 如何在一個集成中使用多種模型的使用向導
如何在一個集成中使用多種模型的使用向導
在統計學和機器學習領域,集成方法(ensemble method)使用多種學習算法以獲得更好的預測性能(相比單獨使用其中任何一種算法)。和統計力學中的統計集成(通常是無窮集合)不同,一個機器學習集成僅由一個離散的可選模型的離散集合組成,但通常擁有更加靈活的結構 [1]。
使用集成的主要動機是在發現新的假設,該假設不一定存在于構成模型的假設空間中。從經驗的角度看,當模型具有顯著的多樣性時,集成方法傾向于得到更好的結果 [2]。
動機
在一個大型機器學習競賽的比賽結果中,最好的結果通常是由模型的集成而不是由單個模型得到的。例如,ILSVRC2015 的得分最高的單個模型架構得到了第 13 名的成績。而第 1 到 12 名都使用了不同類型的模型集成。
我目前并沒有發現有任何的教程或文檔教人們如何在一個集成中使用多種模型,因此我決定自己做一個這方面的使用向導。
我將使用 Keras,具體來說是它的功能性 API,以從相對知名的論文中重建三種小型 CNN(相較于 ResNet50、Inception 等而言)。我將在 CIFAR-10 數據集上獨立地訓練每個模型 [3]。然后使用測試集評估每個模型。之后,我會將所有三個模型組成一個集合,并進行評估。通常按照預期,這個集成相比單獨使用其中任何一個模型,在測試集上能獲得更好的性能。
有很多種不同類型的集成:其中一種是堆疊(stacking)。這種類型更加通用并且在理論上可以表征任何其它的集成技術。堆疊涉及訓練一個學習算法結合多種其它學習算法的預測 [1]。對于這個示例,我將使用堆疊的最簡單的一種形式,其中涉及對集成的模型輸出取平均值。由于取平均過程不包含任何參數,這種集成不需要訓練(只需要訓練模型)。
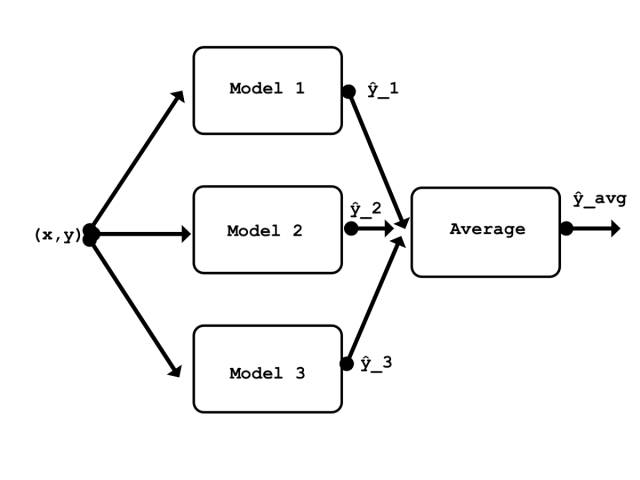
本文介紹的集成的簡要結構
準備數據
首先,導入類和函數:
-
fromkeras.modelsimportModel,Input
-
fromkeras.layersimportConv2D,MaxPooling2D,GlobalAveragePooling2D,Activation,Average,Dropout
-
fromkeras.utilsimportto_categorical
-
fromkeras.lossesimportcategorical_crossentropy
-
fromkeras.callbacksimportModelCheckpoint,TensorBoard
-
fromkeras.optimizersimportAdam
-
fromkeras.datasetsimportcifar10
-
importnumpyasnp
我使用的數據集是 CIFAR-10,因為很容易找到在這個數據集上工作得很好的架構的相關論文。使用一個流行的數據集還可以令這個案例容易復現。
以下是數據集的導入代碼。訓練數據和測試數據都已經歸一化。訓練標簽向量被轉換成一個 one-hot 矩陣。不需要轉換測試標簽向量,因為它不會在訓練中使用。
-
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
-
x_train = x_train /255.
-
x_test = x_test /255.
