") LeCun親授的深度學(xué)習(xí)入門課:從飛行器的發(fā)明到卷積神經(jīng)網(wǎng)絡(luò)
LeCun親授的深度學(xué)習(xí)入門課:從飛行器的發(fā)明到卷積神經(jīng)網(wǎng)絡(luò)
前言
深度學(xué)習(xí)和人腦有什么關(guān)系?計(jì)算機(jī)是如何識(shí)別各種物體的?我們?cè)鯓訕?gòu)建人工大腦?這是深度學(xué)習(xí)入門者繞不過的幾個(gè)問題。很幸運(yùn),這里有位大牛很樂意為你講解。LeCun從鳥類對(duì)飛行器發(fā)明的影響開始講起,層層遞進(jìn)、逐步深入到深度學(xué)習(xí)的本質(zhì),可以說非常新手友好了。機(jī)不可失,還不來(lái)圍觀這堂由大神親自授課的深度學(xué)習(xí)入門指南?
講座的主要內(nèi)容:
今天來(lái),給大家簡(jiǎn)單介紹一下深度學(xué)習(xí)。但我們不從AI開始講起,而是從人類發(fā)明飛行器開始講。
依照達(dá)芬奇飛行器草圖做的第一款飛行器,完全照搬了鳥類的外形。那時(shí)候根本不知道飛行底層的原理,所以只能從自然界的生物獲得靈感,照葫蘆畫瓢。
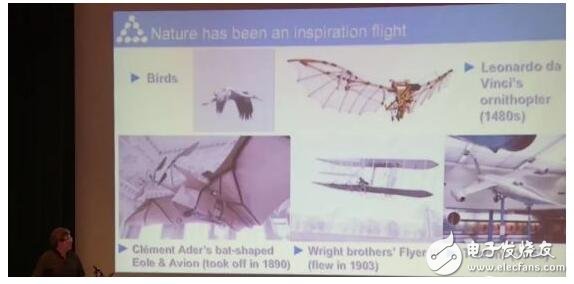
第一次飛行,只成功離地15公分,還是20公分的樣子,飛行器就掛了。所以我們還是需要更系統(tǒng)的方法,就是后來(lái)萊特兄弟造飛行器用到的一套方法,飛行終于成為了現(xiàn)實(shí)。
一般來(lái)說,理論認(rèn)知都是在實(shí)踐積累之后才有的。
飛行就說這么多。
那么問題來(lái)了。
人工智能可以從大自然里獲得靈感嗎?
很明顯,這個(gè)想法很舊啦。我們先看一下生物界的智能體。
人類的大腦,差不多有850億個(gè)神經(jīng)元。而每個(gè)神經(jīng)元都有上萬(wàn)個(gè)突觸,在一千到十萬(wàn)個(gè)之間不等。人腦相當(dāng)高效,能耗才25瓦特,是PC的十分之一。
每個(gè)有大腦的動(dòng)物都能學(xué)習(xí),不同動(dòng)物的學(xué)習(xí)方式可能不同,有些比較簡(jiǎn)單。它們并不需要特別好的視覺,或者其他智能體的教導(dǎo),就能自己去學(xué)。
我們嘗試找出動(dòng)物學(xué)習(xí)的機(jī)制,然后用來(lái)訓(xùn)練機(jī)器學(xué)習(xí)。

慢慢地,從1940年起,就有了打造智能機(jī)器的想法。于是就冒出來(lái)了感知機(jī)(Perceptron)。
它不是一臺(tái)計(jì)算機(jī),而是一個(gè)計(jì)算機(jī)模擬器。輸入值是電壓,超過某個(gè)閾值,就打開。低于閾值,就關(guān)閉。而權(quán)重是可以被訓(xùn)練的,就像一個(gè)可旋轉(zhuǎn)調(diào)節(jié)的鈕。
盡管現(xiàn)在我們可以用三行Python代碼實(shí)現(xiàn)它,但在那年代已經(jīng)算是大型的計(jì)算機(jī)了。
這個(gè)感知機(jī)是怎么運(yùn)轉(zhuǎn)起來(lái)的呢?
原理是很簡(jiǎn)單的,你需要先集齊一堆訓(xùn)練數(shù)據(jù)。
比如說任務(wù)是圖像識(shí)別,那么輸入就是圖像的一個(gè)個(gè)像素。當(dāng)每個(gè)像素用0,1表示時(shí),那么就可以組成一串?dāng)?shù)字。
你給機(jī)器一張圖,字母A,然后輸出應(yīng)該是1。那么訓(xùn)練的時(shí)候,就讀取圖像中的像素,調(diào)高那些能增強(qiáng)最終結(jié)果是1,也就是判定字母是A的像素的權(quán)重,并調(diào)低偏離最終結(jié)果的像素的權(quán)重。

