 如何提高自動駕駛汽車感知模型的訓練效率和GPU利用率
如何提高自動駕駛汽車感知模型的訓練效率和GPU利用率
由于采用了多攝像頭輸入和深度卷積骨干網絡,用于訓練自動駕駛感知模型的 GPU 內存占用很大。當前減少內存占用的方法往往會導致額外的計算開銷或工作負載的失衡。
本文介紹了 NVIDIA 和智能電動汽車開發商蔚來的聯合研究。具體來說,文中探討了張量并行卷積神經網絡(CNN)訓練如何有助于減少 GPU 內存占用,并展示了蔚來如何提高自動駕駛汽車感知模型的訓練效率和 GPU 利用率。
自動駕駛的感知模型訓練
自動駕駛感知任務采用多攝像頭數據作為輸入,卷積神經網絡(CNN)作為骨干(backbone)來提取特征。由于 CNN 的前向激活值(activations)都是形狀為(N, C, H, W)的特征圖(feature maps)(其中 N、C、H、W 分別代表圖像數、通道數、高度和寬度)。這些激活值需要被保存下來用于反向傳播,因此骨干網絡的訓練通常會占據顯著的內存大小。
例如,有 6 路相機以 RGB 格式輸入分辨率為 720p 的圖像,批大小(batchsize)設置為 1,那么骨干網絡的輸入形狀為(6, 3, 720, 1280)。對于如 RegNet 或 ConvNeXt 這樣的骨干網絡而言,激活值的內存占用是遠大于模型權重和優化器狀態的內存占用的,并且可能會超出 GPU 的內存大小限制。
蔚來汽車自動駕駛團隊在這一領域的研究表明,使用更深的模型和更高的圖像分辨率可以顯著提高感知精度,尤其是對尺寸小和距離遠的目標的識別;同時,蔚來 Aquila 超感系統搭載 11 個 800 萬像素高清攝像頭,每秒可產生 8GB 圖像數據。
GPU 內存優化需求
深度模型和高分辨率輸入對于 GPU 內存優化提出了更高的要求。當前解決激活值 GPU 內存占用過大的技術有梯度檢查點(gradient checkpointing),即在前向傳播的過程中,只保留部分層的激活值。而對于其他層的激活值,則在反向傳播的時候重新計算。
這樣可以節省一定的 GPU 內存,但會增加計算的開銷,拖慢模型訓練。此外,設置梯度檢查點通常需要開發者根據模型結構來選擇和調試,這給模型訓練過程引入了額外的代價。
蔚來還使用了流水線并行技術,將神經網絡按照 GPU 內存開銷進行平均分段,部署到多個 GPU 上進行訓練。此方法雖然將存儲需求平分到多個 GPU 上,但是因為計算不平衡,會導致明顯的 GPU 間負載不均衡現象,一些 GPU 的計算資源無法被充分利用。
