") NVIDIA GPU架構(gòu)下的FP8訓練與推理
NVIDIA GPU架構(gòu)下的FP8訓練與推理
本文聚焦 NVIDIA FP8 訓練與推理的實踐應(yīng)用。
FP8 訓練利用 E5M2/E4M3 格式,具備與 FP16 相當?shù)膭討B(tài)范圍,適用于反向傳播與前向傳播。FP8 訓練在相同加速平臺上的峰值性能顯著超越 FP16/BF16,并且模型參數(shù)越大,訓練加速效果越好,且其與 16-bits 訓練在收斂性和下游任務(wù)表現(xiàn)上無顯著差異。FP8 訓練通過 NVIDIA Transformer Engine 實現(xiàn),僅需少量代碼改動,并且支持 FlashAttention、混合精度訓練遷移等。支持 FP8 的框架包括 NVIDIA Megatron-LM、NeMo、DeepSpeed、飛槳 PaddlePaddle、Colossal AI、HuggingFace 等。
FP8 推理通過 NVIDIA TensorRT-LLM 實現(xiàn),權(quán)重輸入先轉(zhuǎn)換為 FP8,并融合操作以提高內(nèi)存吞吐,但部分輸出仍需 FP16 進行 reduction。NVIDIA 技術(shù)團隊正研究直接 FP8 reduction 以實現(xiàn)端到端的加速優(yōu)化。
FP8 基本原理、采用理由和收益
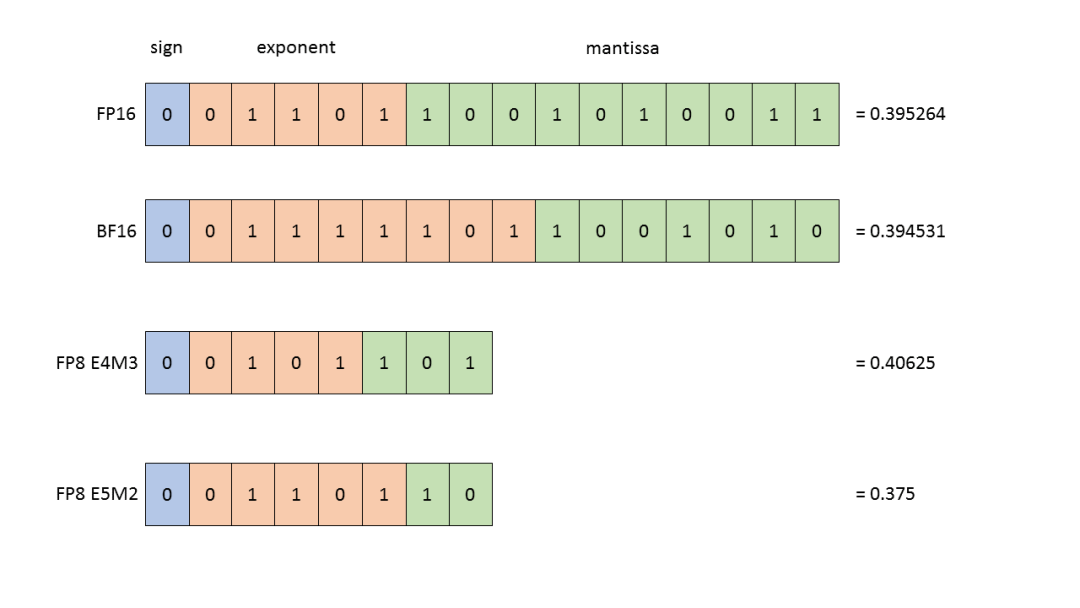
圖 1. 四種數(shù)據(jù)類型
首先詳解 FP8 的概念,圖 1 展示了 FP8、FP16、FP32 與 BF16 四種數(shù)據(jù)類型。業(yè)界曾長期依賴 FP16 與 FP32 訓練,直至 GPT 橫空出世,BF16 因能避免計算過程中的數(shù)值溢出問題而受到青睞。
近年來,NVIDIA 技術(shù)團隊在 FP8 領(lǐng)域持續(xù)投入,發(fā)布了多篇論文,并在歷屆 GTC 大會也分享了 FP8 在計算機視覺 (CV)、自然語言處理 (NLP) 以及大模型訓練中的實際效果。

圖 2. E4M3 與 E5M2 兩種數(shù)據(jù)格式
圖 2 表格展示了 E4M3 與 E5M2 兩種數(shù)據(jù)格式。其中可以看到,F(xiàn)P8 精度的 E5M2 數(shù)據(jù)格式的數(shù)部分,與 FP16 的保持一致。這意味著 FP8 精度的 E5M2 數(shù)據(jù)格式具備與 FP16 相當?shù)膭討B(tài)范圍,因此該數(shù)據(jù)格式常被用在訓練的反向傳播階段。而 E4M3 是在前向傳播中采用的 FP8 格式。圖 2 詳盡展示了 FP8 格式下各類特殊數(shù)值的表示方式。
當我們考慮浮點數(shù)的數(shù)據(jù)精度會不會損失的時候,這個浮點數(shù)往往會落入圖 2 下半部分里粉色的 subnormal 區(qū)間。圖 2 下半部分是以 FP32 舉例的,讀者可根據(jù)圖 2 表格看到 FP8 的 subnormal 區(qū)間,因此我們在訓練模型時可進行理論分析,探究數(shù)值精度是否影響模型效果。