數(shù)學(xué)上只需要一行Python代碼就可以搞定。
事實(shí)上,雖然這個(gè)辦法是直覺上想出來(lái)的,但后來(lái)幾年發(fā)現(xiàn)這個(gè)問題可以總結(jié)成幾個(gè)方程,也是受到了生物學(xué)的啟發(fā)。
我們回到人的大腦是怎么學(xué)習(xí)的。
每個(gè)神經(jīng)元是通過突觸來(lái)連接其他神經(jīng)元,從而傳遞信號(hào)。
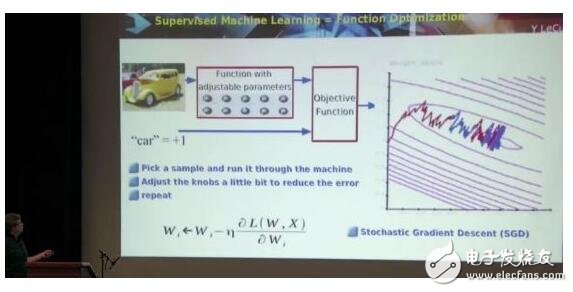
但數(shù)學(xué)上,這個(gè)概念被簡(jiǎn)化了,將感知機(jī)里的權(quán)重看成一個(gè)個(gè)的旋鈕。
對(duì)于具體的輸入,根據(jù)輸出的錯(cuò)誤再調(diào)參數(shù),訓(xùn)練,重復(fù),直到目標(biāo)函數(shù)的值越來(lái)越小(目標(biāo)函數(shù)的值,表示的是你得到的輸出和你想要的輸出的差值)。
這叫做梯度下降(gradient descent),依然是很簡(jiǎn)單的數(shù)學(xué)問題。
舉個(gè)稍微復(fù)雜一點(diǎn)的例子,我們要做一個(gè)圖片分類器,辨識(shí)汽車、飛機(jī)、椅子等物體。

它們的外觀千變?nèi)f化,我們?cè)鯓幼層?jì)算機(jī)認(rèn)出每一類物體呢?
這需要依賴大量的手動(dòng)調(diào)整。給系統(tǒng)一張車的照片,如果系統(tǒng)將它認(rèn)成車,紅燈亮起。如果紅燈不亮,就調(diào)整這些按鈕,讓紅燈的亮度增強(qiáng);輸入飛機(jī)的圖片,調(diào)整按鈕,讓綠燈亮度增強(qiáng)。
輸入足夠多的訓(xùn)練數(shù)據(jù)不停調(diào)整按鈕,直到機(jī)器能夠辨認(rèn)出來(lái)它從來(lái)沒見過的相片為止,那么就算訓(xùn)練成功了。
你們肯定會(huì)問,這個(gè)能識(shí)別圖像的神秘盒子里到底裝了什么?
這個(gè)答案,在過去的幾十年里,一直在變。
傳統(tǒng)的模式識(shí)別,是給它一張圖,然后過一個(gè)特征提取器。這個(gè)特征提取器是人工搭建的,把這些圖像的像素變成一串?dāng)?shù)字,然后用簡(jiǎn)單的算法吸收消化,得到這張圖的內(nèi)容。這種方法在深度學(xué)習(xí)出現(xiàn)以前一直都在用。
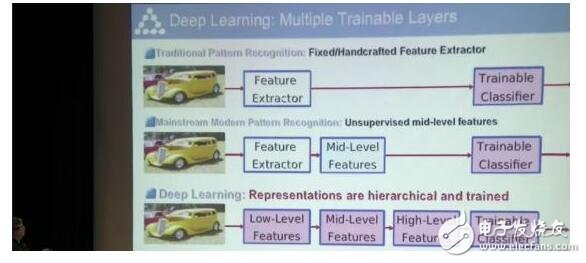
而深度學(xué)習(xí)是把模塊分成可以被訓(xùn)練的好幾層。就像視覺信號(hào)的傳遞一樣,需要多步來(lái)提取信息。
下一個(gè)我們要問的問題是,我們應(yīng)該往這些可訓(xùn)練的模塊箱里放什么東西?
“多層”的概念是50年代提出的,到80年代時(shí)用的人稍微多了起來(lái)。

