") AWK工具介紹
AWK工具介紹
awk是什么
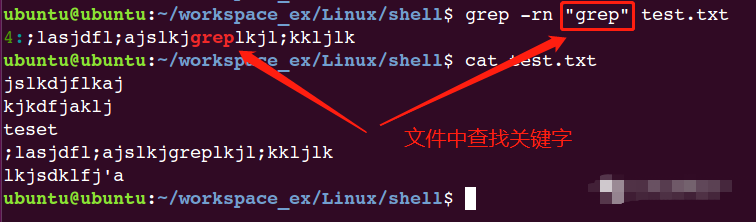
awk是一個(gè)強(qiáng)大的linux命令,有強(qiáng)大的文本格式化的能力,好比將一些文本數(shù)據(jù)格式化成專業(yè)的excel表的樣式。
awk早期在Unix上實(shí)現(xiàn),我們用的awk是gawk,是GUN awk的意思
如何學(xué)awk
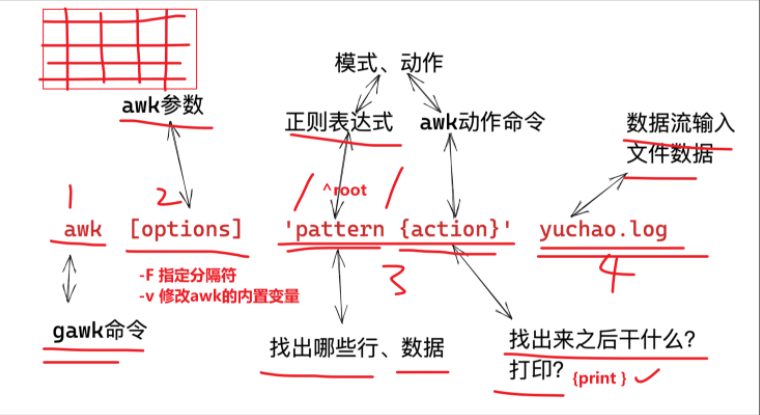
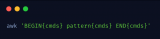
awk的語(yǔ)法格式
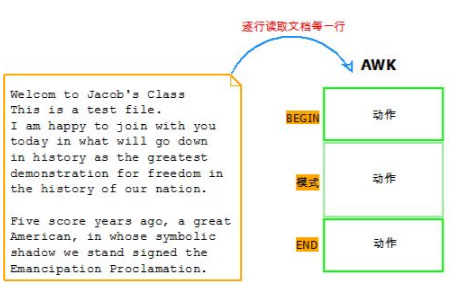
awk 指令是由模式,動(dòng)作,或者模式和動(dòng)作的組合組成.
模式即 pattern,可以類似理解成 sed 的模式匹配,可以由表達(dá)式組成,也可以使兩個(gè)正斜杠之間的正則表 達(dá)式.比如 NR==1,這就是模式,可以把他理解為一個(gè)條件.
動(dòng)作即 action,是由在大括號(hào)里面的一條或多條語(yǔ)句組成,語(yǔ)句之間使用分號(hào)隔開,如下 awk 使用格式
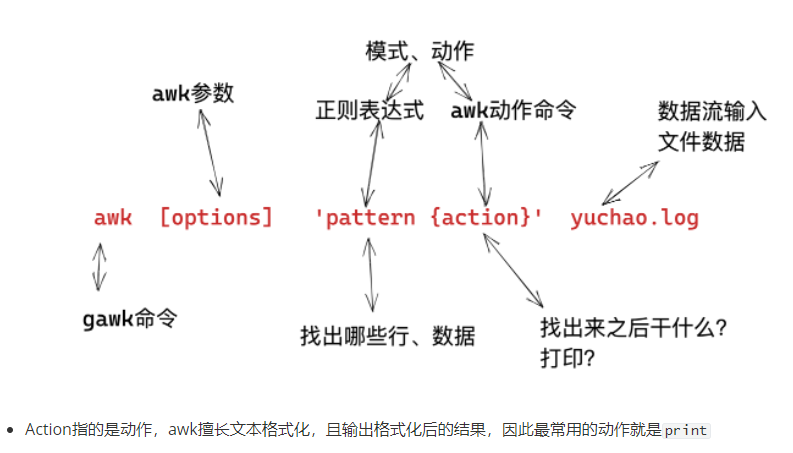
awk模式、動(dòng)作
模式,是指,要操作哪些行
動(dòng)作,是指,找到這些行之后,干什么,如何處理
生成測(cè)試數(shù)據(jù)
[242-yuchao-class01 root ~]#echo cc{01..50} | xargs -n 5
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
寫入文件,生成測(cè)試數(shù)據(jù)文件
echo cc{01..50} | xargs -n 5 > yuchao.log
無(wú)模式、只有動(dòng)作
直接輸出源文件,所有內(nèi)容
動(dòng)作是 {print $0} 這個(gè)$0是表示列的數(shù)據(jù),默認(rèn)是表示一整行數(shù)據(jù)
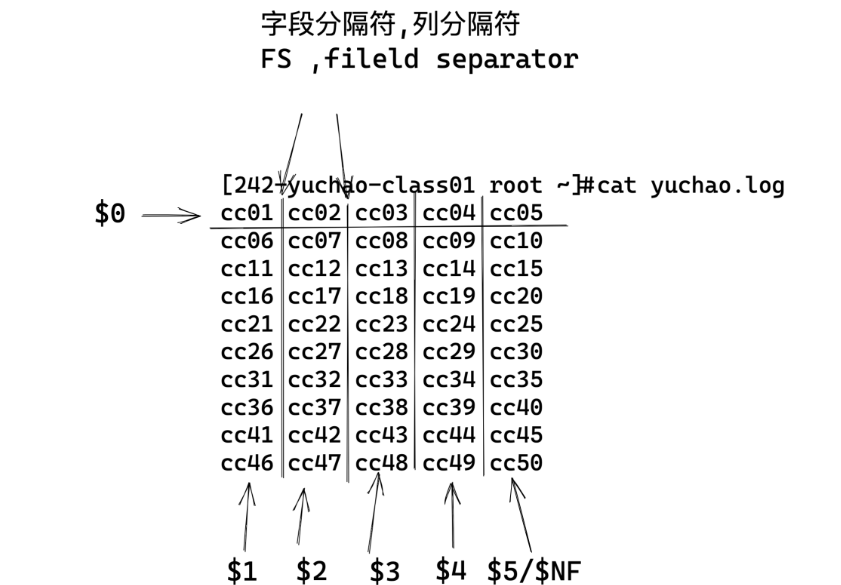
關(guān)于字段的取值語(yǔ)法
是
$0 表示所有字段數(shù)據(jù)
$1 第一列數(shù)據(jù)
$2 第二列數(shù)據(jù)
依次類推
[242-yuchao-class01 root ~]#awk '{print $0}' test_awk.log
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
2.輸出每一行數(shù)據(jù),但是只要第一列的數(shù)據(jù)
awk '{print $1}' test_awk.log
3. 輸出每一行數(shù)據(jù),只要第二列的數(shù)據(jù)
awk '{print $2}' test_awk.log
4. 輸出每一行數(shù)據(jù),只要第一列和 第三列的數(shù)據(jù)
awk '{print $1,$3 }' test_awk.log
[242-yuchao-class01 root ~]#awk '{print $1,$3 }' test_awk.log
cc01 cc03
cc06 cc08
cc11 cc13
cc16 cc18
cc21 cc23
cc26 cc28
cc31 cc33
cc36 cc38
cc41 cc43
cc46 cc48
行變量NR、匹配范圍語(yǔ)法