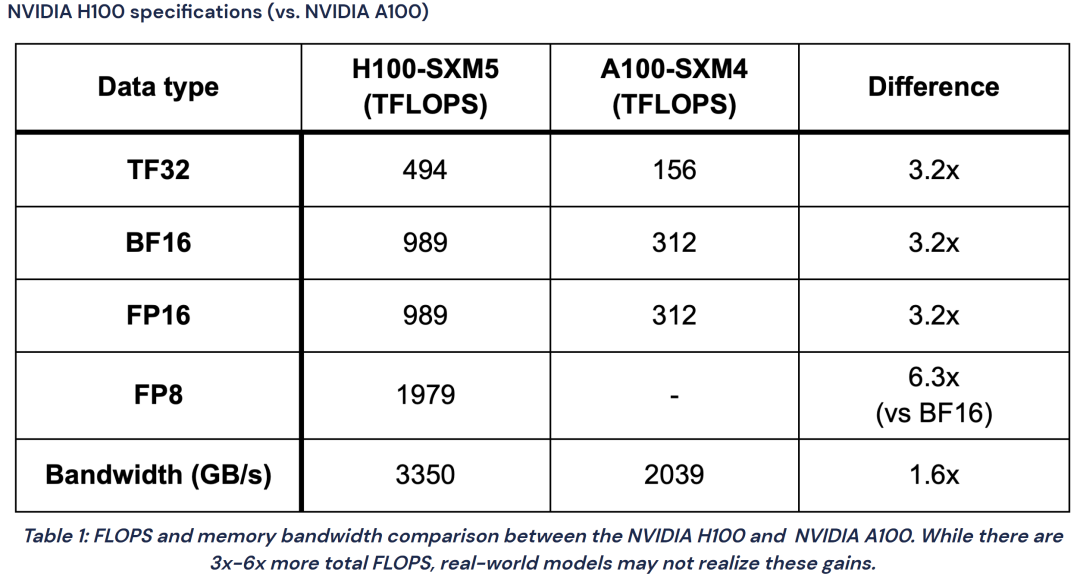
表 1. 援引的測試數(shù)據(jù)[1]僅供技術(shù)參考和討論
表 1 旨在闡述采用 FP8 的原因,以在 NVIDIA H100 Tensor Core GPU 上為例,單位是 TFLOPS,相較 FP16 和 BF16,F(xiàn)P8 的峰值性能能夠?qū)崿F(xiàn)翻倍。并且此表展示的基準測試數(shù)據(jù)是在 2023 年采集的,當前性能提升更為顯著。
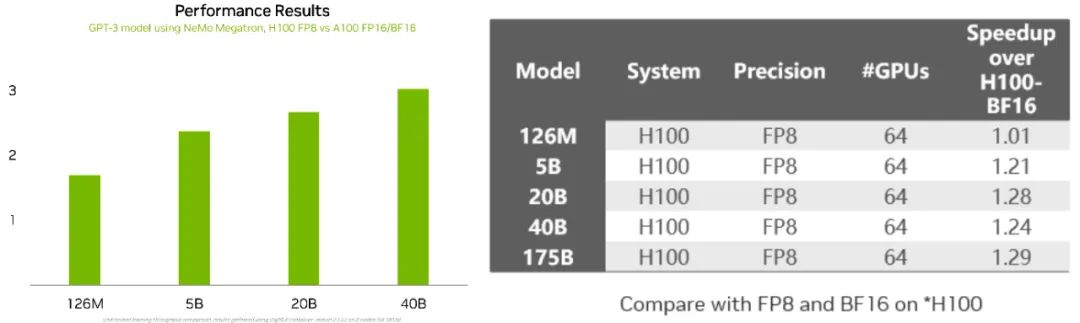
圖 3. 測試數(shù)據(jù)僅供技術(shù)參考和討論
圖 3 左側(cè)圖表對比了不同參數(shù)規(guī)模的 GPT-3 模型在 H100 上做 FP8 訓練,以及在 NVIDIA A100 Tensor Core GPU 上做 FP16/BF16 訓練的吞吐加速比。這個加速效果隨模型規(guī)模正向變化,比如參數(shù)規(guī)模為 5B 至 40B,它的加速效果約為 2 到 3 倍。
右側(cè)表格則進一步對比了不同參數(shù)規(guī)模的模型同在 H100 GPU 上,使用 FP8 訓練相對 BF16 的性能加速比。就 126M 至 175B 參數(shù)的模型而言,除了個別特殊任務(wù)外,F(xiàn)P8 訓練的加速效果同樣隨模型規(guī)模增大而提升。換言之,模型規(guī)模越大,采用 FP8 訓練的收益越大。

圖 4. 援引的測試數(shù)據(jù)[2]僅供技術(shù)參考和討論
圖 4 援引的是行業(yè)測試數(shù)據(jù)。左側(cè)圖表顯示的是對 GEMM 單一計算任務(wù)的加速對比。在 H100 GPU 上 FP8 訓練相對于 A100 GPU 上 BF16 訓練的峰值性能加速比約為 6 倍,而在 GEMM 任務(wù)測試中接近 5 倍。并且鑒于底層 CUDA 內(nèi)核持續(xù)優(yōu)化,未來性能將進一步提升。
右側(cè)表格則展示了在不同規(guī)模的 GPT 模型做 FP8 訓練的實際加速效果,模型參數(shù)規(guī)模分別為 1B、3B、7B 和 30B。該圖表分別對比了在 H100 GPU 與 A100 GPU 上做 BF16 和 FP8 訓練的加速效果。可以看到 BF16 訓練對 1B、3B 模型的加速比約為 2.2 倍,而 FP8 訓練的加速比分別達 2.7 倍、2.8 倍,對 7B、30B 模型加速比則達到 3 倍和 3.3 倍,說明 FP8 訓練的性能優(yōu)化效果更加顯著。
FP8 的訓練性能和收斂性
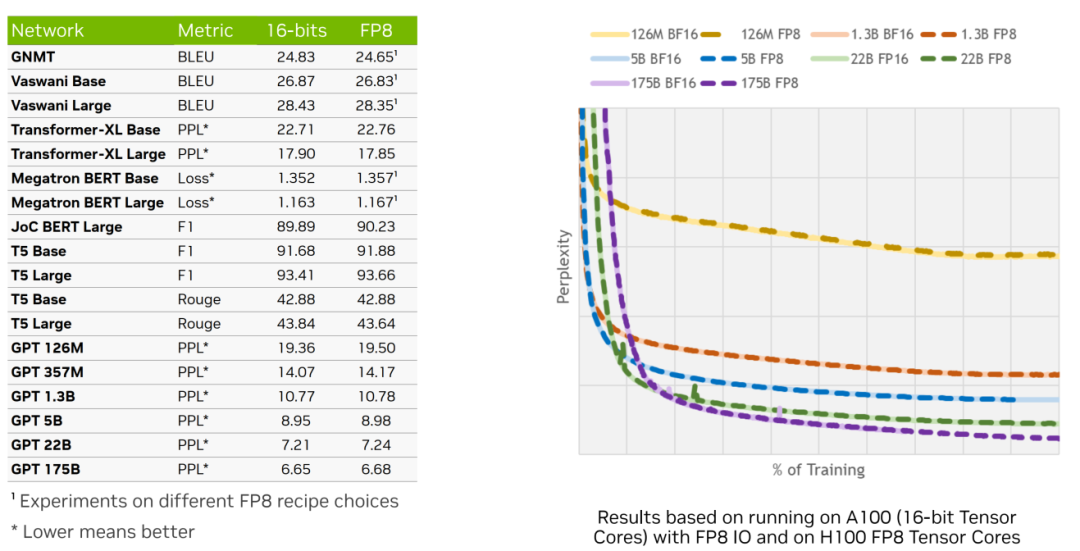
圖 5. 測試數(shù)據(jù)僅供技術(shù)參考和討論