每一層都是由簡(jiǎn)單的單元組成,而單元又是基于上一層的輸入,經(jīng)過不同程度的權(quán)重處理得到的。然后如果值超過閾值,就繼續(xù)往下走,低于閾值就不取。
那么,我們要如何訓(xùn)練機(jī)器呢?
這其實(shí)是不斷調(diào)小偏差的過程。問題的關(guān)鍵在于往什么方向調(diào)整參數(shù)、調(diào)整到什么程度,才可以拿到我們想要的輸出。
1980年,這個(gè)問題才有了解決方案。
這個(gè)方案是一個(gè)復(fù)雜的數(shù)學(xué)概念的實(shí)際應(yīng)用, 叫鏈?zhǔn)椒▌t(Chain rule)。
當(dāng)你有一個(gè)網(wǎng)絡(luò)的時(shí)候, 你有的是連續(xù)的功能區(qū)塊(Functional block)。
每一個(gè)區(qū)塊或者做矩陣乘法,或者是給每個(gè)輸入做一個(gè)非線性的運(yùn)算。我們來(lái)看看系統(tǒng)之中分離出來(lái)的一個(gè)區(qū)塊。

你可以簡(jiǎn)單地算出來(lái)輸出值。比如說這是一個(gè)線性的矩陣乘法模塊,參數(shù)乘以向量,這樣你就能拿到輸出的向量。這兩個(gè)區(qū)塊有不一樣的維度。
現(xiàn)在假設(shè),對(duì)于每個(gè)向量中任何元素的調(diào)整,我們都知道損失會(huì)往什么方向變化。
損失函數(shù)的斜率,表示的是我們得到的輸出和我們想要輸出的差值。通過計(jì)算,可以得出圖中綠色的向量,從上到下計(jì)算一個(gè)遞歸公式,通過反向傳播,就能得到cost和所有模塊相關(guān)的梯度。
很多現(xiàn)在的平臺(tái),在你寫程序定義網(wǎng)絡(luò)后,都可以自動(dòng)運(yùn)行反向傳播,計(jì)算梯度。
這些問題都解決了之后呢,我們就可以建一個(gè)人工的大腦了嗎?
要知道,人腦每秒可以做10的17次方的運(yùn)算,神經(jīng)元數(shù)量達(dá)到10的11次方。
我們來(lái)看一款運(yùn)算速度很快的芯片。右下角的英偉達(dá)Titan-V,這個(gè)GPU每秒可做10的15次方運(yùn)算,比人腦要慢100倍。