-
y_train = to_categorical(y_train, num_classes=10)
數據集由 6 萬張 10 個類別的 32x32 的 RGB 圖像組成。其中 5 萬張用于訓練/驗證,其它 1 萬張用于測試。
-
print('x_train shape: {} |
-
y_train shape: {}\nx_test shape : {} |
-
y_test shape : {}'.format(x_train.shape, y_train.shape, x_test.shape, y_test.shape))
>>> x_train shape: (50000, 32, 32, 3) | y_train shape: (50000, 10)
>>> x_test shape : (10000, 32, 32, 3) | y_test shape : (10000, 1)
由于三個模型使用的是相同類型的數據,定義單個用于所有模型的輸入層是合理的。
-
input_shape = x_train[0,:,:,:].shape
-
model_input =Input(shape=input_shape)
第一個模型:ConvPool-CNN-C
第一個將要訓練的模型是 ConvPool-CNN-C[4]。它使用了常見的模式,即每個卷積層連接一個池化層。唯一一個對一些人來說可能不熟悉的細節是其最后的層。它使用的并不是多個全連接層,而是一個全局平均池化層(global average pooling layer)。
以下是關于全局池化層的工作方式的簡介。最后的卷積層 Conv2D(10,(1,1)) 輸出和 10 個輸出類別相關的 10 個特征圖。然后 GlobalAveragePooling2D() 層計算這 10 個特征圖的空間平均(spatial average),意味著其輸出是一個維度為 10 的向量。之后,對這個向量應用一個 softmax 激活函數。如你所見,這個方法在某種程度上類似于在模型的頂部使用全連接層。可以在這篇論文 [5] 中查看更多關于全局池化層的內容。
重要事項:不要對最后的 Conv2D(10,(1,1)) 層的輸出直接應用激活函數,因為這個層的輸出需要先輸入 GlobalAveragePooling2D()。
-
defconv_pool_cnn(model_input):
-
x =Conv2D(96, kernel_size=(3,3), activation='relu', padding = 'same')(model_input)
-
x =Conv2D(96, (3,3), activation='relu', padding ='same')(x)
-
x =Conv2D(96, (3,3), activation='relu', padding ='same')(x)
-
x =MaxPooling2D(pool_size=(3,3), strides =2)(x)
-
x =Conv2D(192, (3,3), activation='relu', padding ='same')(x)
-
x =Conv2D(192, (3,3), activation='relu', padding ='same')(x)
-
x =Conv2D(192, (3,3), activation='relu', padding ='same')(x)
-
x =MaxPooling2D(pool_size=(3,3), strides =2)(x)
-
x =Conv2D(192, (3,3), activation='relu', padding ='same')(x)
-
x =Conv2D(192, (1,1), activation='relu')(x)
-
x =Conv2D(10, (1,1))(x)
-
x =GlobalAveragePooling2D()(x)
-
x =Activation(activation='softmax')(x)
-
model =Model(model_input, x, name='conv_pool_cnn')
-
returnmodel
用具體例子解釋該模型
-
conv_pool_cnn_model = conv_pool_cnn(model_input)
為了簡單起見,每個模型都使用相同的參數進行編譯和訓練。其中,epoch 數等于 20、批尺寸等于 32(每個 epoch 進行 1250 次迭代)的參數設置能使三個模型都找到局部極小值。隨機選擇訓練集的 20% 作為驗證集。
-
defcompile_and_train(model, num_epochs):
-
model.compile(loss=categorical_crossentropy, optimizer=Adam(), metrics=['acc'])
-
filepath ='weights/'+ model.name +'.{epoch:02d}-{loss:.2f}.hdf5'
-
checkpoint =ModelCheckpoint(filepath, monitor='loss', verbose=0, save_weights_only=True, save_best_only=True, mode='auto', period=1)
-
tensor_board =TensorBoard(log_dir='logs/', histogram_freq=0, batch_size=32)
-
history = model.fit(x=x_train, y=y_train, batch_size=32, epochs=num_epochs, verbose=1, callbacks=[checkpoint, tensor_board], validation_split=0.2)
-
returnhistory
大約需要每 epoch1 分鐘的時間訓練這個(以及下一個)模型,我們使用了單個 Tesla K80 GPU。如果你使用的是 CPU,可能需要花較多的時間。
-
_ = compile_and_train(conv_pool_cnn_model, num_epochs=20)