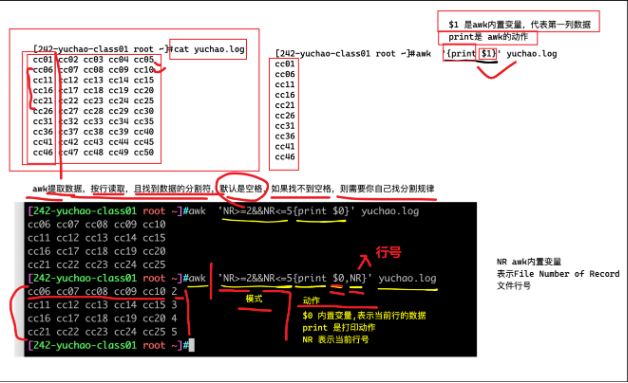
剛才是沒指定處理那一行,默認(rèn)是所有行
可以指定對(duì)某一行處理了
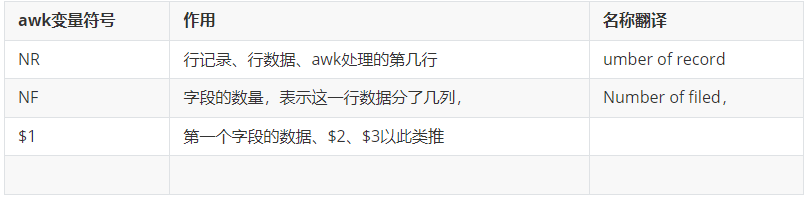
語(yǔ)法說(shuō)明,內(nèi)置變量NR,表示awk處理的每一行
number of record (記錄,行的意思)
NR ============== 行號(hào)
#格式說(shuō)明
NR 行
直接打印這個(gè)內(nèi)置變量,表示取當(dāng)前行的號(hào)碼
在開頭顯示行號(hào)
[242-yuchao-class01 root ~]#awk '{print NR,$0}' test_awk.log
在結(jié)尾顯示行號(hào)
[242-yuchao-class01 root ~]#awk '{print $0,NR}' test_awk.log
NR== 等于行
打印第二行的所有字段數(shù)據(jù)
awk 'NR==2{print $0}' test_awk.log
打印第二行的,第1列,和第四列數(shù)據(jù)
[242-yuchao-class01 root ~]#awk 'NR==2{print $1,$4}' test_awk.log
cc06 cc09
NR>= 大于等于行
NR<= 小于等于
NR>=N && NR<=M 從N行到M行
|| 或的用法
這是關(guān)于awk對(duì)行處理的 語(yǔ)法
列變量NF、每一列的字段
number of field (字段的數(shù)量) =====NF====等于列的總數(shù)
直接寫NF變量表示每一行字段的總數(shù)
查看每一行有多少個(gè)字段
awk '{print $0,NF}' test_awk.log
輸出列:
#位置變量說(shuō)明
直接寫NF變量表示每一行字段的總數(shù)
查看每一行有多少個(gè)字段====
這個(gè)NF,默認(rèn)表示,字段的總數(shù)
awk '{print $0,NF}' test_awk.log
$1,$2,$3
, 輸出分隔符,默認(rèn)逗號(hào),awk輸出每一列的分隔符是,空格
$0 輸出所有字段
$1 輸出第一列
$2 輸出第二列的數(shù)據(jù)
$3 輸出第三類的數(shù)據(jù)
... 依次類推
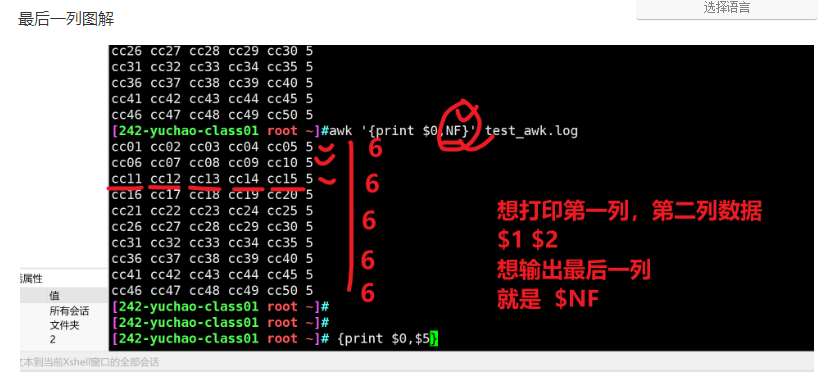
$NF 輸出最后一列
awk '{print $NF}' test_awk.log
$(NF-1) 輸出倒數(shù)第2列
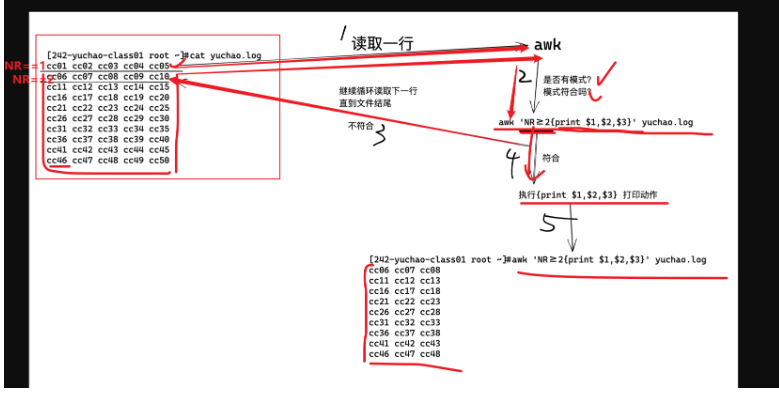
指定行(模式)、打印動(dòng)作
awk '模式 {打印動(dòng)作} '
提取出第二行的數(shù)據(jù)
NR 行變量
awk 'NR==2{print $0}' test_awk.log
懶人寫法,默認(rèn)awk給你進(jìn)行打印$0了,不建議用
awk 'NR==2' test_awk.log
提取出第二行到第五行
awk 'NR>=2&&NR<=5{print $0}' test_awk.log
指定行(模式)、打印某一列(動(dòng)作)
提取出第二行到第五行,并且只打印前三列的數(shù)據(jù)
[242-yuchao-class01 root ~]#awk 'NR>=2&&NR<=5{print $1,$2,$3}' test_awk.log
cc06 cc07 cc08
cc11 cc12 cc13
cc16 cc17 cc18
cc21 cc22 cc23
圖解模式、動(dòng)作
只有動(dòng)作、不寫模式