所以大家算算,即使芯片的速度翻一倍要18個(gè)月的話,那還要多長(zhǎng)時(shí)間能達(dá)到和我們?nèi)四X一樣?如果要讓芯片在合理的大小范圍的話,我認(rèn)為我們還要等多幾十年。
但這個(gè)不是主要問題。主要問題是我們不知道怎么編程它們、怎么訓(xùn)練它們、訓(xùn)練原則是什么。
這個(gè)GPU很便宜,才3000刀,但是現(xiàn)在大家都在買來(lái)挖礦,所以已經(jīng)買不到了。
我說過很多次了,如果在我職業(yè)生涯中,能夠造一個(gè)智能體,像大鼠一樣具有常識(shí),我會(huì)感到很開心很滿足。我們現(xiàn)在也許有相應(yīng)的算力了,但我們還沒有搞清楚潛在原則。現(xiàn)在是這個(gè)底層原理限制住了。
好啦,現(xiàn)在我們來(lái)跳出來(lái)看看生物還有沒有給我們別的啟發(fā)。
Hubel & Wiesel 1962這個(gè)生物研究工作太有名了,大家都知道的,是70年代拿了諾貝爾獎(jiǎng)的。工作本身是在60年代做的,是視覺信號(hào)傳遞的生理結(jié)構(gòu)。
簡(jiǎn)單的細(xì)胞檢測(cè)位置信息,復(fù)雜的細(xì)胞整合簡(jiǎn)單細(xì)胞受到刺激的信息。
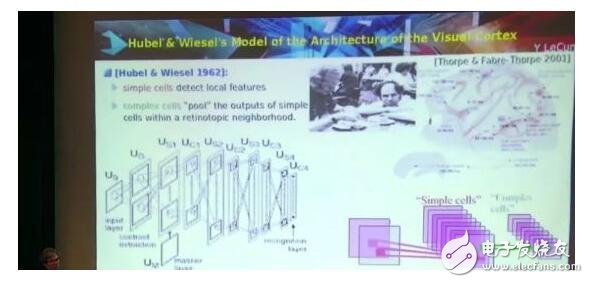
所以,如果有一個(gè)特殊的動(dòng)機(jī),稍微移動(dòng)一點(diǎn),復(fù)雜細(xì)胞都會(huì)被激活。
Fukushima 1982年造了一個(gè)計(jì)算模型,就是描述簡(jiǎn)單細(xì)胞和復(fù)雜細(xì)胞之間的層級(jí)關(guān)系。這個(gè)是80年代的工作,那時(shí)候還沒有合適的學(xué)習(xí)算法。所以用了其他的非監(jiān)督型算法。
后來(lái),我受到這個(gè)算法啟發(fā),造了一個(gè)含有相似構(gòu)造的網(wǎng)絡(luò),用反向傳播算法來(lái)訓(xùn)練,就是我們平時(shí)說的卷積神經(jīng)網(wǎng)絡(luò)(CNN)。
下面是卷積神經(jīng)網(wǎng)絡(luò)的示意圖。
圖像中的像素會(huì)激活CNN中的單元。但我不敢稱他們?yōu)樯窠?jīng)元,不然神經(jīng)科學(xué)家會(huì)不爽。因?yàn)楸绕鹕窠?jīng)元來(lái)說,這些單元實(shí)在是太簡(jiǎn)單了。

每個(gè)單元,看起來(lái)像patch。這些單元會(huì)和閾值比,比他們高,就打開。低的話就關(guān)上。
可以看到這個(gè)用激光筆指出的patch是系數(shù)。
左邊這個(gè)是輸入patch,把系數(shù)向量和輸入向量乘在一起。用系數(shù)把整個(gè)輸入刷一遍,然后你記錄就能得到右邊的結(jié)果。
如果它們能夠匹配的話,就得到高度激活的結(jié)果,不匹配就得到非激活的結(jié)果。
這在數(shù)學(xué)上就叫做離散型卷積。
經(jīng)過了層層卷積核的系數(shù)處理,最后得到的是最右邊的壓縮過的信息。
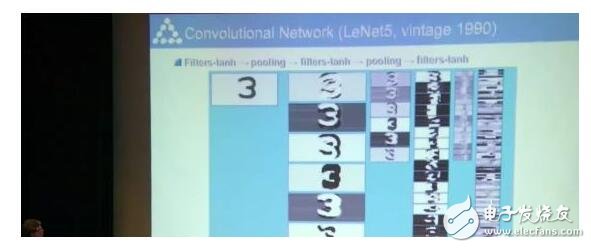
我們90年代中期的時(shí)候弄了一個(gè)很牛的模型。不僅能夠認(rèn)出來(lái)一個(gè)字母,還能認(rèn)出多個(gè)字母,還不用先分割開。當(dāng)時(shí)如果用經(jīng)典數(shù)學(xué)算法就必須先分割。
等到無(wú)法從圖像中分割出物體時(shí),我們模型的重要性就顯現(xiàn)出來(lái)了。
這個(gè)模型中每一層都是卷積的,同時(shí)進(jìn)行分割和識(shí)別。
這是那個(gè)時(shí)候年輕的我,把一張紙條放在一個(gè)攝像頭下面,然后按一下鍵盤。這是1993年的時(shí)候(嘴上說的是1992年)。
這是我在新澤西的時(shí)候貝爾實(shí)驗(yàn)室那會(huì)兒的電話號(hào)碼,現(xiàn)在已經(jīng)不用了。