該模型達到了大約 79% 的驗證準確率。
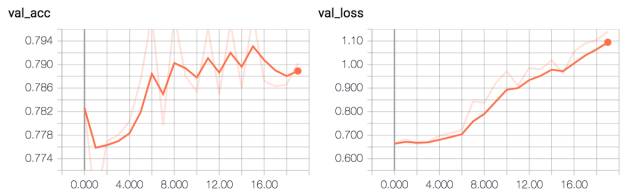
ConvPool-CNN-C 驗證準確率和損失
通過計算測試集的誤差率對模型進行評估。
-
defevaluate_error(model):
-
pred=model.predict(x_test,batch_size=32)
-
pred=np.argmax(pred,axis=1)
-
pred=np.expand_dims(pred,axis=1)# make same shape as y_test
-
error=np.sum(np.not_equal(pred,y_test))/y_test.shape[0]
-
returnerror
-
evaluate_error(conv_pool_cnn_model)
>>> 0.2414
第二個模型:ALL-CNN-C
下一個模型,ALL-CNN-C,來自同一篇論文 [4]。這個模型和上一個很類似。唯一的區別是用步幅為 2 的卷積層取代了最大池化層。再次,需要注意,在 Conv2D(10,(1,1)) 層之后不要立刻應用激活函數,如果在該層之后應用了 ReLU 激活函數,會導致訓練失敗。
-
defall_cnn(model_input):
-
x=Conv2D(96,kernel_size=(3,3),activation='relu',padding='same')(model_input)
-
x=Conv2D(96,(3,3),activation='relu',padding='same')(x)
-
x=Conv2D(96,(3,3),activation='relu',padding='same',strides=2)(x)
-
x=Conv2D(192,(3,3),activation='relu',padding='same')(x)
-
x=Conv2D(192,(3,3),activation='relu',padding='same')(x)
-
x=Conv2D(192,(3,3),activation='relu',padding='same',strides=2)(x)
-
x=Conv2D(192,(3,3),activation='relu',padding='same')(x)
-
x=Conv2D(192,(1,1),activation='relu')(x)
-
x=Conv2D(10,(1,1))(x)
-
x=GlobalAveragePooling2D()(x)
-
x=Activation(activation='softmax')(x)
-
model=Model(model_input,x,name='all_cnn')
-
returnmodel
-
all_cnn_model=all_cnn(model_input)
-
_=compile_and_train(all_cnn_model,num_epochs=20)
該模型收斂到了大約 75% 的驗證準確率。
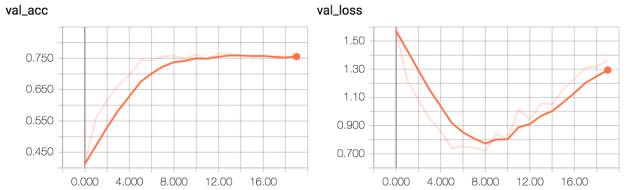
ConvPool-CNN-C 驗證準確率和損失
由于這兩個模型很相似,誤差率差別不大。
-
evaluate_error(all_cnn_model)
>>> 0.26090000000000002
第三個模型:Network In Network CNN
第三個 CNN 是 Network In Network CNN[5]。這個模型來自引入了全局池化層的論文。它比之前的兩個模型更小,因此其訓練速度更快。(再提醒一次,不要在最后的卷積層之后使用 ReLU 函數!)
相較于在 MLP 卷積層中使用多層感知機,我使用的是 1x1 卷積核的卷積層。從而需要優化的參數變得更少,訓練速度進一步加快,并且還獲得了更好的結果(當使用全連接層的時候無法獲得高于 50% 的驗證準確率)。該論文中稱,MLP 卷積層中應用的函數等價于在普通卷積層上的級聯跨通道參數化池化(cascaded cross channel parametric pooling),其中依次等價于一個 1x1 卷積核的卷積層。如果這個結論有錯誤,歡迎指正。
-
defnin_cnn(model_input):
-
#mlpconv block 1
-
x=Conv2D(32,(5,5),activation='relu',padding='valid')(model_input)
-
x=Conv2D(32,(1,1),activation='relu')(x)
-
x=Conv2D(32,(1,1),activation='relu')(x)
-
x=MaxPooling2D((2,2))(x)
-
x=Dropout(0.5)(x)
-
#mlpconv block2
-
x=Conv2D(64,(3,3),activation='relu',padding='valid')(x)
-
x=Conv2D(64,(1,1),activation='relu')(x)
-
x=Conv2D(64,(1,1),activation='relu')(x)
-
x=MaxPooling2D((2,2))(x)
-
x=Dropout(0.5)(x)
-
#mlpconv block3
-
x=Conv2D(128,(3,3),activation='relu',padding='valid')(x)
-
x=Conv2D(32,(1,1),activation='relu')(x)
-
x=Conv2D(10,(1,1))(x)
-
x=GlobalAveragePooling2D()(x)
-
x=Activation(activation='softmax')(x)
-
model=Model(model_input,x,name='nin_cnn')
-
returnmodel
-
nin_cnn_model=nin_cnn(model_input)
這個模型的訓練速度快得多,在我的機器上每個 epoch 只要 15 秒就能完成。
-
_=compile_and_train(nin_cnn_model,num_epochs=20)