圖 5 展示了 FP8 訓練的性能與收斂性。右圖顯示在不同規(guī)模的 GPT 模型上使用 BF16 與 FP8 進行訓練的 loss (損失值)曲線,并以困惑度 PPL(Perplexity) 為度量指標。同色曲線代表相同模型規(guī)模,實線代表 BF16,虛線為 FP8。觀察 PPL 曲線走勢,可見隨著訓練進程,F(xiàn)P8 與 BF16 的曲線幾乎完全吻合,表明兩者收斂性并無顯著差異。
左側(cè)表格則匯總了歷屆 GTC 大會中分享的下游任務(wù)數(shù)據(jù),包括 PPL 指標及 FP8 與 16-bits 訓練的對比,涵蓋 NLP 模型和 CV 模型。結(jié)果顯示,使用 FP8 訓練的模型與 16-bits 訓練的模型在各項指標上的數(shù)值差異甚微,證實了 FP8 訓練能達到同等效果。
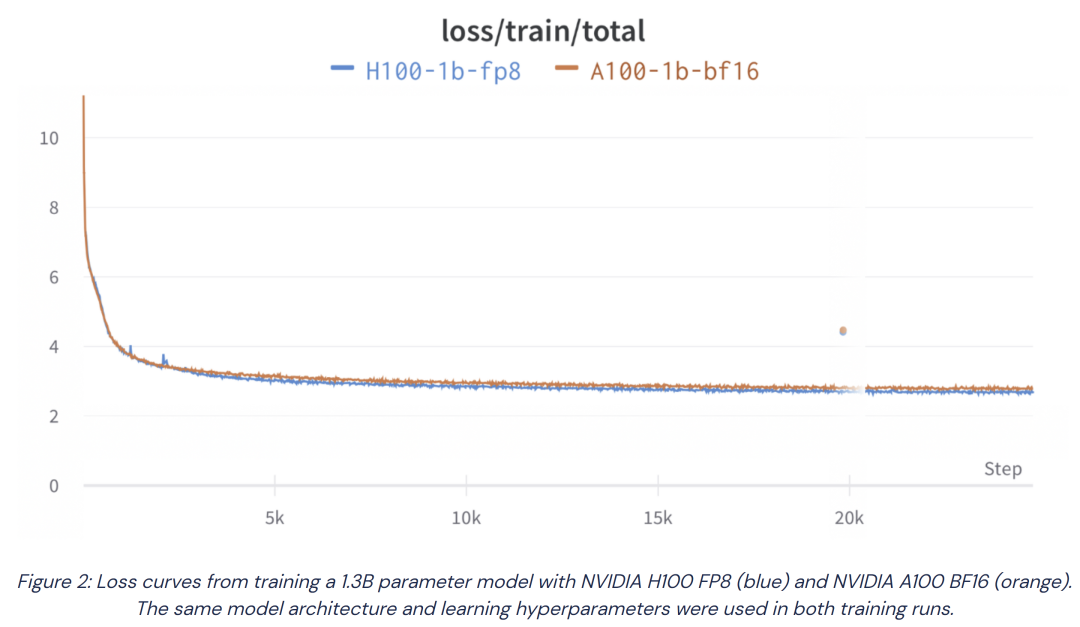
圖 6. 援引的測試數(shù)據(jù)[3]僅供技術(shù)參考和討論
圖 6 展示了我們在本地測試的一個 1.3B 參數(shù)模型的實際訓練結(jié)果,共進行了約 2.5 萬步訓練。結(jié)果顯示,該模型的 loss 曲線與預(yù)期基本相符,僅有微小(零點零幾)的差異。
這里列舉在 FP8 訓練中實際采用的配置。可以看到使用 FP8 訓練時對代碼的改動極少,只需添加幾行代碼即可,后文將詳細解釋這些代碼的具體含義。
--fp8-hybrid
--transformer-impl transformer_engine
--fp8-amax-history-len 1024
--fp8-amax-compute-algo max
此外,我們在實際訓練中的常見問題解答如下:
目前廣泛采用 BF16 進行混合訓練,轉(zhuǎn)用 FP8 是否需要自行編譯 kernel 或進行復(fù)雜的數(shù)據(jù)類型轉(zhuǎn)換? 答案是否,建議使用 NVIDIA Transformer Engine 預(yù)置的多種 FP8 kernel(Linear、MLP、LayerNorm 等基礎(chǔ)算子及基于這些算子的fused kernel),無需開發(fā),直接調(diào)用即可。
如果沒使用 NVIDIA Megatron 或 DeepSpeed 框架,而是采用自定義框架,可以無縫使用 Transformer Engine 進行 FP8 訓練嗎? 答案是可以。只需在 PyTorch 上使用 Transformer Engine 提供的 fp8_autocast 包裝器(wrapper),即可在原生 PyTorch 環(huán)境中開展 FP8 訓練。此 wrapper 主要用于提供一系列 FP8-safe 的算子,自動將高精度的輸入數(shù)據(jù)轉(zhuǎn)換為 FP8,簡化了低精度訓練的實現(xiàn)過程。在上述過程中,需要對每個 tensor 更新其縮放因子 (scale),為此我們引入 amax(maximums of absolute value)的概念,fp8_autocast wrapper 會更新 amax 值。此外,根據(jù) amax 值,該 wrapper 還會自動計算每個 tensor 的實際 scale 值。