基于 PyTorch DTensor 的張量并行 CNN 訓練
綜合考慮以上因素,NVIDIA 和蔚來合作設計并實現了張量并行(Tensor Parallel)卷積神經網絡訓練方案,將輸入值和中間激活值切分到多個 GPU 上。而對于模型權重和優化器狀態,我們采用和數據并行訓練相同的策略,將其復制到各個 GPU 上。該方法能夠降低對單個 GPU 的內存占用和帶寬壓力。
PyTorch 2.0 中引入的 DTensor 提供了一系列原語(primitives)來表達張量的分布如切片(sharding)和重復(replication),使用戶能夠方便地進行分布式計算而無需顯式調用通信算子,因為 DTensor 的底層實現已經封裝了通信庫,如 NVIDIA 集合通信庫 (NCCL)。
有了 DTensor 的抽象,用戶可以方便地搭建各種并行訓練策略,如張量并行(Tensor Parallel),分布式數據并行(Distributed Data Parallel)和完全切片數據并行(Fully Sharded Data Parallel)。
實現
以用于視覺任務的 CNN 模型 ConvNeXt-XL 為例,我們將展示 Tensor Parallel 卷積神經網絡訓練的實現。DTensor 放置方式如下:
模型參數:Replicate
重復放置在各個 GPU 上,模型包含 3.50 億個參數,以 FP32 存儲時占據 1.4GB GPU 內存。
模型輸入:Shard(3)
切分(N, C, H, W)的 W 維度,將輸入分片放到各個 GPU 上。例如,在 4 個 GPU 上對形狀為(7, 3, 512, 2048) 的輸入執行 Shard(3) 會生成四個切片,形狀為 (7, 3, 512, 512)。
激活值:Shard(3)
切分(N, C, H, W)的 W 維度,將激活值分片放在各個 GPU 上
模型參數的梯度:Replicate
重復放置在各個 GPU 上。
優化器狀態:Replicate
重復放置在各個 GPU 上。
上述配置可以通過 DTensor 提供的 API 來實現,且用戶只需指明模型參數和模型輸入的放置方式,其他張量的放置方式會自動生成。
而要達成張量并行的訓練,我們需要給卷積算子 aten.convolution 和 aten.convolution_backward 注冊傳播規則,這將根據輸入 DTensor 的放置方式來確定輸出 DTensor 的放置方式:
aten.convolution
Input 放置方式為 Shard(3),weight 和 bias 放置方式為 Replicate,output 放置方式為 Shard(3)
aten.convolution_backward
grad_output 放置方式為 Shard(3),weight和 bias 放置方式為 Replicate,grad_input 放置方式為 Shard(3),grad_weight 和 grad_bias 方式方式為 _Partial
放置方式為 _Partial 的 DTensor,在使用其數值時會自動執行規約操作,默認規約算子為求和。
接下來,我們便要給出張量并行的卷積算子前向和反向的實現。由于將激活值切分到了多個 GPU 上,1 個 GPU 上的本地卷積可能需要相鄰 GPU 上激活值的邊緣數據,這就需要 GPU 之間進行通信。在 ConvNeXt-XL 模型中,其降采樣層的卷積不存在該問題,而 Block 中的逐深度卷積則需要處理該問題。
如果無需交換數據,用戶可以直接調用卷積的前向和反向算子,傳入本地張量即可。如果需要交換本地激活值張量邊緣數據,則使用如圖 1 和圖 2 所示的卷積前向算法和反向算法,省略了圖中的 N 和 C 維度,并假設卷積核大小為 5x5,padding 為 2,stride 為 1。
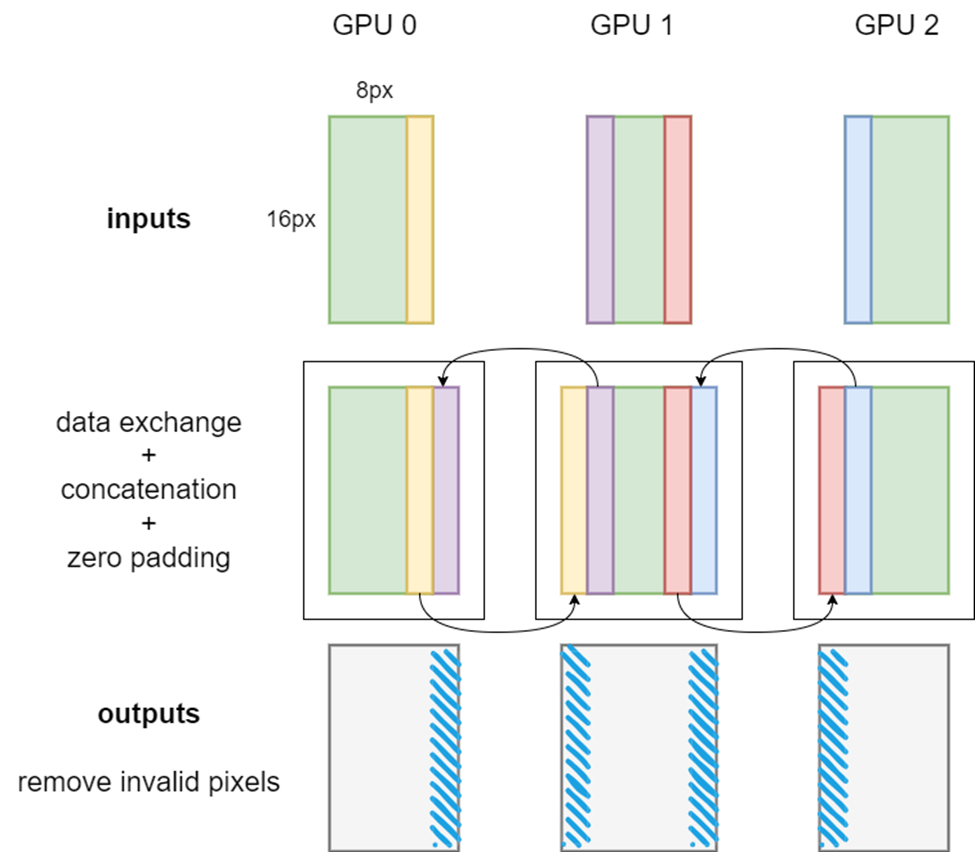
圖 1 張量并行卷積前向算法示意圖
如圖 1 所示,當卷積核大小為 5x5,padding 為 2,stride 為 1 時,每個 GPU 上的本地 input 都需要取用相鄰 GPU 的寬度為 2 的輸入邊緣,并將收到的邊緣數據拼接到自身上。換句話說,需要 GPU 間的通信來確保張量并行卷積的正確性。這種數據交換,可以通過調用 PyTorch 封裝的 NCCL 發送接受通信算子來實現。
值得一提的是,在多個 GPU 上存在激活切片時,卷積算子的有些 padding 是不需要的。因此本地卷積前向傳播完成后,需要切除 output 中由不需要的 padding 引入的無效像素,如圖 1 中的藍色條所示。
圖 2 顯示了張量并行卷積的反向傳播。首先,在梯度輸出上應用 zero padding,這與前向傳播過程中的輸出切除操作相對應。對本地輸入同樣要進行數據交換、拼接和 padding 操作。
