") Yuan2.0千億大模型在通用服務(wù)器NF8260G7上的推理部署
Yuan2.0千億大模型在通用服務(wù)器NF8260G7上的推理部署
巨量模型的智能生產(chǎn)力正在逐步滲透到各行各業(yè),但它們的部署和運(yùn)行通常需要專(zhuān)用的AI加速卡,能否在CPU上運(yùn)行千億大模型,對(duì)千行百業(yè)智能化轉(zhuǎn)型的深化與普惠至關(guān)重要。
日前,浪潮信息研發(fā)工程師基于2U4路旗艦通用服務(wù)器NF8260G7,通過(guò)張量并行、模型壓縮量化等技術(shù),解決了通用服務(wù)器的CPU計(jì)算資源不足、內(nèi)存帶寬瓶頸、缺乏大規(guī)模并行計(jì)算環(huán)境等問(wèn)題,在業(yè)內(nèi)首次實(shí)現(xiàn)服務(wù)器僅依靠4顆CPU即可運(yùn)行千億參數(shù)“源2.0”大模型。該方案建設(shè)成本更低,首次投入可節(jié)約80%以上建設(shè)成本,且通用服務(wù)器功耗更低,運(yùn)維更便捷,能夠有效降低客戶(hù)TCO。
大模型推理的硬件需求:內(nèi)存與帶寬的雙重考驗(yàn)
當(dāng)前,大模型的推理計(jì)算面臨多方面的挑戰(zhàn),制約了大模型服務(wù)成本的降低和應(yīng)用落地。
首先是對(duì)內(nèi)存容量的需求。大模型的推理過(guò)程中,需要將全部的模型權(quán)重參數(shù)、計(jì)算過(guò)程中的KV Cache等數(shù)據(jù)存放在內(nèi)存中,一般需要占用相當(dāng)于模型參數(shù)量2-3倍的內(nèi)存空間。隨著業(yè)界LLM的網(wǎng)絡(luò)架構(gòu)從GPT架構(gòu)走向MOE架構(gòu),主流開(kāi)源模型的尺寸越來(lái)越大,千億及以上參數(shù)的模型已經(jīng)成為主流,運(yùn)行一個(gè)千億大模型(100B),則需要200-300GB的顯存空間。
其次是對(duì)計(jì)算和內(nèi)存讀寫(xiě)帶寬的需求。大模型的推理主要分為預(yù)填充和解碼兩個(gè)階段。預(yù)填充階段把Prompt一次性輸入給模型進(jìn)行計(jì)算,對(duì)顯存的需求更大;解碼階段,每次推理僅生成1個(gè)token,計(jì)算訪(fǎng)存較低,對(duì)內(nèi)存帶寬的需求更大。因此,千億大模型的實(shí)時(shí)推理,計(jì)算設(shè)備需要具備較高的計(jì)算能力,以及較高的存儲(chǔ)單元到計(jì)算單元的數(shù)據(jù)搬運(yùn)效率。
NF8260G7作為一款采用高密度設(shè)計(jì)的2U4路服務(wù)器,支持16TB大內(nèi)存容量,配置了4顆具有AMX(高級(jí)矩陣擴(kuò)展)的AI加速功能的英特爾至強(qiáng)處理器,內(nèi)存帶寬極限值為1200GB/s。盡管NF8260G7服務(wù)器可以輕松滿(mǎn)足千億大模型推理的內(nèi)存需求,甚至于萬(wàn)億參數(shù)的MOE架構(gòu)大模型推理的內(nèi)存需求。但是,按照BF16的精度計(jì)算,千億參數(shù)大模型運(yùn)行時(shí)延要小于100ms,內(nèi)存與計(jì)算單元之間的通信帶寬至少要在2TB/s以上。因此,要在NF8260G7上實(shí)現(xiàn)千億大模型的高效運(yùn)行,僅靠硬件升級(jí)還遠(yuǎn)遠(yuǎn)不夠,硬件資源與軟件算法協(xié)同優(yōu)化至關(guān)重要。
