 什么是自然語言處理 (NLP)
什么是自然語言處理 (NLP)
一、什么是自然語言處理 (NLP)
自然語言處理(Natural Language Processing, NLP)是人工智能領域中的一個重要分支,它專注于構建能夠理解和生成人類語言的計算機系統。NLP的目標是使計算機能夠像人類一樣理解和處理自然語言文本,從而實現人機交互的流暢和自然。NLP不僅關注理論框架的建立,還側重于實際技術的開發和應用,廣泛應用于法律、醫療、教育、安全、工業、金融等多個領域。
二、NLP的重要性
NLP的重要性體現在多個方面:
- 提升工作效率 :通過自動化處理大量文本數據,NLP技術可以顯著提高工作效率,減少人工干預和錯誤。
- 改善用戶體驗 :在客戶服務、智能助手等領域,NLP技術能夠提供更加智能、個性化的交互體驗。
- 推動技術創新 :NLP作為人工智能的重要組成部分,其發展不斷推動人工智能技術的整體進步。
三、NLP的應用場景
NLP技術在多個領域具有廣泛應用,包括但不限于:
- 機器翻譯 :實現不同語言之間的自動翻譯,打破語言障礙。
- 情感分析 :判斷文本的情感傾向,如積極、消極或中立,用于輿情監測、產品評價等。
- 命名實體識別 :從文本中提取特定類型的實體信息,如人名、地名、組織名等,用于信息抽取、知識圖譜構建等。
- 垃圾郵件檢測 :識別并過濾掉不受歡迎的電子郵件,保護用戶隱私和安全。
- 智能客服 :通過聊天機器人提供自動化的客戶服務,解決用戶問題,提高客戶滿意度。
- 自動完成和預測輸入 :在文本編輯、搜索等場景中,預測用戶輸入的下一個詞或短語,提高輸入效率。
- 文本生成 :生成類似人類寫作的文本,如新聞報道、小說、詩歌等,用于內容創作、廣告營銷等。
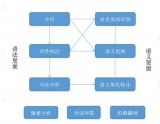
四、NLP的工作原理
NLP技術通過一系列復雜的算法和模型來實現對自然語言文本的處理和理解,主要包括以下幾個步驟:
- 數據預處理 :包括文本清洗、分詞、去停用詞、標準化和特征提取等步驟,為后續的文本處理提供高質量的輸入數據。
- 文本表示 :將文本轉換為計算機可理解的數值形式,常用的文本表示方法包括詞袋模型、詞嵌入等。
- 模型構建 :選擇合適的NLP模型,如傳統機器學習模型(邏輯回歸、樸素貝葉斯等)或深度學習模型(RNN、LSTM、Transformer等),對文本數據進行訓練和學習。
- 結果輸出 :根據訓練好的模型對新的文本數據進行處理,輸出相應的結果,如分類標簽、翻譯文本、摘要等。
五、NLP的主要技術
NLP涵蓋了多種技術和算法,以下是一些關鍵技術:
- 詞嵌入(Word Embedding) :將詞語映射到低維向量空間,使得語義相近的詞語在向量空間中距離較近。常見的詞嵌入算法包括Word2Vec、GloVe和FastText等。
- 序列模型(Sequence Models) :處理序列數據的算法,對于NLP特別重要。RNN和LSTM是常用的序列模型,能夠捕捉自然語言的上下文和語義依賴關系。
- 注意力機制(Attention Mechanism) :用于提取和聚焦于輸入序列中相關部分的技術,廣泛應用于機器翻譯、文本摘要和問答系統等任務。
- Transformer模型 :一種基于自注意力機制的模型架構,能夠同時處理序列中的所有元素,克服了RNN的局限性,在多個NLP任務上取得了優異性能。
- 預訓練語言模型(Pre-trained Language Models) :如BERT、GPT等,通過在大規模文本數據上進行預訓練,學習語言的通用表示,然后應用于各種下游NLP任務。
六、NLP面臨的挑戰
盡管NLP技術取得了顯著進展,但仍面臨諸多挑戰:
- 模型的偏見問題 :由于訓練數據的不平衡或偏見,NLP模型可能會產生不公平的預測結果。
- 環境影響 :NLP模型的訓練需要大量的計算資源和時間,對環境造成一定影響。
- 高昂的成本 :構建和維護高性能的NLP系統需要投入大量的人力和物力資源。
- 模型的不可解釋性 :深度學習模型雖然性能優異,但其決策過程往往難以解釋,不利于信任度的提升。
七、NLP的未來展望
隨著技術的不斷進步和應用的深入,NLP的未來展望充滿希望:
- 多模態融合 :將NLP與計算機視覺、語音識別等技術相結合,實現更加全面的人機交互。
- 低資源語言處理 :針對低資源語言(如少數民族語言)開發更加有效的NLP技術,促進語言多樣性。
- 可解釋性增強 :通過引入可解釋性算法和技術,提高NLP模型的透明度和可信度。### NLP的未來展望(續)
- 個性化與自然化 :隨著技術的進步,NLP系統將更加個性化,能夠根據用戶的習慣、偏好和上下文提供更加自然、貼合需求的交互體驗。這要求NLP系統具備更強的理解和推理能力,以及更靈活的適應性。
- 自動化與智能化 :未來的NLP系統將更加自動化和智能化,能夠自主完成復雜的文本處理任務,減少人工干預。例如,自動化的文檔分類、信息抽取、摘要生成等,將極大地提高工作效率和準確性。
