") 國產(chǎn)AI新星DeepSeek崛起:日活超2000萬,百萬年薪搶人,或適配國產(chǎn)GPU
國產(chǎn)AI新星DeepSeek崛起:日活超2000萬,百萬年薪搶人,或適配國產(chǎn)GPU
電子發(fā)燒友網(wǎng)報道(文/吳子鵬)在蛇年春節(jié)期間,國產(chǎn)AI大模型DeepSeek爆火,頻繁登上國內(nèi)外的熱搜榜單,成為科技界最炙手可熱的新星。根據(jù)第三方統(tǒng)計數(shù)據(jù),DeepSeek應(yīng)用上線僅僅20天,日活用戶數(shù)量就突破了2000萬大關(guān),其日活增長速度已經(jīng)超過了當初爆火的ChatGPT。
爆火之后,發(fā)布DeepSeek的幻方量化旗下AI公司杭州深度求索人工智能(AI)基礎(chǔ)技術(shù)研究有限公司開始招兵買馬,開放了多個崗位的招聘,并且給出了豐厚的薪資報酬。同時,有業(yè)內(nèi)人士指出,DeepSeek或許會接入國產(chǎn)GPU,對國產(chǎn)GPU發(fā)展有著積極的帶動作用。
DeepSeek現(xiàn)象級爆火后,公司和產(chǎn)業(yè)發(fā)展都將提速
今年1月20日,DeepSeek正式發(fā)布DeepSeek-R1,并同步開源模型權(quán)重。據(jù)介紹,DeepSeek-R1遵循MIT License,允許用戶通過蒸餾技術(shù)借助R1訓(xùn)練其他模型。DeepSeek-R1上線API,對用戶開放思維鏈輸出,通過設(shè)置`model='deepseek-reasoner'`即可調(diào)用。
在性能方面,DeepSeek-R1比肩OpenAI的GPT-4。這款A(yù)I大模型在后訓(xùn)練階段大規(guī)模使用了強化學(xué)習(xí)技術(shù),在僅有極少標注數(shù)據(jù)的情況下,極大提升了模型推理能力。在數(shù)學(xué)、代碼、自然語言推理等任務(wù)上,DeepSeek-R1性能比肩OpenAI o1正式版。同時,由于這款模型采用的是開源策略,因此被認為具有更好的成長性。
目前DeepSeek-R1和更早之前發(fā)布的DeepSeek-V3得到了行業(yè)的廣泛認可,包括京東云、百度云、華為云等云產(chǎn)品都已經(jīng)接入DeepSeek大模型。以京東云來說,京東云已正式上線DeepSeek-R1和DeepSeek-V3模型,支持公有云在線部署、專混私有化實例部署兩種模式。華為云方面,2月1日,華為云宣布經(jīng)過連日攻堅,雙方聯(lián)合首發(fā)并上線了基于華為云昇騰云服務(wù)的DeepSeek-R1/V3推理服務(wù)。同時,英偉達平臺也已經(jīng)宣布上線DeepSeek,英偉達網(wǎng)站顯示,DeepSeek-R1模型已作為NVIDIA NIM微服務(wù)預(yù)覽版在英偉達面向開發(fā)者的網(wǎng)站上發(fā)布。根據(jù)介紹內(nèi)容,英偉達認為,DeepSeek-R1模型是最先進、高效的大型語言模型,在推理、數(shù)學(xué)和編碼方面表現(xiàn)出色。