 張量并行+NF4量化,實(shí)現(xiàn)千億模型極致優(yōu)化
張量并行+NF4量化,實(shí)現(xiàn)千億模型極致優(yōu)化
Yuan2.0-102B是浪潮信息發(fā)布的新一代基礎(chǔ)語(yǔ)言大模型,參數(shù)量為1026億,通過(guò)提出全新的局部注意力過(guò)濾增強(qiáng)機(jī)制(LFA:Localized Filtering-based Attention),有效提升了自然語(yǔ)言的關(guān)聯(lián)語(yǔ)義理解能力。
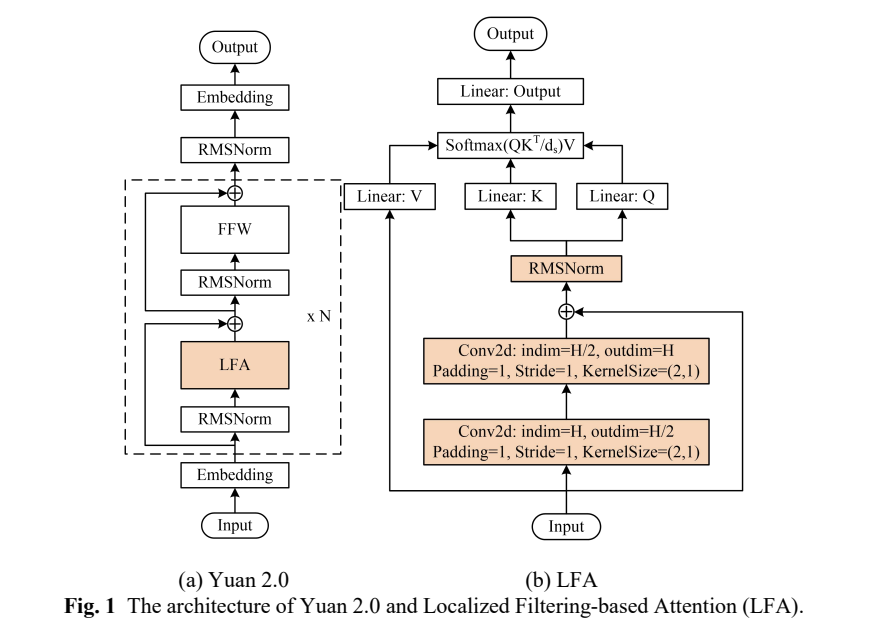
為了盡可能提升Yuan2.0-102B模型在NF8260G7服務(wù)器上的推理計(jì)算效率,浪潮信息算法工程師采用了張量并行(tensor parallel)策略。該策略改變了傳統(tǒng)CPU服務(wù)器串行運(yùn)行的模式,把Yuan2.0-102B模型中的注意力層和前饋層的矩陣計(jì)算分別拆分到多個(gè)處理器,實(shí)現(xiàn)同時(shí)使用4顆CPU進(jìn)行計(jì)算加速。然而,張量并行對(duì)模型參數(shù)的切分粒度較細(xì),要求CPU在每次張量計(jì)算后進(jìn)行數(shù)據(jù)同步,增加了對(duì)CPU間通信帶寬的需求。在傳統(tǒng)的使用多個(gè)基于PCIe互聯(lián)的AI芯片進(jìn)行張量并行時(shí),通信占比往往會(huì)高達(dá)50%,也就是AI芯片有50%的時(shí)間都在等待數(shù)據(jù)傳輸,極大影響了推理效率。
NF8260G7服務(wù)器的4顆CPU通過(guò)全鏈路UPI(Ultra Path Interconnect)總線(xiàn)互連,該設(shè)計(jì)帶來(lái)了兩個(gè)優(yōu)勢(shì):首先,全鏈路UPI互連允許任意兩個(gè)CPU之間直接進(jìn)行數(shù)據(jù)傳輸,減少了通信延遲;其次,全鏈路UPI互連提供了高傳輸速率,高達(dá)16GT/s(Giga Transfers per second),遠(yuǎn)高于PCIe的通信帶寬,保障了4顆處理器間高效的數(shù)據(jù)傳輸,從而支持張量并行策略下的數(shù)據(jù)同步需求。
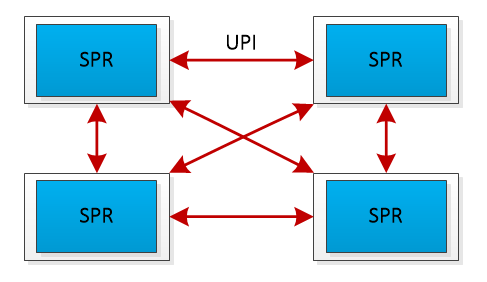
UPI總線(xiàn)互連示意圖