在幾秒鐘之內(nèi),就可以處理圖像,識(shí)別出數(shù)字。
訓(xùn)練數(shù)據(jù)量不用很多,哪怕是很小的、不同的手寫體,都能識(shí)別成這樣,效果很不錯(cuò)了。
為了以合適的速度跑起來(lái)這個(gè)程序,我們用了特殊的硬件DSP 32C,速度可到 20 FLOPS。最后,我們用這個(gè)造了一個(gè)可以識(shí)別支票的系統(tǒng)。于1996年左右開始鋪開使用。
到90年代末,這套系統(tǒng)已經(jīng)在處理10%到20%左右的支票了。如果你夠老的話,也許你的支票被這套系統(tǒng)讀取過。
這么看,這套系統(tǒng)還是挺成功的。可惜在90年代中期,在機(jī)器學(xué)習(xí)圈里,大家對(duì)神經(jīng)網(wǎng)絡(luò)的熱情消失了。
很大一個(gè)原因是,這套系統(tǒng)需要大量的計(jì)算力投入才軟件系統(tǒng)里。這樣才有可能跑起來(lái)。
這一切都發(fā)生在MATLAB、微軟系統(tǒng)、Linux出現(xiàn)之前,AT&T都還沒公開相應(yīng)的硬件資源。沒有大型計(jì)算機(jī),或大型數(shù)據(jù)集,大家做這個(gè)都只能靠直覺。
其實(shí)在那個(gè)時(shí)候,很多東西都很玄學(xué),我們并不能從數(shù)學(xué)的角度去解釋他們。
不能解釋背后的原理的話,就沒辦法形成一套理論。沒有理論就很混亂,都發(fā)不了文章。
哪怕事實(shí)上,這些方法是可用的,但是也被拋棄了。
不過我們當(dāng)中的某些人,知道,這方法最終還是會(huì)回來(lái)的。因?yàn)樵谀承┣闆r下,這套方法是更好的。
因?yàn)樗鼈儠?huì)自己學(xué)習(xí),不僅僅是識(shí)別圖像,還能夠抽象地表示這個(gè)世界。它們能夠找到事物的本質(zhì),然后找到不同部分之間的聯(lián)系,然后組裝成以個(gè)整體。它們做的事情很強(qiáng)大,所以也需要更多的數(shù)據(jù)。
在1996年和2002年之間,我?guī)缀跬V沽诉@方面的研究,改做圖像壓縮。
2003年的時(shí)候我又開始搞回這個(gè)了。我們做了一輛有兩個(gè)攝像頭小車,讓人來(lái)控制它,當(dāng)距離障礙物2米的時(shí)候,我們會(huì)控制它向左轉(zhuǎn)或向右轉(zhuǎn)來(lái)避開障礙物。然后,我們訓(xùn)練一個(gè)CNN來(lái)看兩個(gè)攝像頭采到的畫面,去預(yù)測(cè)方向盤轉(zhuǎn)向的角度。

只需要20分鐘的訓(xùn)練數(shù)據(jù),這個(gè)CNN就可以自己開車了!遇到障礙物的時(shí)候,它會(huì)自行轉(zhuǎn)向避開。
在這套系統(tǒng)的啟發(fā)下,DARPA舉辦了LAGR(Learning Applied to Ground Vehicles),一個(gè)150萬(wàn)美元的項(xiàng)目。

你可以看到這個(gè)機(jī)器人有四個(gè)攝像頭,內(nèi)部裝了三臺(tái)計(jì)算機(jī),可以在自然環(huán)境中自動(dòng)行駛。我們訓(xùn)練了一個(gè)CNN,讓它告訴我們?cè)诋嬅嫔希男﹨^(qū)域是可以順利通過的。
使用傳統(tǒng)的立體視覺成像技術(shù),也能實(shí)現(xiàn)這個(gè)功能。但是,立體成像很貴,工作范圍也很有限,大概能做到10米的距離。
這就是CNN的一種用途。
很快我們就意識(shí)到,不能只是標(biāo)記一個(gè)區(qū)域能不能通過,更有意思的是,看圖中的某些像素屬于哪個(gè)物體。(物體識(shí)別分類)。
舉個(gè)例子來(lái)說,這些是天,樹,窗,路等等。