Transformer Engine 除提供 FP8 layer-wise 模塊和自動數(shù)據(jù)類型轉(zhuǎn)換外,還有什么功能? 答案是它還支持 FlashAttention 機制。這意味著 Transformer Engine 也能夠提升傳統(tǒng) BF16、FP16 訓練的性能。
對于已使用 BF16 訓練的存量模型,能夠使用 FP8 做繼續(xù)訓練嗎? 答案是可以。實踐證明,BF16 格式的 checkpoint 可以直接導入進行 FP8 繼續(xù)訓練;反之亦然,即在預(yù)訓練階段使用了 FP8,那么在 SFT(supervised Fine-Tuning) 階段,出于對模型精度或數(shù)據(jù)健壯性的考慮,仍舊可以從 FP8 無縫切換到 BF16 做繼續(xù)訓練。Transformer Engine 全面支持此類精度遷移的操作。
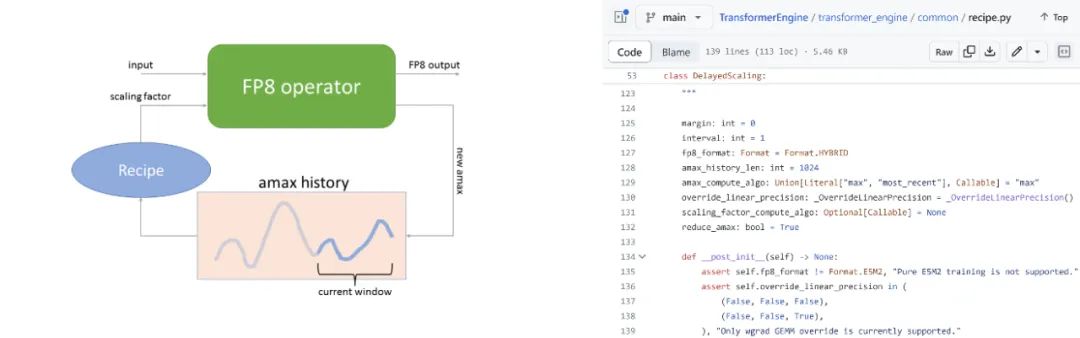
圖 7. 解讀 FP8 訓練中新增的五行代碼
圖 7 旨在解讀前文提及的 FP8 訓練中新增的五行代碼,代碼的功能是用于計算當前 tensor 的 scale 值。我們采用名為 delayed scaling 策略,即當前 tensor 的 scale 值并非基于實時計算得出,而是依據(jù)其歷史數(shù)據(jù),例如基于前幾個迭代周期的值計算得出。計算方法可選擇取 max 值,也可采用最近時間的值。
以該圖展示的 amax history 說明,針對當前 tensor,系統(tǒng)可存儲 1,024 個 amax 值,并從中選取最大值作為當前 tensor 的 amax 值。隨后,根據(jù)一個簡化的 recipe 算法即可計算出 scale 值。
實際應(yīng)用中,Hopper GPU 上 FP8 訓練相較于 BF16 的加速效果為 30%-40%,低于 FP8 在單一 GEMM 計算任務(wù)中理論可達的 5 倍加速比。為解釋此現(xiàn)象,本文借助圖 8 進行闡述。
使用 Transformer Engine 訓練 FP8 LLM
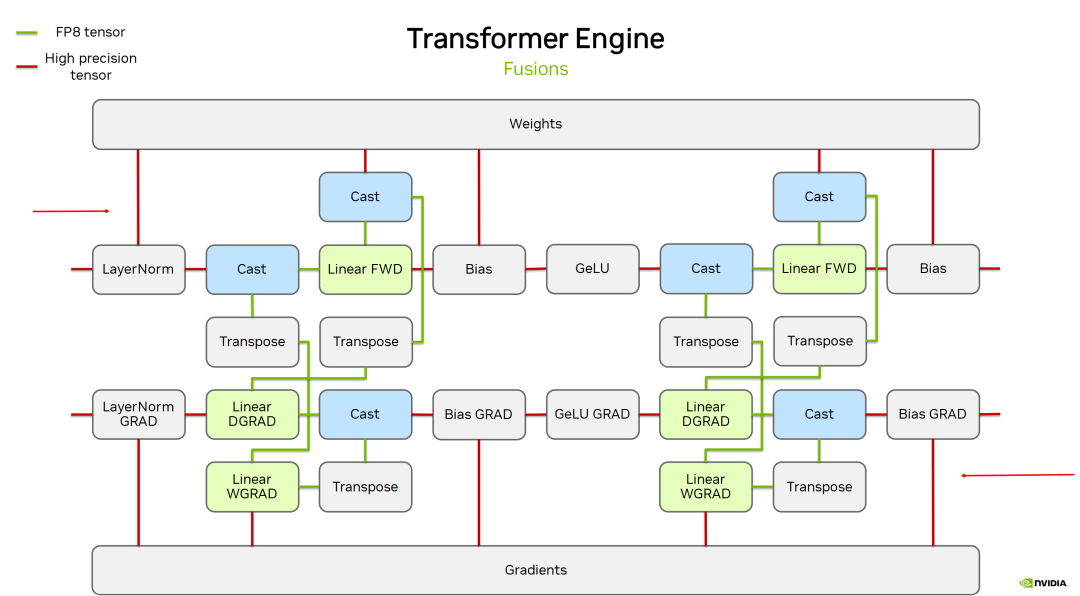
圖 8. FP8 訓練在 Transformer Engine 上的完整流程
圖 8 顯示了訓練中前向與反向計算的精度差異:紅線表示高精度(BF16、FP32),綠線為 FP8。在整個訓練期間,圖片上半部分的權(quán)重(weight)及下半部分的梯度(gradient)始終以高精度存儲。僅在執(zhí)行 linear 操作時,才對當前 tensor 進行數(shù)據(jù)格式轉(zhuǎn)換(cast),轉(zhuǎn)為 FP8 精度計算,但 linear 輸出仍為高精度。因此,后續(xù) bias 計算等均在高精度上進行。
