 一種信息引導的量化后LLM微調新算法IR-QLoRA
一種信息引導的量化后LLM微調新算法IR-QLoRA
大模型應用開卷,連一向保守的蘋果,都已釋放出發展端側大模型的信號。 問題是,大語言模型(LLM)卓越的表現取決于“力大磚飛”,如何在資源有限的環境中部署大模型并保障性能,仍然頗具挑戰。 以對大模型進行量化+LoRA的路線為例,有研究表明,現有方法會導致量化的LLM嚴重退化,甚至無法從LoRA微調中受益。 為了解決這一問題,來自蘇黎世聯邦理工學院、北京航空航天大學和字節跳動的研究人員,最新提出了一種信息引導的量化后LLM微調新算法IR-QLoRA。論文已入選ICML 2024 Oral論文。

論文標題:Accurate LoRA-Finetuning Quantization of LLMs via Information Retention
論文鏈接:
hhttps://arxiv.org/pdf/2402.05445
代碼鏈接:
https://github.com/htqin/IR-QLoRA 論文介紹,IR-QLoRA能有效改善量化導致的大模型性能退化。在LLaMA和LLaMA 2系列中,用該方法微調的2位模型,相比于16位模型僅有0.9%的精度差異。
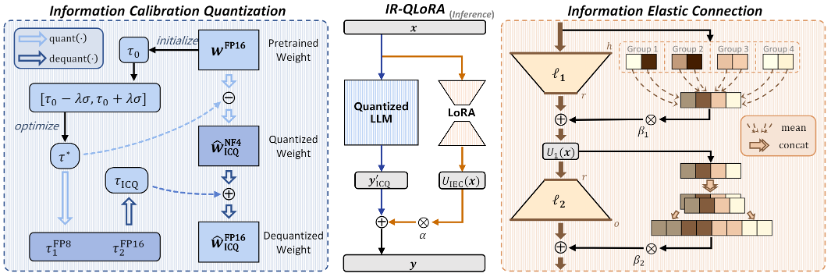
該方法的核心思想,是通過信息保留來使LoRA微調量化的大語言模型實現精度提升。 包含從統一信息角度衍生的兩種技術:信息校準量化和信息彈性連接。
信息校準量化LLM的量化權重被期望反映原始對應方所攜帶的信息,但比特寬度的減小嚴重限制了表示能力。從信息的角度來看,量化LLM和原始LLM的權重之間的相關性表示為互信息。
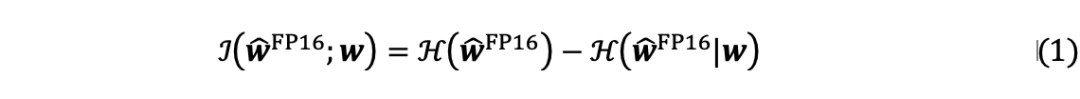
在LLM量化后,由于比特寬度的顯著減小導致表示能力的降低,量化權重的熵遠小于原始權重的熵。因此,優先考慮低比特權重內的信息恢復對于增強量化LLM至關重要。 首先從數學上定義信息校準的優化目標。校準過程可以看為向量化器引入一個校準常數以最大化信息,量化過程可以表述如下:
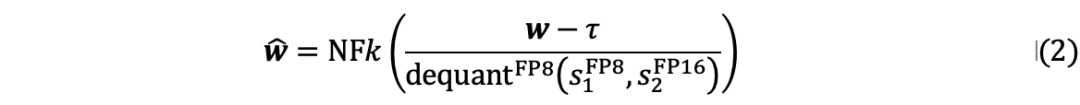
由于原始權重是固定的,公式 (1) 中的優化目標可以表示為:
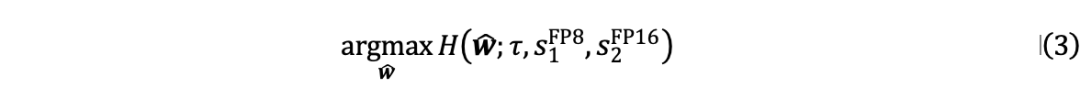
由于直接求解公式 (3) 中的目標非常耗時,作者提出了一種分塊校準量化器信息的兩步策略: 第一步是初始化校準常數。基于神經網絡權重正態分布的常見假設,將每個權重量化塊的常數初始化為中值。由于正態分布中靠近對稱軸的區域的概率密度較高,因此該初始化旨在更大程度地利用量化器的間隔。應用位置相關中值來初始化, 以減輕異常值的影響。 第二步是優化校準常數、量化尺度、雙量化尺度。使用信息熵作為度量,并進行基于搜索的優化以獲得。通過將線性劃分為個候選來創建的搜索空間,其中是標準差,是系數。使用每個候選校準權重后,量化校準的權重并計算信息熵。獲得的量化尺度與基線一致。通過得到量化尺度,然后二次量化為和。 對于優化后的校準常數,執行類似于尺度的雙量化以節省內存,信息校準量化的量化過程可以總結為:
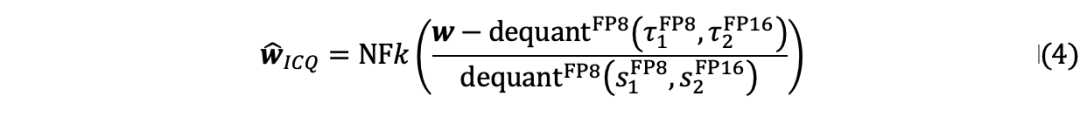
信息彈性連接除了基線中的量化LLM之外,由低秩矩陣組成的LoRA也阻礙了信息的恢復,為了增強LoRA的表示能力,幫助恢復量化LLM的信息,同時保持其輕量級性質,作者引入了有效的信息彈性連接。該方法構建了一個強大的低秩適配器,有助于利用從量化的LLM單元導出的信息。 具體來說,首先根據輸入和中間維度的最大公約數對原始特征進行分組和平均,并將其添加到由矩陣計算的輸出中。增加彈性連接的 LoRA 的第一個子單元可以表示為:
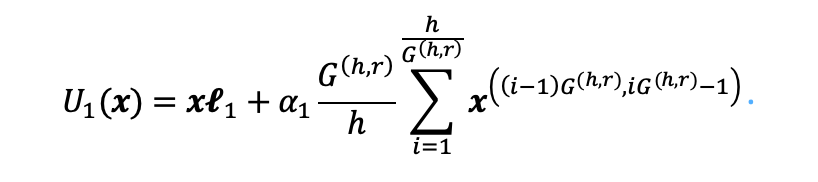
LoRA 的后一個矩陣將低秩中間表示變換為輸入維度,因此其伴隨的無參數變換使用重復串聯來增加維度。后一個子單元的計算過程可以表示為:
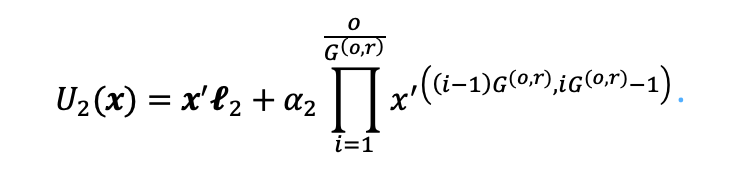