為了進(jìn)一步提升Yuan2.0-102B模型在NF8260G7服務(wù)器上的推理效率,浪潮信息算法工程師還采用了NF4量化技術(shù),來(lái)進(jìn)一步提升推理的解碼效率,從而達(dá)到實(shí)時(shí)推理的解碼需求。NF4(4位NormalFloat)是一種分位數(shù)量化方法,適合于正態(tài)分布的數(shù)據(jù)。它通過(guò)確保量化區(qū)間內(nèi)輸入張量的值數(shù)量相等,來(lái)實(shí)現(xiàn)對(duì)數(shù)據(jù)的最優(yōu)量化。由于大型語(yǔ)言模型(LLM)的權(quán)重通常呈現(xiàn)零中心的正態(tài)分布,NF4量化技術(shù)可以通過(guò)調(diào)整標(biāo)準(zhǔn)差來(lái)適配量化數(shù)據(jù)類(lèi)型的范圍,從而獲得比傳統(tǒng)的4位整數(shù)或4位浮點(diǎn)數(shù)量化(這些量化方法的數(shù)據(jù)間隔通常是平均分布或指數(shù)分布的)更高的精度。
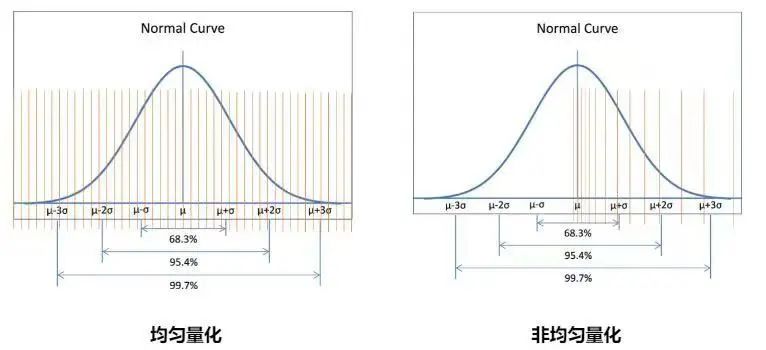
INT4數(shù)據(jù)類(lèi)型與NF4數(shù)據(jù)類(lèi)型對(duì)比
為了進(jìn)一步壓縮Yuan2.0-102B模型的權(quán)重參數(shù),浪潮信息算法工程師采用了嵌套量化(Double Quant)技術(shù),這是在NF4量化基礎(chǔ)上進(jìn)行的二次量化。NF4量化后,由于會(huì)產(chǎn)生大量的scale參數(shù),如果使用32位浮點(diǎn)數(shù)(FP32)存儲(chǔ),會(huì)占用大量的內(nèi)存空間。若以64個(gè)參數(shù)作為一個(gè)量化塊(block size=64)來(lái)計(jì)算,對(duì)于一個(gè)千億參數(shù)的大模型,僅存儲(chǔ)scale參數(shù)就需要額外的6GB內(nèi)存:
(100B/64) * 4 = 6GB
為了減少內(nèi)存占用,浪潮信息工程師通過(guò)將這些scale參數(shù)量化到8位浮點(diǎn)數(shù)(FP8),可以顯著減少所需的存儲(chǔ)空間。在采用256為量化塊大小(block size=256)的情況下,存儲(chǔ)所有scale參數(shù)所需的額外空間僅為1.57GB:
(100B/64/256)* 4 + (100B/64) * 1 = 1.57GB
通過(guò)嵌套量化,模型的每個(gè)權(quán)重參數(shù)最終僅占用4字節(jié)的內(nèi)存空間,這比原始的FP32存儲(chǔ)方式減少了大量的內(nèi)存占用,從內(nèi)存到CPU的數(shù)據(jù)搬運(yùn)效率提高了4倍。這樣的優(yōu)化顯著減輕了內(nèi)存帶寬對(duì)Yuan2.0-102B模型推理解碼效率的限制,從而進(jìn)一步提升了模型的推理性能。
高算效,低成本
通過(guò)在NF8260G7服務(wù)器上應(yīng)用張量并行和NF4量化技術(shù),浪潮信息工程師成功實(shí)現(xiàn)了千億大模型Yuan2.0-102B的實(shí)時(shí)推理,根據(jù)性能分析(profiling)的結(jié)果,可以清晰地看到模型中不同部分的計(jì)算時(shí)間分布:線(xiàn)性層運(yùn)行時(shí)間占比50%,卷積運(yùn)行時(shí)間占比20%,聚合通信時(shí)間占比20%,其它計(jì)算占比10%。在整個(gè)推理過(guò)程中,計(jì)算時(shí)間占比達(dá)到了80%,和此前相比,計(jì)算時(shí)間占比提升30%,大幅提升了算力利用率。