沒有模式,也就是沒限定條件,
Awk默認(rèn)處理所有行
打印前三列的數(shù)據(jù)
awk '{print $1,$2,$3}' test_awk.log
多個(gè)模式和動(dòng)作(解釋NR、NF)
指定行,NR==4,number of record,行號(hào)的記錄
指定動(dòng)作
[242-yuchao-class01 root ~]#awk '{print $0,NF,NR}' test_awk.log
cc01 cc02 cc03 cc04 cc05 5 1
cc06 cc07 cc08 cc09 cc10 5 2
cc11 cc12 cc13 cc14 cc15 5 3
cc16 cc17 cc18 cc19 cc20 5 4
cc21 cc22 cc23 cc24 cc25 5 5
cc26 cc27 cc28 cc29 cc30 5 6
cc31 cc32 cc33 cc34 cc35 5 7
cc36 cc37 cc38 cc39 cc40 5 8
cc41 cc42 cc43 cc44 cc45 5 9
cc46 cc47 cc48 cc49 cc50 5 10
內(nèi)置變量$0表示整行數(shù)據(jù)
NF表示Number of filed,字段的數(shù)量,表示這一行數(shù)據(jù)分了幾列
NF表示字段總數(shù)
$NF表示取最后一個(gè)字段的值
NR表示,number of record,行號(hào)的記錄,表示在處理第幾行
打印前四行數(shù)據(jù),要求輸出每一行的行號(hào)、字段數(shù)、以及對(duì)應(yīng)行的數(shù)據(jù)
[242-yuchao-class01 root ~]#awk 'NR<=4{print NR,NF,$0 }' test_awk.log
1 5 cc01 cc02 cc03 cc04 cc05
2 5 cc06 cc07 cc08 cc09 cc10
3 5 cc11 cc12 cc13 cc14 cc15
4 5 cc16 cc17 cc18 cc19 cc20
awk快速入門小結(jié)
pattern和action都要用單引號(hào),防止shell作特殊解釋(是交給awk去執(zhí)行的,而不是bash)
不指定模式,awk默認(rèn)處理輸入的文件數(shù)據(jù),每一行,每一列
如果指定模式,例如指定的行,awk就處理指定那一行的數(shù)據(jù)
awk的動(dòng)作,必須寫在花括號(hào)里
,括號(hào)里寫入awk提供的命令。
如果沒有{ }花括號(hào),就會(huì)被識(shí)別為patter,而不是action
注意給awk傳入數(shù)據(jù),一般都是file
也可以是管道傳遞的數(shù)據(jù)
拿到第二行的,倒數(shù)第二列的數(shù)據(jù)
[242-yuchao-class01 root ~]#cat test_awk.log | awk 'NR==2{print $(NF-1)}'
cc09
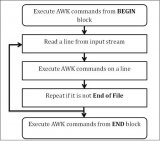
圖解awk執(zhí)行過(guò)程
awk的字段(列)、記錄(行)變量
awk其他內(nèi)置變量(翻譯)