- 跨語言處理 :隨著全球化的深入發展,跨語言處理成為NLP領域的一個重要研究方向。未來的NLP系統將能夠處理多種語言,實現跨語言的文本理解、翻譯和生成,打破語言障礙,促進全球信息的交流和共享。
- 實時性與高效性 :在實時應用場景中,如在線聊天、語音助手等,NLP系統需要具備高效的處理能力和快速的響應速度。未來的NLP技術將不斷優化算法和模型,提高處理速度和效率,以滿足實時交互的需求。
- 隱私與安全 :隨著NLP技術的廣泛應用,隱私和安全問題日益凸顯。未來的NLP系統將更加注重用戶數據的保護,采用加密、匿名化等技術手段,確保用戶隱私的安全。同時,也需要加強對NLP系統的監管和審計,防止濫用和誤用。
- 終身學習 :借鑒人類的學習機制,未來的NLP系統將具備終身學習的能力。它們能夠不斷從新的數據中學習新知識,優化自身性能,適應不斷變化的環境和需求。這種能力將使NLP系統更加靈活和強大,能夠在更廣泛的領域發揮作用。
- 倫理與道德 :隨著NLP技術的深入應用,倫理和道德問題也日益受到關注。未來的NLP系統需要遵循一定的倫理規范和道德準則,確保技術的合理、合法和負責任地使用。這要求開發者、研究者和使用者共同努力,建立健全的倫理框架和監管機制,促進NLP技術的健康發展。
結語
自然語言處理(NLP)作為人工智能領域的一個重要分支,具有廣泛的應用前景和巨大的發展潛力。通過不斷的技術創新和應用實踐,NLP技術將不斷突破現有的局限和挑戰,為人類社會的發展和進步貢獻更多的智慧和力量。然而,我們也應該清醒地認識到NLP技術所面臨的挑戰和問題,并積極尋求解決方案和途徑,以確保技術的健康、可持續和負責任地發展。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
計算機
+關注
關注
19文章
7536瀏覽量
88638 -
人工智能
+關注
關注
1796文章
47666瀏覽量
240278 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13646
發布評論請先 登錄
相關推薦
自然語言處理(NLP)領域的高效方法
訓練越來越大的深度學習模型已經成為過去十年的一個新興趨勢。如下圖所示,模型參數量的不斷增加讓神經網絡的性能越來越好,也產生了一些新的研究方向,但模型的問題也越來越多。
命名實體識別(NER)是自然語言處理(NLP)中的基本任務之一
LSTM網絡是整體思路同樣是先對給定的訓練樣本進行學習,確定模型中的參數,再利用該模型對測試樣本進行預測得到最后的輸出。由于測試輸出的準確性現階段達不到100%,這就意味著,肯定存在一部分錯誤的輸出,這些輸出里很可能就包含類似于上述第二句話這種不符合語法規則的文本。
OpenAI介紹可擴展的,與任務無關的的自然語言處理(NLP)系統
近日,OpenAI 在其官方博客發文介紹了他們最新的自然語言處理(NLP)系統。這個系統是可擴展的、與任務無關的,并且在一系列不同的 NLP 任務中都取得了亮眼的成績。但該方法在計算需

自然語言處理(NLP)知識結構總結
的自然語言處理課程。主要參考書為宗成慶老師的《統計自然語言處理》,雖然很多內容寫的不清楚,但好像中文NLP書籍就這一本全一些,如果想看好的英
回顧2018自然語言處理NLP最全的應用與合作
2018年見證了 NLP 許多新的應用發展。Elvis Saravia 是計算語言學專家,也是2019 計算語言學會年度大會北美分部的項目委員之一。
如何學習自然語言處理NLP詳細學習方法說明
這篇文章是一名自然語言處理(nlp)的初學者,在nlp里摸爬滾打了許久的一些心得,推薦了nlp的學習路線和資料合集,本站極力推薦。
一套新的自然語言處理(NLP)評估基準,名為 SuperGLUE
實現 NLP 的方法有很多,主流的方法大多圍繞多任務學習和語言模型預訓練展開,由此孕育出很多種不同模型,比如 BERT、MT-DNN、ALICE 和 Snorkel MeTaL 等等。在某個模型的基礎上,研究團隊還可以借鑒其它模型的精華或者直接結合兩者。
自然語言處理(NLP)的學習方向
自然語言處理(Natural Language Processing,NLP)是計算機科學領域與人工智能領域中的一個重要方向。它研究人與計算機之間用自然語言進行有效通信的理論和方法。融
自然語言處理(NLP)的優勢、現狀以及其適用范圍
自然語言處理(NLP)在語音和文本方面的改進將助力主流技術的發展。例如以人類自然發音朗讀電子郵件時,如果用戶對電子表格中的數據提出質疑,Excel會自動以圖表和數據透視表的形式回答相關
自然語言處理(NLP)技術不斷突破,谷歌Transformer再升級
后,計算機就可以迅速將它翻譯為 Transformer 是一種基于自注意力機制的新型神經網絡架構,神奇的機器翻譯使得多語種互譯成為可能。 近年來,得益于機器學習的快速發展,自然語言處理(NLP)技術





 工商網監
工商網監
評論