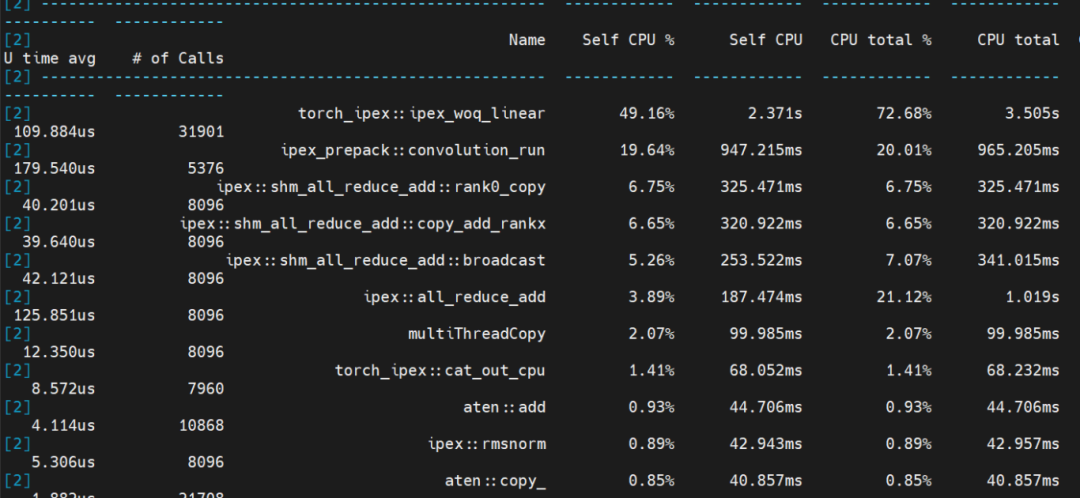
Yuan2.0-102B模型推理性能分析(profiling)結(jié)果圖
浪潮信息基于通用服務(wù)器NF8260G7的軟硬件協(xié)同創(chuàng)新,為千億參數(shù)AI大模型在通用服務(wù)器的推理部署,提供了性能更強(qiáng),成本更經(jīng)濟(jì)的選擇,讓AI大模型應(yīng)用可以與云、大數(shù)據(jù)、數(shù)據(jù)庫(kù)等應(yīng)用能夠?qū)崿F(xiàn)更緊密的融合,從而充分釋放人工智能在千行百業(yè)中的創(chuàng)新活力。
-
cpu
+關(guān)注
關(guān)注
68文章
10902瀏覽量
213006 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9303瀏覽量
86061 -
浪潮
+關(guān)注
關(guān)注
1文章
468瀏覽量
23945 -
大模型
+關(guān)注
關(guān)注
2文章
2545瀏覽量
3164
原文標(biāo)題:服務(wù)器僅靠4顆CPU運(yùn)行千億大模型的“算法秘籍”
文章出處:【微信號(hào):浪潮AIHPC,微信公眾號(hào):浪潮AIHPC】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于spring boot的linux服務(wù)器部署方法
OPC服務(wù)器開(kāi)發(fā)淺談 — 服務(wù)器模型
用tflite接口調(diào)用tensorflow模型進(jìn)行推理
通過(guò)Cortex來(lái)非常方便的部署PyTorch模型
Jenkins遠(yuǎn)程部署Linux服務(wù)器的過(guò)程
浪潮宣布支持NVIDIA的AI服務(wù)器NF5488M5-D和NF5488A5全球量產(chǎn)供貨
浪潮AI服務(wù)器NF5488A5的實(shí)測(cè)數(shù)據(jù)分享,單機(jī)最大推理路數(shù)提升88%

使用MIG和Kubernetes部署Triton推理服務(wù)器
騰訊云TI平臺(tái)利用NVIDIA Triton推理服務(wù)器構(gòu)造不同AI應(yīng)用場(chǎng)景需求
如何使用NVIDIA Triton 推理服務(wù)器來(lái)運(yùn)行推理管道
浪潮信息聯(lián)合英特爾發(fā)布新一代AI服務(wù)器NF5698G7
浪潮信息NF5468服務(wù)器LLaMA訓(xùn)練性能
浪潮信息NF5468系列AI服務(wù)器率先支持英偉達(dá)最新推出的L40S GPU
源2.0適配FastChat框架,企業(yè)快速本地化部署大模型對(duì)話(huà)平臺(tái)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論