圖示表明,實際訓練中僅 GEMM 計算采用 FP8,其余計算保持高精度。盡管業(yè)界存在對非線性操作也采用 FP8 計算和存儲的激進策略,并在部分下游任務(wù)中表現(xiàn)良好,但主流方案依然遵循上述精細化的精度分配原則。
目前支持 FP8 訓練的分布式訓練框架與工具包括 NVIDIA Megatron-LM、NeMo 框架,DeepSpeed、飛槳 PaddlePaddle、Colossal AI、HuggingFace 等,也就是說這些框架均已集成了 Transformer Engine,可選用上述任一框架進行大模型 FP8 訓練。

圖 9. 不同數(shù)據(jù)精度
集合Transformer Engine 的訓練測試結(jié)果對比
圖 9 總結(jié)了上述重點,通過對比三類測試情況:綠線代表僅使用 BF16 訓練,橘線表示 BF16 訓練結(jié)合 Transformer Engine(即在啟用 FlashAttention 的同時,使用 Transformer Engine 內(nèi)置的 fused kernel),藍線為 FP8 訓練結(jié)合 Transformer Engine。
綠線顯示,僅用 BF16 訓練時,模型在單 GPU 卡上即遭遇內(nèi)存不足(OOM),而在啟用 Transformer Engine 后,依舊采用 BF16,模型也能順利完成訓練。若進一步轉(zhuǎn)為 FP8,單次迭代時間可提升約 34.56%。
中間的圖表展示了各類測試的顯存占用情況。如前文所述,權(quán)重、梯度及優(yōu)化器(optimizer)的數(shù)據(jù)均以高精度存儲,此外,F(xiàn)P8 訓練因需在 checkpoint 中保存額外值,訓練時顯存占用比 FP16 略高約 5% 以內(nèi)。須注意,推理階段的顯存占用與訓練階段是完全不同的。
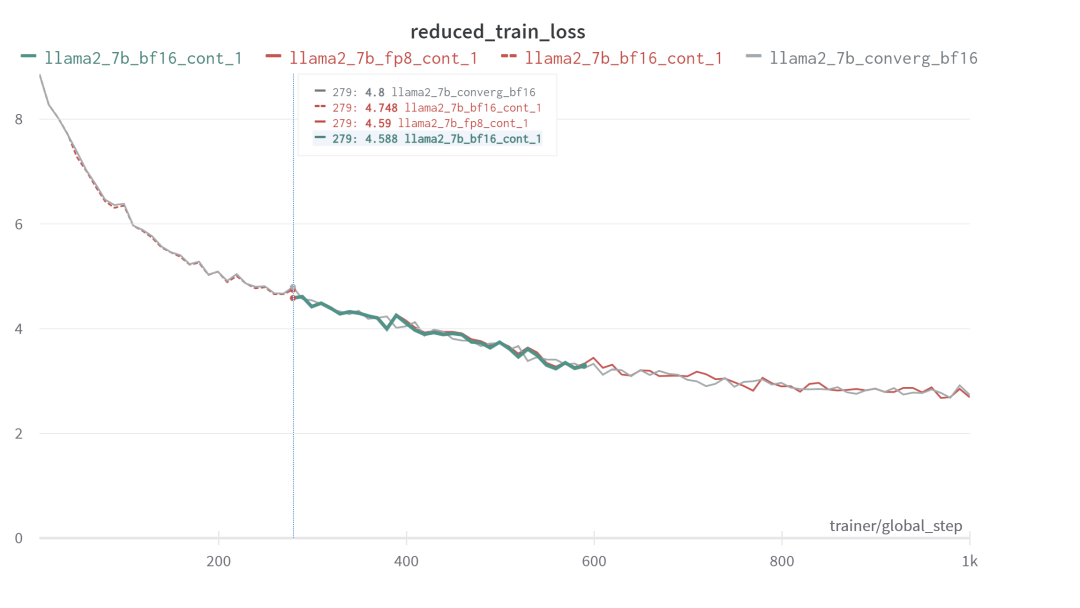
圖 10. Llama2-7B 模型做 FP8/BF16
繼續(xù)訓練的 loss 曲線高度一致
圖 10 展示了對 Llama2-7B 模型做 FP8 繼續(xù)訓練的效果。本測試并未進行長時間的訓練,目的是在為了提供概念驗證 (PoC, Proof of Concept)。圖中共有四條曲線:灰色曲線代表全程使用 BF16 訓練,其余三條線分別表示以 BF16 進行預(yù)訓練,保存 checkpoint 后,再分別以 BF16 與 FP8 繼續(xù)訓練。從繼續(xù)訓練的兩條曲線來看,loss 曲線高度一致,且與灰色曲線的趨勢也保持一致。
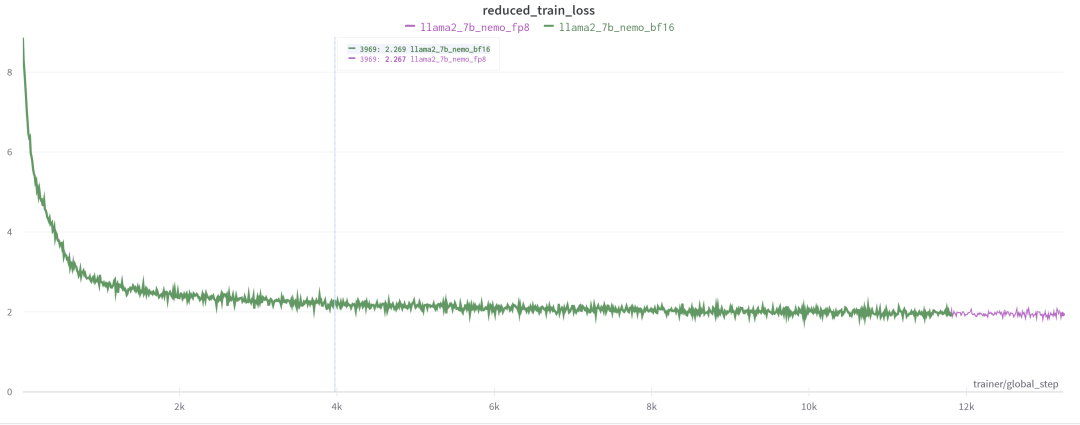
圖 11. Llama2-7B 模型 1.3 萬步內(nèi)
全程 FP8/BF16 訓練的 loss 曲線基本一致
圖 11 展示的是對 Llama2-7B 在 1.3 萬迭代步內(nèi)做全程 FP8 訓練,可以看到它和全程 BF16 訓練的 loss 曲線也幾乎一致。
FP8 推理流程
