 揭示大模型剪枝技術的原理與發展
揭示大模型剪枝技術的原理與發展
當你聽到「剪枝」二字,或許會聯想到園丁修整枝葉的情景。而在 AI 大模型領域,這個詞有著特殊的含義 —— 它是一種通過“精簡”來提升大模型效率的關鍵技術。隨著 GPT、LLaMA 等大模型規模的持續膨脹,如何在保持性能的同時降低資源消耗,已成為亟待解決的難題。本文將揭示大模型剪枝技術的原理與發展,帶你一次性讀懂剪枝。
隨著人工智能的快速發展,大模型以其卓越的性能在眾多領域中占據了重要地位。然而,大模型驚人的參數規模也帶來了一系列挑戰,如高昂的訓練成本、巨大的存儲需求和推理時的計算負擔。為了解決這些問題,大模型剪枝技術應運而生,成為壓縮大模型的關鍵手段。本文將簡要介紹大模型剪枝技術的背景及原理、代表性方法和研究進展。
背景及原理
當今大模型的“身軀”越來越龐大,對資源的需求也日益增加。如 LLaMA 3.1,且不說其訓練算力高達 24000塊 H100,訓練數據量高達 15T tokens(Qwen 2.5 在 18T tokens 的數據集上進行了預訓練,成為目前訓練數據最多的開源大模型),單看表 1 和表 2 中 LLaMA 3.1 在推理和微調時的內存需求,對普通用戶而言就是難以承受之重。這些龐大的需求不僅對硬件資源提出了極高的要求,也限制了模型的可擴展性和實用性。大模型剪枝技術通過減少模型中的參數數量,旨在降低這些需求,同時盡量保持模型的性能。
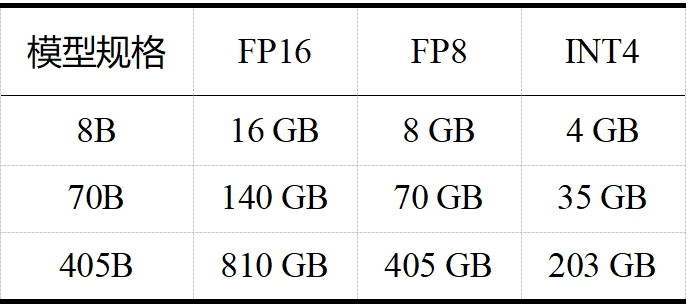
表 1 LLaMA 3.1 推理內存需求(不包括 KV 緩存)
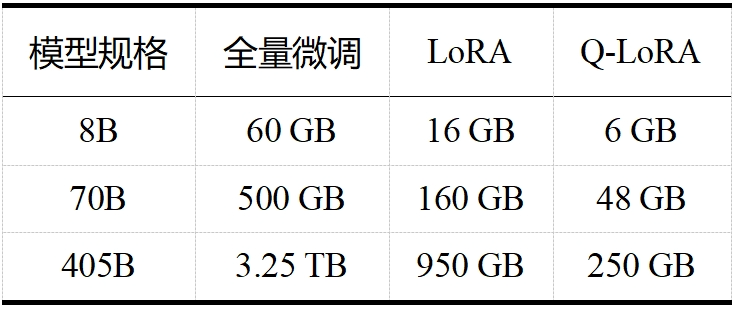
表 2 LLaMA 3.1 微調內存需求