多家分析機構(gòu)認為,DeepSeek-R1和DeepSeek-V3模型的發(fā)布將加速AI應(yīng)用落地。中信證券研報表示,DeepSeek火爆全球,對全球AI產(chǎn)業(yè)鏈帶來強大借鑒意義,意味著AI大模型的應(yīng)用將逐步走向普及,有望開啟全新的Scaling Law,模型重心逐步從預(yù)訓(xùn)練切換到強化學(xué)習(xí)、推理階段,助力算力需求持續(xù)增長;中航證券指出,DeepSeek在基礎(chǔ)模型訓(xùn)練和推理模型訓(xùn)練方面均有創(chuàng)新,有效克服了推高模型成本的FP8訓(xùn)練精度不足、高質(zhì)量數(shù)據(jù)匱乏等困難,極大降低了訓(xùn)練和推理成本;國泰君安認為,DeepSeek-R1的推出體現(xiàn)了開源范式下技術(shù)進步的速度,以及在AI訓(xùn)練、推理上成本大幅度壓縮的可能,AI的廣泛落地有望加速。
DeepSeek爆火之后,深度求索AI公司也進一步快速擴張。公開資料顯示,DeepSeek員工數(shù)量大約為150人,屬于規(guī)模較小的AI公司。作為對比,OpenAI目前約有1700名員工。為了擴張隊伍,在招聘網(wǎng)站上,深度求索AI公司放出了一系列職位,涵蓋客戶端研發(fā)工程師、深度學(xué)習(xí)研發(fā)工程師、全棧開發(fā)工程師、自然語言處理算法、深度學(xué)習(xí)研究員等不同工作內(nèi)容。
薪酬方面,從正式員工崗位的招聘信息看,DeepSeek對員工薪酬采取“14薪”的模式。在Deepseek掛出的職位中,大部分崗位的起薪在2萬元以上,不少年薪能夠達到百萬元級別。以深度學(xué)習(xí)研究員崗位為例,薪資水平為50—80k*14薪,工作地點為北京,招聘要求是在校或者應(yīng)屆的碩士生。這意味著,若按照最高月薪8萬元計算,應(yīng)屆生入職DeepSeek,年薪就可達到112萬元。除了正式員工,DeepSeek還招聘AGI大模型-數(shù)據(jù)百曉生實習(xí)生、深度學(xué)習(xí)-AGI實習(xí)生等實習(xí)崗位,實習(xí)工資為每天500元左右。
同時,DeepSeek爆火對美國AI產(chǎn)業(yè)造成了巨大的沖擊。此前,DeepSeek的優(yōu)異表現(xiàn)以及不及OpenAI近1/20的算力成本令英偉達股價曾一夜暴跌17%,市值蒸發(fā)近6000億美元,這是美股單日最大跌幅。當天,DeepSeek給美國科技股帶來了重創(chuàng),除了英偉達外,博通、臺積電、AMD和ASML等公司均出現(xiàn)了不同程度的下跌。
另外,DeepSeek的強大也引起了一些國家的擔(dān)憂。比如,美國國會近日提出《2025年美國人工智能能力與中國脫鉤法案》。法案主要內(nèi)容包括:禁止美國人在中國境內(nèi)推進人工智能能力,禁止下載或使用DeepSeek,否則將被定性為犯罪,最高可判處20年監(jiān)禁。隨后,意大利宣布,由于缺乏有關(guān)人工智能模型DeepSeek使用個人數(shù)據(jù)的信息,該機構(gòu)已經(jīng)下架了DeepSeek;法國隱私監(jiān)管機構(gòu)國家信息與自由委員會(CNIL)表示,該機構(gòu)將對中國初創(chuàng)公司DeepSeek進行質(zhì)詢;澳大利亞稱,DeepSeek對政府技術(shù)構(gòu)成了“不可接受的風(fēng)險”,立即實施禁令是為了“保護澳大利亞的國家安全和國家利益”。