本章節(jié)分享使用 TensorRT-LLM 進行 FP8 推理。前文圖 8 展示的 FP8 訓練在 Transformer Engine 上的完整流程,而在進入推理階段,圖 8 下半部分如梯度等訓練特有部分可去除,僅保留上半部份即可。
訓練時為確保梯度計算準確,權(quán)重通常維持為高精度(如 BF16 或 FP32),這是由于訓練時需更新參數(shù),而在推理時,權(quán)重已固定,故可在模型加載或預(yù)處理階段提前將權(quán)重轉(zhuǎn)換為 FP8,確保模型加載即為 FP8 格式。此外,推理階段應(yīng)盡量進行操作融合,如將 LayerNorm 與后續(xù)數(shù)據(jù)格式轉(zhuǎn)換操作整合,確保 kernel 輸入輸出盡可能維持 FP8,從而能夠有效提升 GPU 內(nèi)存吞吐。同樣,GeLU (Gaussian Error Linear Unit) 激活函數(shù)也要力求融合。
目前少量輸出仍會保持為 FP16,原因是 NVIDIA NCCL 僅支持高精度規(guī)約操作 (reduction),所以現(xiàn)在仍然需采用 FP16 進行 reduction,完成后再轉(zhuǎn)化為 FP8。
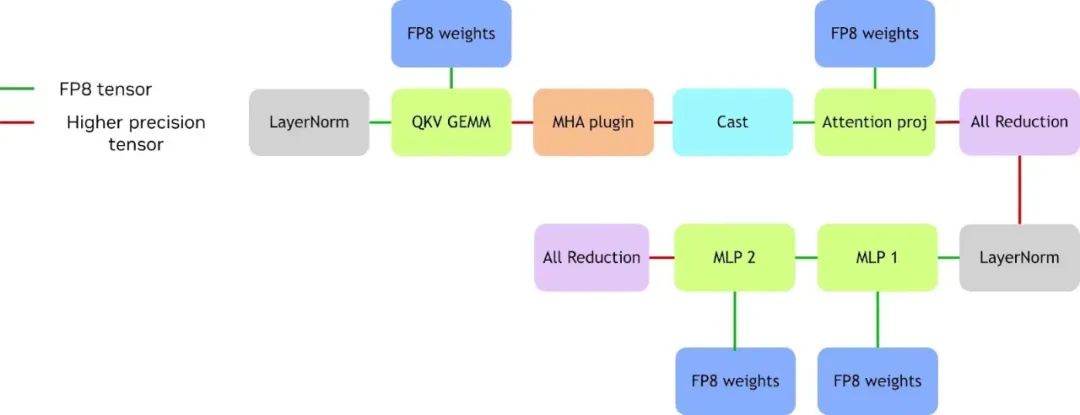
圖 12. FP8 推理流程
經(jīng)過上述融合后,推理流程就簡化為圖 12 所示。綠線代表 FP8 的輸入輸出(I/O),紅線表示高精度 I/O。圖中可見,最前端的 LayerNorm 輸出與權(quán)重均為 FP8,矩陣輸出暫時保持 FP16,與前文描述一致。并且經(jīng)過測試驗證可得,雖然矩陣輸出精度對整體性能影響較小,但與輸入問題的規(guī)模相關(guān);且因其計算密集特性,對輸出形態(tài)影響微弱。
在完成 MHA(Multi-Head Attention)后,需要將結(jié)果轉(zhuǎn)換為 FP8 以進行后續(xù)矩陣計算,Reduction 是以 FP16 執(zhí)行后再轉(zhuǎn)換到 FP8 的。對于 MLP1 和 MLP2,兩者邏輯相似,但不同之處在于:MLP1 的輸出可保持在 FP8,因為它已經(jīng)把 GeLU 加 Bias 等操作直接融合到 MLP1 的 kernel。
由此引發(fā)的關(guān)鍵問題是,能否將剩余紅線(高精度 I/O)全部轉(zhuǎn)為綠線(FP8 I/O),實現(xiàn)進一步的加速優(yōu)化?這正是 NVIDIA 持續(xù)進行的方向。以 reduction 為例,NVIDIA 正研究直接實現(xiàn) FP8 reduction,盡管中間累加仍需高精度,但在數(shù)據(jù)傳輸階段可采用 FP8。與現(xiàn)有 reduction 不同的是,F(xiàn)P8 reduction 內(nèi)部需引入反量化(de-quantization)與量化 (quantization)操作,故需定制開發(fā) reduction kernel。