之后,通過調用每個 GPU 上的卷積反向算子,即可獲得權重梯度、偏置梯度和梯度輸入。
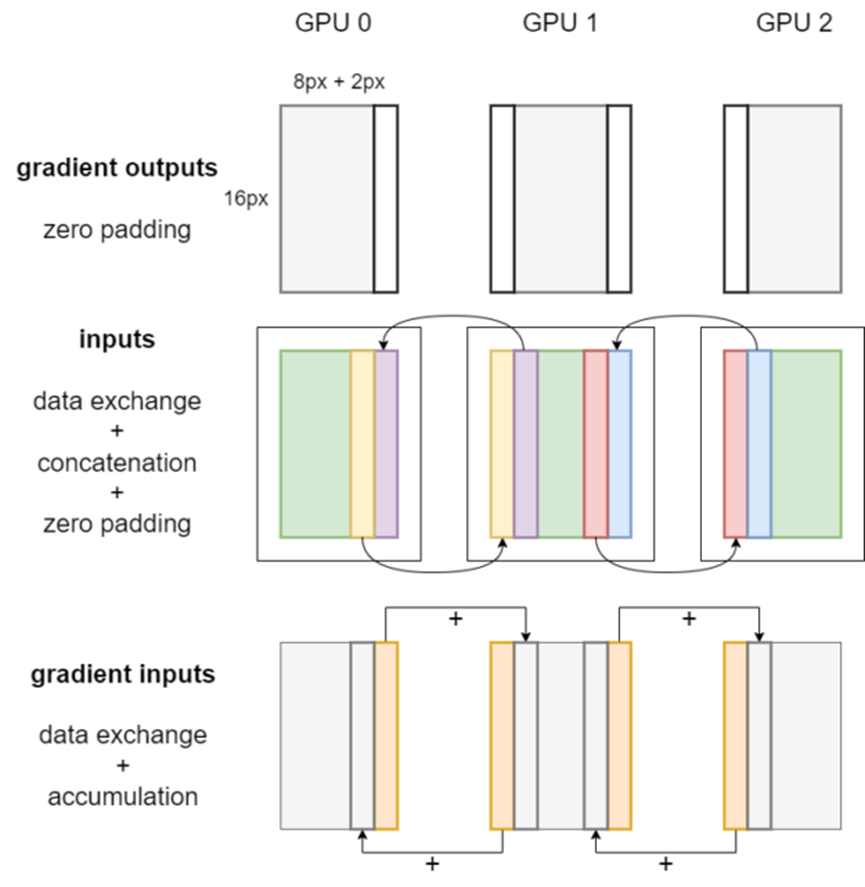
圖 2 張量并行卷積反向傳播工作流程
權重梯度和偏置梯度的 DTensor 放置方式是 _Partial,因此使用時會自動對它們的值進行多 GPU 規約操作。梯度輸入的 DTensor 放置方式是 Shard(3)。
最后,本地梯度輸入的邊緣像素會被發送到鄰近 GPU 并在相應位置累積,如圖 2 中的橙色條所示。
除了卷積層之外,ConvNeXt-XL 還有一些層需要處理以支持張量并行訓練。例如我們需要為 DropPath 層使用的 aten.bernoulli 算子傳播規則。該算子應被置于隨機數生成追蹤器的分布式區域內,以保證各個 GPU 上的一致性。
所有代碼已經并入了 PyTorch GitHub repo 的主分支,用戶使用時直接調用 DTensor 的上層 API 便可實現張量并行的卷積神經網絡訓練。
使用張量并行訓練 ConvNeXt 的基準效果
我們在 NVIDIA DGX AI 平臺上進行了基準測試,研究 ConvNeXt-XL 訓練的速度和 GPU 內存占用。梯度檢查點技術和 DTensor 是兼容的,并且結合兩項技術,GPU 的內存占用能夠更顯著地降低。
測試的基線是在 1 個 NVIDIA GPU 上使用 PyTorch 原生 Tensor,輸入大小為(7, 3, 512, 1024)時的結果:不使用梯度檢查點時 GPU 內存占用為 43.28 GiB,一次訓練迭代時間為 723 ms;使用梯度檢查點時 GPU 內存占用為 11.89 GiB,一次訓練迭代時間為 934 ms。
全部測試結果如圖 3 和圖 4 所示:全局輸入形狀為 (7,3,512,W),其中 W 從 1024 到 8192 不等。實線為未使用梯度檢查點時的結果,虛線為使用梯度檢查點時的結果。
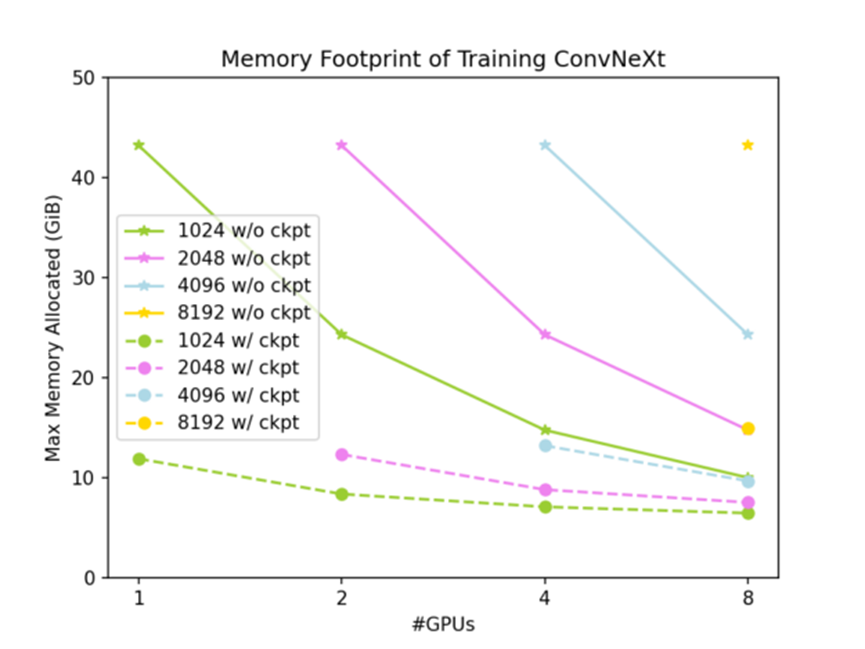
圖 3 各種測試條件下的 GPU 內存占用
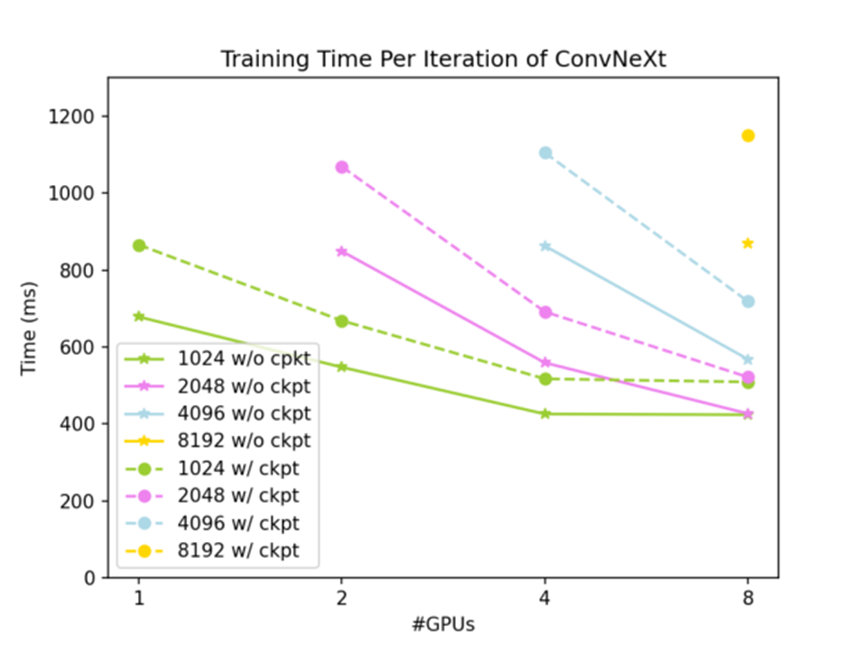
圖 4 各種測試條件下一次訓練迭代耗時