與 LLM 和 LoRA 單元中的矩陣乘法相比,無參數變換是一種多樣化的變換形式,進一步增強了量化 LLM 的信息表示。
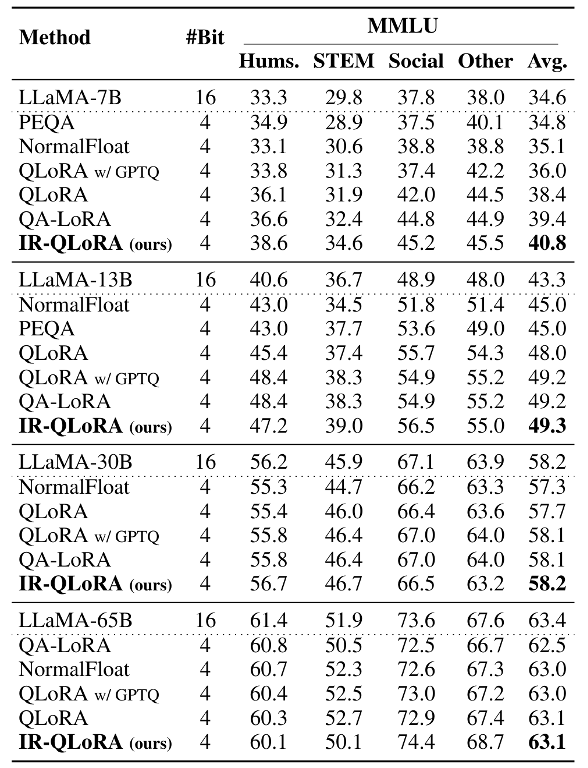
實驗驗證作者廣泛評估了IR-QLoRA的準確性和效率。選擇LLaMA和LLaMA 2系列模型,在Alpaca和Flanv2數據集上構建參數高效的微調,使用MMLU和CommonsenseQA基準進行評估微調后量化模型的效果。 準確率 以下兩張表格分別展示了在Alpaca和Flanv2數據集上微調的MMLU基準的5-shot精度結果。綜合結果表明,在各種規模的LLaMA模型中,IR-QLoRA優于所有比較量化方法。 與基線方法QLoRA相比,IR-QLoRA在相同的微調管道下在MMLU基準上實現了精度的顯著提高。
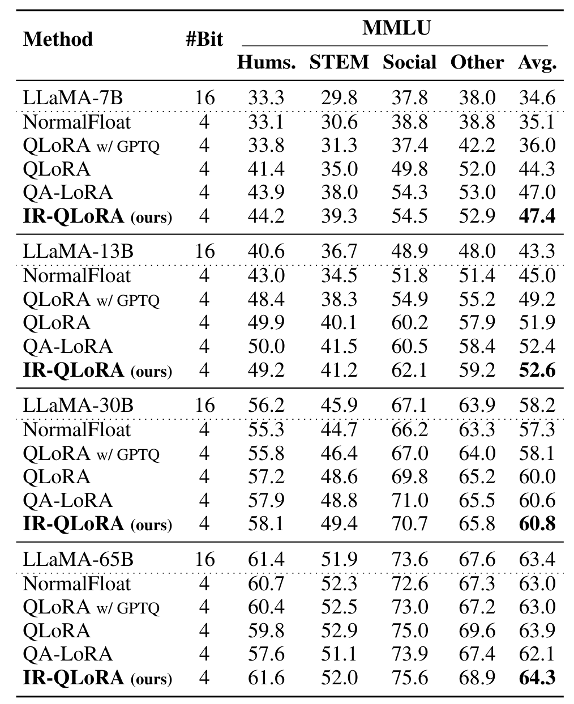
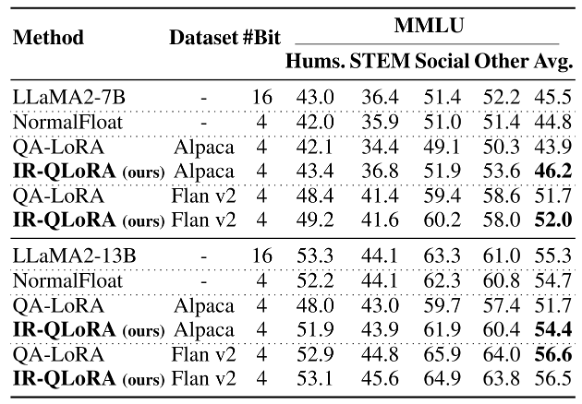
此外,在LLaMA 2上的準確性比較,證明了IR-QLoRA跨LLM系列的泛化性能。 下表中的結果表明,IR-QLoRA不僅平均實現了至少2.7%的性能改進,而且在幾乎每個單獨的指標上都表現出了優勢。這些結果表明IR-QLoRA在不同的LLM系列中表現出很強的泛化性。
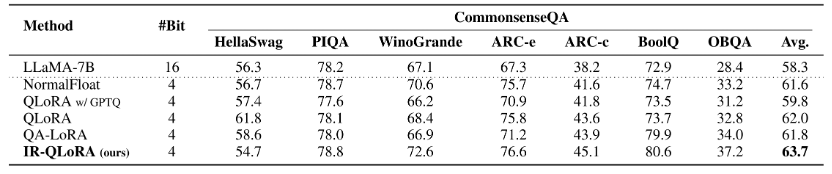
與MMLU基準上的現象類似,在CommonsenseQA基準上,與SOTA方法相比,IR-QLoRA始終保持了LLaMA-7B的最佳平均準確率,而且還顯著提高了大多數子項的有效性。
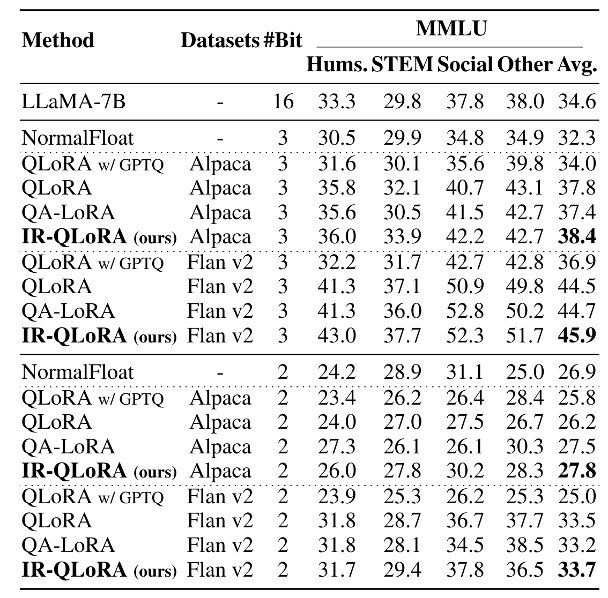
超低位寬 除了4比特以外,作者還評估了超低位寬下的IR-QLoRA建議。 具體來說,作者采用了QLoRA和LoftQ的量化方法,按照百分位量化方法構建了NF2和NF3量化。 下表顯示,隨著量化位寬的減小,基線QLoRA的性能急劇下降,以至于其在2位情況下的性能與隨機相差無幾。 相比之下,IR-QLoRA表現出更優越的性能,在Flan v2數據集上微調2位模型時,與16位模型相比僅有0.9%的精度差異。