NR=======行號(hào) NF========字段數(shù)量 FS===========數(shù)據(jù)輸入的字段分隔符,默認(rèn)是 【空格】 (awk讀取的這個(gè)數(shù)據(jù),以什么分隔符去讀,去分割它的數(shù)據(jù)) RS============record separator 行分隔符,默認(rèn)是【換行符】 awk的其他內(nèi)置變量如下。 FILENAME:當(dāng)前文件名 ===================awk在數(shù)據(jù)輸入時(shí),的一個(gè)分隔符=================== FS:字段分隔符,默認(rèn)是空格和制表符。 Input field separator variable.輸入字段分隔符變量。 RS:行分隔符,用于分割每一行,默認(rèn)是換行符。 Record Separator variable,行分隔符變量 ============awk處理完畢后,打印的數(shù)據(jù)格式,分隔符================= OFS:輸出字段的分隔符,用于打印時(shí)分隔字段,默認(rèn)為空格。 Output Field Separator Variable,輸出字段分隔符變量 ORS:輸出記錄的分隔符,用于打印時(shí)分隔記錄,默認(rèn)為換行符。 Output Record Separator Variable,輸出記錄分隔符變量 OFMT:數(shù)字輸出的格式,默認(rèn)為%.6g。
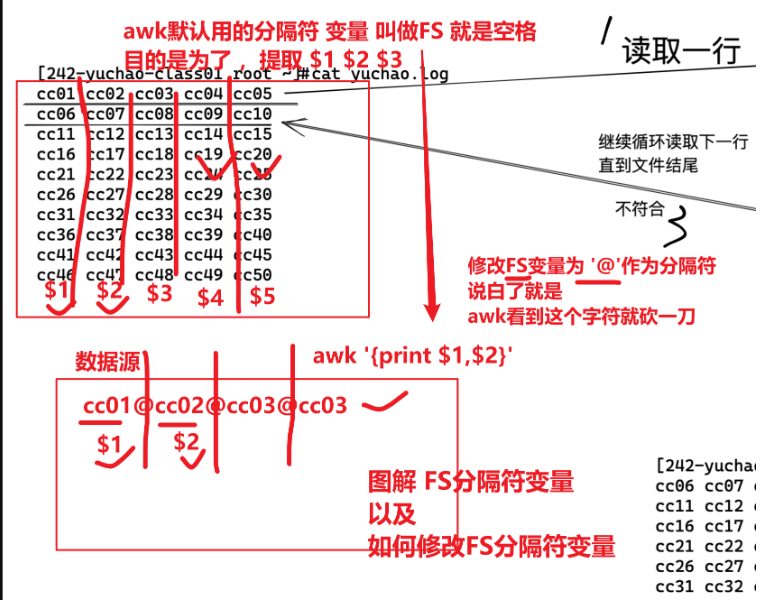
圖解FS變量,,,,,,,,,,,,關(guān)于列的分隔符
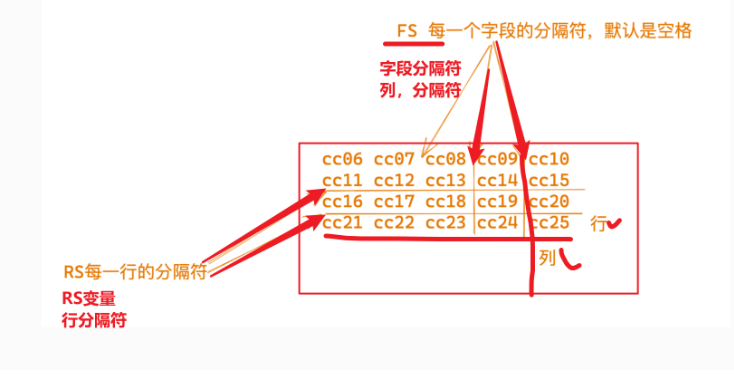
圖解RS變量,,,,,,,,,,,,,,,,關(guān)于行分隔符

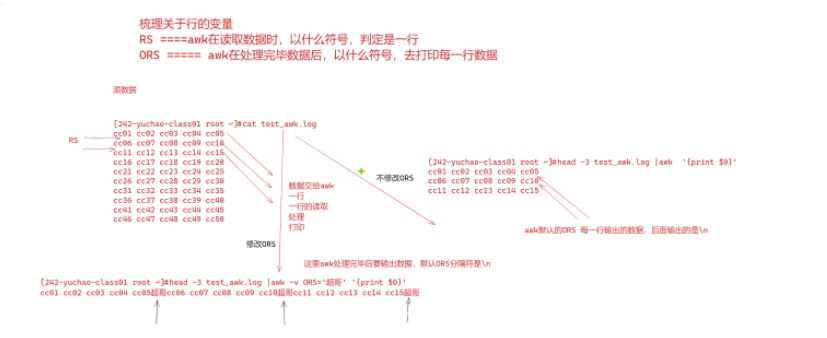
RS變量/ORS變量
RS變量作用是, 行分隔符========awk在數(shù)據(jù)輸入時(shí),讀取的一個(gè)行分隔符
ORS ,output RS =======awk在{print $0} 打印數(shù)據(jù)后,的一個(gè)行分隔符==
RS變量: record separator,輸入行、分隔符
ORS、awk輸出行、分隔符
圖解awk執(zhí)行的輸入、輸出
awk 對(duì)每個(gè)要處理的輸入數(shù)據(jù)認(rèn)為都是具有格式和結(jié)構(gòu)的,而不僅僅是一堆字符串
默認(rèn)情況下,每一行 內(nèi)容都是一條記錄,并以換行符分隔( )結(jié)束
awk默認(rèn)下,每一行就是每一個(gè)record(記錄)
RS 即 record separator 輸入輸入數(shù)據(jù) ,表示每個(gè)記錄輸入的時(shí)候分隔符.即行與行之間如何分隔.
NR 即 number of record 記錄(行)號(hào),表示當(dāng)前正在處理的記錄(行)的號(hào)碼
ORS 即 output record separator 輸出記錄分隔符
修改RS/修改awk輸入顯示
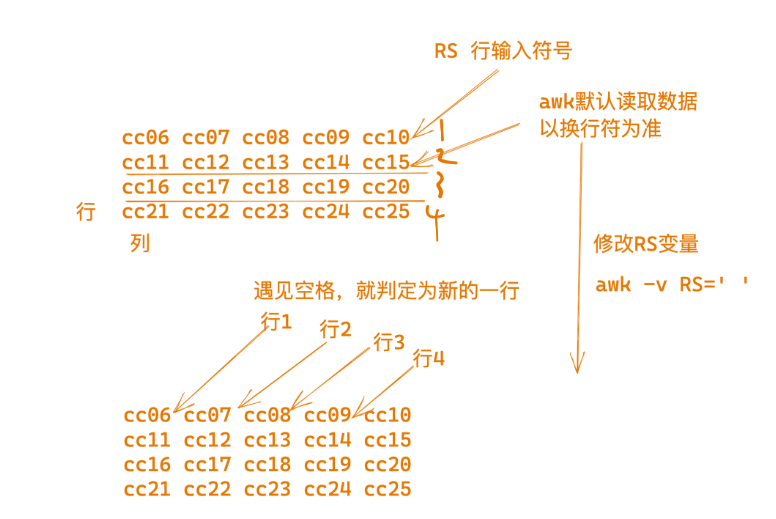
測(cè)試修改RS變量
測(cè)試數(shù)據(jù)
[242-yuchao-class01 root ~]#head -3 yuchao.log cc01 cc02 cc03 cc04 cc05 cc06 cc07 cc08 cc09 cc10 cc11 cc12 cc13 cc14 cc15 =========基本玩法,默認(rèn)行分隔符是 換行符 awk '{print $0}' test_awk.log
awk默認(rèn)的行分隔符
這個(gè)寫法,等于awk默認(rèn)的行分隔符,現(xiàn)在是指定看效果是
[242-yuchao-class01 root ~]#awk -v RS='
' '{print $0}' test_awk.log