最佳實踐:使用 TensorRT-LLM 實現(xiàn) FP8 推理
TensorRT-LLM 是基于 NVIDIA TensorRT 構(gòu)建,其 FP8 能力也主要是通過 TensorRT 提供。自 TensorRT 9.0 版本起,官方就已經(jīng)開始支持 FP8 推理。要在 TensorRT 中啟用 FP8 推理,需完成以下幾步:
設(shè)置 FP8 標志:通過調(diào)用 config.set_flag (trt.BuilderFlag.FP8) 在 TensorRT 配置中啟用 FP8 支持。類似 INT8、BF16、FP16,F(xiàn)P8 也是類似的啟用方式。
添加 GEMM 縮放因子(scale):主要針對輸入和權(quán)重,需在 weight.py (TensorRT-LLM 中的文件)中額外加載這些縮放因子。這是 FP8 推理中不可或缺的步驟。
編寫 FP8模型:現(xiàn)階段我們需要明確編寫需要 FP8 支持的模型。具體做法如下:將原始 FP16 輸入量化至 FP8,隨后進行反量化;權(quán)重同樣進行量化與反量化操作。如此編寫的模型,TensorRT 會自動將量化與反量化操作盡可能與前一個 kernel 融合,以及將反量化操作與 matmul kernel 融合。最終生成的計算圖表現(xiàn)為量化后的 X 與 W 直接進行 FP8 計算,輸出也為 FP8 結(jié)果。
為了簡化 FP8 在 TensorRT-LLM 中的應(yīng)用,TensorRT-LLM 已對其進行封裝,提供了 FP8 linear 函數(shù)和 FP8 row linear 函數(shù)來實現(xiàn)。對于使用直接線性層(linear layer),則無需重新編寫代碼,直接調(diào)用函數(shù)即可。
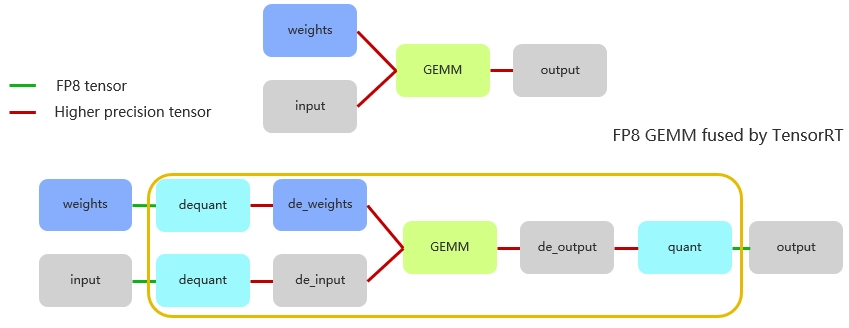
圖 13. FP8 推理計算流程
本文用圖 13 總結(jié)上述內(nèi)容。首先權(quán)重以 FP8 精度存儲的,在進行計算前,權(quán)重先經(jīng)歷一次反量化。注意,在此之前,權(quán)重的量化已在輸入前完成了,此處僅需進行反量化操作。這意味著,在進行矩陣內(nèi)部計算時,實際上是使用反量化后的數(shù)據(jù),通常是 FP16 或甚至 FP32 來進行運算的。
矩陣層盡管以 FP8 表示,但累加是采用 FP32 完成,累加后再乘以 scale 的相關(guān)參數(shù),形成如圖所示的計算流程。最終得到的結(jié)果具備較高精度。由于累加器(accumulator)需要采用高精度的數(shù)值,因此,要獲得最終 FP8 的輸出結(jié)果,模型還需經(jīng)過一個量化節(jié)點 (quantitation node)。
回顧整個流程,輸入經(jīng)歷了量化與反量化操作。其中,量化 kernel 發(fā)生在反量化 kernel 之前,而 TensorRT 則會智能地融合這些 kernel,確保計算的高效和準確。