剪枝“流派”的開山鼻祖是圖靈獎得主、深度學習“三巨頭”之一 Yann LeCun,他在 1989 年 NeurIPS 會議上發表的《Optimal Brain Damage》[1]是第一篇剪枝工作。后來剪枝“流派”逐漸開枝散葉,如今可主要分為兩大類:非結構化剪枝和結構化剪枝。非結構化剪枝通過移除單個權重或神經元得到稀疏權重矩陣,這種方法易于實現且性能指標較高,但需要專門的硬件或軟件支持來加速模型;結構化剪枝通過去除基于特定規則的連接來實現,如層級剪枝、塊級剪枝等,這種方法不需要專門的軟硬件支持,但算法更為復雜。
兩類剪枝方法在大模型上都有很多的嘗試和應用,但考慮到通用性,我們主要關注結構化剪枝,本文的第二部分也將主要介紹 LLM 結構化剪枝的經典文章 LLM-Pruner。
下面談一談剪枝的理論基礎。首先,所謂的理論基礎只是暫時的,在一個高速發展的學科中,很難確保今天的理論不會被明天的實驗推翻。在傳統上,人們一直認為剪枝的基礎是 DNN 的過參數化,即深度神經網絡參數比擬合訓練數據所需參數更多,可以剪去一部分以降低網絡復雜度而盡量不影響其性能。 在 2019 年,有學者提出了彩票假設(ICLR 2019 best paper)[2]:一個隨機初始化的神經網絡里包括一個子網絡,當該子網絡被單獨訓練時,能在最多相同迭代次數后達到原始網絡訓練后的性能——就好比一堆彩票中存在一個中獎子集,只要買了這個子集就能獲得最大收益。 隨后,又有學者在《What’sHiddenin a Randomly Weighted Neural Network?》中提出了“近似加強版”彩票假設(CVPR 2020)[3]:在一個隨機權重的足夠過參數化的神經網絡中,存在一個子網絡,無需訓練,其性能與相同參數量訓練過的網絡相當。 再隨后,又有學者聲稱自己證明了這個“近似加強版”的彩票假設,并在標題里宣稱 Pruning is all you need(ICML 2020)[4]。也就是說,如圖 1 所示,以后不需要訓練了,我們只用找一個足夠大的網絡,剪啊剪啊就能得到一個性能很好的子網絡。這個說法如果成立當然是極好的,因為基于梯度的優化算法訓練時間長,且是次優的,但問題在于缺乏有效的純剪枝算法,所以目前剪枝的基本流程還是:訓練、剪枝、微調。