效率 IR-QLoRA的信息校準量化和信息彈性連接并沒有帶來額外的存儲和訓練開銷。 如上所示,信息校準量化增加的參數僅相當于量化的縮放因子,而且采用了雙重量化以進一步減少存儲。因此其帶來的額外存儲空間很小,在4位LLaMA-7B上僅增加了 2.04%。 校準常數的優化過程也只增加了微不足道的訓練時間(例如,LLaMA-7B為 0.46%,LLaMA-13B為 0.31%)。此外,增加的時間僅用于訓練過程中的初始優化,并不會導致推理時間的增加。信息彈性連接也只在每層引入了2個額外參數,在整個模型中可以忽略不計。
結論總的來說,基于統計的信息校準量化可確保LLM的量化參數準確保留原始信息;以及基于微調的信息彈性連接可以使LoRA利用不同信息進行彈性表示轉換。 廣泛的實驗證明,IRQLoRA在LLaMA和LLaMA 2系列中實現了令人信服的精度提升,即使是2-4位寬,耗時也僅增加了0.45%。 IR-QLoRA具有顯著的多功能性,可與各種量化框架無縫集成,并且大大提高了LLM的LoRA-finetuning量化精度,有助于在資源受限的情況下進行實際部署。
-
算法
+關注
關注
23文章
4630瀏覽量
93362 -
LoRa
+關注
關注
349文章
1700瀏覽量
232388 -
大模型
+關注
關注
2文章
2551瀏覽量
3172 -
LLM
+關注
關注
0文章
299瀏覽量
400
原文標題:ICML 2024 | 量化大模型退化嚴重?ETH北航字節推出LoRA新范式
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
小白學大模型:構建LLM的關鍵步驟

在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

解鎖NVIDIA TensorRT-LLM的卓越性能
TensorRT-LLM低精度推理優化

LLM和傳統機器學習的區別
理解LLM中的模型量化





 工商網監
工商網監
評論