該模型達到了大約 65% 的驗證準確率。
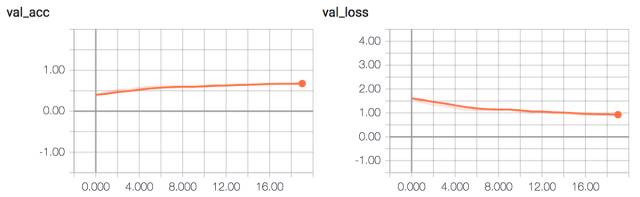
NIN-CNN 驗證準確率和損失
這個模型比之前的兩個模型簡單得多,因此其誤差率要高一點。
-
evaluate_error(nin_cnn_model)
>>> 0. 0.31640000000000001
三個模型的集成
現在將這三個模型組合成一個集成。
所有三個模型都被重新實例化并加載了最佳的已保存權重。
-
conv_pool_cnn_model=conv_pool_cnn(model_input)
-
all_cnn_model=all_cnn(model_input)
-
nin_cnn_model=nin_cnn(model_input)
-
conv_pool_cnn_model.load_weights('weights/conv_pool_cnn.29-0.10.hdf5')
-
all_cnn_model.load_weights('weights/all_cnn.30-0.08.hdf5')
-
nin_cnn_model.load_weights('weights/nin_cnn.30-0.93.hdf5')
-
models=[conv_pool_cnn_model,all_cnn_model,nin_cnn_model]
集成模型的定義是很直接的。它使用了所有模型共享的輸入層。在頂部的層中,該集成通過使用 Average() 合并層計算三個模型輸出的平均值。
-
defensemble(models,model_input):
-
outputs=[model.outputs[0]formodelinmodels]
-
y=Average()(outputs)
-
model=Model(model_input,y,name='ensemble')
-
returnmodel
-
ensemble_model=ensemble(models,model_input)
不出所料,相比于任何單一模型,集成有著更低的誤差率。
-
evaluate_error(ensemble_model)
>>> 0.2049
其他可能的集成
為了完整性,我們可以查看由兩個模型組合組成的集成的性能。相比于單一模型,前者有更低的誤差率。
-
pair_A=[conv_pool_cnn_model,all_cnn_model]
-
pair_B=[conv_pool_cnn_model,nin_cnn_model]
-
pair_C=[all_cnn_model,nin_cnn_model]
-
pair_A_ensemble_model=ensemble(pair_A,model_input)
-
evaluate_error(pair_A_ensemble_model)
>>> 0.21199999999999999
-
pair_B_ensemble_model=ensemble(pair_B,model_input)
-
evaluate_error(pair_B_ensemble_model)
>>> 0.22819999999999999
-
pair_C_ensemble_model=ensemble(pair_C,model_input)
-
evaluate_error(pair_C_ensemble_model)
>>>0.2447
結論
重申一下介紹中的內容:每個模型有其自身的缺陷。使用集成背后的原因是通過堆疊表征了關于數據的不同假設的不同模型,我們可以找到一個更好的假設,它不在一個從其構建集成的模型的假設空間之中。
與在大多數情況下使用單個模型相比,使用一個非常基礎的集成實現了更低的誤差率。這證明了集成的有效性。
當然,在使用集成處理你的機器學習任務時,需要牢記一些實際的考慮。由于集成意味著同時堆棧多個模型,這也意味著輸入數據需要前向傳播到每個模型。這增加了需要被執行的計算量,以及最終的評估(預測)時間。如果你在研究或 Kaggle 競賽中使用集成,增加的評估時間并不重要,但是在設計一個商業化產品時卻非常關鍵。另一個考慮是最后的模型增加的大小,它會再次成為商業化產品中集成使用的限制性因素。
參考文獻
1. Ensemble Learning. (n.d.). In Wikipedia. Retrieved December 12, 2017, from https://en.wikipedia.org/wiki/Ensemble_learning
2. D. Opitz and R. Maclin (1999)「Popular Ensemble Methods: An Empirical Study」, Volume 11, pages 169–198 (http://jair.org/papers/paper614.html)
3. Learning Multiple Layers of Features from Tiny Images, Alex Krizhevsky, 2009.
4. Striving for Simplicity: The All Convolutional Net:arXiv:1412.6806v3 [cs.LG]
5. Network In Network:arXiv:1312.4400v3 [cs.NE]
-
集成
+關注
關注
1文章
176瀏覽量
30316 -
keras
+關注
關注
2文章
20瀏覽量
6096
原文標題:如何使用Keras集成多個卷積網絡并實現共同預測
文章出處:【微信號:gh_ecbcc3b6eabf,微信公眾號:人工智能和機器人研究院】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何在Windows中使用MTP協議
如何在RS-485網絡中使用MSP430和MSP432 eUSCI和USCI模塊

如何在顯示器設計中使用TPS6598x I2C控制TUSB564
將amc1200 SPICE模型轉成PSPICE模型后 無法在ORCAD16.5中使用,為什么?
請問cmakelists中的變量如何在程序中使用?
工業計算機是什么?如何在不同行業中使用?






 工商網監
工商網監
評論