另外,作者是用二值小網絡+推廣證明的,太過理想化,而且沒有考慮非線性的情況。近年來,雖然彩票假設及其衍生理論在一些研究領域取得了進展,例如圖中獎彩票(KDD 2023)[5]和對偶彩票假設(ICLR 2022)[6],但在大模型領域,我們尚未觀察到具有顯著影響力的研究工作。

圖 1 LLaMA 3.1 微調內存需求
代表性方法:LLM-Pruner
本節將以首個針對大模型的結構化剪枝框架——LLM-Pruner(NeurIPS 2023)[7]為例,介紹大模型剪枝的基本流程。該框架特點為任務無關的壓縮、數據需求量少、快速和全自動操作,主要包括以下三個步驟:(1)分組階段
本階段的主要工作是根據依賴性準則,將 LLM 中互相依賴的神經元劃分為一組。依賴性準則為:若 i 是 j 的唯一前驅,則 j 依賴于 i;若 j 是 i 的唯一后繼,則 i 依賴于 j。在具體操作中,需要分別將網絡中每個神經元作為初始節點,依賴關系沿方向傳導,傳導過程中遍歷的神經元為一組,一組需同時剪枝。以圖 2 中 Group Type B(即 MHA,多頭注意力)為例,從 Head 1 開始傳導,Head 1 是上面兩個虛線圈神經元的唯一前驅,是下面六個虛線圈神經元的唯一后繼,它們都依賴于 Head 1,故被劃分為一組。
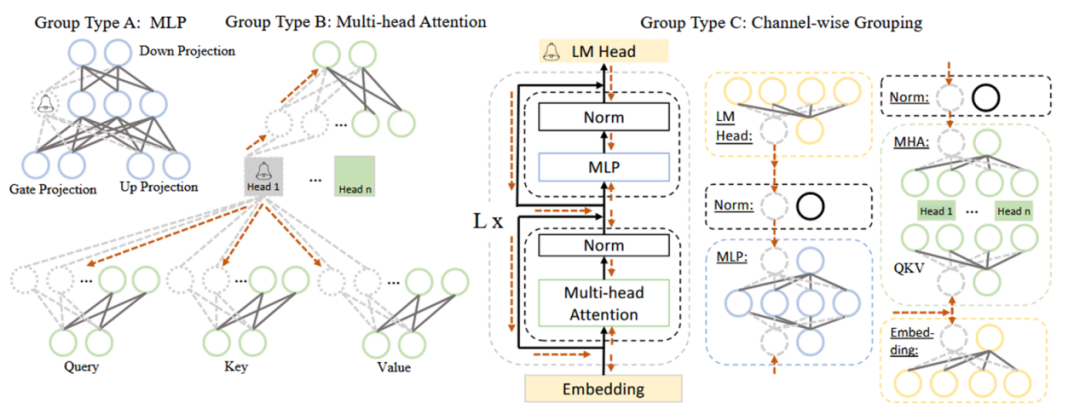
圖 2 LLaMA 中耦合結構的簡化示例 (2)評估階段
本階段的主要工作是根據重要性準則評估每個組對模型整體性能的貢獻,貢獻小的組將被修剪。常見的重要性準則有:L1 范數(向量中各元素絕對值之和)、L2 范數(向量中各元素平方和的開平方)、損失函數的 Taylor 展開一階項、損失函數的 Taylor 展開二階項等。LLM-Pruner 采用損失函數的 Taylor 展開來計算重要性,并提出了兩條計算組重要性的路徑:權重向量級別和單個參數級別。