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
[242-yuchao-class01 root ~]## 讓awk讀取該文件,將每一個(gè) cc01 cc02 都單獨(dú)認(rèn)為是一行
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
這里是修改RS行分隔符為空格
awk看到空格就認(rèn)為是新的一行數(shù)據(jù)
[242-yuchao-class01 root ~]#awk -v RS=' ' '{print $0}' test_awk.log
cc01
cc02
cc03
修改ORS、修改awk動(dòng)作執(zhí)行后的數(shù)據(jù)打印格式
當(dāng)awk處理完畢后,print打印結(jié)果,默認(rèn)也是 一個(gè)換行符
源數(shù)據(jù)
[242-yuchao-class01 root ~]#cat test_awk.log
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
awk給這個(gè)默認(rèn)打印的結(jié)果,結(jié)尾加上的是 換行符
你可以修改這個(gè),awk的輸出行分隔符,默認(rèn)是 換行符
把a(bǔ)wk輸出的行分隔符,改為 @@
修改 ORS變量為@@
awk -v ORS='@@' '{print $0}' test_awk.log
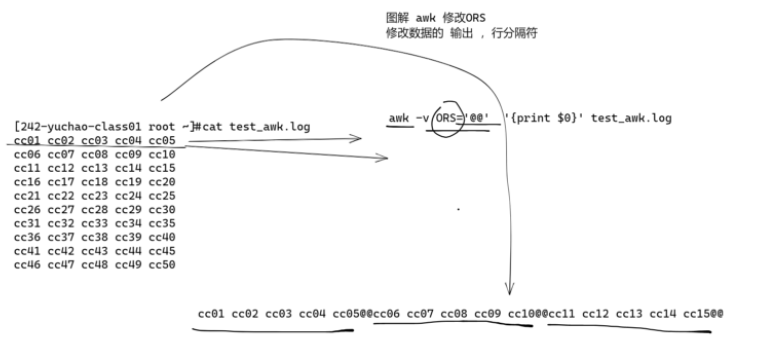
修改ORS/修改awk輸出顯示
可以自由修改,awk處理完畢后的每一行的分隔符,也就是修改ORS變量。
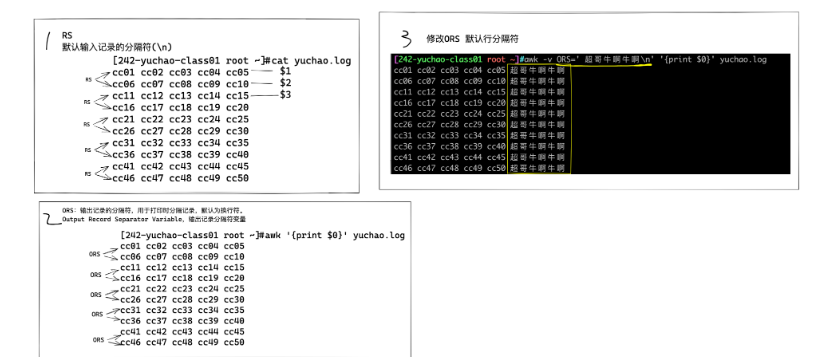
小結(jié)
awk默認(rèn)情況下,認(rèn)為文件從頭到尾是一整行數(shù)據(jù),直到碰見換行符
回車換行符
因此本行結(jié)束,進(jìn)入下一行
可以通過(guò)修改awk的RS變量,修改行輸入的分隔符
面試題,統(tǒng)計(jì)單詞出現(xiàn)頻率
并且統(tǒng)計(jì)出現(xiàn)最多的前5個(gè)
[242-yuchao-class01 root ~]#cat english.log I have a dog, it is lovely, it is called Mimi. Every time I go home from school, Mimi always cruising around me, I will go to the kitchen to get a piece of meat to it, it lay on the floor to eat. My legs and then jump to bark "Wang "called, so I picked up Mimi, it is the opportunity to lick my hand, making me laugh.I like Mimi, like puppies. 1.將一整行的數(shù)據(jù),改為,每一個(gè)單詞,就是一行 2.改為這樣后,就可以交給sort去排序了 3.再去uniq 去重 -c 統(tǒng)計(jì)重復(fù)的次數(shù)
這道題,核心就在于
1.單行的多個(gè)單詞,替換為,每一個(gè)單詞成為一行
簡(jiǎn)單處理,找到空格就改為換行,修改RS,數(shù)據(jù)輸入換行符,改為RS=' '
復(fù)雜處理,找到非連續(xù)的大小寫字母,就換行
排序
3.去重
4.排序統(tǒng)計(jì) 最多的前五個(gè)