DeepSeek有望接入國產(chǎn)GPU
筆者也在DeepSeek平臺向這款大模型提問:DeepSeek為什么會爆火?
DeepSeek給出了6條總結(jié),分別是:
·高性能與精準度:DeepSeek采用了先進的深度學(xué)習(xí)算法和大規(guī)模數(shù)據(jù)集進行訓(xùn)練,使其在多個應(yīng)用場景中表現(xiàn)出色,如自然語言處理、圖像識別等。其高精準度和快速響應(yīng)能力贏得了用戶的廣泛認可。
·技術(shù)創(chuàng)新:DeepSeek在模型架構(gòu)和訓(xùn)練方法上進行了多項創(chuàng)新,例如引入了更高效的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)和優(yōu)化算法,這些技術(shù)突破顯著提升了模型的性能和效率。
·強大的硬件支持:DeepSeek利用了NVIDIA的高性能GPU(如A100和H100),這些硬件提供了強大的計算能力,使得模型訓(xùn)練和推理過程更加高效,進一步提升了用戶體驗。
·廣泛的應(yīng)用場景:DeepSeek不僅在學(xué)術(shù)研究中表現(xiàn)出色,還在商業(yè)應(yīng)用中展現(xiàn)了巨大的潛力。無論是智能客服、內(nèi)容推薦,還是自動駕駛、醫(yī)療診斷,DeepSeek都能提供強有力的支持,滿足了多樣化的市場需求。
·開放與合作:DeepSeek團隊積極與學(xué)術(shù)界和產(chǎn)業(yè)界合作,推動了技術(shù)的快速迭代和應(yīng)用落地。同時,部分技術(shù)和工具的開放也吸引了大量開發(fā)者和研究者的參與,形成了良好的生態(tài)系統(tǒng)。
·市場推廣與用戶口碑:DeepSeek通過有效的市場推廣策略和優(yōu)質(zhì)的用戶體驗,迅速積累了大量的用戶和粉絲。用戶的口碑傳播進一步加速了其知名度的提升。
業(yè)內(nèi)人士稱,雖然DeepSeek曾一度重創(chuàng)英偉達股價,但是其也是基于英偉達的高性能計算芯片訓(xùn)練而來,英偉達芯片的領(lǐng)先性依然是毋庸置疑的。只不過,DeepSeek改變了傳統(tǒng)AI大模型Scaling Law的邏輯,在訓(xùn)練過程中提升強化學(xué)習(xí)的權(quán)重,且更加注重推理。這一改變相較于此前的預(yù)訓(xùn)練權(quán)重高,可能會降低英偉達芯片的影響力,這也是美國科技產(chǎn)業(yè)恐慌的地方。
不過,無論如何,算力芯片依然是DeepSeek的基礎(chǔ),這一AI大模型并不是憑空出現(xiàn)的,只是改變了運用算力芯片的側(cè)重點。有業(yè)內(nèi)人士爆料稱,在使用英偉達H800芯片訓(xùn)練DeepSeek時,沒有采用CUDA代碼,而是從CUDA生態(tài)的中間態(tài)表示入手,用PTX代碼直接編寫,而后轉(zhuǎn)為目標GPU架構(gòu)的機器碼,這和傳統(tǒng)英偉達CUDA生態(tài)的應(yīng)用是有一定差異的。