權重向量級別的重要性公式如下所示, 代表每個神經元的權重向量,H 是 Hessian 矩陣, 表示 next-token prediction loss。一般來說由于模型在訓練數據集上已經收斂,即 , 所以一階項通常為 0 。然而,由于 LLM-Pruner 所用數據集 D 并不是原始訓練數據,故 。同時,由于 Hessian 矩陣的計算復雜度過高, 所以只計算了一階項。
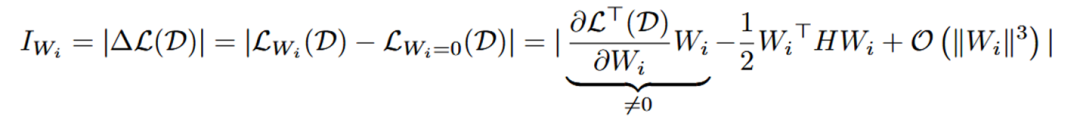
單個參數級別的重要性公式如下所示, 內的每個參數都被獨立地評估其重要性,其中 Hessian 矩陣用 Fisher 信息矩陣進行了近似。在 LLM-Pruner 的源碼中,這兩個公式被如圖 3 所示的代碼片段表示。
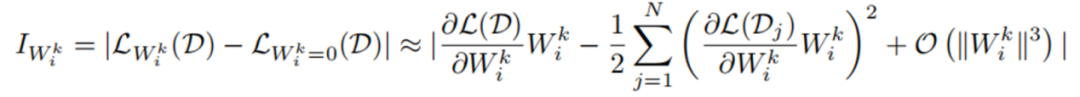
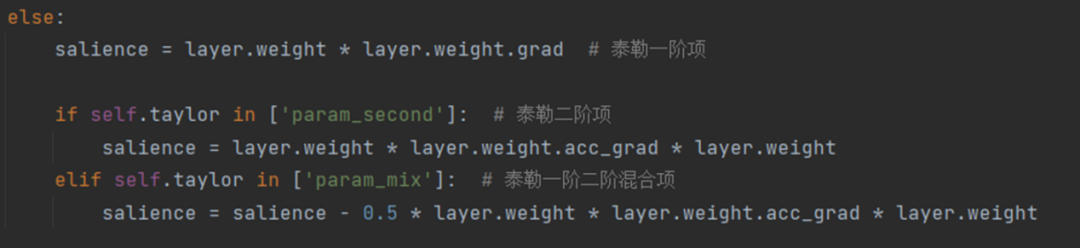
圖 3 評估重要性的源碼
最后,通過對每組內權重向量或參數的重要性進行累加/累乘/取最大值/取最后一層值,就得到了每組的重要性,再按剪枝率剪去重要性低的組即可。
(3)微調階段
本階段的主要工作是使用LoRA微調模型中每個可學習的參數矩陣W,以減輕剪枝帶來的性能損失。LoRA的公式為W+?W=W+BA,其具體步驟如圖4所示:
① 在模型的特定層中用 Wd×k+ΔWd×k 替換原有的權重矩陣 Wd×k,并把矩陣 ?Wd×k 分解成降維矩陣 Ad×r 和升維矩陣 Br×k,r << min(d, k)。
② 將 A 隨機高斯初始化,B 置為 0,凍結預訓練模型的參數 W,只訓練矩陣 A 和矩陣 B。
③ 訓練完成后,將 B 矩陣與 A 矩陣相乘再與矩陣 W 相加,作為微調后的模型參數。
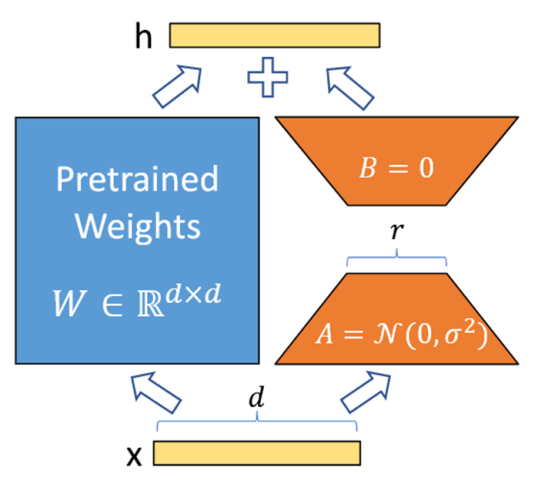
圖 4LoRA基本步驟