sed答題
[242-yuchao-class01 root ~]#sed -r 's#[^a-zA-Z]+#
#g' english.log | sort | uniq -c | sort -r -n | head -5
6 to
5 it
5 I
4 Mimi
3 the
tr答題
tr命令就是將字符替換的作用
基本語(yǔ)法
[242-yuchao-class01 root ~]#echo 'hello world' | tr 'll' 'LL'
heLLo worLd
思路就是
將文本中的空格,換為
,就實(shí)現(xiàn)了每一個(gè)單詞,作為新的一行
[242-yuchao-class01 root ~]#cat english.log |tr ' ' '
' | sort | uniq -c | sort -r -n | head -5
6 to
4 it
4 I
3 the
3 is
grep答題
grep關(guān)鍵字提取
[242-yuchao-class01 root ~]#grep -E '[a-zA-Z]+' english.log -o | sort | uniq -c | sort -r -n | head -5
6 to
5 it
5 I
4 Mimi
3 the
awk答題
簡(jiǎn)單考慮,直接考慮輸入的行分隔符,改為 空格
1.將一整行的數(shù)據(jù),改為,每一個(gè)單詞,就是一行
awk -v RS=' ' '{print $0}' english.log
2.改為這樣后,就可以交給sort去排序了,將子母一樣的,擱一塊
awk -v RS=' ' '{print $0}' english.log | sort
3.再去uniq 去重 -c 統(tǒng)計(jì)重復(fù)的次數(shù)
awk -v RS=' ' '{print $0}' english.log | sort |uniq
4.并且統(tǒng)計(jì)出現(xiàn)最多的前5個(gè)
awk -v RS=' ' '{print $0}' english.log | sort |uniq -c | sort -r | head -5
就是用正則,提取,大小寫字母
復(fù)雜考慮
[242-yuchao-class01 root ~]#awk -v RS='[^a-zA-z]+' '{print $0}' english.log | sort | uniq -c | sort -r -n | head -5
6 to
5 it
5 I
4 Mimi
3 the
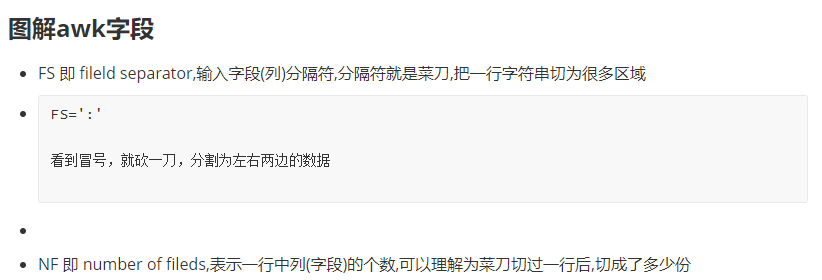
awk列操作(分隔符修改)
字段(列)
每條記錄都是由多個(gè)區(qū)域(field)組成的
每一行數(shù)據(jù),都被分割為了很多個(gè)字段
默認(rèn)情況下區(qū)域之間的分隔符是由空格(即空格或制表符)來(lái)分隔
將分隔符記錄在內(nèi)置變量 FS中
每行記錄的區(qū)域數(shù)據(jù)保存在 awk 的內(nèi)置變量 NF 中
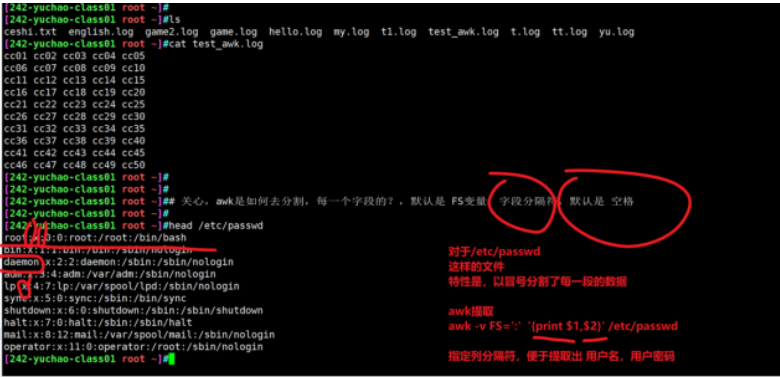
指定分隔符
當(dāng)文本不是以空格分割,你得自己找特征,進(jìn)行切蛋糕。
FS的值可以是固定的字符、也可以是正則表達(dá)式
例如/etc/passwd文件 ,提取用戶信息 提取出用戶名、登錄解釋器 awk -v FS=':' '{print $1,$NF }' /etc/passwd # 美化顯示的命令column -t [242-yuchao-class01 root ~]#awk -v FS=':' '{print $1,$NF }' /etc/passwd |column -t