使用 Tensor-LLM 實現(xiàn) FP8 推理的性能
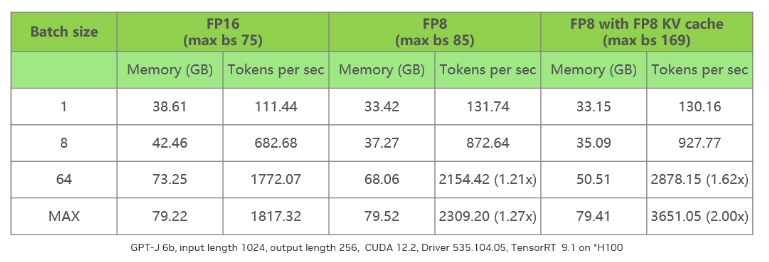
表 2 測試數(shù)據(jù)僅供技術(shù)參考和討論
表 2 對比第一列不同的 batch size,其中 max 值指的是在設(shè)定輸入為 1,024,輸出為 256,模型為 GPT-J 6B,所能使用的最大 batch size。
列表顯示,F(xiàn)P16 的 max 值為 75,而 FP8 的 max 值則提升至 85。原因是 FP8 僅節(jié)省了權(quán)重部分的內(nèi)存,部分 tensor 以及 KV cache 仍保持在 FP16。表格最后一列展示了使用 FP8 KV cache 的情況,此時能夠看到其 max 值相比 FP16 的 max 值超出 2 倍。
在性能方面,單純啟用 FP8 會由于 batch size 提升有限,以及 KV cache 的影響,導致性能提升并不顯著。然而,一旦將 KV cache 也轉(zhuǎn)換至 FP8,通過減半其內(nèi)存消耗,模型吞吐量可以相較 FP16 提升約兩倍左右,這是一個相當理想的性能提升幅度。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5076瀏覽量
103717 -
計算機視覺
+關(guān)注
關(guān)注
8文章
1700瀏覽量
46126 -
GPT
+關(guān)注
關(guān)注
0文章
360瀏覽量
15505
原文標題:NVIDIA GPU 架構(gòu)下的 FP8 訓練與推理
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
FP8在大模型訓練中的應(yīng)用

解鎖NVIDIA TensorRT-LLM的卓越性能
《CST Studio Suite 2024 GPU加速計算指南》
如何使用FP8新技術(shù)加速大模型訓練
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
FP8數(shù)據(jù)格式在大型模型訓練中的應(yīng)用

TensorRT-LLM低精度推理優(yōu)化

PyTorch GPU 加速訓練模型方法
NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案

FP8模型訓練中Debug優(yōu)化思路
進一步解讀英偉達 Blackwell 架構(gòu)、NVlink及GB200 超級芯片
NVIDIA推出兩款基于NVIDIA Ampere架構(gòu)的全新臺式機GPU
利用NVIDIA組件提升GPU推理的吞吐
FP8在NVIDIA GPU架構(gòu)和軟件系統(tǒng)中的應(yīng)用

NVIDIA的Maxwell GPU架構(gòu)功耗不可思議






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論