根據表 3 的實驗結果,剪枝 20% 后,模型的性能為原模型的 89.8%,經過 LoRA 微調后,性能可提升至原模型的 94.97%。在大多數數據集上,剪枝后的 5.4B LLaMA 甚至優于 ChatGLM-6B,所以如果需要一個具有定制尺寸的更小的模型,理論上用 LLM-Pruner 剪枝一個比再訓練一個成本更低效果更好。
然而,根據表 4 的數據顯示,剪枝 50% 后模型表現并不理想,LoRA 微調后綜合指標也僅為原模型 77.44%,性能下降幅度較大。如何進行高剪枝率的大模型結構化剪枝,仍是一個具有挑戰性的問題。
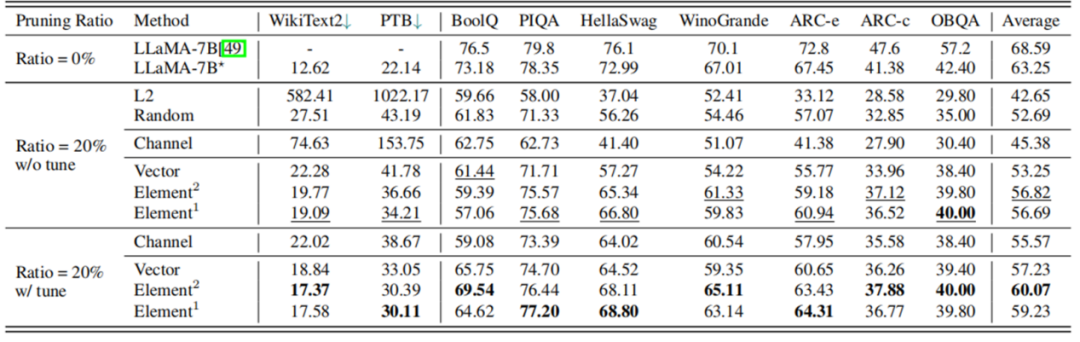
表 3LLaMA-7B 剪枝 20% 前后性能對比
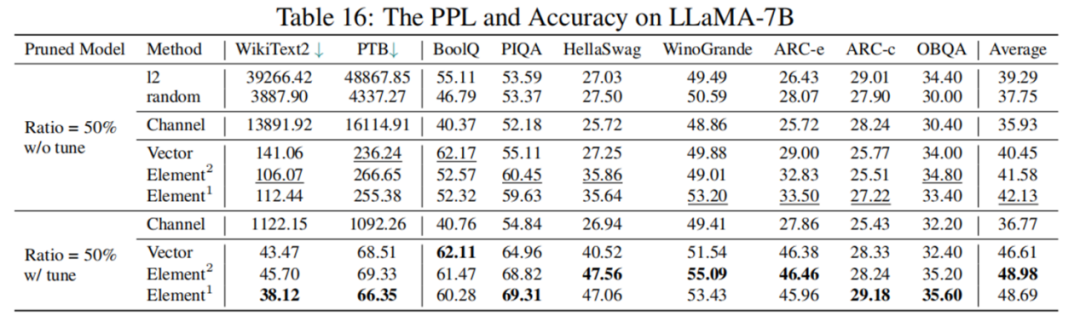
表 4LLaMA-7B 剪枝 50% 前后性能對比
研究進展
大模型剪枝技術已經成為近兩年的研究熱點,無論是在工業界還是學術界,都有許多研究人員投身于這一領域——這一點從表 5 和表 6 中可以明顯看出,而表格中列出的論文只是眾多大模型剪枝研究工作中的一小部分。除此之外,還有學者提出了介于結構化剪枝和非結構化剪枝之間的半結構化剪枝,如 Nvidia 的 N:M 稀疏化,就是每 M 個連續元素留下 N 個非零元素,但與前兩者相比目前相關探索較少。隨著研究的不斷深入和技術的持續進步,我們有理由相信,剪枝將繼續在大模型領域扮演重要的角色,并推動大模型技術的創新和發展。
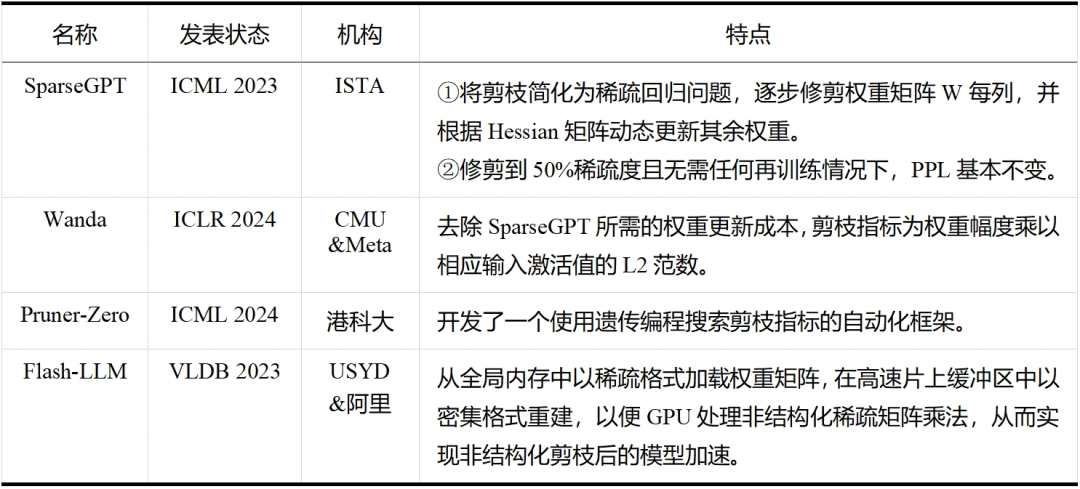
表5大模型非結構化剪枝
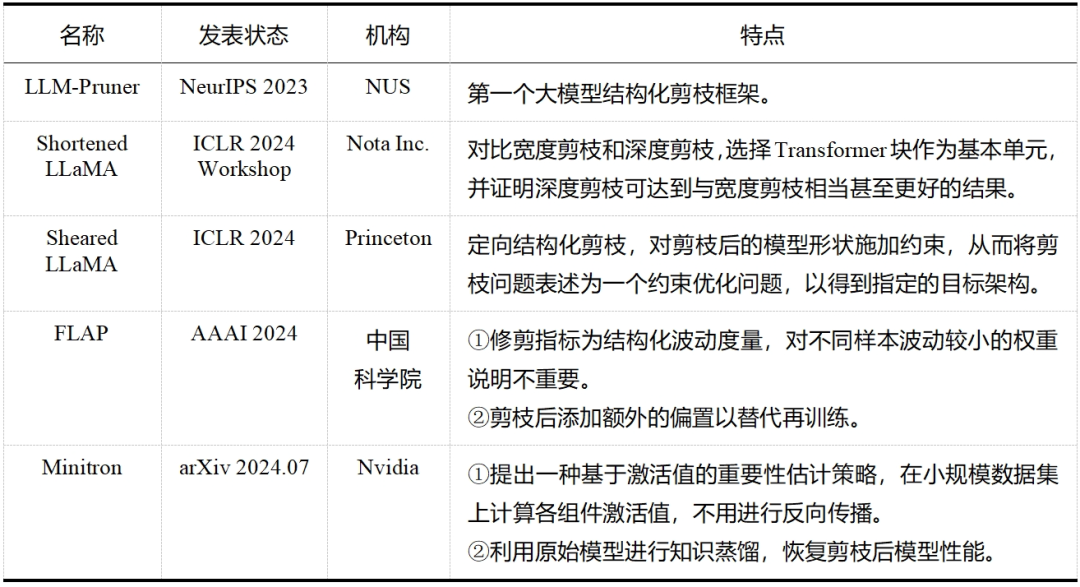
表6大模型結構化剪枝
-
人工智能
+關注
關注
1796文章
47681瀏覽量
240298 -
大模型
+關注
關注
2文章
2550瀏覽量
3169
原文標題:一文讀懂剪枝(Pruner):大模型也需要“減減肥”?