簡(jiǎn)單的,讀數(shù)據(jù),然后awk打印,改為以空格分割每一個(gè)數(shù)據(jù)
test10 123456 583438864691290311
awk -v FS=',' '{print $1,$2,$3}' user_id.csv
修改格式
身份證號(hào) 用戶名 密碼
awk -v FS=',' '{print $3,$1,$2}' user_id.csv
身份證號(hào)---用戶名---密碼
[242-yuchao-class01 root ~]#cat user1.csv
t1,123,1111111
t2,456,2222222
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#awk -v FS=',' '{print $3,$2,$1}' user1.csv
1111111 123 t1
2222222 456 t2
提取30號(hào)用戶的用戶名、身份證號(hào),且顯示行號(hào)
test30,123456,895782891435332651
test90,123456,845590904189307705
test91,123456,631309684235761490
test92,123456,140550391185668516
test93,123456,753107759637368854
test94,123456,572732019383725076
test95,123456,817005865875540475
答案
awk -v FS=',' 'NR==30{print $1,$3,NR}' user_id.csv
awk使用正則的語(yǔ)法
test30
awk '/正則表達(dá)式/{action}' user_id.csv
awk -v FS=',' '/^test30/{print $1,$3,NR}' user_id.csv
awk內(nèi)置變量梳理
關(guān)于行的內(nèi)置變量,RS、ORS
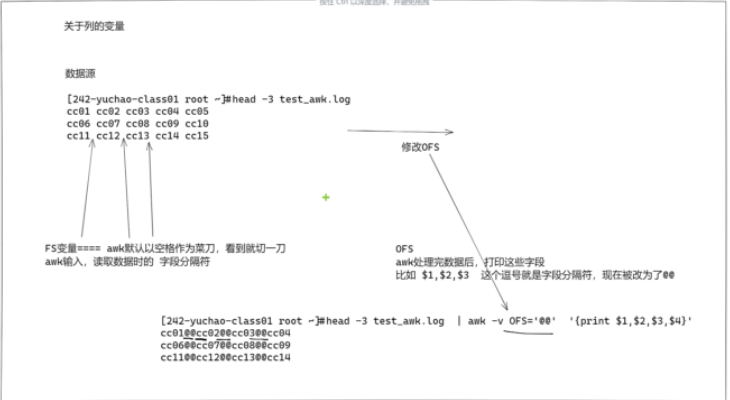
關(guān)于列的變量
FS,提取數(shù)據(jù)時(shí),提取的字段,以什么字符進(jìn)行切割,分割
OFS,打印數(shù)據(jù)時(shí),每一個(gè)字段之間的分隔符是什么
修改FS和OFS變量
RS和ORS
RS、輸入記錄分隔符,決定awk如何分隔每一行(默認(rèn)是 )
ORS,輸出記錄分隔符,決定awk如何輸出每一行(默認(rèn)是 )
FS和OFS
FS是輸入字段分隔符,決定awk輸入數(shù)據(jù)后的每一個(gè)字段分隔符是什么,默認(rèn)是空格
OFS是輸出字段分隔符,決定awk輸出每個(gè)字段的分隔符是什么,默認(rèn)是空格
指定FS分隔符(在哪個(gè)位置切蛋糕)
兩個(gè)方式 1、參數(shù) awk -F '分隔符' 2.修改變量 awk -v FS='分隔符'
指定OFS分隔符
兩個(gè)方式 1、參數(shù) awk -F '分隔符' 2.修改變量 awk -v FS='分隔符'
測(cè)試數(shù)據(jù)
[242-yuchao-class01 root /opt]#cat yuchao.log cc01 cc02 cc03 cc04 cc05 cc06 cc07 cc08 cc09 cc10 cc11 cc12 cc13 cc14 cc15 cc16 cc17 cc18 cc19 cc20 cc21 cc22 cc23 cc24 cc25 cc26 cc27 cc28 cc29 cc30 cc31 cc32 cc33 cc34 cc35 cc36 cc37 cc38 cc39 cc40 cc41 cc42 cc43 cc44 cc45 cc46 cc47 cc48 cc49 cc50