此舉引發(fā)了大量的猜測。其中一種猜測是,直接使用PTX代碼編寫就是為了繞開CUDA生態(tài),為接入國產(chǎn)GPU做準備。在相關(guān)討論中,也有研發(fā)人員表示,直接使用PTX代碼編寫對GPU有很強的針對性,H100上的代碼一旦轉(zhuǎn)移到H800或者A100上,效果可能就會打折扣,不過這一做法確實能夠更好地發(fā)揮國產(chǎn)GPU的性能。PTX代碼被稱為GPU硬件的“母語”,并不是只針對英偉達GPU,這種做法確實容易引起聯(lián)想。
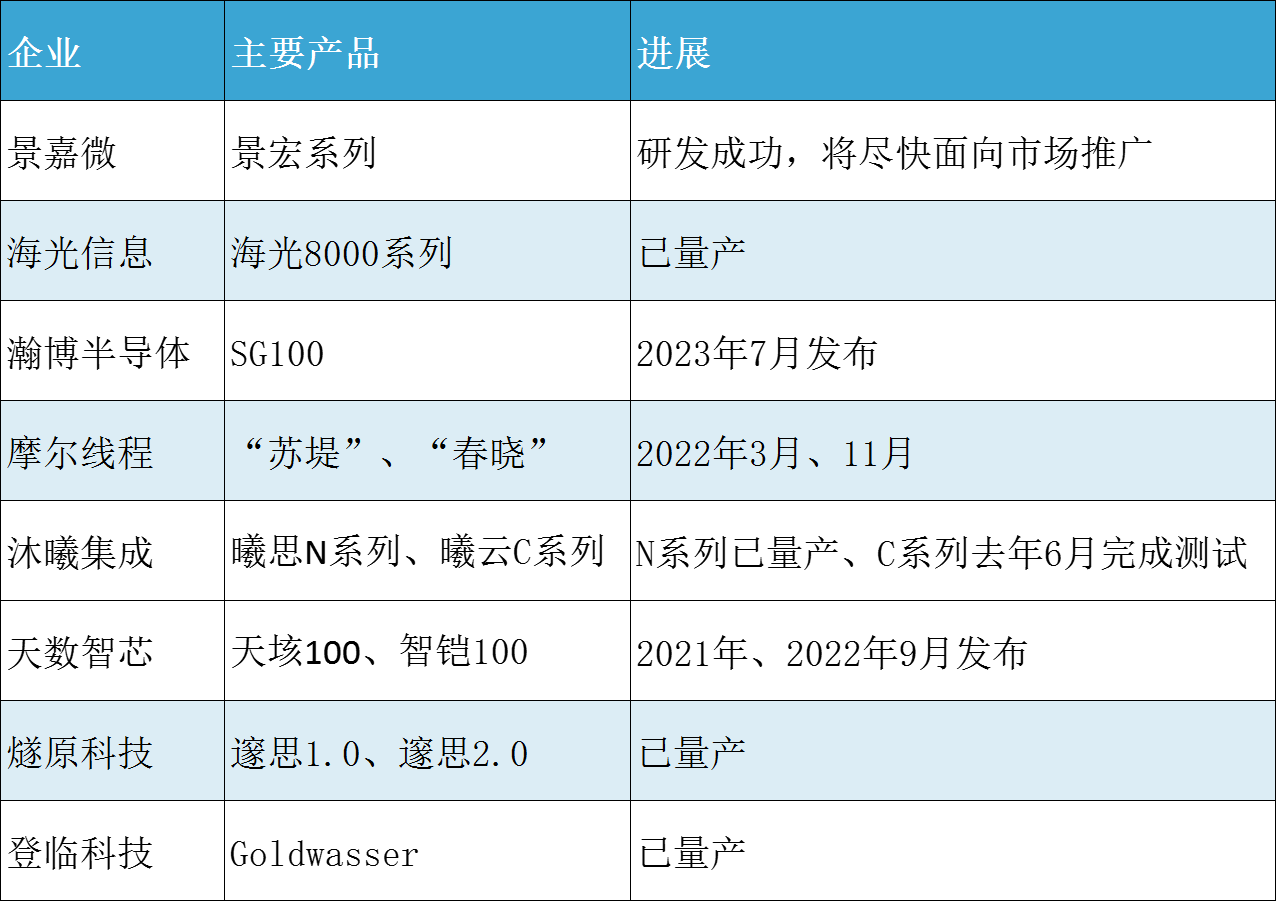
目前,國產(chǎn)計算芯片可用于AI計算的產(chǎn)品有摩爾線程的MTT系列,燧原科技的云燧系列,寒武紀的思元系列,天數(shù)智芯的Big Island系列,以及華為的昇騰(Ascend)系列等,這些產(chǎn)品都有望在DeepSeek開啟的AI大模型新紀元里廣泛受益。
結(jié)語
DeepSeek的爆火是現(xiàn)象級的,顛覆了此前由OpenAI引領(lǐng)的預(yù)訓(xùn)練技術(shù)路線,提升了強化學(xué)習(xí)和推理的作用和權(quán)重,并在硬件的使用上獨辟蹊徑,將會引領(lǐng)全球AI產(chǎn)業(yè)發(fā)展的新潮流。DeepSeek的強大也展示了國內(nèi)AI創(chuàng)新力量的強大,由于DeepSeek沒有采用傳統(tǒng)CUDA語言編程的做法,更是讓人們對國產(chǎn)AI大模型產(chǎn)業(yè)的后續(xù)發(fā)展充滿了無限想象。
發(fā)布評論請先 登錄
相關(guān)推薦
CPU\GPU引領(lǐng),國產(chǎn)AI PC進階

海光信息技術(shù)團隊完成模型與DCU國產(chǎn)化適配
AMD將DeepSeek-V3模型集成至Instinct MI300X GPU
AMD集成DeepSeek-V3模型至Instinct MI300X GPU
國產(chǎn)主板的崛起之路代表著我們的科技實力和創(chuàng)新能力
雷軍千萬年薪挖角95后AI天才少女 DeepSeek開源大模型DeepSeek-V2關(guān)鍵開發(fā)者之一羅福莉
萬年芯:芯片管制再升級,國產(chǎn)替代已是必然

半導(dǎo)體行業(yè)加速國產(chǎn)替代,萬年芯多種產(chǎn)品受關(guān)注

摩爾線程GPU與超圖軟件大模型適配:共筑國產(chǎn)地理空間AI新生態(tài)
國產(chǎn)DSP,自研指令集內(nèi)核C2000,F(xiàn)28335、F280049、F28377
大模型發(fā)展下,國產(chǎn)GPU的機會和挑戰(zhàn)

FHT4644國產(chǎn)替代必然性崛起你還不來了解一下芯片這些事嗎
深圳恒興隆|制造業(yè)的新星:高光超精電主軸的崛起...
國產(chǎn)GPU在AI大模型領(lǐng)域的應(yīng)用案例一覽

盤點國產(chǎn)GPU在支持大模型應(yīng)用方面的進展





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論