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
【「大模型啟示錄」閱讀體驗】對大模型更深入的認知
AI模型部署邊緣設備的奇妙之旅:如何實現手寫數字識別
車載大模型分析揭示:存儲帶寬對性能影響遠超算力
未來AI大模型的發展趨勢
利用阿秒脈沖揭示光電效應新信息
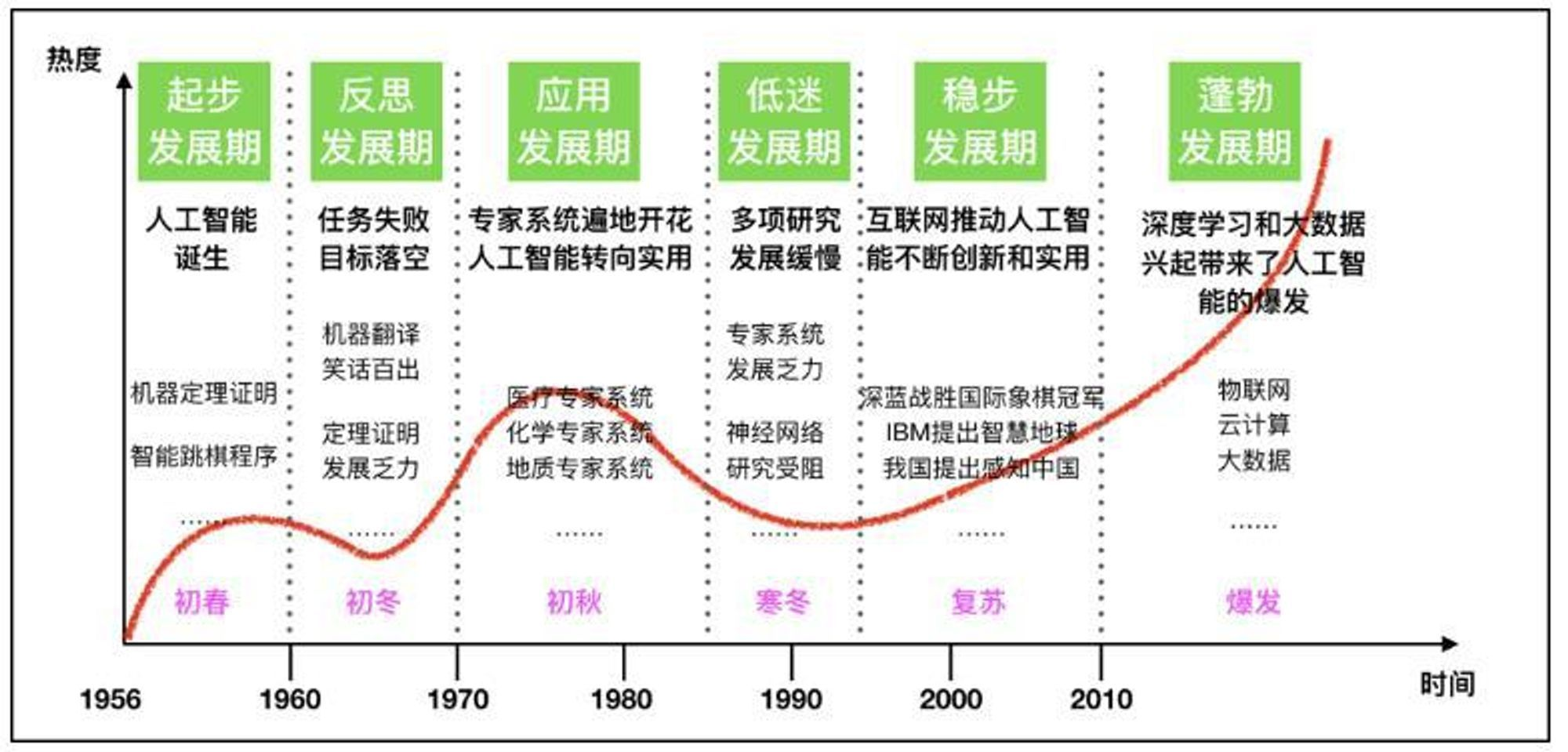
AI大模型的發展歷程和應用前景
【大語言模型:原理與工程實踐】大語言模型的應用
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】核心技術綜述
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
張宏江深度解析:大模型技術發展的八大觀察點






 工商網監
工商網監
評論