要求修改每一個(gè)數(shù)據(jù)之間的分隔符,改為#號(hào)
$1 ,$2 是字段之間的逗號(hào),和OFS對(duì)應(yīng)
[242-yuchao-class01 root ~]#awk -v OFS='#' '{print $1,$2,$3,$4,$5}' test_awk.log
cc01#cc02#cc03#cc04#cc05
cc06#cc07#cc08#cc09#cc10
cc11#cc12#cc13#cc14#cc15
cc16#cc17#cc18#cc19#cc20
cc21#cc22#cc23#cc24#cc25
cc26#cc27#cc28#cc29#cc30
cc31#cc32#cc33#cc34#cc35
cc36#cc37#cc38#cc39#cc40
cc41#cc42#cc43#cc44#cc45
cc46#cc47#cc48#cc49#cc50
修改/etc/passwd的格式
修改原本用戶信息的冒號(hào)分隔符、改為---
提取出 root、家目錄、登錄解釋器
[242-yuchao-class01 root ~]#head -5 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
head -5 /etc/passwd|awk -v FS=':' -v OFS='---' 'NR==1{print $1, $(NF-1),$NF}'

圖解修改FS、OFS

總結(jié)行、列
RS、ORS、代表了awk的輸入、輸出、關(guān)于行的分隔符
FS、OFS、代表了awk的輸入、輸出、關(guān)于列的分隔符
對(duì)于不同的文本,需要選擇合適的FS、合適的菜刀,來(lái)分割出左右可以便于提取的數(shù)據(jù)
NR表示行號(hào)、記錄號(hào)
NF表示每一行的字段數(shù)、有多少列
$符號(hào)一般用于提取某一列的數(shù)據(jù),如$1、$2
$NF表示最后一列的數(shù)據(jù)
鏈接:https://www.cnblogs.com/btcm409181423/p/18024202
-
Linux
+關(guān)注
關(guān)注
87文章
11345瀏覽量
210385 -
命令
+關(guān)注
關(guān)注
5文章
696瀏覽量
22107
原文標(biāo)題:AWK是什么?掌握這一工具,輕松搞定文本處理
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Linux Awk命令實(shí)例教程
Linux中g(shù)rep、sed和awk命令詳解
基于ebpf的性能工具-bpftrace腳本語(yǔ)法
linux awk命令簡(jiǎn)單易懂分分鐘學(xué)會(huì)
Linux Awk用法總結(jié)
快速掌握AWK的基本使用方式
linux下awk以及重定向命令如何使用?
Linux入門教程之快速學(xué)習(xí)Linux AWK命令的教程免費(fèi)下載
20分鐘 Awk 入門
Linux中awk命令的格式和匹配模式
Linux三劍客之awk實(shí)戰(zhàn)詳解教程
這些awk用法你會(huì)用幾個(gè)
一文詳解Linux awk命令
如何像 awk一樣分割字符串





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論