如圖 3 所示,使用 DTensor 切分激活值可以有效降低 ConvNeXt-XL 訓練的 GPU 內存占用,并且同時使用 DTensor 和梯度檢查點,ConvNeXt-XL 訓練的 GPU 內存占用可以降到很低的水平。如圖 4 所示,張量并行方法有很好的弱擴展性;在問題規模足夠大時,也有不錯的強擴展性。下面是不使用梯度檢查點時的擴展性:
全局輸入(7, 3, 512, 2048)給 2 個 GPU 時,一次迭代時間為 937 ms
全局輸入(7, 3, 512, 4096)給 4 個 GPU 時,一次迭代時間為 952 ms
全局輸入(7, 3, 512, 4096)給 8 個 GPU 時,一次迭代時間為 647 ms
結論
蔚來自動駕駛開發平臺(NADP)是蔚來專門用于研發核心自動駕駛服務的平臺。該平臺可提供高性能計算和全鏈工具,用來處理每天成千上萬的日常推理和訓練任務,以確保主動安全和駕駛輔助功能的持續演進。使用 DTensor 實現的張量并行 CNN 訓練能夠有效提高 NADP 上的訓練效率。
該關鍵性的方案使得 NADP 能夠進行萬卡規模的并行計算,它提高了對 GPU 的利用率,降低了訓練模型的成本,支持了更靈活的模型結構。基準測試顯示,在蔚來自動駕駛場景下,該方法表現良好,有效解決了視覺大模型的訓練難題。
基于 PyTorch DTensor 的張量并行 CNN 訓練可顯著減少內存占用并保持良好的可擴展性。我們預計該方法將充分利用多個 GPU 的算力和互連功能,使感知模型訓練更加普及。
審核編輯:劉清
-
NVIDIA
+關注
關注
14文章
5076瀏覽量
103728 -
gpu
+關注
關注
28文章
4777瀏覽量
129360 -
自動駕駛
+關注
關注
785文章
13932瀏覽量
167013 -
pytorch
+關注
關注
2文章
808瀏覽量
13363
原文標題:使用張量并行技術進行自動駕駛感知模型訓練
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦


MEMS技術在自動駕駛汽車中的應用
Waymo利用谷歌Gemini大模型,研發端到端自動駕駛系統

FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
自動駕駛汽車傳感器有哪些
LeddarTech和Immervision達成合作,加速ADAS和AD感知模型訓練
LeddarTech 和 Immervision 聯合宣布 合作加速 ADAS 和 AD 感知模型訓練







 工商網監
工商網監
評論