這是有人騎著自行車上路拍到的第一人稱視角畫面,這個(gè)算法不能說完美,它認(rèn)為這里是沙漠,實(shí)際上在曼哈頓不可能有沙漠。
不過,它識(shí)別行人等主要目標(biāo)的能力都不錯(cuò),而且即使在普通電腦上跑,也比當(dāng)時(shí)最領(lǐng)先的系統(tǒng)快100倍。這個(gè)算法讓很多人產(chǎn)生了靈感,認(rèn)為我們能把它用到無(wú)人駕駛上。
2014年,有兩個(gè)公司很快就把這個(gè)技術(shù)拿過去用了。一個(gè)是MobilEye,另一個(gè)是Nvidia。

2010年之前,這些研究都在低調(diào)地進(jìn)行著,后來(lái),事情有了變化。
2011年的時(shí)候,深度學(xué)習(xí)在語(yǔ)音識(shí)別上有了重大的進(jìn)展。
在2012年年底,深度學(xué)習(xí)在ImageNet比賽上一舉成名。ImageNet數(shù)據(jù)集包含1000類物體的130萬(wàn)張照片,傳統(tǒng)圖像分類算法在這個(gè)數(shù)據(jù)集上取得的最低錯(cuò)誤率大約是26%。
2012年,一個(gè)多倫多大學(xué)做出來(lái)的大型CNN,將錯(cuò)誤率降到了15%。他們是第一個(gè)正式用GPU跑這么大的CNN的團(tuán)隊(duì)。
于是,突然之間,整個(gè)計(jì)算機(jī)視覺領(lǐng)域都開始使用這項(xiàng)技術(shù)。我從來(lái)沒見過一個(gè)研究領(lǐng)域如此快速地從一種技術(shù)轉(zhuǎn)向另一種。
其實(shí)就在2011年,我們還提交了一篇論文到CVPR。這篇論文打敗了當(dāng)時(shí)最好的記錄,但是卻被拒了。因?yàn)槟莻€(gè)時(shí)候人們都不相信CNN能取得這么好的成績(jī)。因?yàn)榇蠹覜]見過,于是,他們就主觀臆斷地認(rèn)為我們犯規(guī)了之類的。
但是3年之后,世道完全反過來(lái)了。你不用CNN,文章都不可能被接收。
不過這也不是一件好事。因?yàn)檫@樣會(huì)滅殺多樣性。講這件事是想讓大家知道,這在當(dāng)時(shí)是一個(gè)多么重大的革命。
這些網(wǎng)絡(luò)都特別大,有上百萬(wàn)個(gè)按鈕、單元和權(quán)重。網(wǎng)絡(luò)的第一層檢測(cè)的都是一些基本motif,比如邊緣、線條等等。
有的CNN多達(dá)50層,甚至更多。為什么我們需要這么多層?

神經(jīng)網(wǎng)絡(luò)的多層架構(gòu)對(duì)應(yīng)著數(shù)據(jù)的組成型結(jié)構(gòu),不同層檢測(cè)不同的特征,比如線條、邊緣等底層特征,圓圈、弧線、角等中層特征,更接近圖形的高層特征。
這個(gè)世界的所有事物呈現(xiàn)都是分層的。比如文本,就是從字母,字,詞,從句,句子,段落組成的。
愛因斯坦曾經(jīng)說過,這個(gè)世界最不可思議的事,是所有東西都是可以被理解的。
世界上最令人費(fèi)解的事情是,世界是可以理解的。
過去幾年大量的公司做了很多努力,讓這些技術(shù)落地,并規(guī)模化。
開始列舉最近各種研究進(jìn)展
比如說,我們現(xiàn)在用256個(gè)CNN,1小時(shí)就能完成在整個(gè)ImageNet上的訓(xùn)練,錯(cuò)誤率達(dá)到23.74。
計(jì)算機(jī)視覺的最前沿研究Mask R-CNN,可以做物體分割,關(guān)鍵點(diǎn)檢測(cè),人體姿態(tài)捕捉等等。用Sparse ConvNet還可以做3D語(yǔ)義分割——

