 Gbps。這是因?yàn)樵谶@條10 GbE 鏈路上,無損類被分配了5 Gbps(50%)的帶寬保證。但該交換機(jī)其他端口上無損流量的總?cè)肟谒俾嗜詾? Gbps。為了將這些流量均衡到5 Gbps,該交換機(jī)調(diào)用了PFC,從而導(dǎo)致?lián)砣麛U(kuò)散。交換機(jī)上接收邊緣端口發(fā)送流量的其他端口上的Tx 暫停幀峰值證實(shí)了這一點(diǎn)。
在本案例研究中,明顯的問題是融合鏈路的容量不足,以及無損和有損類之間的流量爭用。通過增加另一條10 GbE 鏈路,這一問題得以解決。
在本案例研究中,兩種類型的流量(有損和無損)都使用兩條鏈路,這是共享存儲網(wǎng)絡(luò)的方法。另一種有效的方法是將一條鏈路專用于有損(普通級)流量,另一條鏈路專用于無損(無丟包級)流量,這就是專用存儲網(wǎng)絡(luò)的方法。
正確答案在于鏈路的容量和這些鏈路的預(yù)期吞吐量。專用存儲網(wǎng)絡(luò)是一種不同的架構(gòu),需要以不同的方式進(jìn)行操作。其優(yōu)點(diǎn)在于結(jié)構(gòu)的獨(dú)立性、可擴(kuò)展性、故障隔離和更易于故障排除。相反,專用存儲網(wǎng)絡(luò)的部署成本更高,需要更多資源來管理和運(yùn)行。
-
以太網(wǎng)
+關(guān)注
關(guān)注
40文章
5460瀏覽量
172726 -
交換機(jī)
+關(guān)注
關(guān)注
21文章
2656瀏覽量
100178 -
PFC
+關(guān)注
關(guān)注
47文章
977瀏覽量
106394 -
UTM
+關(guān)注
關(guān)注
0文章
29瀏覽量
13105 -
存儲網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
31瀏覽量
8139
原文標(biāo)題:以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載(五)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載方案(一)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載方案(二)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載方案(三)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載案例(六)
以太網(wǎng)存儲網(wǎng)絡(luò)的擁塞管理連載案例(七)


車載以太網(wǎng)基礎(chǔ)培訓(xùn)——車載以太網(wǎng)的鏈路層#車載以太網(wǎng)

車載以太網(wǎng)基礎(chǔ)培訓(xùn)——網(wǎng)絡(luò)層#車載以太網(wǎng)
以太網(wǎng)和工業(yè)以太網(wǎng)的不同
以太網(wǎng)供電新標(biāo)準(zhǔn)促熱網(wǎng)絡(luò)化電源管理應(yīng)用市場
以太網(wǎng)光纖通道(FCoE)技術(shù)問答
以太網(wǎng)的分類及靜態(tài)以太網(wǎng)交換和動態(tài)以太網(wǎng)交換、介紹
萬兆以太網(wǎng)和IP SAN的融合
光纖通道到以太網(wǎng)存儲結(jié)構(gòu)解析
以太網(wǎng)光模你了解多少
優(yōu)化網(wǎng)絡(luò)管理與監(jiān)控——工業(yè)以太網(wǎng)交換機(jī)的智能化之路

- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機(jī)智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論