另外,CNN還能用在和視覺沒什么關(guān)系的領(lǐng)域,比如做翻譯。這對(duì)于Facebook來(lái)說很有用,幫助用戶翻譯短篇的文章。
今天分享提到的很多資料,都是開源的。
卷積神經(jīng)網(wǎng)絡(luò)可以應(yīng)用在很多領(lǐng)域,比如在無(wú)人駕駛上,可以幫機(jī)器用視覺感知環(huán)境。在醫(yī)學(xué)影像、基因?qū)W、物理學(xué)等等各種領(lǐng)域都有應(yīng)用,而且?guī)缀趺刻於加行碌穆涞仡I(lǐng)域出現(xiàn)。
深度學(xué)習(xí)不僅能感知,還能推理。
比如說,我們可以根據(jù)一張圖片,提出問題,
下圖中方塊的數(shù)量比黃色的物體多嗎?
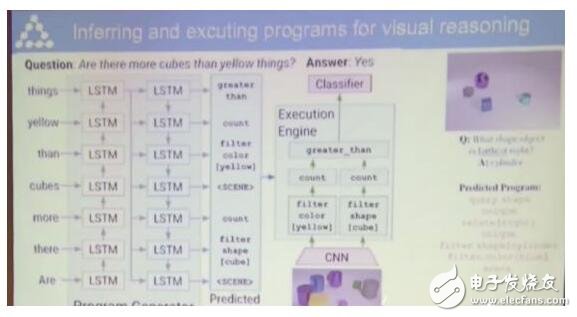
如果是人類來(lái)回答這個(gè)問題,需要分別數(shù)一數(shù)方塊和黃色物體的數(shù)量,然后比較這兩個(gè)數(shù)量的大小。
對(duì)于神經(jīng)網(wǎng)絡(luò)來(lái)說,就需要一個(gè)模塊來(lái)分類出方塊和黃色物體,另一個(gè)模塊來(lái)數(shù)數(shù),還需要一個(gè)模塊比較大小給出答案。
這個(gè)神經(jīng)網(wǎng)絡(luò)是動(dòng)態(tài)的會(huì)隨著輸入的變化而變化,輸入會(huì)決定神經(jīng)網(wǎng)絡(luò)的架構(gòu)。
另外,用記憶模塊來(lái)增強(qiáng)神經(jīng)網(wǎng)絡(luò)也是一個(gè)很有意思的研究方向。
在講座中,立昆老師又提到了他最近推崇的可微分編程。感興趣的同學(xué)可以閱讀之前的文章,以及自行看視頻。
最后,立昆老師還強(qiáng)調(diào)了一點(diǎn):目前,機(jī)器并沒有通用的智能,也沒有嘗常識(shí)。

未來(lái)智能實(shí)驗(yàn)室是人工智能學(xué)家與科學(xué)院相關(guān)機(jī)構(gòu)聯(lián)合成立的人工智能,互聯(lián)網(wǎng)和腦科學(xué)交叉研究機(jī)構(gòu)。由互聯(lián)網(wǎng)進(jìn)化論作者,計(jì)算機(jī)博士劉鋒與中國(guó)科學(xué)院虛擬經(jīng)濟(jì)與數(shù)據(jù)科學(xué)研究中心石勇、劉穎教授創(chuàng)建。
未來(lái)智能實(shí)驗(yàn)室的主要工作包括:建立AI智能系統(tǒng)智商評(píng)測(cè)體系,開展世界人工智能智商評(píng)測(cè);開展互聯(lián)網(wǎng)(城市)云腦研究計(jì)劃,構(gòu)建互聯(lián)網(wǎng)(城市)云腦技術(shù)和企業(yè)圖譜,為提升企業(yè),行業(yè)與城市的智能水平服務(wù)。
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5516瀏覽量
121556
原文標(biāo)題:LeCun親授的深度學(xué)習(xí)入門課:從飛行器的發(fā)明到卷積神經(jīng)網(wǎng)絡(luò)
文章出處:【微信號(hào):AItists,微信公眾號(hào):人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論